Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Consumatori di dati
I consumatori di dati utilizzano i dati del produttore di dati dopo che il catalogo centralizzato li utilizza AWS Lake Formation per condividerli. Il diagramma seguente mostra due consumatori di dati nel data lake.
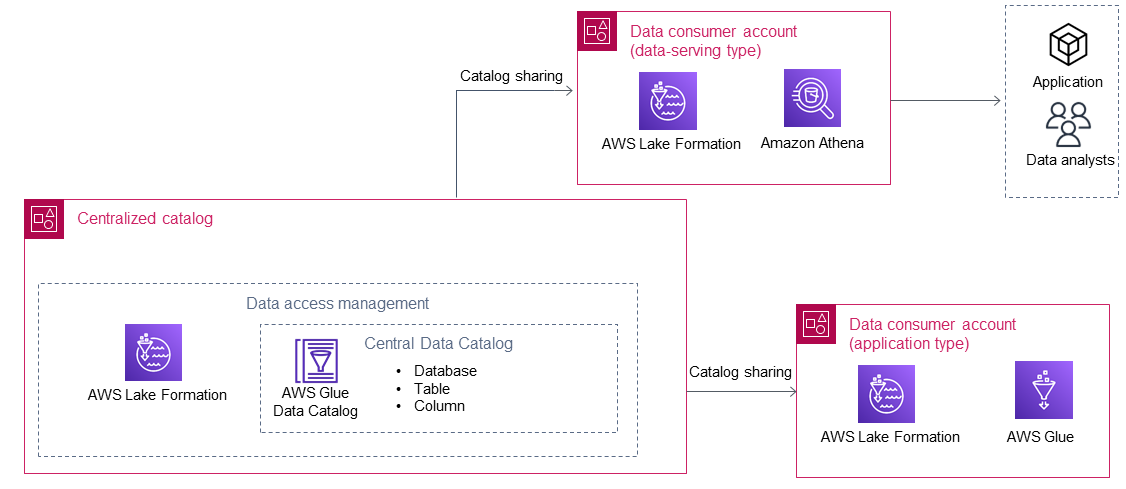
Esistono due tipi di consumatori di dati: applicazioni e servizi di dati. La tabella seguente descrive questi due tipi.
| Tipo di applicazione |
Gli utenti che utilizzano i dati delle applicazioni eseguono le applicazioni autonomamente Account AWS. Le applicazioni utilizzano i ruoli AWS Identity and Access Management (IAM) per accedere ai dati condivisi da un produttore di dati e quindi elaborarli secondo la loro logica. In genere, questo tipo di consumatore di dati ha requisiti prescrittivi in materia di dati per soddisfare le esigenze di un'applicazione. |
| Tipo di data serving |
I consumatori di dati che servono dati sono in genere destinati a individui (ad esempio analisti di dati o data scientist) e applicazioni (ad esempio, un'applicazione di business intelligence) che non dispongono di una propria. Account AWS Nel data lake di un'organizzazione possono esistere più consumatori di dati che servono dati. Ad esempio, diverse linee di business potrebbero scegliere di creare i propri consumatori di dati per il servizio di dati per aiutare gli utenti a consumare i dati dal data lake. Questi consumatori di dati hanno i propri principi di ruolo IAM configurati Account AWS (ad esempio, ruoli IAM associati a AWS IAM Identity Center) che vengono utilizzati dagli utenti finali nell'account del consumatore di dati per accedere ai dati condivisi tramite AWS servizi (ad esempio, Amazon Athena). In genere, questo tipo di consumatore di dati ha requisiti di dati di ampia portata e in continuo aumento. |
AWS Lake Formation è il AWS servizio più importante utilizzato da un consumatore di dati per la condivisione dei dati tra account e l'accesso al catalogo centralizzato. Dopo che i database sono stati condivisi dal catalogo centralizzato, le risorse condivise sono disponibili in Lake Formation nell'account data consumer. L'accesso ai dati può quindi essere concesso ai responsabili IAM locali nell'account Data Consumer, con l'autorizzazione del produttore dei dati, se necessario. I dati condivisi possono quindi essere utilizzati dai AWS servizi integrati con Lake Formation (ad esempio, Amazon Athena e AWS Glue). Puoi utilizzare i seguenti AWS servizi per accedere ai dati condivisi nell'account Data Consumer:
-
Amazon Athena è un servizio di query interattivo che aiuta ad analizzare direttamente i dati in Amazon Simple Storage Service (Amazon S3) utilizzando SQL standard. Per ulteriori informazioni su Athena e Lake Formation, consulta Come Athena accede ai dati registrati con Lake Formation nella documentazione di Amazon Athena.
-
Amazon Redshift Spectrum ti aiuta a interrogare e recuperare in modo efficiente dati strutturati e semistrutturati dai file in Amazon S3 senza dover caricare i dati nelle tabelle Amazon Redshift. Per ulteriori informazioni su Redshift Spectrum e Lake Formation, consulta Using Redshift Spectrum with Lake Formation nella documentazione di Amazon Redshift.
-
AWS Glueè un servizio di estrazione, trasformazione e caricamento (ETL) completamente gestito che rende semplice ed economico classificare i dati, pulirli, arricchirli e spostarli in modo affidabile tra diversi archivi di dati e flussi di dati. Il ruolo IAM associato a un job AWS Glue ETL può accedere ai dati del data lake gestiti da Lake Formation se dispone delle autorizzazioni di accesso richieste.
-
Amazon EMR aiuta a eseguire framework di big data (ad esempio, Apache Hadoop e Apache
Spark) per elaborare e analizzare grandi quantità di dati. Per ulteriori informazioni su Amazon EMR e Lake Formation, consulta Integrare Amazon EMR con Lake Formation nella documentazione di Amazon EMR. -
Amazon QuickSight è un servizio di business intelligence scalabile, serverless, incorporabile e basato sull'apprendimento automatico (ML) che puoi utilizzare per analizzare e visualizzare i dati dal tuo data lake. Per ulteriori informazioni su QuickSight Lake Formation, vedere Authorizing connections through Lake Formation nella QuickSight documentazione.
-
Amazon SageMaker AI Data Wrangler (Data Wrangler) riduce il tempo necessario per aggregare e preparare i dati per il machine learning. Per ulteriori informazioni su Data Wrangler e Lake Formation, consulta Prepare ML Data with Amazon SageMaker AI Data Wrangler nella documentazione di Amazon AI. SageMaker
