OPS10-BP02 Definizione di un processo per ogni avviso
Stabilire un processo chiaro e definito per ogni avviso nel sistema è essenziale per una gestione degli incidenti efficace ed efficiente. Questa pratica garantisce che ogni avviso porti a una risposta specifica e attuabile, migliorando l'affidabilità e la reattività delle operazioni.
Risultato desiderato: ogni avviso avvia un piano di risposta specifico e ben definito. Ove possibile, le risposte sono automatizzate e dotate di una chiara titolarità e di un percorso di escalation definito. Gli avvisi sono collegati a una base di conoscenze aggiornata, in modo che qualsiasi operatore sia in grado di rispondere in modo coerente ed efficace. Le risposte sono rapide e uniformi su tutta la linea, migliorando l'efficienza e l'affidabilità operativa.
Anti-pattern comuni:
-
Gli avvisi non hanno un processo di risposta predefinito, il che porta a risoluzioni improvvisate e tardive.
-
Il sovraccarico di avvisi comporta che gli avvisi importanti vengano trascurati.
-
Gli avvisi vengono gestiti in modo incoerente a causa della mancanza di titolarità e responsabilità chiare.
Vantaggi dell'adozione di questa best practice:
-
Creazione solo di avvisi utilizzabili, con conseguente riduzione dell'affaticamento da avvisi.
-
Riduzione del tempo medio di risoluzione (MTTR) per problemi operativi.
-
Riduzione del tempo medio di indagine (MTTI), il che aiuta a ridurre l'MTTR.
-
Migliore capacità di scalare le risposte operative.
-
Maggiore coerenza e affidabilità nella gestione degli eventi operativi.
Ad esempio, disponi di un processo definito per gli eventi di AWS Health per gli account critici, compresi gli allarmi delle applicazioni, i problemi operativi e gli eventi del ciclo di vita pianificati (come l'aggiornamento delle versioni di Amazon EKS prima dell'aggiornamento automatico dei cluster) e fornisci ai team la possibilità di monitorare attivamente, comunicare e rispondere a questi eventi. Queste azioni aiutano a prevenire le interruzioni del servizio causate da modifiche lato AWS o a mitigarle più rapidamente quando si verificano problemi imprevisti.
Livello di rischio associato se questa best practice non fosse adottata: elevato
Guida all'implementazione
Avere un processo per ogni avviso implica stabilire un piano di risposta chiaro per ciascun avviso, automatizzare le risposte ove possibile e perfezionare continuamente questi processi in base al feedback operativo e all'evoluzione dei requisiti.
Passaggi dell'implementazione
Il diagramma seguente illustra il flusso di lavoro di gestione degli incidenti all'interno di Strumento di gestione degli incidenti AWS Systems Manager
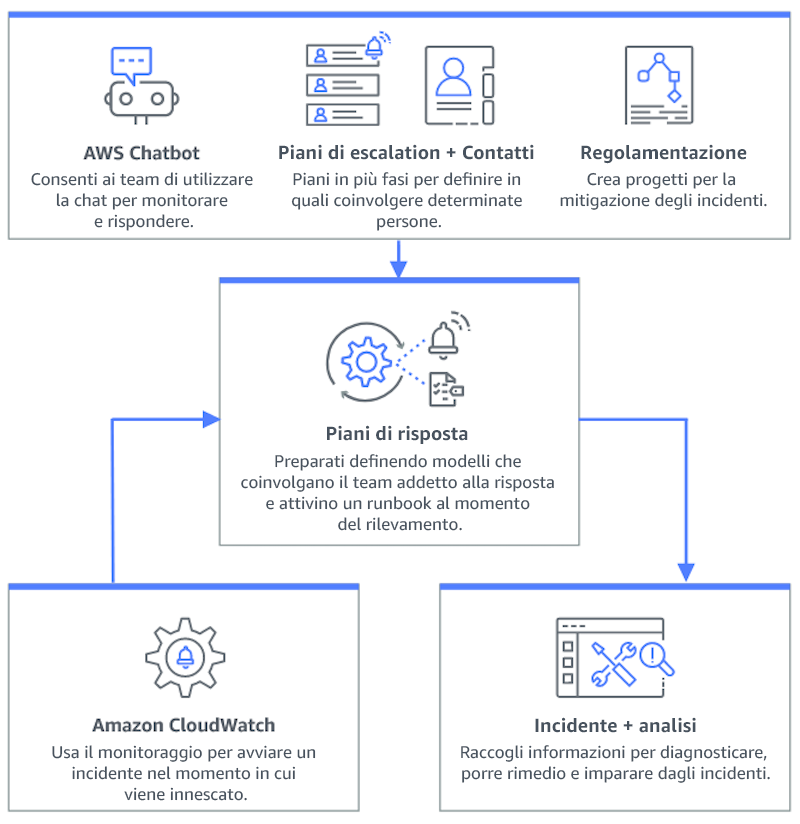
-
Utilizza allarmi compositi: crea allarmi compositi in CloudWatch per raggruppare allarmi correlati, così da ridurre il rumore e consentire risposte più significative.
-
Resta aggiornato con AWS Health: AWS Health è la fonte autorevole di informazioni sull'integrità delle risorse Cloud AWS. Utilizza AWS Health per visualizzare e ricevere notifiche su eventuali eventi di servizio in corso e modifiche imminenti, come gli eventi pianificati del ciclo di vita, in modo da poter adottare misure per mitigare gli impatti.
-
Crea notifiche di eventi AWS Health personalizzati per i canali e-mail e chat con Notifiche all'utente AWS e integra a livello di codice con gli strumenti di monitoraggio e avviso di Amazon EventBridge o l'AWS Health API.
-
Pianifica e monitora i progressi relativi agli eventi sull'integrità che richiedono un'azione integrando con strumenti di gestione delle modifiche o ITSM (come Jira ServiceNow) che potresti già utilizzare tramite Amazon EventBridge o l'API AWS Health.
-
Se utilizzi AWS Organizations, abilita la visualizzazione dell'organizzazione per AWS Health per aggregare gli eventi AWS Health tra gli account.
-
-
Integra gli allarmi di Amazon CloudWatch con lo strumento di gestione degli incidenti: configura gli allarmi di CloudWatch per la creazione automatica di incidenti in Strumento di gestione degli incidenti AWS Systems Manager.
-
Integra Amazon EventBridge con Incident Manager: crea regole EventBridge in modo da reagire agli eventi e creare incidenti mediante piani di risposta definiti.
-
Preparati per gli incidenti in Incident Manager:
-
Crea piani di risposta dettagliati in Incident Manager per ciascun tipo di avviso.
-
Stabilisci canali di chat tramite Amazon Q Developer nelle applicazioni di chat collegato ai piani di risposta nello strumento di gestione degli incidenti, semplificando la comunicazione in tempo reale durante gli incidenti su piattaforme come Slack, Microsoft Teams e Amazon Chime.
-
Integra i runbook di Systems Manager Automation in Incident Manager per fornire risposte automatiche agli incidenti.
-
Risorse
Best practice correlate:
Documenti correlati:
Video correlati:
Esempi correlati:
