Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dell'editor di query v2
L'editor di query v2 viene utilizzato principalmente per modificare ed eseguire query, visualizzare i risultati e condividere il lavoro con il team. Con l'editor di query v2, è possibile creare database, schemi, tabelle e funzioni definite dall'utente (FDU). In un pannello con struttura ad albero, per ciascuno dei database, puoi visualizzarne gli schemi. Per ogni schema, è possibile visualizzare le tabelle, le viste, le FDU e le procedure archiviate.
Argomenti
Apertura editor di query v2
Scopri come aprire l'editor di query v2
Dal menu navigator, selezionare Editor, quindi Editor di query v2. L'editor di query v2 viene aperto in una nuova scheda del browser.
Nella pagina dell'editor di query è disponibile un menu di navigazione in cui è possibile scegliere una vista nel modo descritto di seguito.
- Editor
Puoi gestire ed eseguire query sui dati organizzati come tabelle e contenuti in un database. Il database può contenere dati archiviati o un riferimento a dati archiviati altrove, ad esempio in Amazon S3. È possibile connettersi a un database contenuto in un cluster o in un gruppo di lavoro serverless.
Quando si lavora nella vista Editor, si dispone dei seguenti controlli:
Il campo Cluster o Workgroup (Gruppo di lavoro) visualizza il nome dell'elemento a cui si è attualmente connessi. Il campo Database visualizza i database all'interno del cluster o del gruppo di lavoro. Le azioni che esegui nella vista Database agiscono per impostazione predefinita sul database selezionato.
Una vista gerarchica ad albero dei cluster o dei gruppi di lavoro, dei database e degli schemi. In schemi, è possibile lavorare con tabelle, viste, funzioni e procedure archiviate. Ogni oggetto nella vista ad albero supporta un menu contestuale per eseguire azioni associate, ad esempio Aggiorna o Elimina, per l'oggetto.
Un'operazione
 Crea per creare database, schemi, tabelle e funzioni.
Crea per creare database, schemi, tabelle e funzioni.Un'operazione
 Carica dati per caricare i dati da Amazon S3 o da un file locale nel database.
Carica dati per caricare i dati da Amazon S3 o da un file locale nel database.Un'icona
 Salva per salvare la query.
Salva per salvare la query. Un'icona
 Shortcuts per visualizzare le scorciatoie da tastiera per l'editor.
Shortcuts per visualizzare le scorciatoie da tastiera per l'editor. Un'icona
 Altro per visualizzare più operazioni nell'editor. Ad esempio:
Altro per visualizzare più operazioni nell'editor. Ad esempio: Condividi con il mio team per condividere la query o il notebook con il team. Per ulteriori informazioni, consulta Collaborazione e condivisione come team.
Tasti di scelta rapida per visualizzare i tasti di scelta rapida per l'editor.
Cronologia delle schede per visualizzare la cronologia delle schede di una scheda nell'editor.
Aggiorna il completamento automatico per aggiornare i suggerimenti visualizzati durante la creazione di SQL.
Un'area Editor
 in cui è possibile inserire ed eseguire la query.
in cui è possibile inserire ed eseguire la query. Dopo aver eseguito una query, viene visualizzata la scheda Risultato con i risultati. Qui puoi abilitare Grafico per visualizzare i risultati. Puoi anche esportare i risultati usando il comando Export (Esporta).
Un'area
Notebook in cui è possibile aggiungere sezioni per inserire ed eseguire istruzioni SQL o aggiungere markdown. Dopo aver eseguito una query, viene visualizzata la scheda Risultato con i risultati. È in questa area che è possibile esportare i risultati mediante il comando Export (Esporta).
- Query

Una query contiene i comandi SQL per gestire i dati contenuti in un database ed eseguirvi query. Quando utilizzi l'editor di query v2 per caricare i dati di esempio, vengono automaticamente create e salvate anche query di esempio.
Quando si sceglie una query salvata, è possibile aprirla, rinominarla ed eliminarla usando il menu contestuale (clic con il pulsante destro del mouse). È possibile visualizzare attributi come l'ARN della query di una query salvata scegliendo Dettagli della query. È anche possibile visualizzarne la cronologia delle versioni, modificare i tag collegati alla query e condividerla con il proprio team.
- Notebook

Un notebook SQL contiene celle SQL e Markdown. È possibile utilizzare i notebook per organizzare, annotare e condividere più query SQL in un singolo documento.
Quando si sceglie un notebook salvato, è possibile aprirlo, rinominarlo ed eliminarlo usando il menu contestuale (clic con il pulsante destro del mouse). È possibile visualizzare attributi come l'ARN del notebook di un notebook salvato scegliendo Dettagli del notebook. È anche possibile visualizzarne la cronologia delle versioni, modificare i tag collegati al notebook, esportarlo e condividerlo con il proprio team. Per ulteriori informazioni, consulta Autorizzazione ed esecuzione di notebook.
- Grafici

Un grafico è una rappresentazione visiva dei dati. Nell'editor di query v2 sono disponibili gli strumenti per la creazione e il salvataggio di molti tipi di grafici.
Quando si sceglie un grafico salvato, è possibile aprirlo, rinominarlo ed eliminarlo usando il menu contestuale (clic con il pulsante destro del mouse). È possibile visualizzare attributi come l'ARN del grafico di un grafico salvato scegliendo Dettagli del grafico. È anche possibile modificare i tag collegati al grafico ed esportarlo. Per ulteriori informazioni, consulta Visualizzazione dei risultati delle query.
- Cronologia

La cronologia di query è un elenco di query eseguite utilizzando l'editor di query v2 di Amazon Redshift. Queste query sono state eseguite come singole quiery o come parte di un notebook SQL. Per ulteriori informazioni, consulta Visualizzazione della cronologia delle query e delle schede.
- Query pianificate

Una query pianificata è una query impostata per essere avviata in orari specifici.
Tutte le visualizzazioni dell'editor di query v2 includono le seguenti icone:
L'icona
 (Modalità visiva) per passare dal tema chiaro al tema scuro.
(Modalità visiva) per passare dal tema chiaro al tema scuro.L'icona
 (Impostazioni) per mostrare un menu per accedere alle diverse schermate delle impostazioni.
(Impostazioni) per mostrare un menu per accedere alle diverse schermate delle impostazioni.L'icona
 (Preferenze dell'editor) per modificare le preferenze quando utilizzi l'editor di query v2. Qui puoi scegliere Modifica delle impostazioni dell'area di lavoro per modificare la dimensione del carattere, la dimensione delle schede e altre impostazioni di visualizzazione. Puoi anche attivare (o disattivare) il Completamento automatico per mostrare suggerimenti quando inserisci il codice SQL.
(Preferenze dell'editor) per modificare le preferenze quando utilizzi l'editor di query v2. Qui puoi scegliere Modifica delle impostazioni dell'area di lavoro per modificare la dimensione del carattere, la dimensione delle schede e altre impostazioni di visualizzazione. Puoi anche attivare (o disattivare) il Completamento automatico per mostrare suggerimenti quando inserisci il codice SQL.L'icona
 (Connessioni) per visualizzare le connessioni utilizzate dalle schede dell'editor.
(Connessioni) per visualizzare le connessioni utilizzate dalle schede dell'editor.Per recuperare dati da un database, viene utilizzata una connessione. Viene creata una connessione per un database specifico. Con una connessione isolata, i risultati di un comando SQL che modifica il database in una scheda dell'editor, ad esempio la creazione di una tabella temporanea, non sono visibili in un'altra scheda dell'editor. Quando si apre una scheda nell'editor di query v2, l'impostazione predefinita è una connessione isolata. Quando si crea una connessione condivisa, ovvero si disattiva il parametro Isolated session (Sessione isolata), i risultati di altre connessioni condivise allo stesso database sono visibili tra loro. Tuttavia, le schede dell'editor che utilizzano una connessione condivisa a un database non vengono eseguite in parallelo. Le query che utilizzano la stessa connessione devono attendere che la connessione torni disponibile. Una connessione a un database non può essere condivisa con un altro database e pertanto i risultati SQL non sono visibili tra le varie connessioni.
Il numero di connessioni attive che qualsiasi utente nell'account può avere è gestito da un amministratore dell'editor di query v2.
L'icona
 (Impostazioni account) utilizzata da un amministratore per modificare alcune impostazioni di tutti gli utenti nell'account. Per ulteriori informazioni, consulta Modifica delle impostazioni dell'account.
(Impostazioni account) utilizzata da un amministratore per modificare alcune impostazioni di tutti gli utenti nell'account. Per ulteriori informazioni, consulta Modifica delle impostazioni dell'account.
Connessione a un database Amazon Redshift
Per connetterti a un database, scegli il nome del cluster o del gruppo di lavoro nel pannello con struttura ad albero. Se richiesto, immettere i parametri di connessione.
Quando ti connetti a un cluster o a un gruppo di lavoro e ai relativi database, di solito fornisci un nome per il database. È inoltre possibile fornire i parametri necessari per uno dei seguenti metodi di autenticazione:
- IAM Identity Center
-
Con questo metodo, esegui la connessione al data warehouse Amazon Redshift con le credenziali dell'autenticazione unica del tuo gestore dell'identità digitale. Il cluster o il gruppo di lavoro deve essere abilitato per il Centro identità IAM nella console Amazon Redshift. Per assistenza nella configurazione delle connessioni a IAM Identity Center, consultaConnessione di Redshift al Centro identità IAM per offrire agli utenti un'esperienza di autenticazione unica.
- Utente federato
-
Con questo metodo, i tag dei principali dell'utente o del ruolo IAM devono fornire i dettagli di connessione. Questi tag vengono configurati nel AWS Identity and Access Management nostro provider di identità (IdP). L'editor di query v2 si basa sui seguenti tag:
RedshiftDbUser: questo tag definisce l'utente del database utilizzato dall'editor di query v2. Questo tag è obbligatorio.RedshiftDbGroups: questo tag definisce i gruppi di database che vengono uniti durante la connessione all'editor di query v2. Questo tag è facoltativo e il suo valore deve essere un elenco separato da due punti, ad esempiogroup1:group2:group3. I valori vuoti vengono ignorati, ossia,group1::::group2è interpretato comegroup1:group2.
Questi tag vengono inoltrati all'API
redshift:GetClusterCredentialsper ottenere le credenziali per il tuo cluster. Per ulteriori informazioni, consulta Configurazione dei tag principali per la connessione a un cluster o un gruppo di lavoro dall'editor di query v2. - Credenziali temporanee con un nome utente del database
-
Questa opzione è disponibile solo quando ci si connette a un cluster. Con questo metodo, l'editor di query v2 fornisce un nome utente per il database. L'editor di query v2 genera una password temporanea per la connessione al database con il tuo nome utente del database. Un utente che utilizza questo metodo per connettersi deve avere l'autorizzazione IAM per
redshift:GetClusterCredentials. Per impedire agli utenti di utilizzare questo metodo, modifica il loro utente o ruolo IAM per negare questa autorizzazione. - Credenziali temporanee che utilizzano la tua identità IAM
-
Questa opzione è disponibile solo quando ci si connette a un cluster. Con questo metodo, l'editor di query v2 mappa un nome utente alla tua identità IAM e genera una password temporanea per la connessione al database con la tua identità IAM. Un utente che utilizza questo metodo per connettersi deve avere l'autorizzazione IAM per
redshift:GetClusterCredentialsWithIAM. Per impedire agli utenti di utilizzare questo metodo, modifica il loro utente o ruolo IAM per negare questa autorizzazione. - Nome utente e password del database
-
Con questo metodo, fornire anche un Nome utente e una Password per il database a cui ti stai connettendo. L'editor di query v2 crea un segreto per tuo conto archiviato in AWS Secrets Manager. Questo segreto contiene le credenziali per la connessione al database.
- AWS Secrets Manager
-
Con questo metodo, anziché un nome di database fornisci un Secret (Segreto) archiviato in Gestione dei segreti che contiene il tuo database e le credenziali di accesso. Per informazioni sulla creazione di un segreto, Creazione di un segreto per le credenziali di connessione al database consulta.
Quando selezioni un cluster o un gruppo di lavoro con l'editor di query v2, a seconda del contesto, puoi creare, modificare ed eliminare connessioni utilizzando il menu contestuale (clic con il pulsante destro del mouse). È possibile visualizzare attributi come l'ARN di connessione della connessione scegliendo Dettagli connessione. È anche possibile modificare i tag collegati alla connessione.
Navigazione in un database Amazon Redshift
All'interno di un database è possibile gestire schemi, tabelle, viste, funzioni e procedure archiviate nel pannello di visualizzazione ad albero. Ad ogni oggetto nella visualizzazione vengono associate operazioni in un menu contestuale (clic con il pulsante destro del mouse).
Il pannello gerarchico con visualizzazione ad albero mostra gli oggetti del database. Per aggiornare il pannello della visualizzazione ad albero per visualizzare gli oggetti del database che potrebbero essere stati creati dopo l'ultima visualizzazione della visualizzazione ad albero, scegli l'icona
 . Aprire il menu contestuale (clic con il pulsante destro del mouse) di un oggetto per vedere quali operazioni è possibile eseguire.
. Aprire il menu contestuale (clic con il pulsante destro del mouse) di un oggetto per vedere quali operazioni è possibile eseguire.
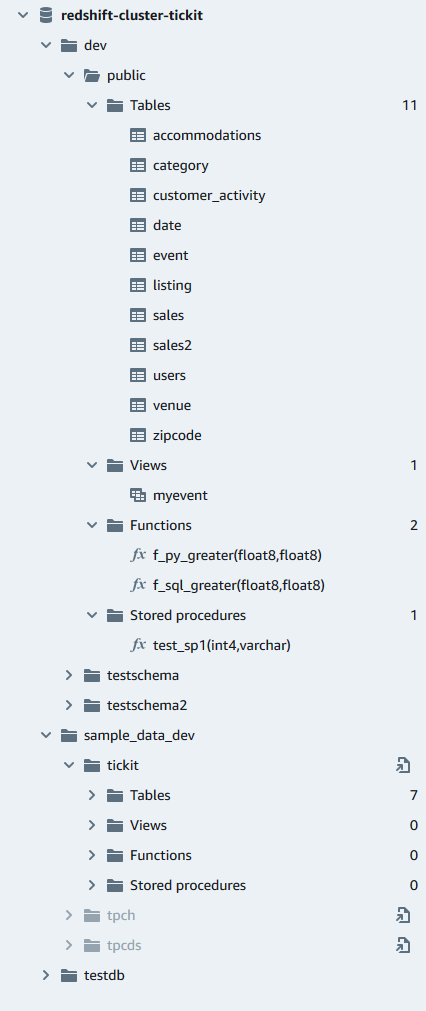
Dopo aver scelto una tabella, puoi procedere come segue:
Per avviare una query nell'editor con un'istruzione SELECT che esegue query su tutte le colonne della tabella, utilizzare Seleziona tabella.
Per visualizzare gli attributi o una tabella, utilizzare Visualizza definizione della tabella. Utilizzare questa opzione per visualizzare i nomi delle colonne, i tipi di colonna, la codifica, le chiavi di distribuzione, le chiavi di ordinamento e se una colonna può contenere valori nulli. Per ulteriori informazioni sugli attributi della tabella, consultare CREA TABELLA nella Guida per gli sviluppatori di database di Amazon Redshift.
Per eliminare una tabella, utilizzare Elimina. È possibile utilizzare Troncare tabella per eliminare tutte le righe dalla tabella o Elimina tabella per rimuovere la tabella dal database. Per ulteriori informazioni, consultare TRONCARE e ELIMINA TABELLA nella Guida per gli sviluppatori di database di Amazon Redshift.
Scegliere uno schema per Aggiorna o Elimina schema.
Scegliere una vista per Mostra la definizione della vista o Elimina vista.
Scegliere una funzione per Mostra definizione della funzione o Elimina funzione.
Scegli una procedura archiviata per Mostra definizione della procedura o Elimina procedura.
Creazione di oggetti di database
È possibile creare oggetti di database, inclusi database, schemi, tabelle e funzioni definite dall'utente (FDU). Per creare oggetti di database, è necessaria la connessione a un cluster o a un gruppo di lavoro e a un database.
Creazione di database
Puoi usare l'editor di query v2 per creare database nel tuo cluster o gruppo di lavoro.
Per creare un database:
Per informazioni sui database CREA DATABASE nella Guida per gli sviluppatori di database di Amazon Redshift.
Scegliere
Crea, quindi scegliere Database.Inserire un Nome database.
(Facoltativo) Seleziona Utenti e gruppi e scegli un Utente del database.
(Facoltativo) È possibile creare il database da una unità di condivisione dati o da AWS Glue Data Catalog. Per ulteriori informazioni su AWS Glue, vedi Cos'è AWS Glue? nella Guida per gli AWS Glue sviluppatori.
(Facoltativo) Seleziona Crea utilizzando una unità di condivisione dati e scegli Seleziona una unità di condivisione dati. L'elenco include le unità di condivisione dati che possono essere utilizzate per creare un'unità di condivisione dati consumer nel cluster o nel gruppo di lavoro corrente.
(Facoltativo) Selezionate Crea utilizzando AWS Glue Data Catalog e scegliete un database Choose an AWS Glue. In Schema del catalogo dati, inserisci il nome che verrà utilizzato per lo schema quando si fa riferimento ai dati in un nome composto da tre parti (database.schema.table).
Scegliere Crea database.
Il nuovo database viene visualizzato nel pannello con visualizzazione ad albero.
Quando scegli la procedura facoltativa per eseguire una query su un database creato da una unità di condivisione dati, connettiti a un database Amazon Redshift nel cluster o nel gruppo di lavoro (ad esempio, il database predefinito
dev) e usa una notazione in tre parti (database.schema.table) che fa riferimento al nome del database che hai creato quando hai selezionato Crea utilizzando un'unità di condivisione dati. Il database di unità di condivisione dati è elencato nella scheda editor dell'editor di query v2, ma non è abilitato per la connessione diretta.Quando scegli il passaggio opzionale per interrogare un database creato da un AWS Glue Data Catalog, connettiti al tuo database Amazon Redshift nel cluster o nel gruppo di lavoro (ad esempio, il database predefinito
dev) e usa una notazione in tre parti (database.schema.table) che fa riferimento al nome del database creato quando hai selezionato Crea utilizzando AWS Glue Data Catalog, allo schema che hai nominato nello schema del catalogo dati e alla tabella in. AWS Glue Data Catalog Simile a:SELECT * FROMglue-database.glue-schema.glue-tableNota
Conferma di essere connesso al database predefinito utilizzando il metodo di connessione Credenziali temporanee che utilizzano la tua identità IAM e che alle tue credenziali IAM sia stato concesso il privilegio di utilizzo per il AWS Glue database.
GRANT USAGE ON DATABASEglue-databaseto "IAM:MyIAMUser"Il AWS Glue database è elencato nella scheda dell'editor di query v2, ma non è abilitato per la connessione diretta.
Per ulteriori informazioni sull'interrogazione di un AWS Glue Data Catalog, consulta Lavorare con le condivisioni di dati gestite da Lake Formation come consumatore e Lavorare con le condivisioni di dati gestite da Lake Formation come produttore nella Amazon Redshift Database Developer Guide.
Esempio di creazione di un database come utente di unità di condivisione dati
L'esempio seguente descrive uno scenario specifico utilizzato per creare un database da un'unità di condivisione dati utilizzando l'editor di query v2. Esamina questo scenario per scoprire come creare un database da un'unità di condivisione dati nel tuo ambiente. Questo scenario utilizza due cluster, cluster-base (il cluster produttori) e cluster-view (il cluster di consumatori).
Usa la console Amazon Redshift per creare una condivisione di dati per la tabella
category2nel clustercluster-base. L'unità di condivisione dati del produttore è denominatadatashare_base.Per ulteriori informazioni sulla creazione di unità di condivisione dati, consultare Condivisione dei dati tra cluster in Amazon Redshift nella Guida per gli sviluppatori di database di Amazon Redshift.
Usa la console Amazon Redshift per creare un'unità di condivisione dati
datashare_basecome consumatore per la tabellacategory2nel clustercluster-view.Visualizza il pannello di visualizzazione ad albero nell'editor di query v2 che mostra la gerarchia di
cluster-basecome:Cluster:
cluster-baseDatabase:
devSchema:
publicTabelle:
category2
Scegliere
Crea, quindi scegliere Database.Per Nome database, immettere
see_datashare_base.Seleziona Crea utilizzando una unità di condivisione dati e scegli Seleziona una unità di condivisione dati. Scegli
datashare_baseda utilizzare come origine del database che stai creando.Il pannello di visualizzazione ad albero nell'editor di query v2 mostra la gerarchia di
cluster-viewcome:Cluster:
cluster-viewDatabase:
see_datashare_baseSchema:
publicTabelle:
category2
Quando esegui una query sui dati, connettiti al database predefinito del cluster
cluster-view(tipicamente denominatodev), ma fai riferimento al database di unità di condivisione datisee_datashare_basenel tuo SQL.Nota
Nella vista dell'editor di query v2, il cluster selezionato è
cluster-view. Il database selezionato èdev. Il databasesee_datashare_baseè elencato ma non è abilitato per la connessione diretta. Tu scegli il databasedeve i riferimentisee_datashare_basenel codice SQL che esegui.SELECT * FROM "see_datashare_base"."public"."category2";La query recupera i dati dall'unità di condivisione dati
datashare_basenel clustercluster_base.
Esempio di creazione di un database da un AWS Glue Data Catalog
L'esempio seguente descrive uno scenario specifico utilizzato per creare un database da un editor di query AWS Glue Data Catalog using v2. Esamina questo scenario per scoprire come creare un database da un ambiente AWS Glue Data Catalog in uso. Questo scenario utilizza un cluster, cluster-view per contenere il database che crei.
Scegliere
Crea, quindi scegliere Database.Per Nome database, immettere
data_catalog_database.Seleziona Crea usando un AWS Glue Data Catalog e scegli Scegli un AWS Glue database. Scegli
glue_dbda utilizzare come origine del database che stai creando.Scegli Schema del catalogo dati e inserisci
myschemacome nome dello schema da utilizzare nella notazione in tre parti.Il pannello di visualizzazione ad albero nell'editor di query v2 mostra la gerarchia di
cluster-viewcome:Cluster:
cluster-viewDatabase:
data_catalog_databaseSchema:
myschemaTabelle:
category3
Quando esegui una query sui dati, connettiti al database predefinito del cluster
cluster-view(tipicamente denominatodev), ma fai riferimento al databasedata_catalog_databasenel tuo SQL.Nota
Nella vista dell'editor di query v2, il cluster selezionato è
cluster-view. Il database selezionato èdev. Il databasedata_catalog_databaseè elencato ma non è abilitato per la connessione diretta. Tu scegli il databasedeve i riferimentidata_catalog_databasenel codice SQL che esegui.SELECT * FROM "data_catalog_database"."myschema"."category3";L'interrogazione recupera i dati catalogati da AWS Glue Data Catalog.
Creazione di schemi
Puoi usare l'editor di query v2 per creare schemi nel tuo cluster o gruppo di lavoro.
Per creare uno schema
Per informazioni sugli schemi, consultare Schemi nella Guida per gli sviluppatori di database di Amazon Redshift.
Scegliere
Crea, quindi scegliere Schema.Inserire un Nome schema.
Scegliere Local (Locale) o External (Esterno) in Schema type (Tipo di schema).
Per ulteriori informazioni sugli schemi locali, consultare CREATE SCHEMA nella Guida per gli sviluppatori di database di Amazon Redshift. Per ulteriori informazioni sugli schemi esterni, consultare CREATE EXTERNAL SCHEMA nella Guida per gli sviluppatori di database di Amazon Redshift.
Se si sceglie External (Esterno), per lo schema esterno sono disponibili le seguenti opzioni.
Glue Data Catalog (Catalogo dati di Glue): per creare uno schema esterno in Amazon Redshift che faccia riferimento alle tabelle in AWS Glue. Oltre a scegliere il AWS Glue database, scegli il ruolo IAM associato al cluster e il ruolo IAM associato al Data Catalog.
PostgreSQL: per creare uno schema esterno in Amazon Redshift riferito a un database Amazon RDS per PostgreSQL o a un database compatibile con Amazon Aurora PostgreSQL. Specificare inoltre le informazioni sulla connessione al database. Per ulteriori informazioni sulle query federate, consultare Esecuzione di query su dati con query federate nella Guida per gli sviluppatori di database di Amazon Redshift.
MySQL: per creare uno schema esterno in Amazon Redshift riferito a un database Amazon RDS per MySQL o a un database compatibile con Amazon Aurora MySQL. Specificare inoltre le informazioni sulla connessione al database. Per ulteriori informazioni sulle query federate, consultare Esecuzione di query su dati con query federate nella Guida per gli sviluppatori di database di Amazon Redshift.
Scegliere Crea schema.
Il nuovo schema viene visualizzato nel pannello con visualizzazione ad albero.
Creazione di tabelle
Puoi usare l'editor di query v2 per creare tabelle nel tuo cluster o gruppo di lavoro.
Per creare una tabella
È possibile creare una tabella basata su un file CSV (valori separati da virgole) in cui è possibile specificare o definire ogni colonna della tabella. Per informazioni sulle tabelle, consultare Progettazione tabelle e CREA TABELLA nella Guida per gli sviluppatori di database di Amazon Redshift.
Scegliere Apri query nell'editor per visualizzare e modificare l'istruzione CREA TABELLA prima di eseguire la query per creare la tabella.
Scegli
Create (Crea) e quindi Table (Tabella).Scegliere uno schema.
Inserire un nome tabella.
Scegliere
Aggiungi campo per aggiungere una colonna. Utilizzare un file CSV come modello per la definizione della tabella:
Scegliere Carica da CSV.
Seleziona la posizione del file.
Se si utilizza un file CSV, assicurarsi che la prima riga del file contenga le intestazioni di colonna.
Scegli il file e scegli Apri. Confermare che i nomi delle colonne e i tipi di dati corrispondano a quanto voluto.
Per ogni colonna, scegli la colonna e scegli le opzioni desiderate:
Scegliere un valore per Codifica.
Scegliere un Valore predefinito.
Attivare Incremento automatico se si desidera che i valori delle colonne vengano incrementati. Quindi specificare un valore per Auto-incremento del seed e Fase di incremento automatico.
Attivare Non NULL se la colonna deve sempre contenere un valore.
Inserire un valore Dimensione per la colonna.
Attivare Chiave primaria se si desidera che la colonna sia una chiave primaria.
Attivare Chiave unica se si desidera che la colonna sia una chiave unica.
(Facoltativo) Scegliere Dettagli tabella e scegliere una qualsiasi delle seguenti opzioni:
Colonna e stile della chiave di distribuzione.
Colonna chiave di ordinamento e tipo di ordinamento.
Attiva Backup per includere la tabella negli snapshot.
Attivare Tabella temporanea per creare la tabella come tabella temporanea.
Scegliere Apri query nell'editor per continuare a specificare le opzioni per definire la tabella o scegliere Crea tabella per creare la tabella.
Creazione di funzioni
Puoi usare l'editor di query v2 per creare funzioni nel tuo cluster o gruppo di lavoro.
Per creare una funzione
Scegliere
Crea e scegliere Funzione.Per Tipo, scegliere SQL o Python.
Scegliere un valore per Schema.
Inserire un valore Nome per la funzione.
Inserire un valore Volatilità per la funzione.
Scegliere i Parametri in base ai loro tipi di dati nell'ordine dei parametri di input.
Per Valori restituiti, scegliere un tipo di dati.
Inserisci il codice Programma SQL o Programma Python per la funzione.
Scegli Crea.
Per ulteriori informazioni sulle funzioni definite dall'utente (UDF), consultare Creazione di funzioni definite dall'utente nella Guida per sviluppatori di database di Amazon Redshift.
Visualizzazione della cronologia delle query e delle schede
Puoi visualizzare la cronologia delle query con l'editor di query v2. Nella cronologia delle query vengono visualizzate solo le query eseguite utilizzando l'editor di query v2. Vengono visualizzate entrambe le query eseguite utilizzando una scheda Editor o una scheda Notebook. È possibile filtrare l'elenco visualizzato in base a un periodo di tempo, ad esempio This week, in cui una settimana è definita come lunedì-domenica. L'elenco delle query recupera contemporaneamente 25 righe di query che corrispondono al filtro in uso. Scegli Load more (Carica altro) per vedere il set successivo. Scegli una query e dal menu Actions (Operazioni). Le operazioni disponibili dipendono dal fatto se la query selezionata è stata salvata o meno. È possibile effettuare le seguenti operazioni:
View query details (Visualizza dettagli della query): visualizza una pagina dei dettagli della query con ulteriori informazioni sulla query eseguita.
Open query in a new tab (Apri query in una nuova scheda): apre una nuova scheda dell'editor e la prepara con la query scelta. Se ancora connessi, il cluster o il gruppo di lavoro e il database vengono selezionati automaticamente. Per eseguire la query, verifica innanzitutto che siano stati scelti il cluster o il gruppo di lavoro e il database corretti.
Open source tab (Apri scheda origine): se è ancora aperta, passa alla scheda dell'editor o del notebook che conteneva la query quando è stata eseguita. Il contenuto dell'editor o del notebook potrebbe essere cambiato dopo l'esecuzione della query.
Open saved query (Apri la query salvata): passa alla scheda dell'editor o del notebook e apre la query.
È inoltre possibile visualizzare la cronologia delle query eseguite in una scheda Editor o la cronologia delle query eseguite in una scheda Notebook. Per visualizzare la cronologia delle query in una scheda, scegliere Tab history (Cronologia scheda). Nella cronologia della scheda, puoi effettuare le operazioni elencate di seguito:
Copy query (Copia query): copia il contenuto SQL della versione della query negli appunti.
Open query in a new tab (Apri query in una nuova scheda): apre una nuova scheda dell'editor e la prepara con la query scelta. Per eseguire la query, è necessario scegliere il cluster o il gruppo di lavoro e il database.
View query details (Visualizza dettagli della query): visualizza una pagina dei dettagli della query con ulteriori informazioni sulla query eseguita.
Considerazioni sull'utilizzo dell'editor di query v2
Considera quanto segue quando utilizzi l'editor di query v2.
La dimensione massima del risultato della query è la più piccola di 5 MB o 100.000 righe.
È possibile eseguire una query contenente fino a 300 mila caratteri.
È possibile salvare una query contenente fino a 30 mila caratteri.
Per impostazione predefinita, l'editor di query v2 esegue automaticamente il commit di ogni singolo comando SQL eseguito. Quando viene fornita un'istruzione BEGIN, le istruzioni all'interno del blocco BEGIN-COMMIT o BEGIN-ROLLBACK vengono eseguite come una singola transazione. Per ulteriori informazioni sulle transazioni, consultare BEGIN nella Guida per gli sviluppatori di database di Amazon Redshift.
Il numero massimo di avvisi che l'editor di query v2 visualizza durante l'esecuzione di un'istruzione SQL è
10. Ad esempio, quando viene eseguita una stored procedure, non vengono visualizzate più di 10 istruzioni RAISE.L'editor di query v2 non supporta un IAM
RoleSessionNameche contiene virgole (,). Potresti visualizzare un errore simile al seguente:Messaggio di errore: «'AROA123456789Example:myText, yourtext' non è un valore valido per TagValue - contiene caratteri non validi» Questo problema si verifica quando si definisce un IAM cheinclude una virgola e quindi si utilizza l'editor di query v2 con quel ruolo IAM.RoleSessionName
Modifica delle impostazioni dell'account
Un utente con le autorizzazioni IAM adeguate può visualizzare e modificare le opzioni selezionate in Account settings (Impostazioni account) per gli altri utenti nello stesso Account AWS. L'amministratore può visualizzare o impostare quanto segue:
Il numero massimo di connessioni simultanee al database per utente nell'account. Sono incluse le connessioni per le sessioni isolate. Quando si modifica questo valore, possono essere necessari 10 minuti per rendere effettiva la modifica.
La possibilità da parte degli utenti nell'account di esportare un intero set di risultati da un comando SQL a un file.
La possibilità di caricare e visualizzare i database di esempio con alcune query salvate associate.
Specifica un percorso Amazon S3 utilizzato dagli utenti dell'account per caricare i dati da un file locale.
La possibilità di visualizzare l'ARN della chiave KMS per crittografare le risorse dell'editor di query v2.
