This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
MySQL backups
Backup methodologies
There are several approaches to protecting your MySQL data depending on your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements. The choice of performing a hot or cold backup is based on the uptime requirement of the database. When it comes meeting your RPO, your backup approach will be based the logical database level or the physical EBS volume-level backup. This section explores the two general backup methodologies.
The first general approach is to back up your MySQL data using
database-level methodologies. This can include making a hot backup
with
MySQL
Enterprise Backup
If the primary database server exhibits performance issues during a backup, a replication secondary database server or a read replica database server can be created to provide the source data for the backups to alleviate the backup load from the primary database server. One approach can be to back up from a secondary server’s SSD data volume to a backup server’s Throughput Optimized HDD (st1) volume. The high throughput of 500 MiB/s per volume and large 1 MiB I/O block size make it an ideal volume type for sequential backups meaning it can use the larger I/O blocks. The following diagram shows a backup server using the MySQL secondary server to read the backup data.

Using an st1 volume as a backup source
Another option is to have the MySQL secondary server back up the database files directly to Amazon Elastic File System (Amazon EFS) or Amazon S3. Amazon EFS is an elastic file system that stores its data redundantly across multiple Availability Zones. Both the primary and the secondary instances can attach to the EFS file system. The secondary instance can initiate a backup to the EFS file system from where the primary instance can do a restore. Amazon S3 can also be used as a backup target. Amazon S3 can be used in a manner similar to Amazon EFS except that Amazon S3 is object-based storage rather than a file system. The following diagram depicts the option of using Amazon EFS or Amazon S3 as a backup target.

Using Amazon EFS or Amazon S3 as a backup target
The second general approach is to use volume-level EBS snapshots. Snapshots are incremental backups, which means that only the blocks on the device that have changed after your most recent snapshot are saved. This minimizes the time required to create the snapshot and saves on storage costs. When you delete a snapshot, only the data unique to that snapshot is removed. Active snapshots contain all of the information needed to restore your data (from the time the snapshot was taken) to a new EBS volume.
One consideration when utilizing EBS snapshots for backups is to make sure the MySQL data remains consistent. During an EBS snapshot, any data not flushed from the InnoDB buffer cache to disk will not be captured. There is a MySQL command flush tables with read lock that will flush all the data in the tables to disk and only allow database reads but put a lock on database writes. The lock only needs to last for a brief period of time until the EBS snapshot starts. The snapshot will take a point-in-time capture of all the content within that volume. The database lock needs to be active until the snapshot process starts, but it doesn’t have to wait for the snapshot to complete before releasing the lock.
You can also combine these approaches by using database-level backups for more granular objects, such as databases or tables, and using EBS snapshots for larger scale operations, such as recreating the database server, restoring the entire volume, or migrating a database server to another Availability Zone or another Region for disaster recovery (DR).
Creating snapshots of an EBS RAID array
When you take a snapshot of an attached EBS volume that is in use, the snapshot excludes data cached by applications or the operating system. For a single EBS volume, this might not be a problem. However, when cached data is excluded from snapshots of multiple EBS volumes in a RAID array, restoring the volumes from the snapshots can degrade the integrity of the array.
When creating snapshots of EBS volumes that are configured in a RAID array, it is critical that there is no data I/O to or from the volumes when the snapshots are created. RAID arrays introduce data interdependencies and a level of complexity not present in a single EBS volume configuration.
To create an application-consistent snapshot of your RAID array,
stop applications from writing to the RAID array, and flush all caches to disk. At the
database level (recommended), you can use the flush tables with read lock command. Then ensure
that the associated EC2 instance is no longer writing to the RAID array by taking steps such
as freezing the file system with the sync and fsfreeze commands,
unmounting the RAID array, or shutting down the associated EC2 instance. After completing the
steps to halt all I/O, take a snapshot of each EBS
volume.
Restoring a snapshot creates a new EBS volume, then you assemble the new EBS volumes to build the RAID volumes. After that you mount the file system and then start the database. To avoid the performance degradation after the restore, AWS recommends initializing the EBS volume. The initialization of a large EBS volume can take some time to complete because data blocks have to be fetched from the S3 bucket where the snapshots are stored. To make the database available in a shorter amount of time, the initialization of the EBS volume can be done through multi-threaded reads of all the required database files for the engine recovery.
Monitoring MySQL and EBS volumes
Monitoring provides visibility into your MySQL workload. Understanding the resource utilization and performance of MySQL usually involves correlating the data from the database performance metrics gathered from MySQL and infrastructure-related metrics in CloudWatch. There are many tools that you can use to monitor MySQL, some of which include:
-
Tools from MySQL, such as MySQL Workbench Performance
-
Third-party software tools and plugins
-
MySQL monitoring tools in the AWS Marketplace
When the bottleneck for MySQL performance is related to storage,
database administrators usually look at latency when they run into
performance issues of transactional operations. Further, if the
performance is degraded due to MySQL loading or replicating data,
then throughput is evaluated. These issues are diagnosed by
looking at the EBS volume metrics collected by
CloudWatch
Latency
Latency is defined as the delay between request and completion.
Latency is experienced by slow queries, which can be diagnosed in
MySQL by enabling the
MySQL
performance schema.
High latency can result from exhausting the available Provisioned IOPS in your EBS
volume. For gp2 volumes, the CloudWatch metric BurstBalance is presented so that you
can determine if you have depleted the available credit for IOPS. When bandwidth (KiB/s) and
throughput (Ops/s) are reduced, latency (ms/op) increases.
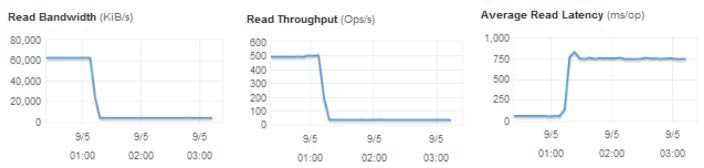
BurstBalance metric showing that when bandwidth and throughput are reduced, latency increases
Disk queue length can also contribute to high latency. Disk queue length refers to the
outstanding read/write requests that are waiting for resources to be available. The CloudWatch
metric VolumeQueueLength shows the number of pending read/write operation
requests for the volume. This metric is an important measurement to monitor if you have
reached the full utilization of the Provisioned IOPS on your EBS volumes. Ideally, the EBS
volumes must maintain an average queue length of about one per minute for every 200
Provisioned IOPS. Use the following formula to calculate how many IOPS will be consumed based
on the disk queue length:
Consumed IOPS = 200 IOPS * VolumeQueueLength
For example, say you have assigned 2,000 IOPS to your EBS volume. If the
VolumeQueueLength increases to 10, then you consume all of your 2000
Provisioned IOPS, which results in increased latency.
Pending MySQL operations will stack up if you observe the increase of the
VolumeQueueLength without any corresponding increase in the Provisioned IOPS,
as shown in the following screenshot.
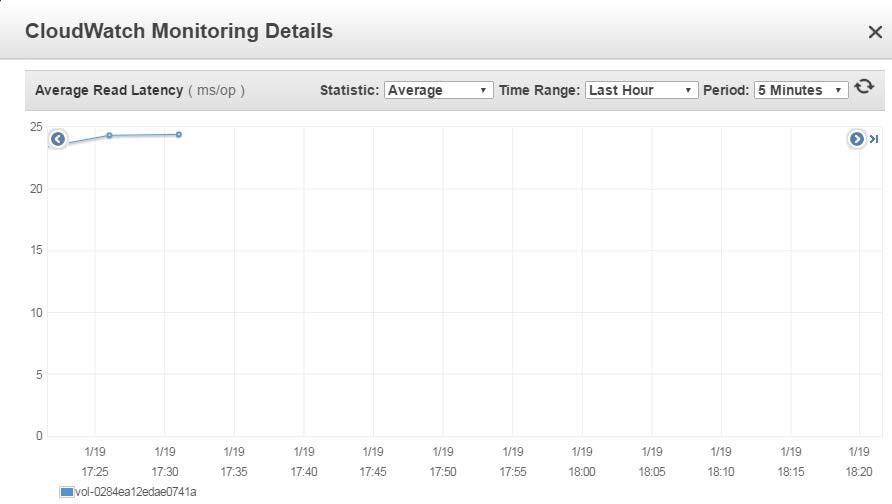
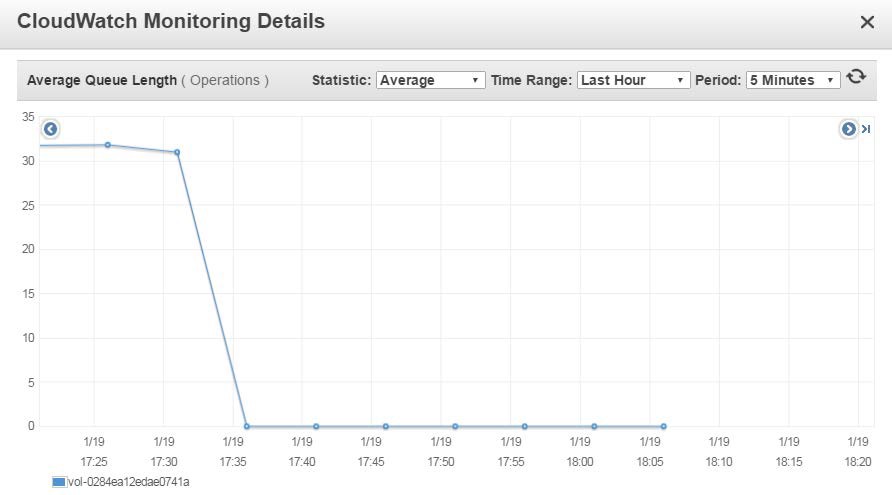
Average queue length and average read latency metrics
Throughput
Throughput is the read/write transfer rate to storage. It affects MySQL database replication, backup, and import/export activities. When considering which AWS storage option to use to achieve high throughput, you must also consider that MySQL has random I/O caused by small transactions that are committed to the database. To accommodate these two different types of traffic patterns, our recommendation is to use io1 volumes on an EBS-optimized instance. In terms of throughput, io1 volumes have a maximum of 320 MB/s per volume, while gp2 volumes have a maximum of 160 MB/s per volume.
Insufficient throughput to underlying EBS volumes can cause MySQL secondary servers to lag, and can also cause MySQL backups to take longer to complete. To diagnose throughput issues, CloudWatch provides the metrics Volume Read/Write Bytes (the amount of data being transferred) and Volume Read/Write Ops (the number of I/O operations).
In addition to using CloudWatch metrics, AWS recommends reviewing the AWS Trusted Advisor to check alerts when an EBS volume attached to an instance isn’t EBS-optimized. EBS optimization ensures dedicated network throughput for your volumes. An EBS-optimized instance has segregated traffic, which is useful as many EBS volumes have significant network I/O activities. Most new instances are EBS-optimized by default, at no extra charge.
