Amazon Forecast は新規顧客には利用できなくなりました。Amazon Forecast の既存のお客様は、通常どおりサービスを引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
DeepAR+ アルゴリズム
Amazon Forecast DeepAR は、再帰型ニューラルネットワーク (RNN) を使用してスカラー (1 次元) 時系列を予測するための、教師あり学習アルゴリズムです。自己回帰和分移動平均 (ARIMA) や指数平滑法 (ETS) などの古典的な予測方法は、1 つのモデルを個々の時系列に適合させ、そのモデルを使用して時系列を未来に当てはめます。ただし多くのアプリケーションでは、一連の横断的な単位にわたって同様の時系列が多数あります。これらの時系列グループは、さまざまな製品、サーバーの負荷、およびウェブページのリクエストを要求します。この場合、これらすべての時系列で、連携して単一のモデルをトレーニングすることが効果的です。DeepAR+ はこのアプローチを使用します。データセットに何百もの特徴の時系列データが含まれている場合、DeepAR+ アルゴリズムは標準の ARIMA や ETS メソッドよりも優れています。トレーニングしたモデルを使用して、トレーニングしたモデルと似た新しい時系列の予測を生成することもできます。
Python ノートブック
DeepAR+ アルゴリズムの使用に関するステップバイステップガイドについては、「Getting Started with DeepAR+
DeepAR+ の仕組み
トレーニング中、DeepAR+ はトレーニングデータセットとオプションのテストデータセットを使用します。テストデータセットは、トレーニングされたモデルを評価するために使用されます。一般的に、トレーニングデータセットとテストデータセットに同じ一連の時系列を含める必要はありません。特定のトレーニングセットでトレーニングされたモデルを使用すると、トレーニングセット内の時系列の今後の予測と他の時系列の予測を生成できます。トレーニングデータセットとテストデータセットはどちらも (可能な場合は複数の) ターゲット時系列で構成されています。オプションで、特徴時系列のベクトルとカテゴリ別特徴のベクトルに関連付けることができます (詳細については、SageMaker AI デベロッパーガイドのDeepAR 入出力インターフェイス」を参照してください)。次の例は、インデックス i が付されたトレーニングデータセットの要素に対してこれがどのように機能するかを示しています。トレーニングデータセットは、ターゲット時系列 zi,t、および 2 つの関連する特徴の時系列 xi,1,t と xi,2,t から構成されます。
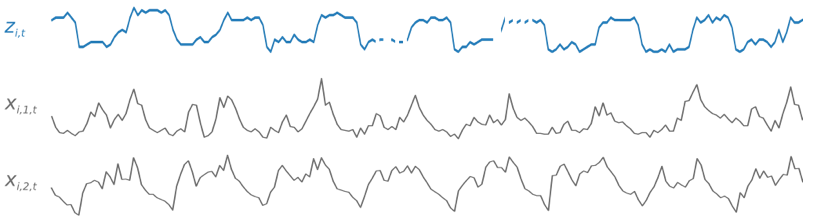
ターゲット時系列には欠落した値が含まれている可能性があります (グラフでは時系列の切れ目で示されています)。DeepAR+ は、今後認識される特徴の時系列のみをサポートします。これにより、事実に反した「what-if」シナリオを実行できます。たとえば、「製品の価格を何らかの方法で変更した場合はどうなりますか?」などです。
各ターゲット時系列は、複数のカテゴリ別特徴に関連付けることもできます。これらを使用して、時系列が特定のグループに属していることをエンコードできます。カテゴリ別特徴を使用すると、モデルはそれらのグループ化の典型的な動作を学習することができ、それによって精度が向上します。モデルはこれを実装するために、グループ内のすべての時系列の共通プロパティをキャプチャする各グループの埋め込みベクトルを学習します。
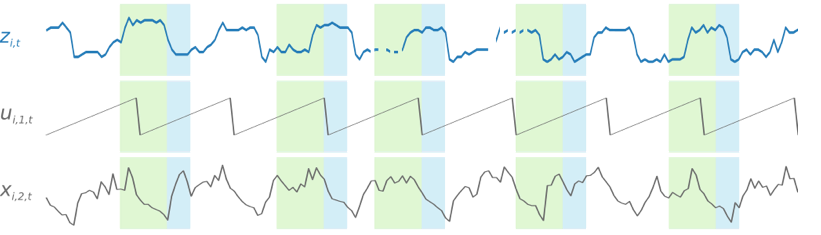
週末の急増などの時間依存パターンの学習を容易にするために、DeepAR+ は時系列の詳細度に基づいて特徴の時系列を自動的に作成します。たとえば、DeepAR+ は、週に 1 回の頻度で 2 つの特徴の時系列 (月初からの日付と年初からの日付) を作成します。DeepAR+ は、このように派生した特徴の時系列を使用するだけでなく、トレーニングと推論の間にユーザーが提供するカスタムの特徴の時系列も使用します。次の例は、派生した 2 つの時系列の特徴を示しています。ui,1,t はその日の時間を表し、ui,2,t はその曜日を表します。

DeepAR+ は、データの頻度とトレーニングデータのサイズに基づいて、これらの特徴の時系列を自動的に組み込みます。次の表に、サポートされている基本的な頻度ごとに、派生させることのできる特徴を示します。
| 時系列の頻度 | 派生する特徴 |
|---|---|
| 分 | 分、時、曜日、月初からの日付、年初からの日付 |
| 時間 | 時、曜日、月初からの日付、年初からの日付 |
| 日。 | 曜日、月初からの日付、年初からの日付 |
| 週 | 月初からの週、年初からの週 |
| 月 | 月 |
DeepAR+ モデルは、トレーニングデータセットの各時系列からいくつかのトレーニング例をランダムにサンプリングすることによってトレーニングされます。各トレーニング例は、事前定義された固定長を持つ一対の隣接コンテキストと予測ウィンドウで構成されています。context_length ハイパーパラメータは、どの程度の過去まで遡ってネットワークを調べられるのかを制御し、ForecastHorizon パラメータは、どの程度の未来まで予測を生成できるかを制御します。トレーニング中、Amazon Forecast は、指定された予測長より時系列が短いトレーニングデータセット内の要素を無視します。次の例は、要素 i から抽出された、コンテキストの長さ (緑でハイライト表示) が 12 時間、予測の長さ (青でハイライト表示) が 6 時間の 5 つのサンプルを示しています。簡潔にするために、特徴の時系列 xi,1,t と ui,2,t は除外しました。
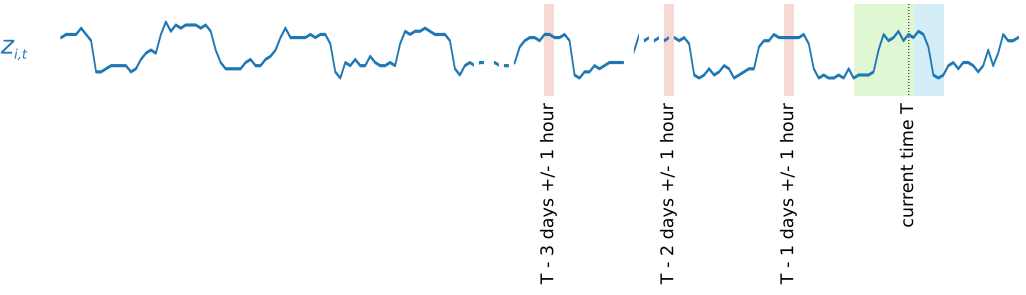
季節的パターンをキャプチャするために、DeepAR+ はターゲット時系列から遅延した (過去の期間の) 値も自動的にフィードします。1 時間に 1 回の頻度で各時間インデックス t = T のサンプルを取得したこの例では、モデルは zi,t 値を公開します。これらは過去約 1、2、および 3 日 (ピンクでハイライト表示) に発生したものです。
トレーニングされたモデルは、推論のために、トレーニング中に使用されたかどうかにかかわらず、ターゲット時系列を入力として受け取り、それ以降の ForecastHorizon 値の確率分布を予測します。DeepAR+ はデータセット全体についてトレーニングされるため、予測では同様の時系列からの学習パターンが考慮されます。
DeepAR+ の背後にある数学の詳細については、コーネル大学ライブラリウェブサイトの DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks (DeepAR: 自己回帰反復ネットワークによる確率予測)
DeepAR+ ハイパーパラメータ
次の表は、DeepAR+ アルゴリズムで使用できるハイパーパラメータのリストです。太字のパラメータは、ハイパーパラメータ最適化 (HPO) に関与します。
| Parameter Name | 説明 |
|---|---|
context_length |
予測を生成する前にモデルが読み込む時間ポイントの数。このパラメータの値は、
|
epochs |
トレーニングデータへのパスの最大数。最適な値は、データサイズと学習レートによって異なります。データセットが小さく、学習率が低くなると、いずれもエポック数が多くなり、良好な結果が得られます。
|
learning_rate |
トレーニングで使用する学習レート。
|
learning_rate_decay |
学習率が低下するレート。学習レートは多くても
|
likelihood |
モデルは確率予測を生成し、分散の変位値を提供してサンプルを返すことができます。データによっては、不確実性予測に使用される適切な尤度 (ノイズモデル) を選択します。 有効値
|
max_learning_rate_decays |
学習レートの減少が起きた場合のその最大回数。
|
num_averaged_models |
DeepAR+ では、トレーニングの軌跡に複数のモデルが含まれる可能性があります。各モデルの予測の長所と短所は異なる場合があります。DeepAR+ は、すべてのモデルの長所を活用するために、モデルの動作を平均化できます。
|
num_cells |
RNN の非表示のレイヤーごとに使用するセルの数。
|
num_layers |
RNN の非表示レイヤーの数。
|
DeepAR+ モデルを調整する
Amazon Forecast DeepAR+ モデルを調整するには、以下の推奨事項に従って、トレーニングプロセスとハードウェア構成を最適化してください。
プロセス最適化のためのベストプラクティス
最良の結果を得るためには、以下の推奨事項に従ってください。
-
トレーニングとテストのデータセットを分割する場合を除き、トレーニングとテストのため、および推論のためにモデルを呼び出す際には、常に時系列全体を提供します。
context_lengthの設定方法にかかわらず、時系列を分割したり、その一部だけを指定したりしないでください。モデルは、遅延値の特徴には、context_lengthより後ろのデータポイントを使用します。 -
モデルを調整するために、データセットをトレーニングデータセットとテストデータセットに分割することができます。典型的な評価シナリオでは、トレーニングで使用したのと同じ時系列でモデルをテストする必要がありますが、トレーニング中に表示される最後の時間ポイントの直後に発生する
ForecastHorizon時間ポイントでモデルをテストします。これらの基準を満たすトレーニングデータセットとテストデータセットを作成するには、データセット全体 (すべての時系列) をテストデータセットとして使用し、トレーニング用の各時系列から最後のForecastHorizonポイントを削除します。このようにトレーニング中には、モデルはテスト時に評価される時間ポイントのターゲット値を確認しません。テストフェーズでは、テストデータセット内の各時系列の最後のForecastHorizonポイントが保留され、予測が生成されます。その後、予測が最後のForecastHorizonポイントの実際の値と比較されます。より複雑な評価を作成するには、テストデータセット内で時系列を複数回繰り返しますが、それぞれ異なる終了ポイントで切り捨てます。これにより、さまざまな時間ポイントからの複数の予測で平均化された精度メトリクスが生成されます。 -
ForecastHorizonに非常に大きい値 (> 400) を使用することは避けてください。このような値を設定すると、モデルの速度が遅くなり、精度が低下します。未来の予測をさらに生成するには、より高い頻度で情報を集約することを検討してください。例えば、1minではなく5minを使用します。 -
遅延のために、モデルは
context_lengthより前を確認することができます。そのため、このパラメータを大きい値に設定する必要はありません。このパラメータの開始点として推奨されるのは、ForecastHorizonと同じ値です。 -
可能な限り多くの時系列で DeepAR+ モデルをトレーニングします。単一の時系列でトレーニングされた DeepAR+ モデルも問題なく機能する可能性はありますが、ARIMA や ETS などの標準的な予測方法を使用すると、正確性が増し、そのユースケースへの適合性が高まるように調整される可能性があります。データセットに何百もの特徴の時系列データが含まれている場合、DeepAR+ は標準の方法より優れた性能を発揮するようになります。DeepAR+ では現在、すべてのトレーニング時系列にわたって利用可能な観測の総数が 300 以上であることが要求されます。
