Soluzioni per i dati di streaming: esempi
Scenario 1: offerta Internet basata sulla posizione
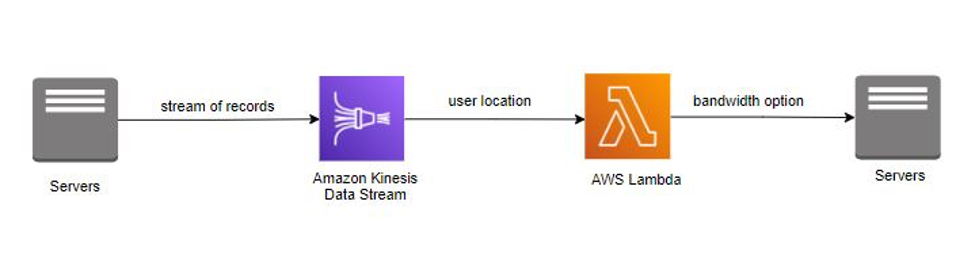
L'azienda InternetProvider fornisce servizi Internet con una varietà di opzioni di larghezza di banda agli utenti di tutto il mondo. Quando un utente si iscrive a Internet, l'azienda InternetProvider fornisce all'utente diverse opzioni di larghezza di banda in base alla sua posizione geografica. Alla luce di questi requisiti, l'azienda InternetProvider ha implementato un servizio Amazon Kinesis Data Streams per utilizzare i dettagli e la posizione dell'utente I dettagli e la posizione dell'utente vengono arricchiti con diverse opzioni di larghezza di banda prima della pubblicazione nell'applicazione. AWS Lambda
Elaborazione di flussi di dati con AWS Lambda
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams
Quando si implementa una soluzione con Kinesis Data Streams, si costruiscono applicazioni di elaborazione dati personalizzate note come applicazioni Kinesis Data Streams. Un'applicazione Kinesis Data Streams legge i dati da un flusso Kinesis come record di dati.
I dati inseriti in Kinesis Data Streams sono garantiti per essere ad alta disponibilità ed elastici e sono disponibili in millisecondi. È possibile aggiungere in modo continuo diversi tipi di dati provenienti da centinaia di migliaia di origini a un flusso di Amazon Kinesis, ad esempio clickstream, registri di applicazioni e social media. In pochi secondi, i dati del flusso potranno essere letti ed elaborati dalle applicazioni Kinesis
Amazon Kinesis Data Streams è un servizio di dati di streaming completamente gestito. Esso gestisce infrastruttura, archiviazione, reti e configurazione necessari per trasmettere i dati al tuo livello di velocità effettiva dei dati.
Invio di dati su Amazon Kinesis Data Streams
Esistono diversi modi per inviare dati a Kinesis Data Streams, garantendo flessibilità nella progettazione delle soluzioni.
-
È possibile scrivere codice utilizzando uno degli AWS SDK
supportati da più linguaggi comuni. -
È possibile utilizzare l'agente Amazon Kinesis, uno strumento per l'invio di dati a Kinesis Data Streams.
Amazon Kinesis Producer Library (KPL) semplifica lo sviluppo delle applicazioni producer consentendo agli sviluppatori di ottenere una velocità effettiva di scrittura elevata su uno o più flussi dei dati Kinesis.
KPL è una libreria facile da usare e altamente configurabile che si installa sugli host. Funge da intermediario tra il codice dell'applicazione producer e le operazioni dell'API di Kinesis Streams. Per ulteriori informazioni KPL e sulla sua capacità di produrre eventi in modo sincrono e asincrono con esempi di codice, consulta l'argomento relativo alla scrittura in Kinesis Data Streams utilizzando KPL
Ci sono due diverse operazioni nell'API di Kinesis Data Streams che aggiungono dati a un flusso: PutRecords e PutRecord. L'operazione PutRecords invia più record al flusso per richiesta HTTP mentre PutRecord invia un record per richiesta HTTP. Per ottenere una velocità effettiva più elevata per la maggior parte delle applicazioni, utilizzare PutRecords.
Per ulteriori informazioni su queste API, consulta Aggiunta di dati a un flusso. I dettagli per ciascuna operazione API sono disponibili nella Documentazione di riferimento delle API di Amazon Kinesis Data Streams.
Elaborazione di dati in Amazon Kinesis Data Streams
Per leggere ed elaborare i dati dai flussi Kinesis, è necessario creare un'applicazione consumer. Esistono diversi modi per creare consumer per Kinesis Data Streams. Alcuni di questi approcci includono l'utilizzo di Amazon Kinesis Data Analytics
Le applicazioni consumer per Kinesis Data Streams possono essere sviluppate utilizzando KCL, che aiuta a consumare ed elaborare i dati da Kinesis Data Streams. KCL si occupa di molte delle attività complesse associate al calcolo distribuito, come il bilanciamento del carico su più istanze, la risposta ai guasti delle istanze, il checkpoint dei record elaborati e la reazione al resharding. KCL consente di concentrarsi sulla scrittura della logica di elaborazione dei record. Per ulteriori informazioni su come costruire la propria applicazione KCL, consulta Utilizzo della libreria client Kinesis.
È possibile sottoscrivere le funzioni Lambda per leggere automaticamente batch di record dal flusso Kinesis ed elaborarli se vengono rilevati record nel flusso. AWS Lambda esegue periodicamente il polling del flusso (una volta al secondo) per nuovi record e quando li rileva, richiama la funzione Lambda passando i nuovi record come parametri. La funzione Lambda viene eseguita solo quando vengono rilevati nuovi record. È possibile mappare una funzione Lambda a un consumer con velocità effettiva condivisa (iteratore standard)
È possibile costruire un consumer che utilizzi una caratteristica chiamata fan-out avanzato quando è necessaria una velocità effettiva dedicata che non si desidera contendere con altri consumer che ricevono dati dal flusso. Questa caratteristica consente alle applicazioni consumer di ricevere record da un flusso con una velocità effettiva fino a 2 MiB di dati al secondo per ogni partizione.
Nella maggior parte dei casi, l'utilizzo di Kinesis Data Analytics, KCL, AWS Glue o AWS Lambda dovrebbe essere allo scopo di elaborare i dati da un flusso. Tuttavia, se si preferisce, è possibile creare un'applicazione consumer da zero utilizzando l'API Kinesis Data Streams. L'API Kinesis Data Streams fornisce i metodi GetShardIterator e GetRecords per recuperare i dati da un flusso.
In questo modello pull, il codice estrae i dati direttamente dalle partizioni del flusso. Per ulteriori informazioni sulla scrittura di applicazioni consumer utilizzando l'API, consulta Sviluppo di consumer personalizzati con velocità effettiva condivisa utilizzando AWS SDK per Java. I dettagli relativi all'API sono disponibili nella Documentazione di riferimento delle API di Amazon Kinesis Data Streams.
Elaborazione di flussi di dati con AWS Lambda
AWS Lambda
AWS Lambda si integra in modo nativo con Amazon Kinesis Data Streams. Le complessità di polling, checkpoint e gestione degli errori vengono astratte quando si utilizza questa integrazione nativa. Ciò permette al codice della funzione Lambda di concentrarsi sull'elaborazione della logica di business.
È possibile mappare una funzione Lambda a un consumer a velocità effettiva condivise (iteratore standard) o a un consumer a velocità effettiva dedicata con fan-out avanzato. Per gli iteratori standard, Lambda esegue il polling di ogni partizione nel flusso Kinesis per i record utilizzando il protocollo HTTP. Per ridurre al minimo la latenza e massimizzare la velocità effettiva di lettura, è possibile creare un consumer di flusso dei dati con fan-out avanzato. I consumer di flussi in questa architettura ottengono una connessione dedicata a ogni partizione senza competere con altre applicazioni che leggono dallo stesso flusso. Amazon Kinesis Data Streams invia i record a Lambda tramite HTTP/2.
Di default, AWS Lambda richiama la funzione appena i record sono disponibili nel flusso. Per eseguire il buffer dei record per gli scenari batch, è possibile implementare una finestra batch per un massimo di cinque minuti nell'origine dell'evento. Se la funzione restituisce un errore, Lambda effettua nuovi tentativi sui batch finché l'elaborazione non va a buon fine o fino alla scadenza dei dati.
Riepilogo
L'azienda InternetProvider ha sfruttato Amazon Kinesis Data Streams per trasmettere dettagli e posizione degli utenti. Il flusso di record è stato utilizzato da AWS Lambda per arricchire i dati con opzioni di larghezza di banda archiviate nella libreria della funzione. Dopo l'arricchimento, AWS Lambda ha pubblicato le opzioni di larghezza di banda nell'applicazione. Amazon Kinesis Data Streams e AWS Lambda hanno gestito il provisioning e la gestione dei server, consentendo all'azienda InternetProvider di concentrarsi maggiormente sullo sviluppo di applicazioni aziendali.
