DynamoDB のデータモデリングの構成要素
このセクションでは、アプリケーションで使用できる設計パターンを提供するビルディングブロックレイヤーについて説明します。
トピック
複合ソートキー構成要素
NoSQL と言えば、非リレーショナルと考えがちです。ただし、DynamoDB の場合は、スキーマにリレーションシップを配置できない理由はなく、リレーショナルデータベースやその外部キーと見た目が異なるだけです。DynamoDB でデータの論理階層を構築するために使用できる最も重要なパターンの 1 つは、複合ソートキーです。最も一般的な設計スタイルは、階層の各レイヤー (親レイヤー > 子レイヤー > 孫レイヤー) をハッシュタグで区切ることです。例えば、PARENT#CHILD#GRANDCHILD#ETC と指定します。
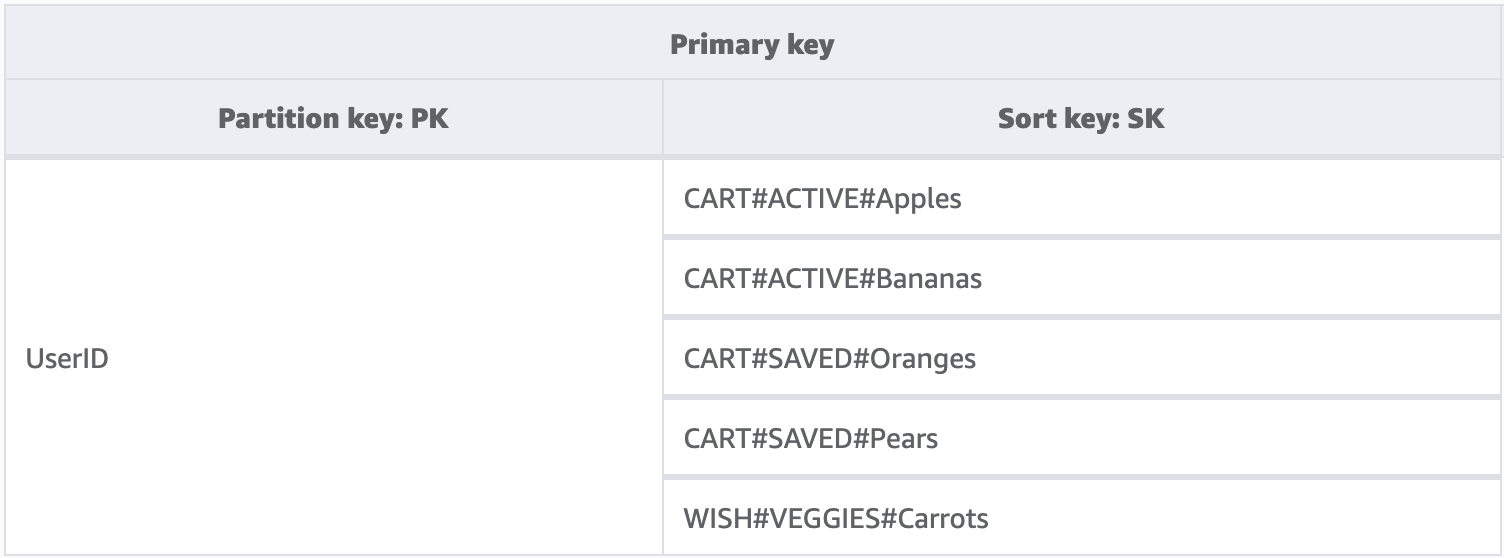
DynamoDB のパーティションキーには、データをクエリするために常に正確な値が必要です。一方、ソートキーには、バイナリツリーをたどる場合と同じように、左から右に部分条件を適用できます。
上の例では、e コマースストアのショッピングカートを、ユーザーセッションをまたいで維持する必要があります。ユーザーはログインするたびに、あとで買うために保存した商品を含むショッピングカート全体を確認したい場合があります。ただし、レジに進むときは、アクティブなカート内の商品のみをロードして購入できるようにする必要があります。これらの KeyConditions は、どちらもカートのソートキーを明示的に要求するため、追加のウィッシュリストのデータは読み取り時に DynamoDB によって単に無視されます。保存した商品とアクティブな商品はどちらも同じカートの一部ですが、アプリケーションの異なる部分ごとに異なる方法で扱う必要があります。この場合、アプリケーションの部分ごとに必要なデータのみを取得する最適な方法は、ソートキーのプレフィックスに KeyCondition を適用することです。
この構成要素の主な特徴
-
関連項目は相互にローカルに保存されるため、データへのアクセスが効率的になります。
-
KeyCondition式を使用すると、階層のサブセットを選択的に取得できるため、無駄な RCU がなくなります。 -
アプリケーションの異なる部分ごとに異なるプレフィックスを適用して項目を保存できるため、項目の上書きや書き込みの競合を防ぐことができます。
マルチテナンシー構成要素
多くのお客様が DynamoDB を使用してマルチテナントアプリケーションのデータをホストしています。このようなシナリオでは、1 つのテナントからのすべてのデータをテーブルの独自の論理パーティションに保持するようにスキーマを設計する必要があります。これには、項目コレクションという概念を活用します。項目コレクションとは、DynamoDB テーブル内で同じパーティションキーを持つすべての項目を表す用語です。DynamoDB におけるマルチテナンシーへのアプローチの詳細については、「DynamoDB のマルチテナンシー」を参照してください。
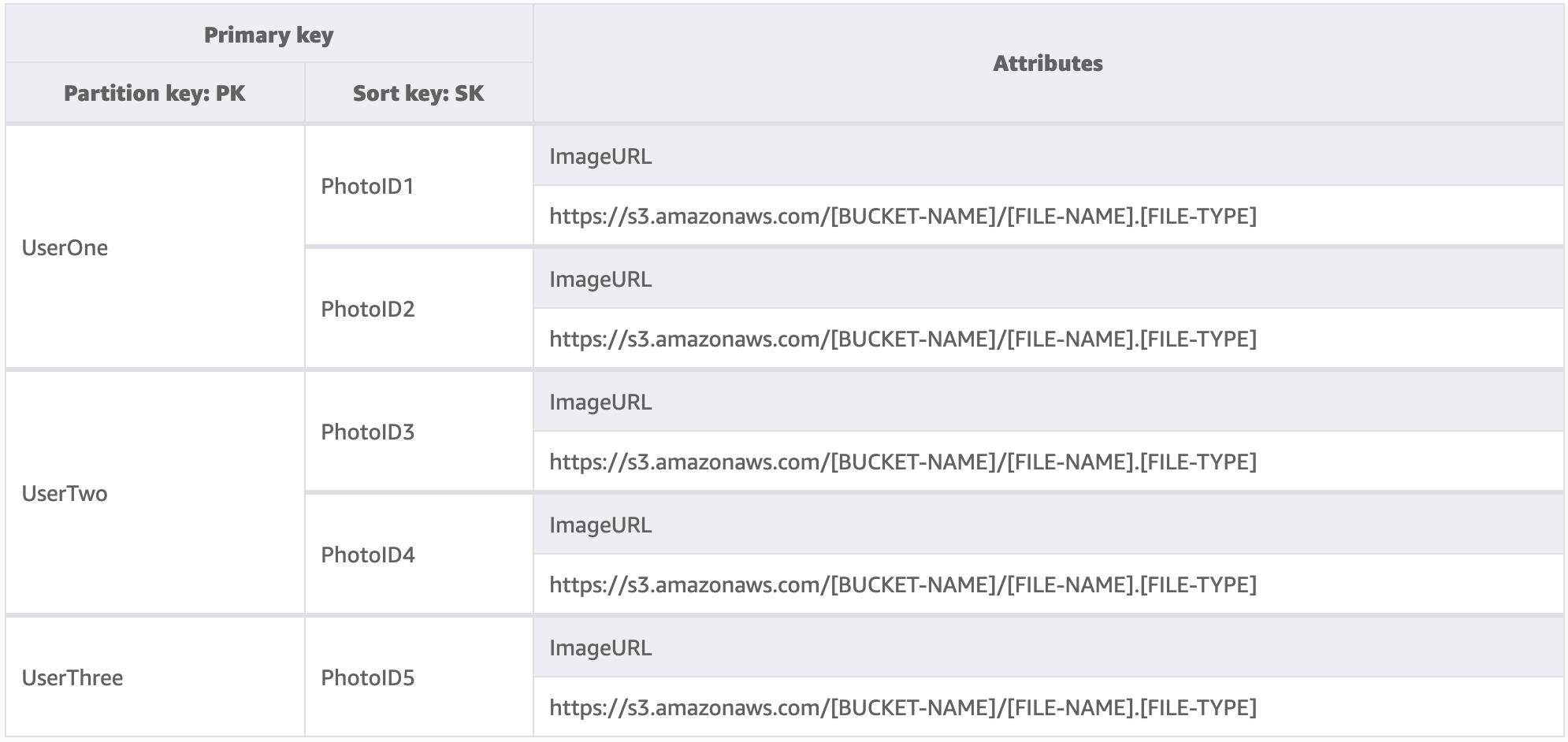
この例では、ユーザー数が数千人に及ぶ可能性がある写真ホスティングサイトを運営しています。各ユーザーは、最初は自分のプロファイルにのみ写真をアップロードし、デフォルトでは他のユーザーの写真を見ることはできません。各ユーザーからの API コールの承認に分離レベルを追加して、各自のパーティションのデータのみを要求していることを確認するのが理想的ですが、スキーマレベルでは一意のパーティションキーで十分です。
この構成要素の主な特徴
-
1 人のユーザーやテナントが読み取ることができるデータ量は、各自のパーティション内の項目の合計量と同じ量に制限されます。
-
アカウントの閉鎖やコンプライアンス要求に伴うテナントのデータの削除は、適切かつ安価に行うことができます。単に、パーティションキーがテナント ID と等しいクエリを実行し、返されたプライマリキーごとに
DeleteItem操作を実行します。
注記
マルチテナンシーを念頭に置いて設計されているため、1 つのテーブル全体でさまざまな暗号化キープロバイダーを使用してデータを安全に分離できます。AWSAmazon DynamoDB 用の Database Encryption SDK を使用すると、DynamoDB ワークロードにクライアント側の暗号化を組み込むことができます。属性レベルの暗号化を実行すると、特定の属性値を DynamoDB テーブルに保存する前に暗号化したり、データベース全体を事前に復号せずに暗号化された属性を検索したりできます。
スパースインデックスの構成要素
アクセスパターンによっては、まれな項目や、ステータスを受け取る項目 (応答のエスカレーションが必要) に一致する項目の検索が必要になる場合があります。これらの項目については、データセット全体を定期的にクエリするのではなく、グローバルセカンダリインデックス (GSI) を利用できます。GSI ではデータがまばらに読み込まれるという事実が役立ちます。つまり、インデックスに定義されている属性を持つベーステーブルの項目だけがインデックスにレプリケートされます。
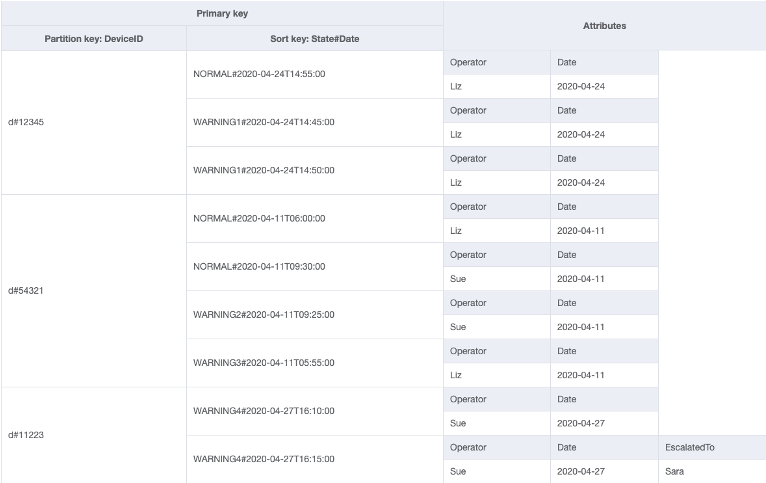

この例は、現場の各デバイスが定期的にステータスを報告している IOT のユースケースを示しています。ほとんどのレポートでは、デバイスから何の問題もないことが報告されると予想されますが、場合によっては障害が発生し、修理技術者へのエスカレーションが必要になる場合があります。エスカレーションを含むレポートでは、EscalatedTo 属性が項目に追加されますが、それ以外の場合は追加されません。この例の GSI は EscalatedTo でパーティション化されており、GSI はベーステーブルからキーを引き継ぐため、どの DeviceID がいつ障害を報告したかは依然として確認できます。
DynamoDB の場合、読み取りは書き込みよりも安価であり、スパースインデックスは、特定の種類の項目のインスタンスがめったに発生しないが、これらを見つけるための読み取りをよく行うユースケースでは非常に強力なツールです。
この構成要素の主な特徴
-
スパース GSI の書き込みコストとストレージコストは、キーパターンに一致する項目にのみ適用されるため、GSI のコストは、すべての項目をレプリケートする他の GSI よりも大幅に低くなる可能性があります。
-
複合ソートキーを引き続き使用して、目的のクエリに一致する項目をさらに絞り込むこともできます。例えば、ソートキーにタイムスタンプを使用して、過去 X 分間 (
SK > 5 minutes ago, ScanIndexForward: False) に報告された障害のみを表示できます。
Time to Live (有効期限) 構成要素
ほとんどのデータは、特定の期限まで、プライマリデータストアに保持する価値があると考えられます。DynamoDB からのデータのエージングアウトを容易にするために、Time to Live (TTL) と呼ばれる機能があります。TTL 機能を使用すると、エポックタイムスタンプ (経過済み) を持つ項目のために、モニタリングする必要がある特定の属性をテーブルレベルで定義できます。これにより、期限切れのレコードをテーブルから無料で削除できます。
注記
グローバルテーブルバージョン 2019.11.21 (現行) を使用しており、Time to Live 機能も使用している場合、DynamoDB は TTL による削除をすべてのレプリカテーブルにレプリケートします。最初の TTL による削除の場合、TTL の有効期限切れが発生したリージョンでは、書き込みキャパシティが消費されません。ただし、レプリカテーブルにレプリケートされた TTL による削除の場合、各レプリカリージョンではレプリケートされた書き込みキャパシティが消費され、該当する料金が適用されます。
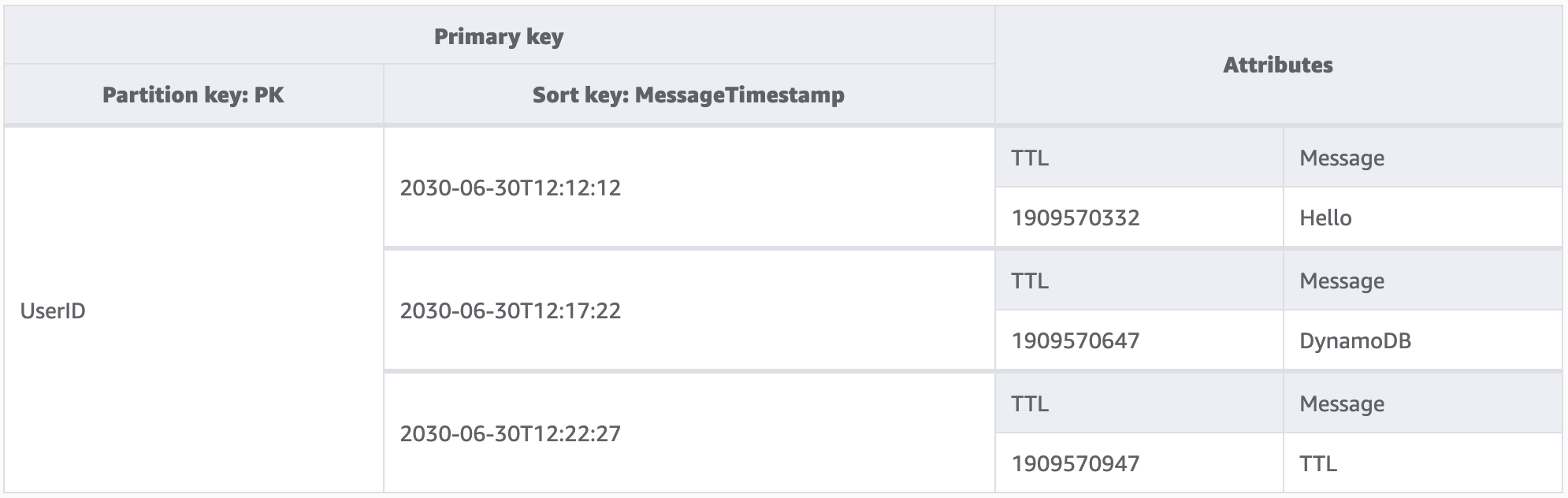
この例は、存続期間の短いメッセージをユーザーが作成できるように設計したアプリケーションを示しています。DynamoDB でメッセージを作成すると、アプリケーションコードによって TTL 属性が 7 日後の日付に設定されます。約 7 日後に、DynamoDB はこれらの項目のエポックタイムスタンプが過去のものであることを確認し、削除します。
TTL による削除は無料であるため、この機能を使用してテーブルから履歴データを削除することを強くお勧めします。これにより、毎月の全体的なストレージ料金が削減され、クエリによって取得されるデータが少なくなるため、ユーザーの読み取りコストも削減される可能性があります。TTL はテーブルレベルで有効になっていますが、どの項目またはエンティティに対して TTL 属性を作成するか、またエポックタイムスタンプをどれだけ将来に設定するかはユーザーが指定できます。
この構成要素の主な特徴
-
TTL による削除はバックグラウンドで実行され、テーブルのパフォーマンスには影響しません
-
TTL は約 6 時間ごとに実行される非同期プロセスですが、期限切れのレコードの削除には 48 時間超かかる場合があります。
-
古いデータを 48 時間以内にクリーンアップする必要がある場合は、ロックレコードや状態管理などのユースケースで TTL による削除に依存しないでください。
-
-
TTL 属性には有効な属性名を指定できますが、値は数値型でなければなりません。
Time to Live (アーカイブ用) 構成要素
TTL は DynamoDB から古いデータを削除する効果的なツールですが、多くのユースケースでは、データのアーカイブをプライマリデータストアよりも長期間保存する必要があります。この場合、TTL によるレコードの時間指定削除を利用して、期限切れのレコードを長期データストアにプッシュできます。
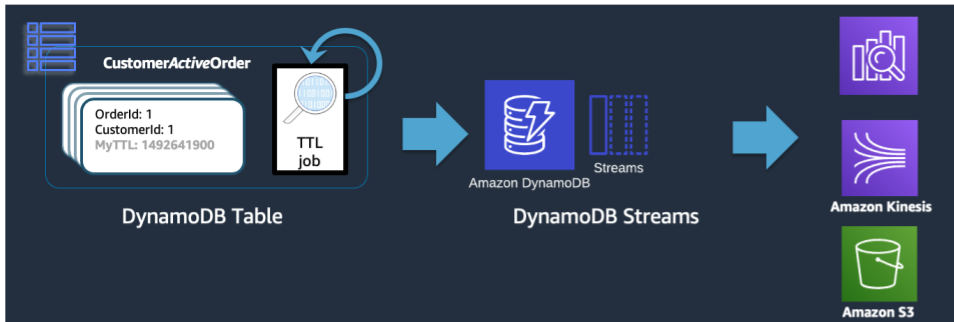
DynamoDB が TTL を使用して削除を実行すると、その操作は引き続き Delete イベントとして DynamoDB Stream にプッシュされます。ただし、DynamoDB の TTL 自体が削除を実行する場合は、principal:dynamodb のストリームレコードの属性を利用できます。DynamoDB Stream への Lambda サブスクライバーを使用すると、DynamoDB プリンシパル属性にのみイベントフィルターを適用することで、このフィルターに一致するすべてのレコードが S3 Glacier などのアーカイブストアにプッシュされるようになります。
この構成要素の主な特徴
-
履歴項目に対する DynamoDB の低レイテンシーの読み取りが不要になったら、それらを S3 Glacier などのコールドストレージサービスに移行することで、ストレージコストを大幅に削減すると同時に、ユースケースのデータコンプライアンスのニーズを満たすことができます。
-
データが Amazon S3 に保存されている場合、Amazon Athena や Redshift Spectrum などのコスト効率の高い分析ツールを使用してデータの履歴分析を行うことができます。
垂直パーティショニング構成要素
ドキュメントモデルデータベースに精通しているユーザーなら、すべての関連データを 1 つの JSON ドキュメントに保存するという考え方に慣れているでしょう。DynamoDB は JSON データ型をサポートしていますが、ネストされた JSON に対する KeyConditions の実行はサポートしていません。KeyConditions は、ディスクから読み取るデータの量とクエリが実際に消費する RCU の数を決定するものであるため、これに伴って大規模な非効率が生じる可能性があります。DynamoDB の書き込みと読み取りをより適切に最適化するには、ドキュメントの個々のエンティティを個別の DynamoDB 項目に分割することをお勧めします。これは垂直パーティショニングとも呼ばれます。


上の垂直パーティショニングは、シングルテーブル設計を示す重要な実例ですが、必要に応じて複数のテーブルに実装することもできます。DynamoDB は書き込みを 1 KB 単位で請求するため、理想的には各項目が 1 KB 未満になるようにドキュメントを分割します。
この構成要素の主な特徴
-
データ関係の階層はソートキーのプレフィックスによって維持されるため、必要に応じて単一のドキュメント構造をクライアント側で再構築できます。
-
データ構造の個々のコンポーネントを個別に更新できるため、小さな項目の更新はわずか 1 WCUで済みます。
-
ソートキー
BeginsWithを使用すると、アプリケーションは 1 回のクエリで類似したデータを取得し、読み取りコストを集約して総コスト/レイテンシーを削減できます。 -
サイズの大きいドキュメントは、DynamoDB の個別項目のサイズ制限である 400 KB を簡単に超えてしまう可能性があり、垂直パーティショニングはこの制限を回避するのに役立ちます。
書き込みシャーディング構成要素
DynamoDB に設定されている数少ないハード制限の 1 つは、単一の物理パーティションが 1 秒あたりに維持できるスループットに対する制限です (必ずしも単一のパーティションキーとは限りません)。現在、これらの制限は以下のとおりです。
-
1000 WCU (または 1 秒あたり 1000 <=1KB 項目の書き込み) および 3000 RCU (または 1 秒あたり 3000 <=4KB の読み取り) の強力な整合性のある読み込み、または
-
1 秒あたり 6000 <=4KB の結果整合性のある読み込み
テーブルに対するリクエストがこれらの制限のいずれかを超えると、エラーが ThroughputExceededException のクライアント SDK に送り返されます。これは一般的にスロットリングと呼ばれます。この制限を超える読み取り操作を必要とするユースケースは、ほとんどの場合、DynamoDB の前に読み取りキャッシュを配置することで最適に処理されます。ただし、書き込み操作には書き込みシャーディングと呼ばれるスキーマレベルの設計が必要です。
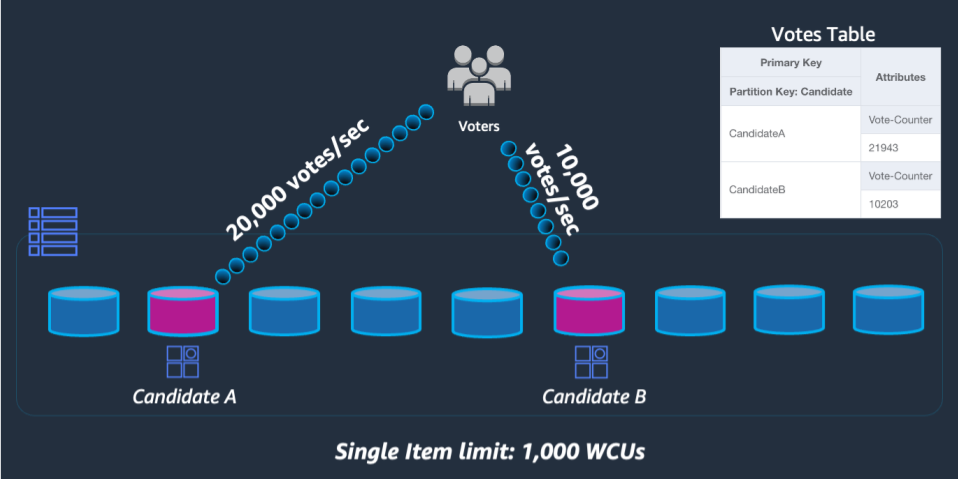
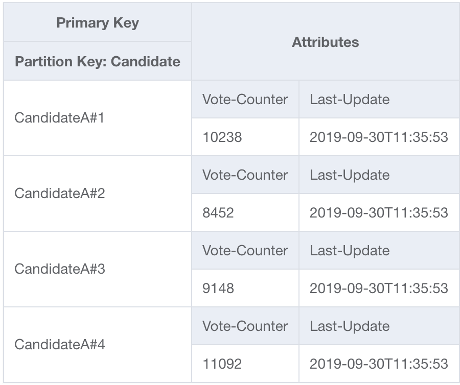
この問題を解決するには、アプリケーションの UpdateItem コードで各候補者のパーティションキーの末尾にランダムな整数を追加します。ランダム整数ジェネレータの範囲の上限は、特定の候補者の 1 秒あたりの予想書き込み量を 1000 で割った値と一致するか、それを超える必要があります。1 秒あたり 20,000 の投票数をサポートするには、rand(0,19) のようになります。データは個別の論理パーティションに保存されているため、読み取り時にデータを結合し直す必要があります。投票総数はリアルタイムである必要はないため、X 分ごとにすべての投票パーティションを読み取るようにスケジュールした Lambda 関数では、候補者ごとに集計をときどき行い、ライブ読み取り用の 1 つの投票集計レコードに書き戻すことができます。
この構成要素の主な特徴
-
特定のパーティションキーに対する書き込みスループットがきわめて高く、これを避けられないユースケースでは、書き込み操作を複数の DynamoDB パーティションに人為的に分散できます。
-
GSI でのスロットリングはベーステーブルへの書き込み操作にバックプレッシャーを与えるため、カーディナリティの低いパーティションキーを持つ GSI でも、このパターンを利用する必要があります。
