Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea un'immagine di contenitore Docker personalizzata SageMaker e usala per l'addestramento dei modelli in AWS Step Functions
Julia Bluszcz, Aubrey Oosthuizen, Mohan Gowda Purushothama, Neha Sharma e Mateusz Zaremba, Amazon Web Services
Riepilogo
Questo modello mostra come creare un'immagine di contenitore Docker per Amazon SageMaker e utilizzarla per un modello di formazione in AWS Step Functions. Impacchettando algoritmi personalizzati in un contenitore, puoi eseguire quasi tutto il codice nell' SageMaker ambiente, indipendentemente dal linguaggio di programmazione, dal framework o dalle dipendenze.
Nel SageMaker notebook di esempio fornito, l'immagine del contenitore Docker personalizzato viene archiviata in Amazon Elastic Container Registry (Amazon ECR). Step Functions utilizza quindi il contenitore archiviato in Amazon ECR per eseguire uno script di elaborazione Python per. SageMaker Quindi, il contenitore esporta il modello in Amazon Simple Storage Service (Amazon S3).
Prerequisiti e limitazioni
Prerequisiti
Un account AWS attivo
Un ruolo AWS Identity and Access Management (IAM) per chi utilizza SageMaker le autorizzazioni di Amazon S3
Familiarità con Python
Familiarità con l'SDK Amazon SageMaker Python
Familiarità con l'AWS Command Line Interface (AWS CLI)
Familiarità con AWS SDK per Python (Boto3)
Familiarità con Amazon ECR
Familiarità con Docker
Versioni del prodotto
SDK AWS Step Functions Data Science versione 2.3.0
SDK Amazon SageMaker Python versione 2.78.0
Architettura
Il diagramma seguente mostra un esempio di flusso di lavoro per creare un'immagine di contenitore Docker per SageMaker, quindi utilizzarla per un modello di addestramento in Step Functions:
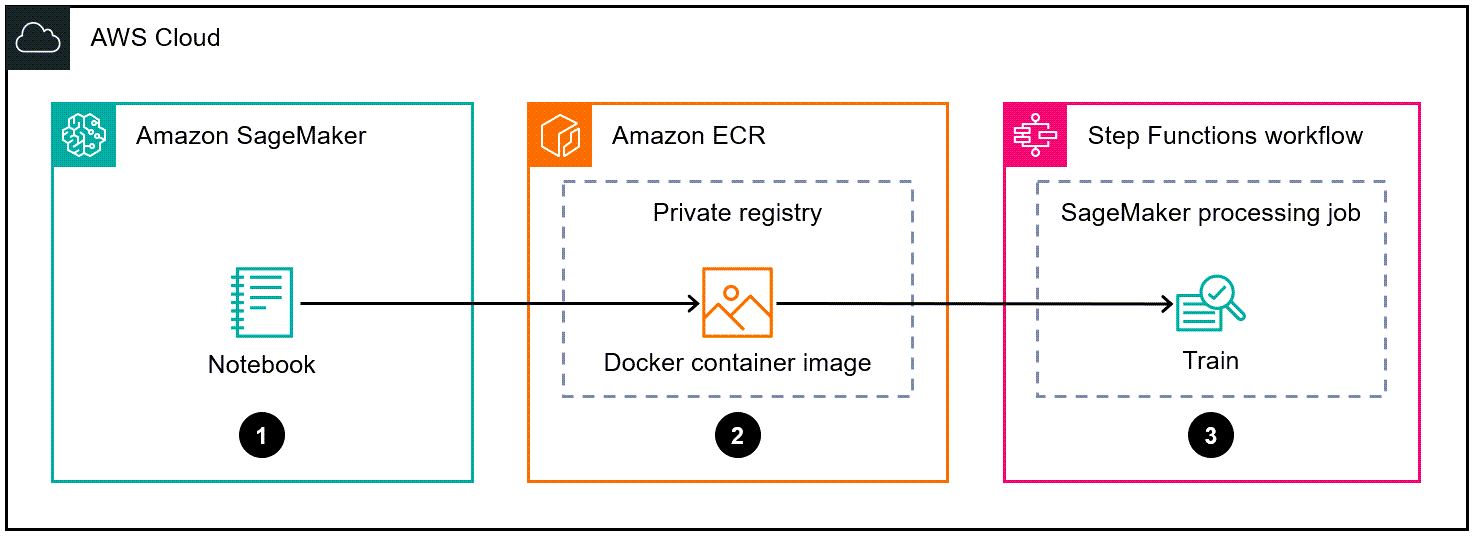
Il diagramma mostra il flusso di lavoro seguente:
Un data scientist o un DevOps ingegnere utilizza un SageMaker notebook Amazon per creare un'immagine di contenitore Docker personalizzata.
Un data scientist o un DevOps ingegnere archivia l'immagine del contenitore Docker in un repository privato Amazon ECR che si trova in un registro privato.
Un data scientist o un DevOps ingegnere utilizza il contenitore Docker per eseguire un processo di elaborazione SageMaker Python in un flusso di lavoro Step Functions.
Automazione e scalabilità
Il SageMaker notebook di esempio in questo modello utilizza un tipo di istanza di ml.m5.xlarge notebook. È possibile modificare il tipo di istanza in base al proprio caso d'uso. Per ulteriori informazioni sui tipi di istanze SageMaker notebook, consulta la pagina SageMaker dei prezzi di Amazon
Strumenti
Amazon Elastic Container Registry (Amazon ECR) è un servizio di registro di immagini di container gestito sicuro, scalabile e affidabile.
Amazon SageMaker è un servizio di machine learning (ML) gestito che ti aiuta a creare e addestrare modelli di machine learning per poi distribuirli in un ambiente ospitato pronto per la produzione.
Amazon SageMaker Python SDK
è una libreria open source per la formazione e la distribuzione di modelli di apprendimento automatico su. SageMaker AWS Step Functions è un servizio di orchestrazione serverless che ti aiuta a combinare le funzioni AWS Lambda e altri servizi AWS per creare applicazioni aziendali critiche.
AWS Step Functions Data Science Python SDK
è una libreria open source che ti aiuta a creare flussi di lavoro Step Functions che elaborano e pubblicano modelli di machine learning.
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Configura Amazon ECR e crea un nuovo registro privato. | Se non l'hai già fatto, configura Amazon ECR seguendo le istruzioni in Configurazione con Amazon ECR nella Amazon ECR User Guide. Ogni account AWS è dotato di un registro Amazon ECR privato predefinito. | DevOps ingegnere |
Crea un repository privato Amazon ECR. | Segui le istruzioni in Creazione di un repository privato nella Amazon ECR User Guide. NotaIl repository che crei è il luogo in cui archivierai le immagini personalizzate dei contenitori Docker. | DevOps ingegnere |
Crea un Dockerfile che includa le specifiche necessarie per eseguire il SageMaker processo di elaborazione. | Crea un Dockerfile che includa le specifiche necessarie per eseguire il SageMaker processo di elaborazione configurando un Dockerfile. Per istruzioni, consulta Adattamento del proprio contenitore di formazione nella Amazon SageMaker Developer Guide. Per ulteriori informazioni su Dockerfiles, consulta il Dockerfile Reference nella documentazione Docker Esempio di celle di codice del notebook Jupyter per creare un Dockerfile Cella 1
Cella 2
| DevOps ingegnere |
Crea l'immagine del tuo contenitore Docker e inviala ad Amazon ECR. |
Per ulteriori informazioni, consulta Creazione e registrazione del contenitore in Costruire il Esempio di celle di codice per notebook Jupyter per creare e registrare un'immagine Docker ImportantePrima di eseguire le seguenti celle, assicurati di aver creato un Dockerfile e di averlo archiviato nella directory chiamata. Cella 1
Cella 2
Cella 3
Cella 4
NotaÈ necessario autenticare il client Docker nel registro privato in modo da poter utilizzare i comandi | DevOps ingegnere |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea uno script Python che includa la tua logica di elaborazione personalizzata e di addestramento dei modelli. | Scrivi una logica di elaborazione personalizzata da eseguire nello script di elaborazione dei dati. Quindi, salvalo come script Python denominato. Per ulteriori informazioni, consulta Bring your own model with SageMaker Script Mode Esempio di script Python che include l'elaborazione personalizzata e la logica di addestramento dei modelli
| Data scientist |
Crea un flusso di lavoro Step Functions che includa il tuo job SageMaker Processing come uno dei passaggi. | Installa e importa l'SDK AWS Step Functions Data Science ImportanteAssicurati di aver creato un ruolo di esecuzione IAM per Step Functions Esempio di configurazione dell'ambiente e script di formazione personalizzato da caricare su Amazon S3
Esempio di definizione della fase di SageMaker elaborazione che utilizza un'immagine Amazon ECR personalizzata e uno script Python NotaAssicurati di utilizzare il
Esempio di flusso di lavoro Step Functions che esegue un SageMaker processo di elaborazione NotaQuesto flusso di lavoro di esempio include solo la fase del processo di SageMaker elaborazione, non un flusso di lavoro Step Functions completo. Per un esempio completo di flusso di lavoro, consulta Notebooks di esempio SageMaker nella documentazione
| Data scientist |
Risorse correlate
Dati di processo (Amazon SageMaker Developer Guide)
Adattamento del proprio contenitore di formazione (Amazon SageMaker Developer Guide)
