SQL Server データベースを Babelfish for Aurora PostgreSQL に移行する
Aurora 用の Babelfish PostgreSQL を使用すると、SQL Server データベースから Amazon Aurora PostgreSQL DB クラスターへの移行が可能です。移行前に「1 つのデータベースまたは複数のデータベースでの babelfish の使用」を確認します。
データ移行プロセスの概要
以下の概要では、SQL Server アプリケーションを移行して Babelfish で使用するために必要なステップを説明します。エクスポートおよびインポートプロセスに使用できるツールの詳細については、「SQL Server から Babelfish に移行するためのインポート/エクスポートツール」を参照してください。データをロードするには、Aurora PostgreSQL DB クラスターを持つ AWS DMS をターゲットエンドポイントとして使用することをお勧めします。
-
Babelfish をオンにした状態で、新しい Aurora PostgreSQL DBクラスターを作成します。この方法の詳細は、「Babelfish for Aurora PostgreSQL DB クラスターの作成」を参照してください。
SQL Server データベースからエクスポートされたさまざまな SQL アーティファクトをインポートするには、sqlcmd
などの SQL Server ツールを使用して Babelfish クラスターに接続します。詳細については、「SQL Server クライアントを使用した DB クラスターへの接続」を参照してください。 -
移行したい SQL Server データベースで、データ定義言語 (DDL) をエクスポートします。DDL は、ユーザーデータ (テーブル、インデックス、ビューなど) とユーザーが作成したデータベースコード (保存された手順、ユーザー定義の関数、トリガーなど) を含むデータベースオブジェクトを記述する SQL コードです。
詳細については、「SQL Server Management Studio (SSMS) を使用して Babelfish に移行する」を参照してください。
-
評価ツールを実行して、Babelfish が SQL Server で実行されているアプリケーションを効果的にサポートできるように、必要な変更の範囲を評価します。詳細については、「SQL Server と Babelfish の違いを評価して処理する」を参照してください。
-
AWS DMS ターゲットエンドポイントの制限を確認し、必要に応じて DDL スクリプトを更新します。詳細については、「Using Babelfish for Aurora PostgreSQL as a target」の「Limitations to using a PostgreSQL target endpoint with Babelfish tables」を参照してください。
-
新しい Babelfish DB クラスターで、指定された T-SQL データベース内で DDL を実行して、プライマリキー制約を持つスキーマ、ユーザー定義データ型、およびテーブルのみを作成します。
-
AWS DMS を使用して、SQL Server から Babelfish テーブルにデータを移行します。SQL Server 変更データキャプチャまたは SQL レプリケーションを使用する連続レプリケーションの場合は、エンドポイントとして Babelfish の代わりに Aurora PostgreSQL を使用してください。これを行うには、「AWS Database Migration Service のターゲットとして Babelfish for Aurora PostgreSQL を使用する」を参照してください。
-
データのロードが完了したら、アプリケーションをサポートする残りのすべての T-SQL オブジェクトを Babelfish クラスター上に作成します。
-
SQL Server データベースではなく Babelfish エンドポイントに接続するようにクライアントアプリケーションを再設定します。詳細については、「BabelfishDB クラスターへの接続」を参照してください。
-
必要に応じてアプリケーションを変更し、再テストします。詳しくは、「Babelfish for Aurora PostgreSQL と SQL Server の違い」を参照してください。
ただし、引き続きクライアント側の SQL クエリを評価する必要があります。SQL Server インスタンスから生成されたスキーマは、サーバー側 SQL コードのみを変換します。次の手順を実行することをお勧めします。
-
TSQL_Replay 定義済みテンプレートで SQL Server プロファイラーを使用して、クライアント側のクエリをキャプチャします。このテンプレートは T-SQL ステートメント情報をキャプチャします。この情報は、反復的なチューニングとテストのために再生できます。プロファイラーは、SQL Server Management Studio 内の [Tools] (ツール) メニューから起動できます。[SQL Server Profiler] (SQL Server プロファイラー) をクリックしてプロファイラーを開き、TSQL_Replay テンプレートを選択します。
Babelfish の移行に使用するには、トレースを開始し、機能テストを使用してアプリケーションを実行します。プロファイラーは T-SQL ステートメントをキャプチャします。テストが完了したら、以下のようにトレースを停止します。クライアント側のクエリを使用して、結果を XML ファイルに保存します ([ファイル] > [名前を付けて保存] > [再生のために XML ファイルをトレース])。
詳細については、Microsoft ドキュメントの「SQL Server プロファイラー
」を参照してください。TSQL_Replay テンプレートの詳細については、「SQL Server プロファイラーテンプレート 」を参照してください。 -
複雑なクライアント側 SQL クエリを使用するアプリケーションでは、Babelfish の互換性のために、Babelfish Compass を使用してこれらのクエリを分析することをお勧めします。分析により、クライアント側 SQL 文にサポートされていない SQL 機能が含まれていることが示された場合、クライアントアプリケーションの SQL の側面を確認し、必要に応じて変更を加えます。
-
SQL クエリを拡張イベント (.xel 形式) としてキャプチャすることもできます。これを行うには、SSMS XEvent プロファイラーを使用します。.xel ファイルを生成した後、SQL ステートメントを Compass で処理できる .xml ファイルに抽出します。詳細については、Microsoft ドキュメントの「SSMS XEvent プロファイラーの使用
」を参照してください。
移行アプリケーションに必要なテスト、分析、および変更がすべて完了したら、本番環境で Babelfish データベースの使用を開始できます。そのためには、元のデータベースを停止し、ライブクライアントアプリケーションをリダイレクトして Babelfish TDS ポートを使用します。
注記
AWS DMS は Babelfish からのデータのレプリケーションをサポートするようになりました。詳細については、「AWS DMS はソースとして Babelfish for Aurora PostgreSQL をサポートするようになった
SQL Server と Babelfish の違いを評価して処理する
最良の結果を得るには、SQL Server データベースアプリケーションを実際に Babelfish に移行する前に、生成された DDL/DML とクライアントクエリコードを評価することをお勧めします。Babelfish のバージョンと、アプリケーションが実装する SQL Server の特定の機能によっては、アプリケーションをリファクタリングするか、Babelfish でまだ完全にはサポートされていない機能の代替手段を使用する必要がある場合があります。
-
SQL Server アプリケーションコードを評価するには、生成された DDL に対して Babelfish Compass を使用し、T-SQL コードが Babelfish でサポートされる範囲を調べます。Babelfish で実行する前に、変更が必要となる可能性がある T-SQL コードを特定します。このツールの詳細については、GitHub で「Babelfish Compass ツール
」を参照してください。 注記
Babelfish Compass は、オープンソースツールです。Babelfish Compass に関する問題は、AWS Support ではなく、GitHub を通じて報告してください。
SQL Server Management Studio (SSMS) でスクリプト生成ウィザードを使用して、Babelfish Compass または AWS Schema Conversion Tool CLI によって評価される SQL ファイルを生成できます。以下のステップによって評価を合理化することをお勧めします。
-
[Choose Objects] (オブジェクトを選択) ページで、[Script entire database and all database objects] (データベース全体とすべてのデータベースオブジェクトをスクリプト化) を選択します。
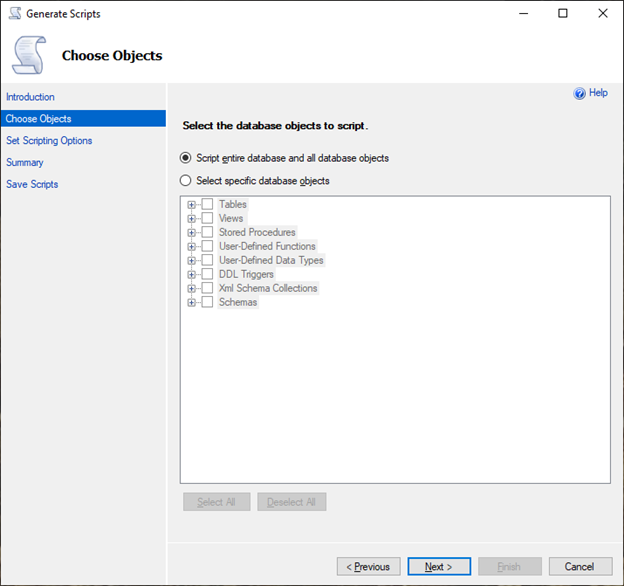
-
[Set Scripting Options] (スクリプトオプションを設定) で、[Save as script file] (名前を付けてスクリプトファイルを保存) を [Single script file] (単一のスクリプトファイル) として選択します。
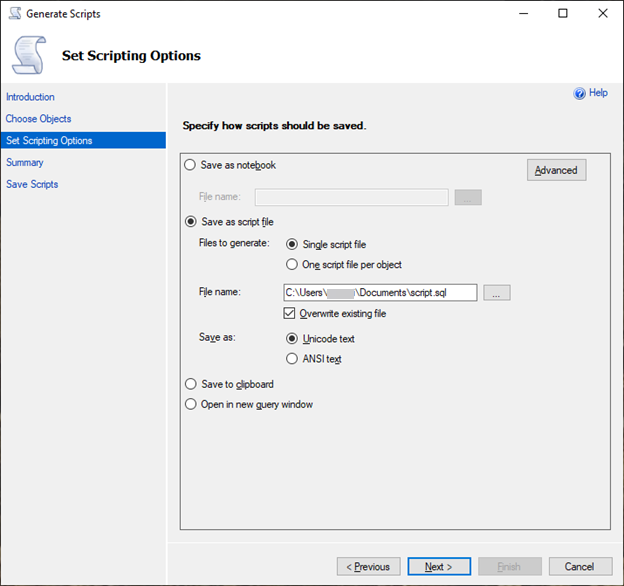
-
[Advanced] (アドバンスト) を選択すると、デフォルトのスクリプトオプションが変更され、通常は完全な評価について false に設定される機能を識別できます。
-
スクリプトの変更追跡を True に
-
スクリプトの全文索引を True に
-
スクリプトのトリガーを True に
-
スクリプトのログインを True に
-
スクリプトオーナーを True に
-
スクリプトのオブジェクトレベルのアクセス許可を True に
-
スクリプトの照合順序を True に
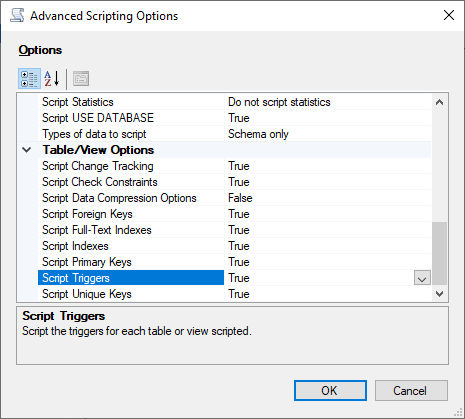
-
-
ウィザードの残りの手順を実行して、ファイルを生成します。
SQL Server から Babelfish に移行するためのインポート/エクスポートツール
SQL Server から Babelfish に移行するための主要なツールとして、AWS DMS を使用することをお勧めします。ただし、Babelfish は、SQL Server ツールを使用してデータを移行する他の方法もいくつかサポートしています。これには次のものが含まれます。
-
Babelfish のすべてのバージョンについて、SQL Server Integration Services (SSIS)。詳細については、「SSIS と Babelfish を使用して SQL Server から Aurora PostgreSQL に移行する
」を参照してください。 -
Babelfish バージョン 2.1.0 以降では、SSMS Import/Export ウィザードを使用します。このツールは SSMS から使用できますが、スタンドアロンツールとしても使用できます。詳細については、Microsoft ドキュメントの「SQL Server インポートおよびエクスポートウィザードへようこそ
」を参照してください。 -
Microsoft bulk data copy program (bcp) ユーティリティを使用すると、Microsoft SQL Server インスタンスから指定した形式のデータファイルにデータをコピーできます。トラブルシューティングの詳細については、Microsoft ドキュメントの「bcp ユーティリティ
」を参照してください。Babelfish は BCP クライアントを使用したデータ移行をサポートするようになり、bcp ユーティリティは -Eフラグ (ID 列用) と -b フラグ (バッチ挿入用) をサポートするようになりました。-C、-T、-G、-K、-R、-V、-hなど、特定の bcp オプションはサポートされません。
SQL Server Management Studio (SSMS) を使用して Babelfish に移行する
特定のオブジェクトタイプごとに別々のファイルを生成することをお勧めします。最初に DDL ステートメントのセットごとに SSMS のスクリプト生成ウィザードを使用してから、オブジェクトをグループとして変更し、評価中に見つかった問題を修正できます。
AWS DMS または他のデータ移行方法を使用してデータを移行するには、次の手順を実行します。これらの作成スクリプトタイプを最初に実行すると、Aurora PostgreSQL の Babelfish テーブルに、より適切かつ迅速にデータをロードできます。
-
CREATE SCHEMAステートメントを実行します。 -
CREATE TYPEステートメントを実行して、ユーザー定義のデータ型を作成します。 -
プライマリキーまたは一意制約を使用して基本の
CREATE TABLEステートメントを実行します。
推奨されるインポート/エクスポートツールを使用して、データのロードを実行します。次の手順で修正したスクリプトを実行して、残りのデータベースオブジェクトを追加します。制約、トリガー、およびインデックスについて、これらのスクリプトを実行するには、create table ステートメントが必要です。スクリプトが生成されたら、create table ステートメントを削除します。
-
チェック制約、外部キー制約、デフォルト制約について、
ALTER TABLEステートメントを実行します。 -
CREATE TRIGGERステートメントを実行します。 -
CREATE INDEXステートメントを実行します。 -
CREATE VIEWステートメントを実行します。 -
CREATE STORED PROCEDUREステートメントを実行します。
各オブジェクトタイプのスクリプトを生成するには
SSMS のスクリプト生成ウィザードを使用して、基本的な create table ステートメントを作成するには、次の手順に従います。同じ手順に従って、さまざまなオブジェクトタイプのスクリプトを生成します。
-
既存の SQL Server インスタンスに接続します。
-
右クリックでデータベース名のメニューを開きます。
-
[Tasks] (タスク) を選択し、[Generate Scripts...] (スクリプトを生成...) を選択します。
-
[オブジェクトを選択] ペインで、[特定のデータベースオブジェクトを選択する] を選択します。[Tables] (テーブル) を選択して、すべてのテーブルを選択します。[次へ] を選択して続行します。
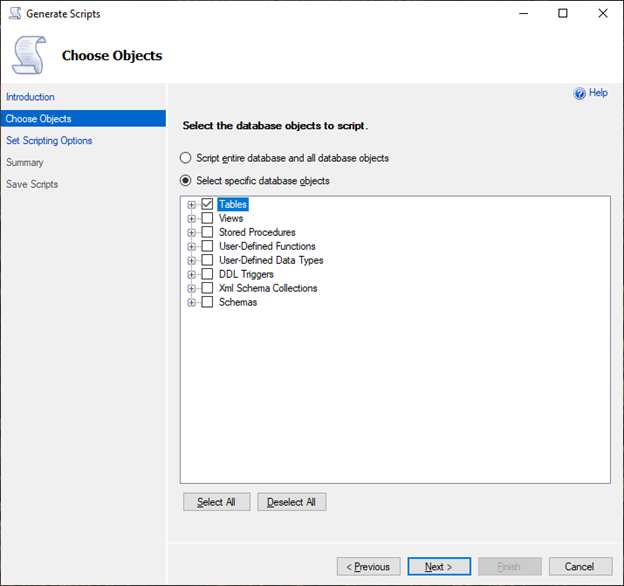
-
[スクリプトオプションの設定] を選択し、[アドバンスト] をクリックして、[オプション] 設定を開きます。基本的な create table ステートメントを生成するには、次のデフォルト値を変更します。
-
スクリプトのデフォルトを False に。
-
スクリプトの拡張プロパティを False に。Babelfish は拡張プロパティをサポートしていません。
-
スクリプトチェック制約を False に。スクリプトの外部キーを False に。
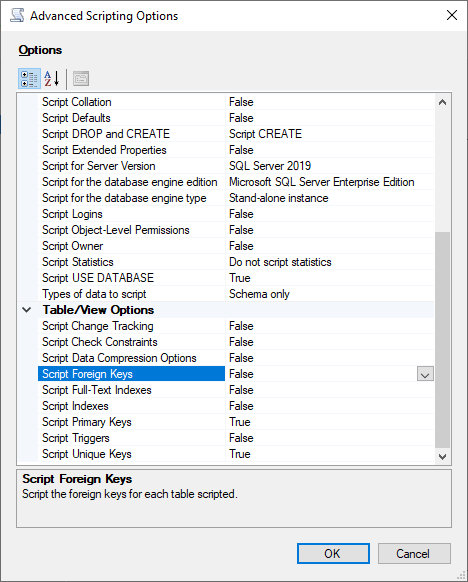
-
-
[OK] を選択してください。
-
[Set Scripting Options] (スクリプトオプションの設定) ページで、[Save as script file] (スクリプトファイルを名前を付けて保存) を選択し、[Single script file] (単一スクリプトファイル) オプションを選択します。[File name] (ファイル名) を入力します。
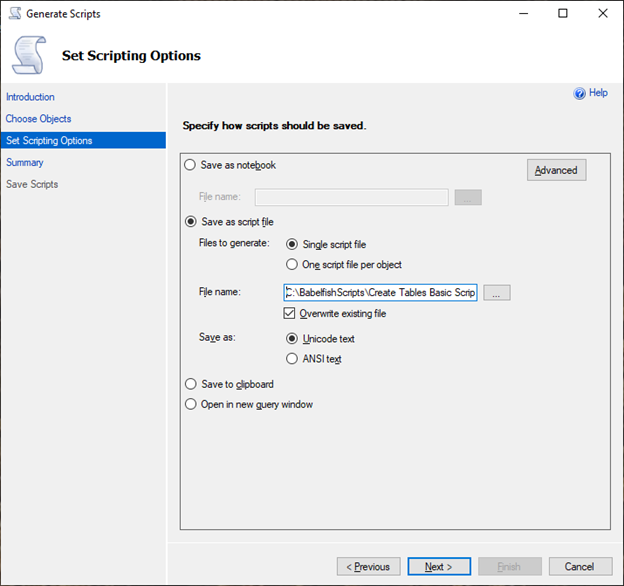
-
[Next] (次へ) を選択すると、[Summary wizard] (ウィザードの概要) ページが表示されます。
-
[Next] (次へ) を選択して、スクリプトの生成を開始します。
ウィザードで他のオブジェクトタイプのスクリプトを引き続き生成できます。ファイルを保存した後、[Finish] (完了) を選択する代わりに、[Previous] (前へ) ボタンを 3 回選択して、[Choose Objects] (オブジェクトを選択) ページに戻ります。次に、ウィザードの手順を繰り返して、他のオブジェクトタイプのスクリプトを生成します。
