翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
配列ジョブ
配列ジョブは、ジョブ定義、vCPU、メモリなどの共通パラメータを共有するジョブです。これは、関連しているが個別の基本ジョブのコレクションとして実行されます。複数のホストに分散されたり、同時に実行される場合もあります。配列ジョブは、モンテカルロシミュレーションジョブ、パラメータスイープジョブ、大規模なレンダリングジョブなど、大量の並列ジョブを実行するもっとも効率的な方法です。
AWS Batch 配列ジョブは、通常のジョブと同様に送信されます。ただし、配列内で実行する子ジョブの数を定義する配列サイズ (2 ~ 10,000) を指定します。配列サイズが 1,000 以内のジョブを送信する場合は、単一ジョブが実行され 1,000 個の子ジョブが生成されます。配列ジョブは、すべての子ジョブを管理するリファレンスまたはポインタです。これにより、1つのクエリで大量のワークロードを送信することができます。attemptDurationSecondsパラメータで指定されたタイムアウトは、それぞれの子ジョブに適用されます。親アレイジョブには、タイムアウトはありません。
配列ジョブを送信すると、親配列ジョブは通常の AWS Batch ジョブ ID を取得します。子ジョブのベース ID は、それぞれ同じです。各子ジョブは同じベース ID を持ちますが、子ジョブの配列インデックスが親 ID の末尾に付加されます。例えば、配列の最初の子ジョブはexample_job_ID:0
親アレイジョブは、 SUBMITTED、 PENDING、FAILED、または SUCCEEDED ステータスを入力できます。アレイの親ジョブは、PENDING 子ジョブが RUNNABLE に更新されるとに更新されます。これらの依存関係の詳細については、ジョブの依存関係を参照してください。
実行時、AWS_BATCH_JOB_ARRAY_INDEX 環境変数がコンテナの対応するジョブ配列インデックス番号に設定されます。最初の配列ジョブインデックスは 0 番となり、後続の試行は昇順の番号 (1、2、3 など) になります。このインデックス値を使用して、配列ジョブの子がどのように区別されるかを制御できます。詳細については、配列ジョブインデックスを使用してジョブの区別を制御するを参照してください。
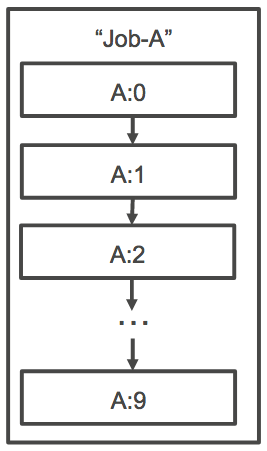
配列ジョブの依存関係では、依存関係のタイプを指定できます (SEQUENTIAL または N_TO_N など)。SEQUENTIAL タイプの依存関係 (ジョブ ID を指定しない) を指定できます。こうすることで各子配列ジョブがインデックス 0 から開始して連続的に完了します。例えば、配列サイズが 100 の配列ジョブを送信する場合、依存関係を SEQUENTIAL タイプに指定すると、100 個の子ジョブが連続押して生成され、最初の子ジョブが成功してから次の子ジョブが開始されます。以下の図で示すジョブ A は、配列サイズが 10 である配列ジョブです。ジョブ A の子インデックスの各ジョブは、前の子ジョブに依存します。ジョブ A:1 はジョブ A:0 が完了するまで開始できません。
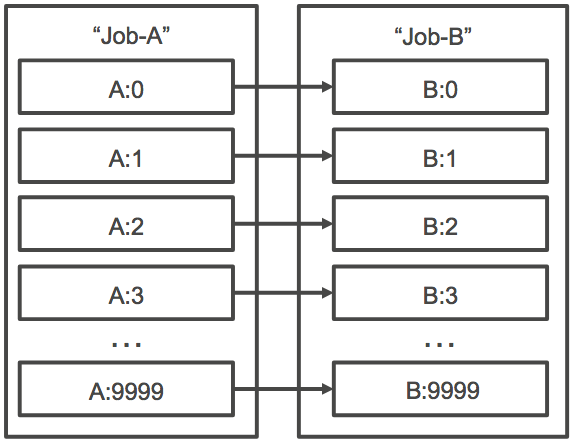
また、アレイジョブのジョブ ID を使用して N_TO_N タイプの依存関係を指定することもできます。この場合、このジョブの各インデックスの子は各依存関係の対応するインデックスの子が完了するまで待機してから開始されます。以下の図で示すジョブ A およびジョブ B は、配列サイズがそれぞれ 10,000 である 2 つの配列ジョブです。ジョブ B の子インデックスの各ジョブは、ジョブ A の対応するインデックスに依存します。ジョブ B:1 はジョブ A:1 が完了するまで開始できません。
親配列ジョブをキャンセルまたは終了した場合、子ジョブもすべてキャンセルまたは終了します。個々の子ジョブを、他の子ジョブに影響を与えずにキャンセルまたは終了できます (FAILED ステータスに移動させる)。ただし、子配列ジョブが失敗した場合 (それ自身の失敗または手動でキャンセルもしくは終了した場合)、親ジョブも失敗します。このシナリオでは、すべての子ジョブが完了すると、親ジョブは FAILED に移行します。
配列ジョブの検索とフィルタリングの詳細については、「」を参照してくださいジョブキュー内のジョブを検索する。
