DynamoDB でリレーショナルデータをモデル化するための最初のステップ
重要
NoSQL 設計では、RDBMS 設計とは異なる考え方が必要です。RDBMS の場合は、アクセスパターンを考慮せずに正規化されたデータモデルを作成できます。その後、新しい課題とクエリの要件が発生したら、そのデータモデルを拡張することができます。対照的に、Amazon DynamoDB の場合は答えが必要な質問が分かるまで、スキーマの設計を開始しないでください。ビジネス上の問題とアプリケーションのユースケースを理解することが極めて重要です。
効率的に拡張する DynamoDB テーブルの設計を開始するには、サポートする必要のあるオペレーションおよびビジネスサポートシステム (OSS/BSS) で必要とされるアクセスパターンを特定するために、まずいくつかの手順を実行する必要があります。
新しいアプリケーションの場合は、アクティビティや目的に関するユーザーストーリーを確認します。特定するさまざまなユースケースを文書化し、必要なアクセスパターンを分析します。
既存のアプリケーションでは、クエリログを分析して、ユーザーが現在どのようにシステムを使用しているか、主要なアクセスパターンを調べます。
このプロセスが完了したら、次のようなリストが表示されます。
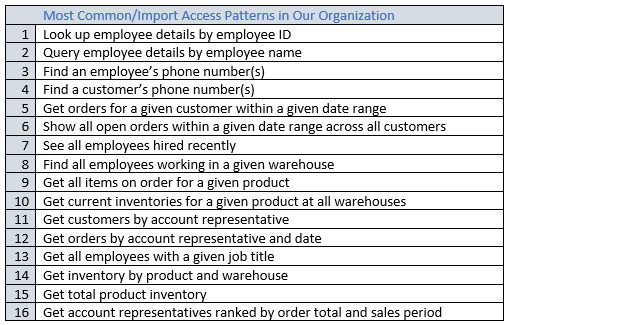
実際のアプリケーションでは、リストはさらに長くなる場合があります。しかし、このコレクションは、本番環境で見つかる可能性のあるクエリパターンの複雑さの範囲を表します。
DynamoDB スキーマ設計の一般的なアプローチとして、アプリケーションレイヤーエンティティを識別し、非正規化と複合キー集約を使用してクエリの複雑さを軽減します。
DynamoDB では、複合ソートキー、多重定義のグローバルセカンダリインデックス、パーティションテーブル/インデックス、その他のデザインパターンを使用することを意味します。これらの要素を使用してデータを構造化することで、アプリケーションは、テーブルまたはインデックスの単一のクエリを使用して、特定のアクセスパターンに必要なものを取得できます。リレーショナルモデル化 に示されている正規化されたスキーマをモデル化するために使用できる主なパターンは、隣接関係リストのパターンです。この設計で使用されるその他のパターンには、グローバルセカンダリインデックスの書き込みシャーディング、グローバルセカンダリインデックスの多重定義、複合キー、マテリアライズされた集計があります。
重要
一般的に、DynamoDB アプリケーションではできるだけ少ないテーブルを維持する必要があります。例外として、大容量の時系列データが必要な場合や、データセットのアクセスパターンが非常に異なる場合などがあります。反転されたインデックスを含む単一のテーブルでは通常、シンプルなクエリを使用してアプリケーションで必要とされる複雑な階層データ構造を構築および取得できます。
NoSQL Workbench for DynamoDB を使用してパーティションキー設計を視覚化する方法については、「NoSQL Workbench を使用したデータモデルの構築」を参照してください。
