翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
レプリカセットとしての Amazon DocumentDB に接続する
Amazon DocumentDB (MongoDB 互換)で開発する場合は、レプリカセットとしてクラスターに接続し、ドライバーに組み込まれている読み取り設定機能を使用してレプリカインスタンスに読み取りを分散することをお勧めします。このセクションでは、その意味についてさらに詳しく説明し、例として SDK for Python を使用して、レプリカセットとして Amazon DocumentDB クラスターに接続する方法について説明します。
Amazon DocumentDB には、クラスターへの接続に使用できる 3 つのエンドポイントがあります。
-
クラスターエンドポイント
-
リーダーエンドポイント
-
インスタンスエンドポイント
ほとんどの場合、Amazon DocumentDB に接続するときは、クラスターエンドポイントを使用することをお勧めします。これは、次の図に示すように、クラスター内のプライマリインスタンスをポイントする CNAME です。
SSH トンネルを使用する場合は、クラスターエンドポイントを使用してクラスターに接続することをお勧めします。レプリカセットモード (接続文字列に replicaSet=rs0 を指定) で接続するとエラーが発生します。
注記
Amazon DocumentDB ウェブサイトのエンドポイントの詳細については、「Amazon DocumentDB エンドポイント」を参照してください。
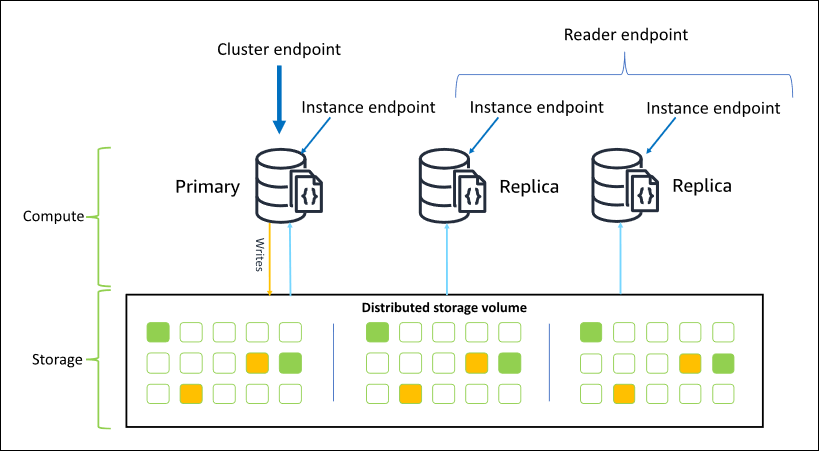
クラスターエンドポイントを使用して、レプリカセットモードでクラスターに接続できます。その後、組み込まれた読み込み設定ドライバー機能を使用できます。次の例では、/?replicaSet=rs0 を指定することで、レプリカセットとして接続することを SDK を示します。/?replicaSet=rs0' を省略すると、クライアントはすべてのリクエストをプライマリインスタンスであるクラスターエンドポイントにルーティングします。
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
レプリカセットとして接続する利点は、インスタンスがクラスターに対して追加または削除されるタイミングを含め、SDK がクラスタートポグラフィを自動的に検出できることです。その後、レプリカインスタンスに読み込みリクエストをルーティングすることで、クラスターをより効率的に使用できます。
レプリカセットとして接続するときは、接続の readPreference を指定できます。secondaryPreferred の読み込み設定を指定した場合、クライアントは(以下の図のように)読み取りクエリをレプリカにルーティングし、書き込みクエリをプライマリインスタンスにルーティングします。これにより、クラスターリソースをより適切に利用できます。詳細については、「読み込み設定のオプション」を参照してください。
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
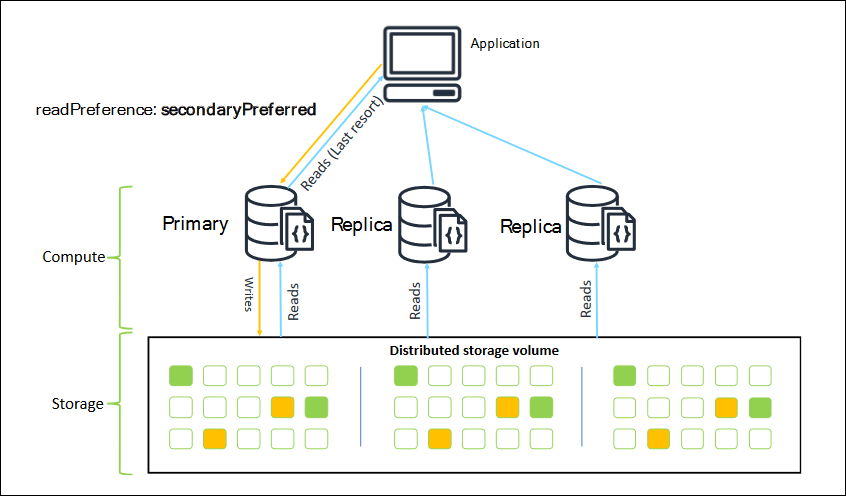
Amazon DocumentDBレプリカからの読み込みには結果整合性があります。プライマリに書き込まれたのと同じ順序でデータを返し、50 ミリ秒未満のレプリケーション遅延もよくあります。Amazon CloudWatch メトリクス DBInstanceReplicaLag と DBClusterReplicaLagMaximum を使用して、クラスターのレプリカラグをモニタリングできます。詳細については、「Amazon DocumentDB と CloudWatch のモニタリング」を参照してください。
従来のモノリシックデータベースアーキテクチャとは異なり、Amazon DocumentDB はストレージとコンピューティングを分離します。この最新のアーキテクチャでは、レプリカインスタンスの読み取りのスケールをお勧めします。レプリカインスタンスの読み込みは、プライマリインスタンスからレプリケートされる書き込みをブロックしません。クラスターに最大 15 個のリードレプリカインスタンスを追加し、1 秒あたり数百万回の読み込みにスケールアウトできます。
レプリカセットとして接続し、レプリカに読み取りを分散する主な利点は、アプリケーションの作業に利用できるクラスター内のリソース全体が増加することです。ベストプラクティスとして、レプリカセットとして接続することをお勧めします。さらに、以下のシナリオでは最も一般的にお勧めします。
-
プライマリでほぼ 100% の CPU を使用している。
-
バッファキャッシュヒット率がほぼゼロである。
-
個別のインスタンスで接続またはカーソルの制限に達する。
クラスターインスタンスサイズのスケールアップは 1 つの選択肢であり、場合によっては、これがクラスターをスケーリングするための最良の方法です。ただし、クラスターにすでに存在するレプリカをより適切に使用する方法も考慮する必要があります。これにより、より大きいインスタンスタイプを使用することでコストが増大することなく、スケールを増加できます。また、CloudWatch アラームを使用してこれらの制限(CPUUtilization、DatabaseConnections、および BufferCacheHitRatio)をモニタリングおよびアラートし、リソースが頻繁に使用されているタイミングを把握することをお勧めします。
詳細については、以下の各トピックを参照してください。
クラスター接続の使用
クラスター内のすべての接続を使用するシナリオを検討します。たとえば、r5.2xlarge インスタンスの接続は 4,500 個 (および開いているカーソルは 450 個) に制限されています。3 つのインスタンスの Amazon DocumentDB クラスターを作成し、クラスターエンドポイントを使用してプライマリインスタンスにのみ接続する場合、開いている接続とカーソルのクラスター制限はそれぞれ 4,500 と 450 になります。コンテナでスピンアップする多くのワーカーを使用するアプリケーションを構築する場合、これらの制限に達する可能性があります。コンテナは、一度に多数の接続を開き、クラスターを飽和させます。
代わりに、レプリカセットとして Amazon DocumentDB クラスターに接続し、レプリカインスタンスに読み取りを分散できます。その後、クラスターで使用できる接続とカーソルの数をそれぞれ 13,500 と 1,350 に実質的に 3 倍にできます。クラスターにインスタンスを追加すると、読み取りワークロードの接続とカーソルの数が増えるだけです。クラスターへの書き込みの接続数を増やす必要がある場合は、インスタンスサイズを大きくすることをお勧めします。
注記
large インスタンス、xlarge インスタンス、および 2xlarge インスタンスの接続数は、インスタンスサイズが最大 4,500 に達するまで増加します。4xlarge インスタンス以上の場合、インスタンスあたりの最大接続数は 4,500 です。インスタンスタイプごとの制限の詳細については、「インスタンス制限」を参照してください。
通常、secondary の読み込み設定を使用してクラスターに接続することはお勧めしません。これは、クラスターにレプリカインスタンスがない場合、読み込みが失敗するためです。例えば、1 つのプライマリと 1 つのレプリカを持つ 2 つのインスタンスの Amazon DocumentDB クラスターがあるとします。レプリカに問題がある場合、secondary に設定されている接続プールからの読み取りリクエストは失敗します。secondaryPreferred の利点は、クライアントが接続する適切なレプリカインスタンスを見つけることができない場合、読み取りのためにプライマリにフォールバックすることです。
複数の接続プール
シナリオによっては、アプリケーションの読み取りに、書き込み後読み取り整合性が必要です。これは、Amazon DocumentDB のプライマリインスタンスからのみ提供できます。このようなシナリオでは、2 つのクライアント接続プールを作成できます。1 つは書き込み用、もう 1 つは書き込み後読み込み整合性を必要とする読み込み用です。そのためには、コードは次のようになります。
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
もう 1 つのオプションは、1 つの接続プールを作成し、特定のコレクションの読み込み設定を上書きすることです。
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
概要
クラスター内のリソースを有効に使用するために、レプリカセットモードを使用してクラスターに接続することをお勧めします。アプリケーションに適している場合は、レプリカインスタンスに読み取りを分散することで、アプリケーションの読み取りをスケーリングできます。
