翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon DocumentDB の 仕組み
Amazon DocumentDB (MongoDB 互換) は、フルマネージドの MongoDB と互換性のあるデータベースサービスです。Amazon DocumentDB では、MongoDB と同じアプリケーションコードを実行し、同じドライバーとツールを使用できます。Amazon DocumentDB は、MongoDB 3.6、4.0 および 5.0 と互換性を持っています。
トピック
Amazon DocumentDB を使用するときは、最初に クラスター を作成します。クラスターは、ゼロ以上のデータベースインスタンスと、これらのインスタンスのデータを管理する 1 つのクラスターボリュームで構成されます。Amazon DocumentDB の クラスターボリューム は、複数のアベイラビリティーゾーンにまたがる仮想データベースストレージボリュームです。アベイラビリティーゾーンごとに、クラスターデータのコピーがあります。
Amazon DocumentDB クラスターは、主要な 2 つのコンポーネントで構成されています。
-
クラスターボリューム - クラウドネイティブなストレージサービスを使用して、3 つのアベイラビリティーゾーンにわたって 6 つの方法でデータをレプリケートし、耐久性と可用性に優れたストレージを提供します。Amazon DocumentDB クラスターには 1 個のクラスターボリュームがあり、最大 128 TiB のデータを格納できます。
-
インスタンス - データベースの処理能力を提供し、クラスターストレージボリュームとの間でデータの書き込みと読み取りを行います。Amazon DocumentDB クラスターには 0 ~ 16 のインスタンスを持つことができます。
インスタンスは以下の 2 つのロールのいずれかを提供します。
-
プライマリインスタンス - 読み書きオペレーションをサポートし、クラスターボリュームに対するすべてのデータ変更を実行します。各 Amazon DocumentDB クラスターには1つのプライマリインスタンスがあります。
-
レプリカインスタンス - 読み取りオペレーションのみをサポートします。Amazon DocumentDB クラスターには、プライマリインスタンスに加えて 15 個までのレプリカを含めることができます。複数のレプリカがあると、読み取りワークロードを分散させることができます。さらに、別のアベイラビリティーゾーンにレプリカを配置することによって、クラスターの可用性を高めることもできます。
次の図は、Amazon DocumentDB クラスター内のクラスターボリューム、プライマリインスタンス、およびレプリカの関係を示しています。
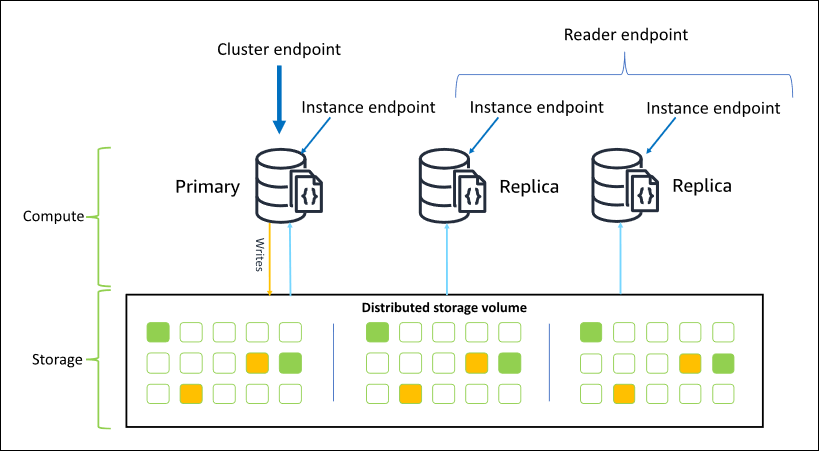
クラスターインスタンスは、同じインスタンスクラスである必要はなく、必要に応じてプロビジョニングおよび終了することができます。このアーキテクチャでは、ストレージとは無関係にクラスターのコンピューティング性能をスケールできます。
アプリケーションがプライマリインスタンスにデータを書き込むときに、プライマリはクラスターボリュームに堅牢な書き込みを実行します。次に、その書き込み (データではありません) の状態がアクティブな各レプリカにレプリケートされます。Amazon DocumentDB レプリカは書き込み処理に関与しないため、Amazon DocumentDB レプリカは読み取りスケーリングにとって有利となります。Amazon DocumentDB レプリカからの読み取りは、最短のレプリカラグで結果整合性があります。通常、プライマリインスタンスがデータを書き込んだ後、100 ミリ秒未満になります。レプリカからの読み込みは、プライマリに書き込まれた順序で読み込まれることが保証されます。レプリカラグは、データ変更のレートによって異なり、書き込みアクティビティが多い期間はレプリカラグが大きくなる可能性があります。詳細については、「Amazon DocumentDB のメトリクス」で ReplicationLag のメトリクスを参照してください。
Amazon DocumentDB エンドポイント
Amazon DocumentDB は複数の接続オプションを提供し、幅広いユースケースに対応します。Amazon DocumentDB クラスターのインスタンスに接続するには、インスタンスのエンドポイントを指定します。エンドポイントでは、ホストアドレスとポート番号がコロンで区切られています。
リーダーエンドポイントまたはインスタンスエンドポイントに接続する特定のユースケースがない限り、クラスターエンドポイントを使用してレプリカセットモード(「レプリカセットとしての Amazon DocumentDB に接続する」を参照)でクラスターに接続することをお勧めします。レプリカにリクエストをルーティングするには、アプリケーションの読み込み整合性要件に合わせて読み取りスケーリングを最大化する、ドライバー読み込み設定を選択します。secondaryPreferred 読み込み設定を使用すると、レプリカの読み取りを有効にし、プライマリインスタンスを解放してより多くの作業を行うことができます。
次のエンドポイントは、Amazon DocumentDB クラスターから取得できます。
クラスターエンドポイント
クラスターエンドポイントはクラスターの現在のプライマリインスタンスに接続します。このクラスターエンドポイントは、読み取りと書き込みの両方のオペレーションに使用できます。Amazon DocumentDB クラスターには、厳密には 1 つのクラスターエンドポイントがあります。
クラスターエンドポイントは、クラスターへの読み取り/書き込み接続のフェイルオーバーサポートを提供します。クラスターの現在のプライマリインスタンスが失敗し、クラスターに少なくとも 1 つのアクティブなリードレプリカがある場合、クラスターエンドポイントは自動的に接続リクエストを新しいプライマリインスタンスにリダイレクトします。Amazon DocumentDB クラスターに接続するときは、クラスターエンドポイントを使用し、レプリカセットモード(「レプリカセットとしての Amazon DocumentDB に接続する」を参照)でクラスターに接続することをお勧めします。
Amazon DocumentDB クラスターエンドポイントの例を以下に示します。
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
次の接続文字列は、このクラスターエンドポイントを使用した例です。
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
クラスターのエンドポイントを見つける方法については、「クラスターのエンドポイントの検索」を参照してください。
リーダーエンドポイント
リーダーエンドポイントは、クラスター内の使用可能なすべてのレプリカ間で、読み取り専用接続の負荷分散を行います。クラスターリーダーエンドポイントは、replicaSet モードで接続する場合、クラスターエンドポイントとして機能します。つまり、接続文字列では、レプリカセットパラメータは &replicaSet=rs0 となります。この場合、プライマリに対して書き込みオペレーションを実行できます。ただし、directConnection=true を指定してクラスターに接続した後、リーダーエンドポイントへの接続を経由して書き込みオペレーションを実行しようとすると、エラーが発生します。Amazon DocumentDB クラスターには、厳密には 1 つのリーダーエンドポイントがあります。
クラスターに 1 つの (プライマリ) インスタンスのみが含まれている場合、リーダーみエンドポイントはプライマリインスタンスのみに接続します。Amazon DocumentDB クラスターにレプリカインスタンスを追加した場合、リーダーエンドポイントは、アクティブになった時点で新しいレプリカへの読み取り専用接続を開きます。
Amazon DocumentDB クラスターのリーダーエンドポイントの例を以下に示します。
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
次の接続文字列は、リーダーエンドポイントを使用した例です。
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
リーダーエンドポイントは、読み込みリクエストではなく、読み取り専用接続の負荷分散を行います。一部のリーダーエンドポイント接続が他のリーダーエンドポイント接続よりも多く使用されている場合、読み込みリクエストはクラスター内のインスタンス間で均等に分散されない可能性があります。クラスターエンドポイントにレプリカセットとして接続し、secondaryPreferred 読み込み設定オプションを使用して、リクエストを分散することをお勧めします。
クラスターのエンドポイントを見つける方法については、「クラスターのエンドポイントの検索」を参照してください。
インスタンスエンドポイント
クラスター内で特定のインスタンスに接続するインスタンスエンドポイントです。現在のプライマリインスタンスのインスタンスエンドポイントは、読み込み/書き込みオペレーションに使用できます。ただし、リードレプリカのインスタンスエンドポイントに書き込みオペレーションを実行しようとすると、エラーが発生します。Amazon DocumentDB クラスターは、アクティブなインスタンスごとに 1 つのインスタンスのエンドポイントを持ちます。
インスタンスエンドポイントは、クラスターエンドポイントやリーダーエンドポイントが適切でないシナリオ向けに、特定のインスタンスへの接続の直接制御を提供します。ユースケースの例として、定期的な読み取り専用分析ワークロード用のプロビジョニングがあります。通常よりも大きいレプリカインスタンスのプロビジョニング、インスタンスエンドポイントを使用した新しいより大きなインスタンスへの直接接続、分析クエリの実行を行った後で、インスタンスを終了できます。インスタンスエンドポイントを使用すると、分析トラフィックが他のクラスターインスタンスに影響を与えるのを防ぐことできます。
次の例では、Amazon DocumentDB クラスターの 1 つのインスタンスのインスタンスエンドポイントを示します。
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
次の接続文字列は、このインスタンスエンドポイントを使用した例です。
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
注記
プライマリまたはレプリカとしてのインスタンスのロールは、フェイルオーバーイベントが原因で変更される可能性があります。アプリケーションで、特定のインスタンスエンドポイントがプライマリインスタンスであることを前提にしないでください。本番稼働アプリケーションのインスタンスエンドポイントに接続することはお勧めしません。代わりに、クラスターエンドポイントを使用し、レプリカセットモード(「レプリカセットとしての Amazon DocumentDB に接続する」を参照)でクラスターに接続することをお勧めします。インスタンスのフェイルオーバー優先度をより高度に制御する方法については、「Amazon DocumentDB クラスターの耐障害性について理解する」を参照してください。
クラスターのエンドポイントを見つける方法については、「インスタンスのエンドポイントの検索」を参照してください。
レプリカセットモード
レプリカセット名 rs0 を指定して、レプリカセットモードで Amazon DocumentDB クラスターエンドポイントに接続できます。レプリカセットモードで接続すると、[読み取り保証]、[書き込み保証]、および [読み取り設定] のオプションを指定できます。詳細については、「読み込み整合性」を参照してください。
レプリカセットモードで接続する接続文字列の例を次に示します。
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
レプリカセットモードで接続するときは、Amazon DocumentDB クラスターはドライバーとクライアントに対してレプリカセットとして表示されます。Amazon DocumentDB クラスターに対して追加、削除したインスタンスは、レプリカセット設定に自動的に反映されます。
各 Amazon DocumentDB クラスターは、デフォルト名が rs0 の 1 つのレプリカセットで構成されます。レプリカセットの名前を変更することはできません。
レプリカセットモードでのクラスターエンドポイントへの接続は、一般的な使用に推奨される方法です。
注記
Amazon DocumentDB クラスター内のすべてのインスタンスは、同じ TCP ポートで接続をリッスンします。
TLS サポート
TLS (Transport Layer Security) を使用した Amazon DocumentDB への接続方法については、「Encrypting data in transit」を参照してください。
Amazon DocumentDB のストレージ
Amazon DocumentDB のデータは クラスターボリューム に保存されます。これは、SSD (Solid State Drive) を使用する単一の仮想ボリュームです。クラスターボリュームはお客様のデータの 6 つのコピーで構成されます。これらのデータは、単一の AWS リージョンの複数のアベイラビリティーゾーン間で自動的にレプリケートされます。このレプリケーションにより、データの高い耐久性が保証され、データ損失の可能性が低くなります。また、データのコピーが他のアベイラビリティーゾーンにすでに存在するため、フェイルオーバー中のクラスターの可用性が高まります。これらのコピーは、継続して Amazon DocumentDB クラスター内のインスタンスに対するデータリクエストを処理できます。
データストレージに対する請求方法
Amazon DocumentDB は、データ量が増えるにつれて、クラスターボリュームのサイズを自動的に増やします。Amazon DocumentDB クラスターボリュームは最大サイズの 128 TiB まで拡張できますが、Amazon DocumentDBクラスターボリュームで使用する領域に対してのみ課金されます。Amazon DocumentDB 4.0 以降では、コレクションやインデックスの削除などでのデータを削除すると、割り当てられた領域全体が相応に減少します。したがって、不要になったコレクション、インデックス、データベースを削除することで、ストレージ料金を削減できます。Amazon DocumentDB バージョン 3.6 では、データを削除すると解放される領域をクラスターボリュームで再利用できますが、ボリューム自体のサイズが小さくなることはありません。バージョン 3.6 では、解放された領域が再利用されていても、コレクションまたはインデックスを削除してもストレージの変更が見られない場合があります。
注記
Amazon DocumentDB 3.6 では、ストレージコストは「高水準点 (high water mark)」 (任意の時点で Amazon DocumentDB クラスター用に割り当てられた最大量) に基づきます。大量の一時情報を作成したり、古い不要データの削除前に新規データを大量にロードする ETL プラクティスを避けることによってコストを管理できます。Amazon DocumentDB クラスターからデータを削除したことによって大量の割り当て済み未使用領域が発生した場合に、高水準点をリセットするには、mongodump や mongorestore などのツールを使用して論理データダンプを作成し、新しいクラスターに復元する必要があります。スナップショットを作成および復元しても、割り当てられたストレージは削減されません。これは、基になるストレージの物理的なレイアウトが、復元されたスナップショットでも変更されないためです。
注記
mongodump や mongorestore などのユーティリティを使用すると、ストレージボリュームに対して読み書きするデータのサイズに応じた I/O 料金が発生します。
Amazon DocumentDB データストレージおよび I/O の料金に関する情報は、「Amazon DocumentDB (MongoDB 互換性) の料金
Amazon DocumentDB レプリケーション
Amazon DocumentDB クラスターでは、各レプリカインスタンスが独立したエンドポイントを公開します。これらのレプリカエンドポイントは、クラスターボリュームのデータへの読み取り専用アクセスを提供します。また、複数のレプリケートされたインスタンス経由で、データの読み取りワークロードをスケールできます。さらに、データ読み取りのパフォーマンスを向上させ、Amazon DocumentDB クラスター内のデータの可用性を高めるためにも有効です。Amazon DocumentDB レプリカはフェイルオーバーターゲットでもあり、Amazon DocumentDB クラスターのプライマリインスタンスに障害が発生した場合は迅速に昇格されます。
Amazon DocumentDB の信頼性
Amazon DocumentDB は、信頼性、耐久性、および耐障害性を持つように設計されています。(可用性を高めるため、Amazon DocumentDB クラスターを設定し、異なるアベイラビリティーゾーンに複数のレプリカインスタンスを存在させる必要があります。) Amazon DocumentDB には、信頼性の高いデータベースソリューションとなるいくつかの自動機能も含まれています。
ストレージの自動修復
Amazon DocumentDB では、データの複数のコピーを 3 つのアベイラビリティーゾーンに保持し、ストレージの障害によってデータが失われる可能性を最小限に抑えます。Amazon DocumentDB は、クラスターボリュームの障害を自動的に検出します。クラスターボリュームのセグメントで障害が発生すると、Amazon DocumentDB はすぐにそのセグメントを修復します。クラスターボリュームを構成する他のボリュームからのデータを使用して、修復されたセグメントのデータが最新であるようにします。その結果、Amazon DocumentDB ではデータ損失が回避され、インスタンス障害から回復するためのポイントインタイム復元を実行する必要性が低減します。
存続できるキャッシュのウォームアップ
Amazon DocumentDB はそのページキャッシュをデータベースとは別のプロセスで管理するため、ページキャッシュはデータベースとは無関係に存続できます。予期できないデータベース障害が発生した場合でも、ページキャッシュはメモリに保持されます。これにより、バッファプールはデータベースの再起動時に最新の状態にウォームアップされます。
クラッシュ回復
Amazon DocumentDB は、クラッシュからほぼ瞬時に回復し、アプリケーションデータを提供し続けるように設計されています。Amazon DocumentDB は、クラッシュ回復を並列スレッドで非同期に実行します。これにより、クラッシュのほぼ直後にデータベースを開き、使用できるようにします。
リソースガバナンス
Amazon DocumentDB は、ヘルスチェックなど、サービス内で重要なプロセスを実行するために必要なリソースを保護します。これを行うには、インスタンスのメモリ負荷が高い場合、Amazon DocumentDB はリクエストをスロットルします。その結果、一部のオペレーションは、メモリ負荷が低下するのを待つためにキューに入れられる場合があります。メモリ負荷が続くと、キューに入れられたオペレーションがタイムアウトすることがあります。次の CloudWatch メトリクスを使用して、メモリ不足によるサービススロットリングオペレーションを監視できます: LowMemThrottleQueueDepth、LowMemThrottleMaxQueueDepth、LowMemNumOperationsThrottled、LowMemNumOperationsTimedOut。詳細については、「CloudWatch によるAmazon DocumentDB のモニタリング」を参照してください。LowMem CloudWatch メトリクスの結果として、インスタンスに持続的なメモリ負荷が見られる場合は、インスタンスをスケールアップしてワークロードに追加のメモリを提供することをお勧めします。
読み込み設定のオプション
Amazon DocumentDB は、3 つのアベイラビリティーゾーンにわたってデータを 6 回レプリケートするクラウドネイティブな共有ストレージサービスを使用して、高レベルの耐久性を提供します。Amazon DocumentDB は、耐久性を実現するためにデータを複数のインスタンスにレプリケートすることに依存しません。クラスターのデータは、1 つのインスタンスが含まれているか、15 個のインスタンスが含まれているかにかかわらず、耐久性に優れています。
書き込みの耐久性
Amazon DocumentDB は、独自の分散型の耐障害性がある自己修復機能を備えたストレージシステムを使用します。このシステムは、データの 6 つのコピー (V=6) を 3 つの AWS アベイラビリティーゾーンにレプリケートして、高可用性と耐久性を実現します。Amazon DocumentDB はデータを書き込む際、クライアントへの書き込みを確認する前に、すべての書き込みが大半のノードに永続的にレコードされることを確認します。3 ノードの MongoDB レプリカセットを実行している場合は、書き込み確認として {w:3, j:true} を使用すると、Amazon DocumentDB と比較したときに可能な限り最高の設定を得られます。
Amazon DocumentDB クラスターへの書き込みは、クラスターのライターインスタンスによって処理される必要があります。リーダーに書き込もうとすると、エラーが発生します。Amazon DocumentDB プライマリインスタンスからの確認済み書き込みは耐久性があり、ロールバックできません。Amazon DocumentDB はデフォルトで高い耐久性に優れており、耐久性に優れない書き込みオプションはサポートされていません。耐久性レベルを変更することはできません (これは、書き込みについてです)。Amazon DocumentDB は w=anything を無視し、事実上 w: 3 と j: true となります。この設定を減らすことはできません。
Amazon DocumentDB アーキテクチャではストレージとコンピューティングが分離されているため、単一インスタンスのクラスターは高い耐久性を持ちます。耐久性はストレージレイヤーで処理されます。その結果、1 つのインスタンスと 3 つのインスタンスを持つ Amazon DocumentDB クラスターは、同じレベルの耐久性を実現します。データの高い耐久性を保持しながら、具体的なユースケースに対してクラスターを設定できます。
Amazon DocumentDB クラスターへの書き込みは、1 つのドキュメント内でアトミックです。
Amazon DocumentDB は wtimeout オプションをサポートしておらず、値が指定された場合はエラーを返しません。プライマリ Amazon DocumentDB インスタンスへの書き込みは、無期限にブロックしないことが保証されます。
読み込みの分離
Amazon DocumentDB インスタンスからの読み取りでは、クエリが開始される前に、耐久性があるデータのみが返されます。読み込みで、クエリの実行が開始された後で変更されたデータが返されることはなく、どのような状況でもダーティーリードが可能になることもありません。
読み込み整合性
Amazon DocumentDB クラスターから読み取られたデータは耐久性があり、ロールバックされません。Amazon DocumentDB 読み取りの読み取り整合性は、リクエストまたは接続の読み取り設定を指定して変更できます。Amazon DocumentDB は、耐久性に優れない読み取りオプションをサポートしていません。
Amazon DocumentDB クラスターのプライマリインスタンスからの読み取りは、通常のオペレーション条件下では整合性が高く、書き込み後読み取りの整合性を実現します。書き込みとそれ以降の読み取りの間にフェイルオーバーイベントが発生した場合、システムは高い整合性を持たない読み取りを一時的に返すことがあります。リードレプリカからのすべての読み取りは、結果的に整合性を持ち、同じ順序でデータを返します。レプリカラグは多くの場合、100 ミリ秒未満です。
Amazon DocumentDB 読み取り設定
Amazon DocumentDB は、レプリカセットモードのクラスターエンドポイントからデータを読み取るときのみ、読み取り設定オプションをサポートします。読み取り設定オプションの設定により、MongoDB クライアントまたはドライバーが Amazon DocumentDB クラスターでインスタンスに読み取りリクエストをルーティングする方法に影響が生じます。特定のクエリ用に読み込み設定オプションを指定するか、MongoDB ドライバーの全般オプションとして指定できます。(読み込み設定オプションの設定方法については、クライアントまたはドライバーのドキュメントを参照してください。)
クライアントまたはドライバーがレプリカセットモードの Amazon DocumentDB クラスターエンドポイントに接続していない場合、読み取り設定の指定結果は定義されていません。
Amazon DocumentDB は、読み取り設定としての タグセット の設定はサポートしていません。
サポートされている読み込み設定オプション
-
primary-primary読み取り設定を指定すると、すべての読み取りがクラスターのプライマリインスタンスにルーティングされます。プライマリインスタンスが使用できない場合、読み込みオペレーションは失敗します。primary読み込み設定により、書き込み後読み取りの整合性が得られ、高可用性および読み込みスケーリングよりも書き込み後読み取りの整合性を優先するユースケースに適しています。次の例では、
primary読み取り設定を指定します。db.example.find().readPref('primary') -
primaryPreferred-primaryPreferred読み取り設定を指定すると、通常のオペレーションでは読み取りがプライマリインスタンスにルーティングされます。プライマリフェイルオーバーが発生した場合、クライアントはレプリカにリクエストをルーティングします。primaryPreferred読み取り設定により、通常のオペレーションで書き込み後読み取り整合性と、フェイルオーバーイベント中の結果整合性のある読み込みが得られます。primaryPreferred読み取り設定は、読み込みスケーリングよりも書き込み後読み取り整合性を優先するが、それでも高可用性を必要とするユースケースに適しています。次の例では、
primaryPreferred読み取り設定を指定します。db.example.find().readPref('primaryPreferred') -
secondary-secondary読み取り設定を指定すると、読み取りはレプリカのみにルーティングされ、プライマリインスタンスにルーティングされることはありません。クラスター内のレプリカインスタンスがない場合、読み込みリクエストは失敗します。secondary読み取り設定では、結果整合性のある読み込みが得られ、高可用性および書き込み後の読み取り整合性よりもプライマリインスタンスの書き込みスループットを優先するユースケースに適しています。次の例では、
secondary読み取り設定を指定します。db.example.find().readPref('secondary') -
secondaryPreferred-secondaryPreferred読み取り設定を指定すると、1 つ以上のレプリカがアクティブになったときに、読み取りはリードレプリカにルーティングされます。クラスター内にアクティブなレプリカインスタンスがない場合、読み取りリクエストはプライマリインスタンスにルーティングされます。secondaryPreferred読み取り設定では、読み取りがリードレプリカによって対応されたときに、結果整合性のある読み込みが得られます。これにより、読み取りがプライマリインスタンスによって処理されたときに (フェイルオーバーイベントがなければ)、書き込み後読み取り整合性が得られます。secondaryPreferred読み取り設定は、書き込み後読み取り整合性よりも読み取りスケーリングや高可用性を優先するユースケースに適しています。次の例では、
secondaryPreferred読み取り設定を指定します。db.example.find().readPref('secondaryPreferred') -
nearest-nearest読み取り設定を指定すると、クライアントと Amazon DocumentDB クラスター内のすべてのインスタンス間で測定されたレイテンシーのみに基づいて、読み取りがルーティングされます。nearest読み取り設定では、読み取りがリードレプリカによって対応されたときに、結果整合性のある読み込みが得られます。これにより、読み取りがプライマリインスタンスによって処理されたときに (フェイルオーバーイベントがなければ)、書き込み後読み取り整合性が得られます。nearest読み取り設定は、書き込み後読み取り整合性と読み込みスケーリングよりも、可能な限り低い読み取りレイテンシーと高可用性の達成を優先するユースケースに適しています。次の例では、
nearest読み取り設定を指定します。db.example.find().readPref('nearest')
高可用性
Amazon DocumentDB は、レプリカをプライマリインスタンスのフェイルオーバーターゲットとして使用して、可用性の高いクラスター設定をサポートします。プライマリインスタンスが失敗すると、Amazon DocumentDB レプリカが新しいプライマリとして昇格します。ここでは、プライマリインスタンスに対して行われた読み取り要求と書き込み要求が失敗して例外が発生するときに、短時間の中断が発生します。
Amazon DocumentDB クラスターにレプリカが含まれていない場合は、障害の発生時にプライマリインスタンスが再作成されます。ただし、Amazon DocumentDB レプリカの昇格は、プライマリインスタンスを再作成するよりもより高速です。したがって、1 つ以上の Amazon DocumentDB レプリカをフェイルオーバーターゲットとして作成することが推奨されます。
フェイルオーバーターゲットとして使用することを目的としたレプリカは、プライマリインスタンスと同じインスタンスのものである必要があります。これらは、プライマリとは別のアベイラビリティーゾーンでプロビジョニングする必要があります。フェイルオーバーターゲットとして設定されるレプリカを制御できます。高可用性のための Amazon DocumentDB の設定に関するベストプラクティスについては、「Amazon DocumentDB クラスターの耐障害性について理解する」を参照してください。
読み取りスケーリング
Amazon DocumentDB レプリカは、読み取りスケーリングに最適です。これらは、クラスターボリュームでの読み取りオペレーション専用です。つまり、レプリカは書き込みを処理しません。データのレプリケーションは、インスタンス間ではなくクラスターボリューム内で行われます。したがって、各レプリカのリソースはクエリの処理専用となり、データのレプリケートおよび書き込み用とはなりません。
アプリケーションがより多くの読み取り容量を必要とする場合、すぐにクラスターにレプリカを追加できます (通常は 10 分未満)。読み取り容量要件が減少した場合、不要なレプリカを削除できます。Amazon DocumentDB レプリカを使用すると、必要な読み取り容量のみのお支払いで済みます。
Amazon DocumentDB は、読み取り設定オプションの使用を通じて、クライアント側の読み取りスケーリングをサポートします。詳細については、「Amazon DocumentDB 読み取り設定」を参照してください。
TTL 削除
バックグラウンドプロセスによって達成された TTL インデックスエリアからの削除は、ベストエフォートであり、特定の期間内に保証されるものではありません。インスタンスサイズ、インスタンスリソースの使用率、ドキュメントサイズ、全体的なスループットなどの要因は、TTL 削除のタイミングに影響を与える可能性があります。
TTL モニタがドキュメントを削除すると、削除ごとに IO コストが発生するため、請求額が増加します。スループットと TTL 削除レートが増加する場合、IO 使用量の増加により、請求額が増加することが予想されます。
既存のコレクションに TTL インデックスを作成する場合、インデックスを作成する前に、期限切れのドキュメントをすべて削除する必要があります。現在の TTL 実装は、コレクション内のドキュメントのごく一部を削除するために最適化されています。これは、最初からコレクションでTTLが有効化されていた場合であり、一度に多数のドキュメントを削除する必要がある場合、必要以上に高い IOPS が発生する可能性があるからです。
TTL インデックスを作成してドキュメントを削除する代わりに、時間に基づいてドキュメントをコレクションにセグメント化し、ドキュメントが不要になったときにそれらのコレクションをドロップすることができます。例えば、週に 1 つのコレクションを作成し、IO コストをかけずにドロップできます。これは、TTL インデックスを使用するよりもコスト効率が大幅に向上します。
有料リソース
有料 Amazon DocumentDB リソースの特定
Amazon DocumentDB はフルマネージドデータベースサービスであるため、インスタンス、ストレージ、I/O、バックアップ、およびデータ転送が有料です。詳細については、「Amazon DocumentDB (MongoDB 互換) の料金
アカウント内の請求対象リソースを検出し、そのリソースを削除する場合は、 AWS Management Console または を使用できます AWS CLI。
の使用 AWS Management Console
を使用すると AWS Management Console、特定の に対してプロビジョニングした Amazon DocumentDB クラスター、インスタンス、スナップショットを検出できます AWS リージョン。
クラスター、インスタンス、およびスナップショットを検出するには
にサインインし AWS Management Console、https://console.aws.amazon.com/docdb
で Amazon DocumentDB コンソールを開きます。 -
デフォルトのリージョン以外のリージョンで請求対象リソースを検出するには、画面の右上隅で、検索 AWS リージョン する を選択します。
-
ナビゲーションペインで、該当する有料リソースのタイプ ([クラスター]、[インスタンス]、または [スナップショット]) を選択します。
-
そのリージョンについてプロビジョニングされたすべてのクラスター、インスタンス、またはスナップショットが右側のペインに表示されます。クラスター、インスタンス、およびスナップショットにたいして料金が発生します。
の使用 AWS CLI
を使用すると AWS CLI、特定の に対してプロビジョニングした Amazon DocumentDB クラスター、インスタンス、スナップショットを検出できます AWS リージョン。
クラスターおよびインスタンスを見つけるには
次のコードは、指定されたリージョンのすべてのクラスターとインスタンスをリスト表示しています。デフォルトのリージョンでクラスターとインスタンスを検索する場合は、--region パラメータを省略できます。
Linux、macOS、Unix の場合:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Windows の場合:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
このオペレーションによる出力は、次のようになります。
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",スナップショットを見つけるには
次のコードは、指定されたリージョンのすべてのスナップショットをリスト表示しています。デフォルトのリージョンでスナップショットを検索する場合は、--region パラメータを省略できます。
Linux、macOS、Unix の場合:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Windows の場合:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
このオペレーションによる出力は、次のようになります。
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]削除する必要があるのは、manual スナップショットのみです。Automated スナップショットは、クラスターを削除すると削除されます。
不要な有料リソースの削除
クラスターを削除するには、まずクラスター内のインスタンスをすべて削除する必要があります。
-
インスタンスを削除するには、「Amazon DocumentDB インスタンスの削除」を参照してください。
重要
クラスター内のインスタンスを削除しても、そのクラスターに関連付けられているストレージとバックアップの使用量に対して料金が発生します。すべての課金を停止するには、クラスターと手動スナップショットも削除する必要があります。
-
クラスターを削除するには、「Amazon DocumentDB クラスターの削除」を参照してください。
-
手動スナップショットを削除するには、「クラスタースナップショットの削除」を参照してください。
