Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Endpoint multi-modello
Gli endpoint a più modelli offrono una soluzione scalabile ed economica per la distribuzione di un numero elevato di modelli. Utilizzano lo stesso parco di risorse e un container di servizio condiviso per l’hosting di tutti i tuoi modelli. Questa caratteristica riduce i costi di hosting migliorando l'utilizzo degli endpoint rispetto all'utilizzo di endpoint a singolo modello. Riduce anche il sovraccarico di implementazione perché Amazon SageMaker AI gestisce il caricamento dei modelli in memoria e il loro ridimensionamento in base ai modelli di traffico verso l'endpoint.
Il diagramma seguente mostra come funzionano gli endpoint a più modelli rispetto agli endpoint a modello singolo.
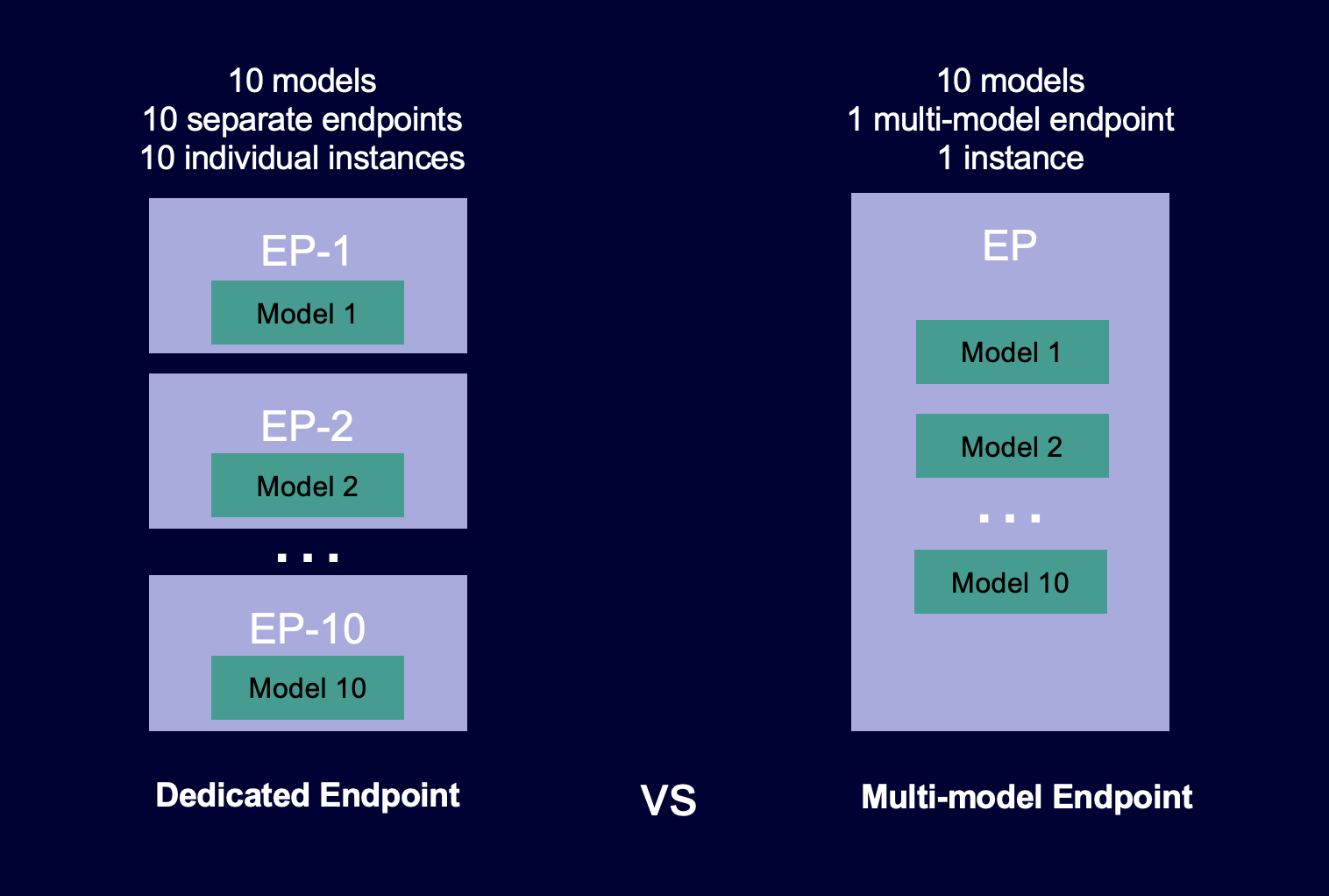
Gli endpoint a più modelli sono ideali per ospitare un gran numero di modelli che utilizzano lo stesso framework ML su un container di servizio condiviso. Se hai un mix di modelli con accesso frequente e non, un endpoint multi-modello può servire in modo efficiente questo traffico con meno risorse e maggiori risparmi. L'applicazione deve tollerare le occasionali penalità di latenza legate all'avvio a freddo che si verificano quando si richiamano modelli utilizzati di rado.
Gli endpoint a più modelli supportano l'hosting di modelli basati su CPU e GPU. Utilizzando modelli basati su GPU, è possibile ridurre i costi di implementazione del modello attraverso un maggiore utilizzo dell'endpoint e delle relative istanza a calcolo accelerato.
Gli endpoint a più modelli consentono inoltre la condivisione temporale delle risorse della memoria tra i modelli. Questo comportamento funziona meglio quando i modelli sono abbastanza simili per dimensioni e latenza di invocazione. In questo caso, gli endpoint a più modelli possono utilizzare in modo efficace le istanze in tutti i modelli. Se hai modelli con transazioni al secondo (TPS) o requisiti di latenza significativamente più elevati, è consigliabile ospitarli su endpoint dedicati.
È possibile utilizzare endpoint a più modelli con le seguenti funzionalità:
-
AWS PrivateLinke VPCs
-
Pipeline di inferenza seriali (ma solo un container a più modelli può essere incluso in una pipeline di inferenza)
-
Test A/B
Puoi utilizzare AWS SDK for Python (Boto) o la console SageMaker AI per creare un endpoint multimodello. Per gli endpoint a più modelli supportati dalla CPU, puoi creare endpoint con container personalizzati integrando la libreria Multi Model Server
Argomenti
Algoritmi, framework e istanze supportati per endpoint multimodello
Raccomandazioni sulle istanze per le distribuzioni di endpoint a più modelli
Crea il tuo contenitore per gli endpoint multimodello di intelligenza artificiale SageMaker
CloudWatch Metriche per le implementazioni di endpoint multimodello
Imposta le Policy di dimensionamento automatico per le implementazioni di endpoint a più modelli
Come funzionano gli endpoint a più modelli
SageMaker L'intelligenza artificiale gestisce il ciclo di vita dei modelli ospitati su endpoint multimodello nella memoria del contenitore. Invece di scaricare tutti i modelli da un bucket Amazon S3 nel contenitore quando crei l'endpoint, l' SageMaker intelligenza artificiale li carica e li memorizza nella cache dinamicamente quando li richiami. Quando l' SageMaker IA riceve una richiesta di invocazione per un particolare modello, esegue le seguenti operazioni:
-
Instrada la richiesta a un'istanza dietro l'endpoint.
-
Scarica il modello dal bucket S3 nel volume di storage di tale istanza.
-
Carica il modello nella memoria del container (CPU o GPU, a seconda che siano presenti istanze supportate da CPU o GPU) su quella istanza a calcolo accelerato. Se il modello è già caricato nella memoria del contenitore, l'invocazione è più veloce perché l' SageMaker IA non ha bisogno di scaricarlo e caricarlo.
SageMaker L'IA continua a indirizzare le richieste di un modello all'istanza in cui il modello è già caricato. Tuttavia, se il modello riceve molte richieste di chiamata e sono presenti istanze aggiuntive per l'endpoint multimodello, l' SageMaker IA indirizza alcune richieste a un'altra istanza per soddisfare il traffico. Se il modello non è già caricato nella seconda istanza, viene scaricato nel volume di storage dell'istanza e caricato nella memoria del container.
Quando l'utilizzo della memoria di un'istanza è elevato e l' SageMaker intelligenza artificiale deve caricare un altro modello in memoria, scarica i modelli inutilizzati dal contenitore dell'istanza per garantire che ci sia abbastanza memoria per caricare il modello. I modelli scaricati rimangono sul volume di storage dell'istanza e possono essere caricati nella memoria del container in un secondo momento senza essere scaricati nuovamente dal bucket S3. Se il volume di archiviazione dell'istanza raggiunge la sua capacità, l' SageMaker IA elimina tutti i modelli inutilizzati dal volume di archiviazione.
Per eliminare un modello, interrompi l'invio di richieste ed eliminalo dal bucket S3. SageMaker L'intelligenza artificiale fornisce funzionalità endpoint multimodello in un contenitore di servizio. L'aggiunta e l'eliminazione di modelli da un endpoint a più modelli non richiede l'aggiornamento dell'endpoint. Per aggiungere un modello, caricalo nel bucket S3 e richiamalo. Per utilizzarlo non sono necessarie modifiche al codice.
Nota
Quando si aggiorna un endpoint a più modelli, le richieste di invocazione iniziali sull'endpoint potrebbero subire latenze più elevate poiché Smart Routing negli endpoint a più modelli si adatta al modello di traffico. Tuttavia, una appreso il modello di traffico, è possibile riscontrare basse latenze per i modelli utilizzati più di frequente. I modelli utilizzati meno frequentemente possono subire alcune latenze di avvio a freddo poiché i modelli vengono caricati dinamicamente su un'istanza.
Notebook di esempio per endpoint a più modelli
Per ulteriori informazioni su come utilizzare gli endpoint a più modelli, puoi provare i seguenti notebook di esempio:
-
Esempi di endpoint a più modelli che utilizzano istanze basate su CPU:
-
Notebook di XGBoost esempio per endpoint multimodello
: questo notebook mostra come implementare più XGBoost modelli su un endpoint. -
Notebook di esempio BYOC per endpoint multimodel: questo taccuino
mostra come configurare e implementare un container per il cliente che supporti gli endpoint multimodello nell'intelligenza artificiale. SageMaker
-
-
Esempio di endpoint a più modelli che utilizzano istanze basate su GPU:
-
Esegui più modelli di deep learning GPUs con Amazon SageMaker AI Multi-model endpoint (MME)
: questo notebook mostra come utilizzare un container NVIDIA Triton Inference per distribuire ResNet -50 modelli su un endpoint multimodello.
-
Per istruzioni su come creare e accedere a istanze di notebook Jupyter da utilizzare per eseguire gli esempi precedenti in AI, consulta. SageMaker Istanze SageMaker per notebook Amazon Dopo aver creato un'istanza di notebook e averla aperta, scegli la scheda Esempi SageMaker AI per visualizzare un elenco di tutti gli esempi di IA. SageMaker Il notebook per endpoint a più modelli si trova nella sezione FUNZIONALITÀ AVANZATA. Per aprire un notebook, seleziona la relativa scheda Utilizza e scegli Crea copia.
Per ulteriori informazioni sui casi d'uso per endpoint a più modelli, consulta i seguenti blog e risorse:
