DynamoDB でリレーショナルデータをモデル化するためのベストプラクティス
このセクションでは、Amazon DynamoDB でリレーショナルデータをモデル化するためのベストプラクティスを説明します。まず、従来のデータモデリングのコンセプトを紹介します。次に、従来のリレーショナルデータベース管理システムではなく DynamoDB を使用する利点について説明します。つまり JOIN オペレーションが不要になり、オーバーヘッドが削減されるということです。
次に、効率的にスケーリングする DynamoDB テーブルを設計する方法を説明します。最後に、DynamoDB でリレーショナルデータをモデル化する方法の例を示します。
トピック
従来のリレーショナルデータベースモデル
従来のリレーショナルデータベース管理システム (RDBMS) は、正規化されたリレーショナル構造でデータを保存します。リレーショナルデータモデルの目的は、(正規化によって) データの重複を減らして参照整合性を維持し、データの異常を削減することです。
次のスキーマは、一般的な注文入力アプリケーションのリレーショナルデータ型の一例です。このアプリケーションは、理論上の製造元の運用およびビジネスサポートシステムを支える人事スキーマをサポートします。
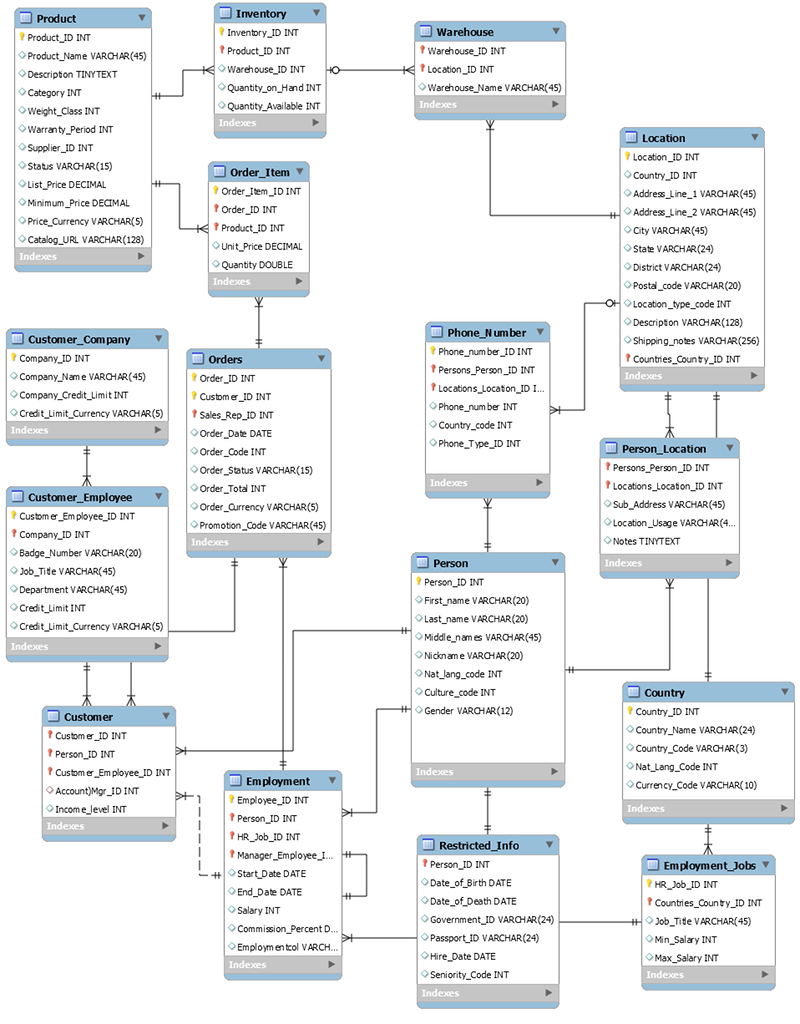
非リレーショナルデータベースサービスである DynamoDB には、従来のリレーショナルデータベース管理システムと比較して多くの利点があります。
DynamoDB によって JOIN オペレーションが不要になる理由
RDBMS は、構造クエリ言語 (SQL) を使用してデータをアプリケーションに返します。データ型の正規化により、このようなクエリでは通常、JOIN 演算子を使用して 1 つ以上のテーブルのデータを結合する必要があります。
例えば、各項目を出荷するすべてのウェアハウスで在庫数量でソートされた発注書項目のリストを生成するには、前のスキーマに対して次の SQL クエリを発行します。
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCこの種の SQL クエリは、データにアクセスするための柔軟な API を提供できますが、大量の処理が必要です。クエリを結合するたびに、クエリのランタイムの複雑さが増します。これは、各テーブルのデータをステージングしてからアセンブルして結果セットを返す必要があるためです。
クエリの実行時間に影響するその他の要因は、テーブルのサイズおよび結合される列にインデックスがあるかどうかです。前述のクエリは、複数のテーブルにわたって複雑なクエリを実行し、結果として生成されるセットをソートします。
JOINs の必要性をなくすことが NoSQL データモデリングの中核となります。これが、Amazon.com をサポートするために DynamoDB を構築した理由であり、DynamoDB があらゆる規模で一貫したパフォーマンスを提供できる理由です。SQL クエリと JOINs のランタイムの複雑さを考慮すると、RBDMS のパフォーマンスは規模に応じて一定ではありません。そのため、お客様のアプリケーションが大きくなるにつれてパフォーマンスの問題が発生します。
データを正規化することでディスクに保存されるデータの量は削減されますが、多くの場合、パフォーマンスに影響する最も制約の厳しいリソースは CPU 時間とネットワーク遅延です。
DynamoDB は、JOINs を削除し(かつデータの非正規化を促進し)、データベースアーキテクチャを最適化して、項目に 1 回のリクエストでアプリケーションクエリに完全に応答します。これによって、両方の制約を最小限に抑えます。これらの特性により、DynamoDB は規模にかかわらず 1 桁のミリ秒単位のパフォーマンスを実現できます。これは、一般的なアクセスパターンでは、DynamoDB オペレーションの実行時の複雑さが一定であるためです。
DynamoDB トランザクションが書き込みプロセスのオーバーヘッドを排除する方法
RDBMS の速度を低下させるもう 1 つの要因は、正規化されたスキーマに書き込むためにトランザクションを使用することです。例に示す通り、ほとんどのオンライントランザクション処理 (OLTP) アプリケーションで使用されるリレーショナルデータ構造は、RDBMS に格納されているときに複数の論理テーブルに分割して分散させる必要があります。
そのため、アプリケーションで書き込み中のオブジェクトを読み込もうとした場合に発生する可能性のある競合状態およびデータの整合性の問題を回避するためには、ACID 準拠のトランザクションフレームワークが必要です。こうしたトランザクションフレームワークをリレーショナルスキーマと組み合わせると、書き込みプロセスにかなりのオーバーヘッドが発生する可能性があります。
DynamoDB にトランザクションを実装すると、RDBMS で一般的に見られるスケーリングの問題が防止されます。DynamoDB では、トランザクションを 1 回の API 呼び出しとして発行し、その 1 回のトランザクションでアクセスできる項目の数を制限することで、これを行っています。トランザクションの実行時間が長いと、トランザクションがクローズされないため、データのロックが長期間、または永続的に保持され、運用上の問題が発生する可能性があります。
DynamoDB でのこのような問題を防ぐため、トランザクションは TransactWriteItems と TransactGetItems の 2 つの異なる API オペレーションを使用して実装されました。これらの API オペレーションには、RDBMS で一般的な開始および終了セマンティクスがありません。さらに、DynamoDB では、同様に長時間実行されるトランザクションを防ぐため、1 回のトランザクション内で 100 項目のアクセス制限を設けています。DynamoDB トランザクションの詳細については、「トランザクションでの使用」を参照してください。
こうした理由から、高トラフィックのクエリに対して低レイテンシーの応答が必要な場合は、NoSQL システムを利用すると、一般的に技術的および経済的な効果がもたらされます。Amazon DynamoDB では、リレーショナルシステムのスケーラビリティを制限する問題を回避できます。
RDBMS のパフォーマンスは、通常、以下の理由から適切にスケーリングできません。
-
高価な結合を使用して、クエリ結果の必要なビューを再構成します。
-
データを正規化し、複数のクエリを必要とする複数のテーブルに格納して、ディスクに書き込みます。
-
一般的に、ACID 準拠のトランザクションシステムのパフォーマンスコストが発生します。
DynamoDB は、次の理由により適切に拡張されます。
-
スキーマの柔軟性により、DynamoDB は複雑な階層データを 1 つの項目内に格納できます。
-
複合キー設計では、関連する項目を同じテーブルの範囲内に格納できます。
-
トランザクションは 1 回のオペレーションで実行されます。オペレーションの実行が長時間に及ぶのを避けるため、アクセスできる項目の上限数は 100 となっています。
データストアに対するクエリは、多くの場合次のような形式で、非常に簡単になります。
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB は、以前の例の RDBMS と比較して、リクエストされたデータを返す作業がはるかに少なくなっています。
