DynamoDB テーブルで多対多リレーションシップを管理するためのベストプラクティス
隣接関係のリストは、Amazon DynamoDB の多対多の関係のモデリングに役立つ設計パターンです。より一般的には、DynamoDB のグラフデータ (ノードとエッジ) を表現する方法です。
隣接関係のリスト設計パターン
異なるエンティティのアプリケーションの間に、多対多の関係がある場合、その関係は隣接関係のリストとしてモデル化することができます。このパターンでは、最上位エンティティ (グラフモデル内のノードと同義) はすべて、パーティションキーを使用して表現されます。他のエンティティとの関係 (グラフのエッジ) は、ソートキーの値をターゲットエンティティ ID (ターゲットノード) に設定することによって、パーティション内の項目として表現されます。
このパターンの利点として、ターゲットエンティティ (ターゲットノードへのエッジを含む) に関連するすべてのエンティティ (ノード) を見つけるために重複データを最小限に抑えられることや、クエリパターンを簡素化できる点などがあります。
このパターンが実際に役に立った例として、請求書に複数の請求書を含めることができる請求システムがあります。1 つの請求書を複数の請求書に含めることができます。この例のパーティションキーは、InvoiceID または BillID です。BillID パーティションには、請求書固有の属性がすべて含まれます。InvoiceID パーティションには、請求書固有の属性を格納する項目と、各 BillID の項目が含まれており、この項目は、1 つの請求書にまとめられます。
スキーマは次のようになります。
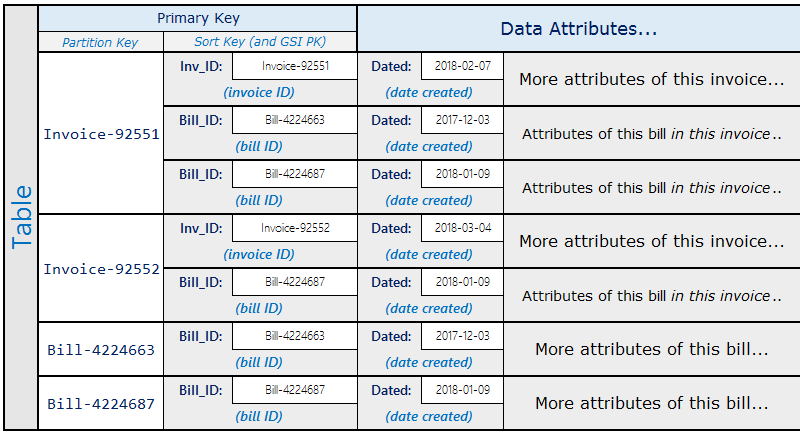
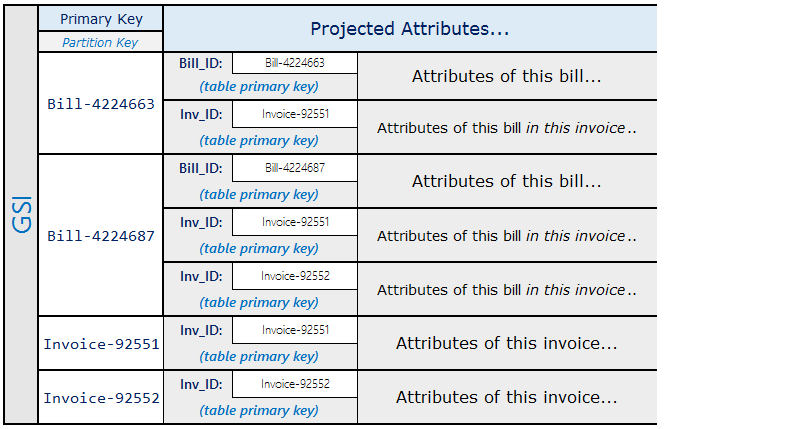
上記のスキーマを使用すると、テーブルのプライマリキーを使用して、請求書の請求内容をすべて照会することができます。請求書の一部を含むすべての請求書を検索するには、テーブルのソートキーにグローバルセカンダリインデックスを作成します。
グローバルセカンダリインデックスの射影は、次のようになります。
マテリアライズされたグラフパターン
多くのアプリケーションは、ピア間のランキング、エンティティ間の共通関係、ネイバーエンティティの状態に加え、他のタイプのグラフスタイルのワークフローを理解することを中心として作成されています。これらのアプリケーションタイプの場合は、次のスキーマ設計パターンを検討します。
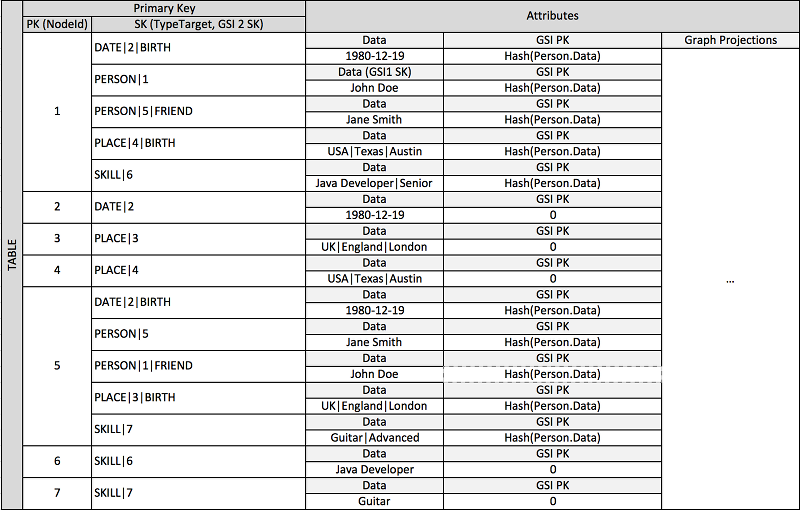
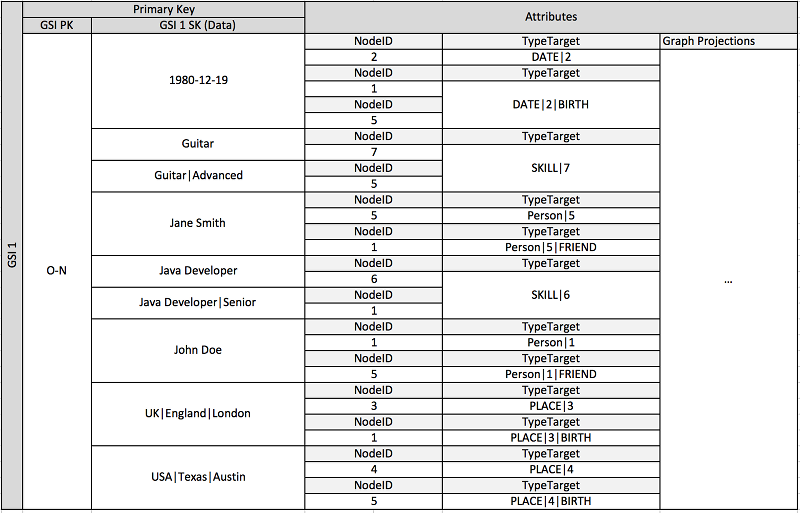
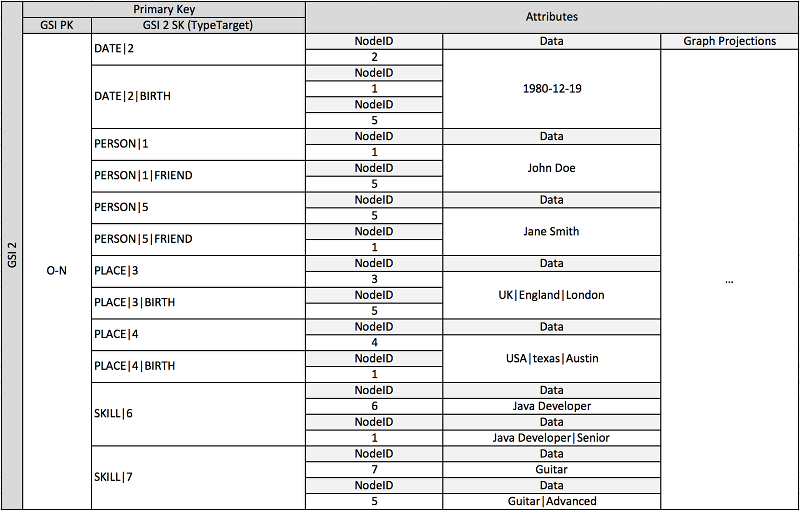
前述のスキーマは、グラフのエッジおよびノードを定義する項目を含むデータパーティションのセットによって定義されるグラフデータ構造を示します。エッジ項目には、Target 属性および Type 属性が含まれます。これらの属性は、プライマリテーブルのパーティションまたはグローバルセカンダリインデックスの項目を識別する複合キー名 "TypeTarget" の一部として使用されます。
最初のグローバルセカンダリインデックスは、Data 属性で構築されます。この属性は、以前説明したようなグローバルセカンダリインデックスの多重定義を使用して、複数の異なる属性タイプ (Dates、Names、Places、Skills のインデックス) を作成します。ここで、1 つのグローバルセカンダリインデックスは、4 つの異なる属性のインデックスを効果的に作成します。
項目をテーブルに挿入する際に、インテリジェントなシャーディング戦略を使用して、大量の集計 (生年月日、スキル) を含む項目セットを、ホット読み書き問題を回避するために必要なグローバルなセカンダリインデックスの論理パーティションに分散させることができます。
このような設計パターンの組み合わせによって、効率の高いリアルタイムグラフワークフローのソリッドなデータストアが実現しました。これらのワークフローでは、推奨のエンジン、ソーシャルネットワーキングアプリケーション、ノードのランキング、サブツリーの集約、およびその他の一般的なグラフのユースケースに対して、高パフォーマンスなネイバーエンティティの状態とエッジの集約クエリを使用できます。
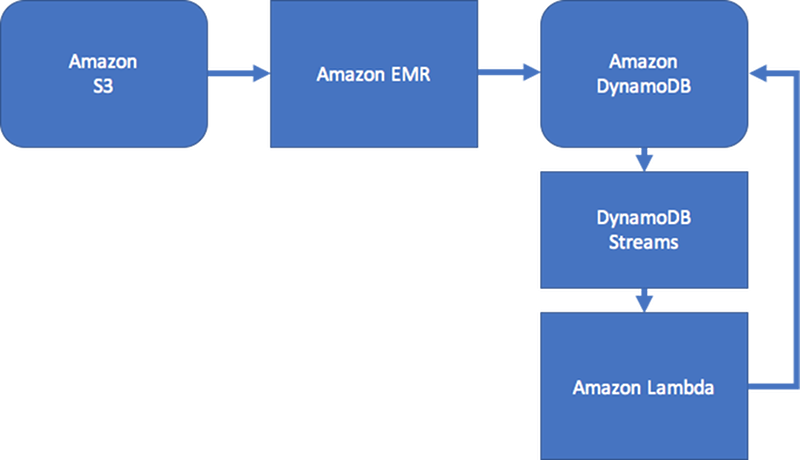
ユースケースがリアルタイムデータの一貫性に優れていない場合は、スケジュールされた Amazon EMR プロセスを使用して、エッジをワークフローに関連するグラフサマリー集約に追加することができます。グラフにエッジが追加されたときにアプリケーションですぐに認識する必要がない場合は、スケジュールされたプロセスを使用して結果を集約できます。
一定レベルの一貫性を維持するために、この設計には、エッジ更新を処理する Amazon DynamoDB Streams や AWS Lambda が含まれることがあります。また、Amazon EMR ジョブを使用して、定期的に結果を検証することもできます。このアプローチを次の図に示します。このアプローチは、リアルタイムクエリのコストが高く、各ユーザーの更新をすぐに知る必要性が低いソーシャルネットワーキングアプリケーションで一般的に使用されます。
IT サービス管理 (ITSM) およびセキュリティアプリケーションでは通常、複雑なエッジ集約で構成されるエンティティ状態の変化にリアルタイムで応答する必要があります。このようなアプリケーションでは、第 2 レベルと第 3 レベルの関係や複雑なエッジトラバーサルの複数のリアルタイムノード集約をサポートできるシステムが必要です。ユースケースに、これらのタイプのリアルタイムグラフクエリワークフローが必要な場合は、これらのワークフローの管理に Amazon Neptune の使用を検討することをお勧めします。
注記
高度に接続されたデータセットをクエリする必要がある場合、またはミリ秒のレイテンシーで複数のノードを通過する必要があるクエリ (マルチホップクエリとも呼ばれます) を実行する必要がある場合は、Amazon Neptune の使用を検討してください。Amazon Neptune は専用の高性能グラフデータベースエンジンです。このエンジンは、数十億の関係を保存し、ミリ秒単位のレイテンシーでグラフをクエリできるよう最適化されています。
