Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Visualizza un rapporto sulle prestazioni del modello Autopilot
Un report sulla qualità del modello Amazon SageMaker AI (noto anche come rapporto sulle prestazioni) fornisce approfondimenti e informazioni sulla qualità per il miglior modello candidato generato da un job di AutoML. Ciò include informazioni sui dettagli del processo, sul tipo di problema del modello, sulla funzione dell'obiettivo e altre informazioni relative al tipo di problema. Questa guida mostra come visualizzare graficamente i parametri delle prestazioni di Amazon SageMaker Autopilot o come dati grezzi in un file JSON.
Ad esempio, nei problemi di classificazione, il report sulla qualità del modello include quanto segue:
-
Matrice di confusione
-
Area sotto la curva caratteristica operativa del ricevitore (AUC)
-
Informazioni per comprendere falsi positivi e falsi negativi
-
Compromessi tra veri positivi e falsi positivi
-
Compromessi tra precisione e recupero
Autopilot fornisce anche parametri prestazionali per tutti i modelli candidati. Questi parametri vengono calcolati utilizzando tutti i dati di addestramento e vengono utilizzati per stimare le prestazioni del modello. L'area di lavoro principale include questi parametri per impostazione predefinita. Il tipo di parametro è determinato dal tipo di problema da risolvere.
Consulta la documentazione di riferimento dell' SageMaker API Amazon per l'elenco delle metriche disponibili supportate da Autopilot.
Puoi ordinare i tuoi modelli candidati in base al parametro pertinente per aiutarti a selezionare e implementare il modello più adatto alle tue esigenze aziendali. Per le definizioni di questi parametri, consulta l'argomento Parametri dei candidati Autopilot.
Per visualizzare un report sulle prestazioni di un processo di Autopilot, completa la seguente procedura:
-
Scegli l'icona Home (
 ) dal riquadro di navigazione a sinistra per visualizzare il menu di navigazione Amazon SageMaker Studio Classic di primo livello.
) dal riquadro di navigazione a sinistra per visualizzare il menu di navigazione Amazon SageMaker Studio Classic di primo livello. -
Seleziona la scheda AutoML dall'area di lavoro principale. Si aprirà una nuova scheda Autopilot.
-
Nella sezione Nome, seleziona il processo di Autopilot contenente i dettagli che desideri esaminare. Si aprirà una nuova scheda Processo di Autopilot.
-
Il pannello di Processo di Autopilot elenca i valori dei parametri, incluso il parametro Obiettivo, per ogni modello in Nome modello. Il Modello migliore è elencato in cima all'elenco sotto Nome modello ed è evidenziato nella scheda Modelli.
-
Per esaminare i dettagli del modello, seleziona quello che ti interessa e seleziona Visualizza i dettagli del modello. Si aprirà una nuova scheda Dettagli del modello.
-
-
Sceglie la scheda Prestazioni tra la scheda Spiegabilità e Artefatti.
-
Nella sezione in alto a destra della scheda, seleziona la freccia rivolta verso il basso sul pulsante Scarica i report sulle prestazioni.
-
La freccia rivolta verso il basso offre due opzioni per visualizzare i parametri delle prestazioni di Autopilot:
-
È possibile scaricare un PDF del report sulle prestazioni per visualizzare i parametri graficamente.
-
È possibile visualizzare i parametri come dati grezzi e scaricarli come file JSON.
-
-
Per istruzioni su come creare ed eseguire un processo AutoML in SageMaker Studio Classic, vedere. Crea lavori di regressione o classificazione per dati tabulari utilizzando l'API AutoML
Il report sulle prestazioni contiene due sezioni. La prima sezione contiene dettagli sul processo di Autopilot che ha prodotto il modello. La seconda sezione contiene un report sulla qualità del modello.
Dettagli del processo di Autopilot
Questa prima sezione del report fornisce alcune informazioni generali sul processo di Autopilot che ha prodotto il modello. Questi dettagli del processo includono le seguenti informazioni:
-
Nome del candidato Autopilot
-
Nome del processo di Autopilot
-
Tipo di problema
-
Parametro obiettivo
-
Direzione dell'ottimizzazione
Report sulla qualità del modello
Le informazioni sulla qualità del modello vengono generate dalle informazioni del modello Autopilot. Il contenuto del report generato dipende dal tipo di problema risolto: regressione, classificazione binaria o classificazione multiclasse. Il report specifica il numero di righe incluse nel set di dati di valutazione e l'ora in cui è avvenuta la valutazione.
Tabelle di parametri
La prima parte del report sulla qualità del modello contiene le tabelle dei parametri. Questi sono i parametri appropriati per il tipo di problema risolto dal modello.
L'immagine seguente è un esempio di tabella di parametri generata da Autopilot per un problema di regressione. Mostra il nome, il valore e la deviazione standard del parametro.

L'immagine seguente è un esempio di tabella dei parametri generata da Autopilot per un problema di classificazione di classificazione multiclasse. Mostra il nome, il valore e la deviazione standard del parametro.

Informazioni sulle prestazioni del modello grafico
La seconda parte del report sulla qualità del modello contiene informazioni grafiche per aiutarti a valutare le prestazioni del modello. Il contenuto di questa sezione dipende dal tipo di problema utilizzato nella modellazione.
L'area sotto la curva caratteristica operativa del ricevitore
L'area sotto la curva delle caratteristiche operative del ricevitore rappresenta il compromesso tra valori veri positivi e falsi positivi. È un parametro di precisione standard del settore utilizzato per i modelli di classificazione binaria. L'AUC (area sotto la curva) misura la capacità del modello di prevedere un punteggio più elevato per gli esempi positivi rispetto a quelli negativi. Il parametro AUC fornisce una misura aggregata delle prestazioni del modello in tutte le possibili soglie di classificazione.
Il parametro AUC restituisce un valore decimale compreso tra 0 e 1. I valori di AUC prossimi a 1 indicano che il modello di machine learning è estremamente accurato. I valori vicino a 0,5 indicano che il modello non ha prestazioni migliori di quelle di un'ipotesi casuale. I valori AUC prossimi allo 0 indicano che il modello ha appreso i modelli corretti, ma sta facendo previsioni il più imprecise possibile. Valori prossimi allo zero possono indicare un problema con i dati. Per ulteriori informazioni sui parametri AUC, consultare l'articolo Receiver operating characteristic
Di seguito è riportato un esempio di un'area sotto il grafico della curva caratteristica operativa del ricevitore per valutare le previsioni fatte da un modello di classificazione binaria. La linea sottile tratteggiata rappresenta l'area sotto la curva caratteristica operativa del ricevitore ottenuta da un modello che classifica le no-better-than-random ipotesi, con un punteggio AUC di 0,5. Le curve dei modelli di classificazione più accurati si collocano al di sopra di questa linea di base casuale, in cui il valore di veri positivi supera il valore di falsi positivi. L'area sotto la curva caratteristica operativa del ricevitore che rappresenta le prestazioni del modello di classificazione binaria è la linea continua più spessa.

Un riepilogo dei componenti del grafico della percentuale di falsi positivi (FPR) e della percentuale di veri positivi (TPR) è definito come segue.
-
Previsioni corrette
-
True positive (TP): il valore previsto è 1 e il valore vero è 1.
-
Vero negativo (TN): il valore previsto è 0 e il valore vero è 0.
-
-
Previsioni errate
-
Falso positivo (FP): il valore previsto è 1, ma il valore vero è 0.
-
Falso negativo (FN): il valore previsto è 0, ma il valore vero è 1.
-
Il tasso di falsi positivi (FPR, false positive rate) misura la frazione di veri negativi (TN) erroneamente previsti come positivi (FP), rispetto alla somma di FP e TN. L'intervallo è compreso tra 0 e 1. Un valore minore indica una migliore accuratezza predittiva.
-
FPR = FP/(FP+TN)
Il tasso di veri positivi (TPR) misura la frazione di veri positivi correttamente previsti come positivi (TP) rispetto alla somma di TP e falsi negativi (FN). L'intervallo è compreso tra 0 e 1. Un valore maggiore indica una migliore accuratezza predittiva.
-
TPR = TP/(TP+FN)
Matrice di confusione
Una matrice di confusione consente di visualizzare l'accuratezza delle previsioni fatte da un modello per la classificazione binaria e multiclasse per diversi problemi. La matrice di confusione nel report sulla qualità del modello contiene quanto segue.
-
Il numero e la percentuale di previsioni corrette ed errate per le etichette effettive
-
Il numero e la percentuale di previsioni accurate sulla diagonale dall'angolo superiore sinistro a quello inferiore destro
-
Il numero e la percentuale di previsioni imprecise sulla diagonale dall'angolo superiore destro a quello inferiore sinistro
Le previsioni errate su una matrice di confusione sono i valori di confusione.
Il diagramma seguente è un esempio di matrice binaria per un problema di classificazione multiclasse. Contiene le seguenti informazioni:
-
L'asse verticale è diviso in due righe contenenti etichette effettive vere e false.
-
L'asse orizzontale è diviso in due colonne contenenti le etichette vero e falso previste dal modello.
-
La barra dei colori assegna una tonalità più scura a un numero maggiore di campioni per indicare visivamente il numero di valori classificati in ciascuna categoria.
In questo esempio, il modello ha previsto correttamente 2.817 valori falsi effettivi e 353 valori veri effettivi. Il modello prevedeva erroneamente che 130 valori veri effettivi fossero falsi e 33 valori falsi effettivi fossero veri. La differenza di tono indica che il set di dati non è bilanciato. Lo squilibrio è dovuto al fatto che ci sono molte più etichette false effettive rispetto alle etichette vere.

Il diagramma seguente è un esempio di matrice di confusione per un problema di classificazione multiclasse. La matrice di confusione nel report sulla qualità del modello contiene quanto segue.
-
L'asse verticale è diviso in tre righe contenenti tre diverse etichette effettive.
-
L'asse orizzontale è diviso in tre colonne contenenti le etichette previste dal modello.
-
La barra dei colori assegna una tonalità più scura a un numero maggiore di campioni per indicare visivamente il numero di valori classificati in ciascuna categoria.
Nell'esempio seguente, il modello ha previsto correttamente 354 valori effettivi per l'etichetta f, 1094 valori per l'etichetta i e 852 valori per l'etichetta m. La differenza di tonalità indica che il set di dati non è bilanciato perché ci sono molte più etichette per il valore i che per f o m.

La matrice di confusione contenuta nel report sulla qualità del modello fornito può contenere un massimo di 15 etichette per tipi di problemi di classificazione multiclasse. Se una riga corrispondente a un'etichetta mostra un valore Nan, significa che il set di dati di convalida utilizzato per verificare le previsioni del modello non contiene dati con quell'etichetta.
Curva di guadagno
Nella classificazione binaria, una curva di guadagno prevede il vantaggio cumulativo derivante dall'utilizzo di una percentuale del set di dati per trovare un'etichetta positiva. Il valore del guadagno viene calcolato durante l'addestramento dividendo il numero cumulativo di osservazioni positive per il numero totale di osservazioni positive nei dati, per ogni decile. Se il modello di classificazione creato durante l'addestramento è rappresentativo dei dati invisibili, è possibile utilizzare la curva di guadagno per prevedere la percentuale di dati da utilizzare come target per ottenere una percentuale di etichette positive. Maggiore è la percentuale del set di dati utilizzato e maggiore sarà la percentuale di etichette positive trovate.
Nel seguente grafico di esempio, la curva di guadagno è la linea con la variazione della pendenza. La linea retta è la percentuale di etichette positive trovate selezionando casualmente una percentuale di dati dal set di dati. Se scegli come target il 20% del set di dati, ti aspetteresti di trovare più del 40% delle etichette positive. Ad esempio, potresti prendere in considerazione l'utilizzo di una curva di guadagno per determinare i tuoi sforzi in una campagna di marketing. Utilizzando il nostro esempio di curva di guadagno, se l'83% delle persone di un quartiere acquistasse biscotti, invieresti un annuncio a circa il 60% del quartiere.

Curva di sollevamento
Nella classificazione binaria, la curva di sollevamento illustra l'aumento derivante dall'utilizzo di un modello addestrato per prevedere la probabilità di trovare un'etichetta positiva rispetto a un'ipotesi casuale. Il valore di sollevamento viene calcolato durante l'addestramento utilizzando il report tra il guadagno percentuale e il report delle etichette positive per ogni decile. Se il modello creato durante l'addestramento è rappresentativo dei dati invisibili, utilizza la curva di sollevamento per prevedere i vantaggi derivanti dall'utilizzo del modello rispetto alle ipotesi casuali.
Nel seguente grafico di esempio, la curva di sollevamento è la linea con la variazione della pendenza. La linea retta è la curva di sollevamento associata alla selezione casuale della percentuale corrispondente dal set di dati. Se hai scelto come target il 40% del set di dati con le etichette di classificazione del modello, ti aspetteresti di trovare circa 1,7 volte il numero di etichette positive che avresti trovato selezionando casualmente il 40% dei dati non visibili.

Curva di richiamo di precisione
La curva di richiamo di precisione rappresenta il compromesso tra precisione e richiamo per problemi di classificazione binaria.
La precisione misura la frazione di risultati positivi effettivi previsti come positivi (TP) tra tutte le previsioni positive (TP e falsi positivi). L'intervallo è compreso tra 0 e 1. Un valore maggiore indica una maggiore accuratezza dei valori previsti.
-
Precisione = TP/ (TP+FP)
Recall misura la frazione di risultati positivi effettivi previsti come positivi (TP) rispetto a tutte le previsioni positive effettive (TP e falsi negativi). Questo valore è noto anche come sensibilità o tasso di veri positivi. L'intervallo è compreso tra 0 e 1. Un valore maggiore indica una migliore rilevazione dei valori positivi dal campione.
-
Richiamo = TP/(TP+FN)
L'obiettivo di un problema di classificazione è etichettare correttamente il maggior numero possibile di elementi. Un sistema con richiamo elevato ma bassa precisione restituisce un'alta percentuale di falsi positivi.
L'immagine seguente mostra un filtro antispam che contrassegna ogni e-mail come spam. Il richiamo è elevato, ma la precisione è bassa, perché il richiamo non misura i falsi positivi.
Dai più peso al richiamo rispetto alla precisione se il tuo problema ha una bassa penalità per i valori falsi positivi, ma un'alta penalità per la mancanza di un risultato vero positivo. Ad esempio, il rilevamento di una collisione imminente in un veicolo a guida autonoma.

Al contrario, un sistema con elevata precisione, ma con basso richiamo, restituisce un'alta percentuale di falsi negativi. Un filtro antispam che contrassegna ogni e-mail come desiderata (non spam) ha un'elevata precisione ma un basso livello di richiamo perché la precisione non misura i falsi negativi.
Se il tuo problema ha una bassa penalità per i valori falsi negativi, ma un'alta penalità per la mancanza di un risultato vero negativo, dai più peso alla precisione rispetto al richiamo. Ad esempio, segnalando un filtro sospetto per un controllo fiscale.
L'immagine seguente mostra un filtro antispam con elevata precisione ma scarso richiamo, poiché la precisione non misura i falsi negativi.

Un modello che effettua previsioni con elevata precisione e richiamo elevato produce un numero elevato di risultati etichettati correttamente. Per ulteriori informazioni, consulta l'articolo Precisione e recupero
Area sotto la curva di richiamo di precisione (AUPRC)
Per problemi di classificazione binaria, Amazon SageMaker Autopilot include un grafico dell'area sotto la curva di richiamo di precisione (AUPRC). Il parametro AUPRC fornisce una misura aggregata delle prestazioni del modello in tutte le possibili soglie di classificazione e utilizza sia la precisione che il richiamo. AUPRC non tiene conto del numero di veri aspetti negativi. Pertanto, può essere utile valutare le prestazioni del modello nei casi in cui i dati contengano un gran numero di veri aspetti negativi. Ad esempio, per modellare un gene contenente una mutazione rara.
L'immagine seguente è un esempio di grafico AUPRC. La precisione al suo valore massimo è 1 e il richiamo è 0. Nell'angolo inferiore destro del grafico, il richiamo è il valore più alto (1) e la precisione è 0. Tra questi due punti, la curva AUPRC illustra il compromesso tra precisione e richiamo a soglie diverse.

Grafico effettivo rispetto a quello previsto
Il grafico effettivo rispetto a quello previsto mostra la differenza tra i valori del modello effettivi e quelli previsti. Nel seguente grafico di esempio, la linea continua è una linea lineare che si adatta meglio. Se il modello fosse accurato al 100%, ogni punto previsto corrisponderebbe al punto effettivo corrispondente e si troverebbe su questa linea di miglior adattamento. La distanza dalla linea di miglior adattamento è un'indicazione visiva dell'errore del modello. Maggiore è la distanza dalla linea di miglior adattamento, maggiore è l'errore del modello.

Grafico residuo standardizzato
Un grafico residuo standardizzato incorpora i seguenti termini statistici:
residual-
Un residuo (grezzo) mostra la differenza tra i valori effettivi e quelli previsti dal modello. Maggiore è la differenza, maggiore è il valore residuo.
standard deviation-
La deviazione standard è una misura di come i valori variano da un valore medio. Una deviazione standard elevata indica che molti valori sono molto diversi dal loro valore medio. Una deviazione standard bassa indica che molti valori sono vicini al loro valore medio.
standardized residual-
Un residuo standardizzato divide i residui grezzi per la loro deviazione standard. I residui standardizzati hanno unità di deviazione standard e sono utili per individuare valori anomali nei dati indipendentemente dalla differenza di scala dei residui grezzi. Se un residuo standardizzato è molto più piccolo o più grande degli altri residui standardizzati, significa che il modello non si adatta bene a queste osservazioni.
Il grafico residuo standardizzato misura l'intensità della differenza tra i valori osservati e quelli previsti. Il valore effettivo previsto viene visualizzato sull'asse x. Un punto con un valore maggiore di un valore assoluto di 3 viene generalmente considerato un valore anomalo.
Il seguente grafico di esempio mostra che un gran numero di residui standardizzati sono raggruppati attorno allo 0 sull'asse orizzontale. I valori vicini allo zero indicano che il modello si adatta bene a questi punti. I punti verso la parte superiore e inferiore del grafico non sono previsti correttamente dal modello.

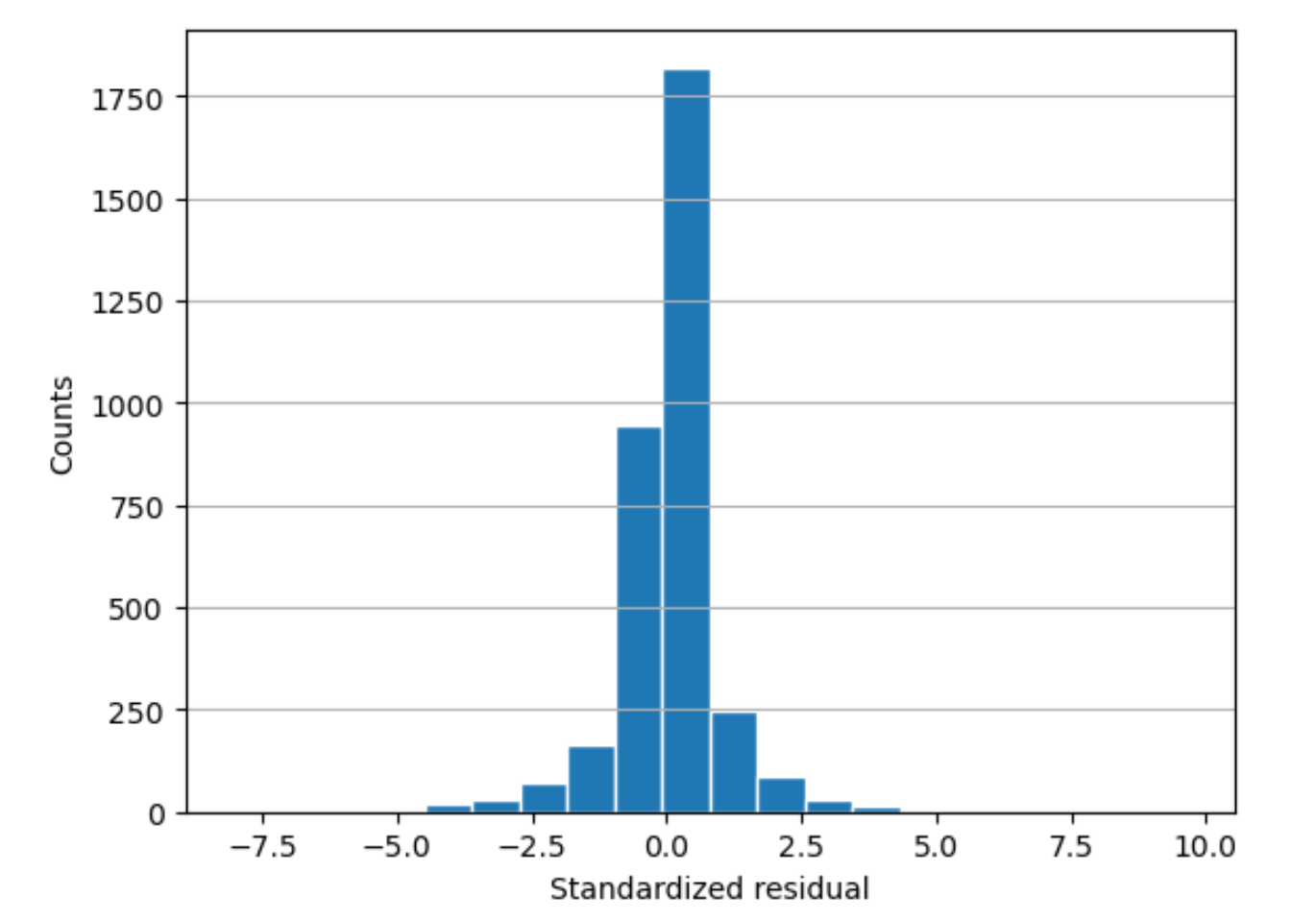
Istogramma residuo
Un istogramma residuo incorpora i seguenti termini statistici:
residual-
Un residuo (grezzo) mostra la differenza tra i valori effettivi e quelli previsti dal modello. Maggiore è la differenza, maggiore è il valore residuo.
standard deviation-
La deviazione standard è una misura di quanto i valori variano da un valore medio. Una deviazione standard elevata indica che molti valori sono molto diversi dal loro valore medio. Una deviazione standard bassa indica che molti valori sono vicini al loro valore medio.
standardized residual-
Un residuo standardizzato divide i residui grezzi per la loro deviazione standard. I residui standardizzati hanno unità di deviazione standard. Sono utili per individuare valori anomali nei dati indipendentemente dalla differenza di scala dei residui grezzi. Se un residuo standardizzato è molto più piccolo o più grande degli altri residui standardizzati, indicherebbe che il modello non si adatta bene a queste osservazioni.
histogram-
Un istogramma è un grafico che mostra la frequenza con cui si è verificato un valore.
L'istogramma residuo mostra la distribuzione dei valori residui standardizzati. Un istogramma distribuito a campana e centrato su zero indica che il modello non prevede o non prevede sistematicamente un particolare intervallo di valori target.
Nel grafico seguente, i valori residui standardizzati indicano che il modello si adatta bene ai dati. Se il grafico mostrasse valori lontani dal valore centrale, indicherebbe che tali valori non si adattano bene al modello.