Lambda 関数のスケーリングについて
同時実行数とは、AWS Lambda 関数が同時に処理できる未完了のリクエストの数のことです。Lambda は、同時実行リクエストごとに、実行環境の個別のインスタンスをプロビジョニングします。関数が受け取るリクエストが増えると、Lambda が実行環境数のスケーリングを自動的に処理し、これはアカウントの同時実行上限に達するまで行われます。Lambda はアカウントに対し、1 つの AWS リージョン内のすべての関数全体での合計数 1,000 を上限とした同時実行をデフォルトで提供しています。特定のアカウントニーズをサポートするため、クォータの引き上げをリクエスト
このトピックでは、Lambda での同時実行数と関数スケーリングについて説明します。このトピックを読み終える頃には、同時実行を計算する、2 つの主な同時実行コントロールオプション (予約された同時実行とプロビジョニングされた同時実行) を視覚化する、適切な同時実行コントロール設定を見積もる、およびさらなる最適化のためのメトリクスを表示する方法を理解できるようになります。
セクション
同時実行の概要と視覚化
Lambda は、セキュアで分離された実行環境で関数を呼び出します。リクエストを処理するため、Lambda はまず実行環境を初期化 (初期化フェーズ) してから、それを使用して関数を呼び出す (呼び出しフェーズ) 必要があります。

注記
実際の初期化と呼び出しの所要時間は、選択したランタイムや Lambda 関数コードなど、さまざまな要因に応じて異なります。上記の図は、初期化フェーズと呼び出しフェーズの所要時間の正確な割合を表すものではありません。
上記の図では、長方形を使用して単一の実行環境を表しています。関数が最初のリクエスト (ラベル 1 が付いた黄色い円) を受け取ると、Lambda が初期化フェーズ中に新しい実行環境を作成し、メインハンドラー外でコードを実行します。次に、Lambda は呼び出しフェーズ中に関数のメインハンドラーコードを実行します。この実行環境は、このプロセス全体を通じてビジー状態になり、他のリクエストを処理することはできません。
この実行環境は、Lambda が最初のリクエストの処理を終了した時点で、同じ関数に対する追加のリクエストを処理できるようになります。Lambda が、後続のリクエストのために実行環境を再度初期化する必要はありません。
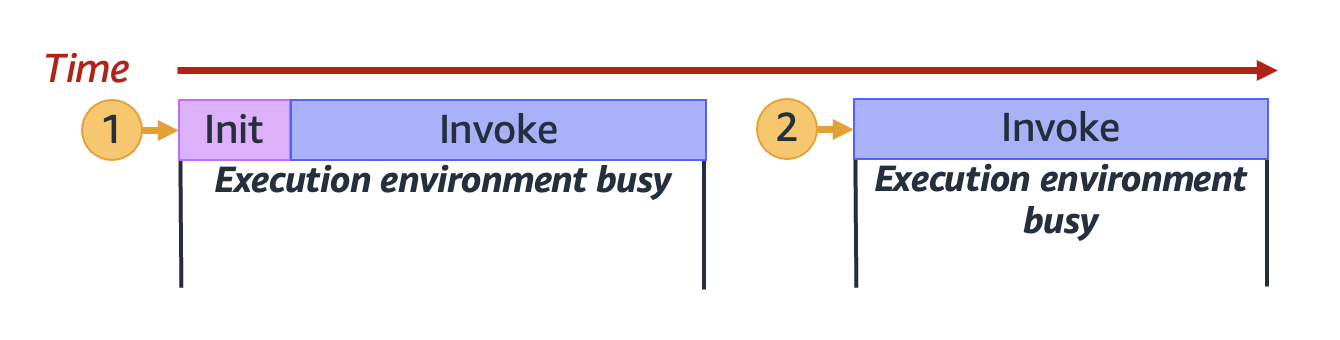
上記の図では、Lambda が実行環境を再利用して 2 番目のリクエスト (ラベル 2 が付いた黄色の円) を処理します。
これまでは、実行環境の単一のインスタンス (つまり、1 個の同時実行) のみに焦点を当ててきました。実際には、すべての受信リクエストを処理するために、Lambda は複数の実行環境インスタンスを並行してプロビジョニングする必要がある場合があります。関数が新しいリクエストを受け取ると、以下の 2 つのいずれかが行われる可能性があります。
-
事前に初期化された実行環境インスタンスが利用できる場合は、Lambda がそれを使用してリクエストを処理する。
-
利用できない場合は、Lambda が新しい実行環境インスタンスを作成してリクエストを処理する。
例として、関数が 10 個のリクエストを受け取った場合について検証してみましょう。

上記の図では、各横棒が単一の実行環境インスタンス (A から F でラベル付けされたもの) を表しています。Lambda はこのように各リクエストを処理します。
| [リクエスト] | Lambda の動作 | 推論 |
|---|---|---|
|
1 |
新しい環境 A をプロビジョニング |
これは最初のリクエストで、利用できる実行環境インスタンスはありません。 |
|
2 |
新しい環境 B をプロビジョニング |
既存の実行環境インスタンス A がビジー状態。 |
|
3 |
新しい環境 C をプロビジョニング |
既存の実行環境インスタンス A と B がどちらもビジー状態。 |
|
4 |
新しい環境 D をプロビジョニング |
既存の実行環境インスタンス A、B、および C のすべてがビジー状態。 |
|
5 |
新しい環境 E をプロビジョニング |
既存の実行環境インスタンス A、B、C、および D のすべてがビジー状態。 |
|
6 |
環境 A を再利用 |
実行環境インスタンス A がリクエスト 1 の処理を完了し、利用可能になっている。 |
|
7 |
環境 B を再利用 |
実行環境インスタンス B がリクエスト 2 の処理を完了し、利用可能になっている。 |
|
8 |
環境 C を再利用 |
実行環境インスタンス C がリクエスト 3 の処理を完了し、利用可能になっている。 |
|
9 |
新しい環境 F をプロビジョニング |
既存の実行環境インスタンス A、B、C、D、および E のすべてがビジー状態。 |
|
10 |
環境 D を再利用 |
実行環境インスタンス D がリクエスト 4 の処理を完了し、利用可能になっている。 |
関数が受け取る同時リクエストが増えると、Lambda はそれに応じて実行環境インスタンスの数をスケールアップします。以下のアニメーションは、同時リクエストの数を経時的に追跡するものです。
上記のアニメーションを 6 つの異なる時点で停止すると、以下の図が得られます。
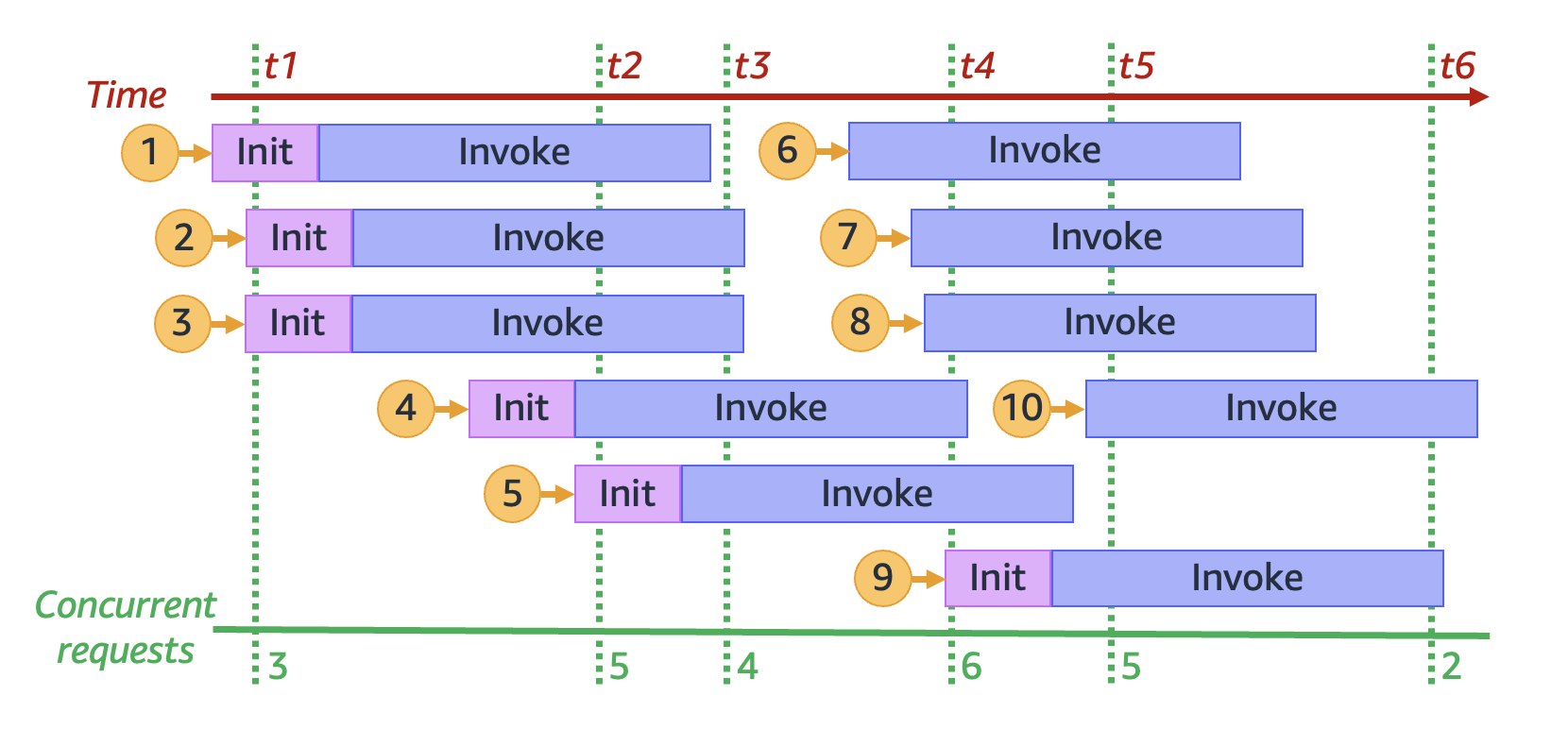
上記の図では、任意の時点で垂直の線を引いて、その線に交差する環境の数を数えることができます。そうすることで、その時点での同時リクエストの数がわかります。例えば、t1 の時点では、3 件の同時リクエストを処理する 3 個のアクティブな環境があります。このシミュレーションでは、t4 の時点で最大数の同時リクエストが行われており、6 個のアクティブな環境が 6 件の同時リクエストを処理しています。
要約すると、関数の同時実行とは、関数が同時に処理している同時リクエストの数になります。Lambda は、関数の同時実行の増加に対応してより多くの実行環境インスタンスをプロビジョニングし、リクエストの需要を満たします。
関数の同時実行数の計算
一般に、システムの同時実行性とは、複数のタスクを同時に処理する能力のことです。Lambda での同時実行は、関数が同時に処理している未完了のリクエストの数です。Lambda 関数の同時実行を測定するためのすばやく実用的な方法は、以下の式を使用することです。
Concurrency = (average requests per second) * (average request duration in seconds)
同時実行の数は、1 秒あたりのリクエスト数とは異なります。例えば、関数が 1 秒あたり平均 100 件のリクエストを受け取るとします。リクエストの平均所要時間が 1 秒の場合、同時実行の数も 100 になります。
Concurrency = (100 requests/second) * (1 second/request) = 100
ただし、リクエストの平均所要時間が 500 ミリ秒の場合、同時実行の数は 50 になります。
Concurrency = (100 requests/second) * (0.5 second/request) = 50
同時実行の数が 50 というのは、実際に何を意味するのでしょうか? リクエストの平均所要時間が 500 ミリ秒の場合、関数のインスタンスは 1 秒あたり 2 件のリクエストを処理できると考えられます。その場合、1 秒あたり 100 リクエストの負荷を処理するには、関数のインスタンスが 50 個必要です。50 の同時実行は、このワークロードをスロットリングなしで効率的に処理するには Lambda が 50 個の実行環境インスタンスをプロビジョニングする必要があることを意味します。これを方程式で表現すると、以下のようになります。
Concurrency = (100 requests/second) / (2 requests/second) = 50
関数が 2 倍のリクエスト (1 秒あたり 200 件のリクエスト) を受け取り、各リクエストの処理に半分の時間 (250 ミリ秒) しか必要ない場合でも、同時実行の数は 50 のままです。
Concurrency = (200 requests/second) * (0.25 second/request) = 50
実行に平均 200 ミリ秒かかる関数があるとします。負荷のピーク時には、1 秒あたり 5,000 件のリクエストがあります。負荷のピーク時における関数の同時実行の数を計算してください。
関数の平均所要時間は 200 ミリ秒、つまり 0.2 秒です。同時実行の式を使用し、これらの数値を代入すると、同時実行の数は 1,000 になります。
Concurrency = (5,000 requests/second) * (0.2 seconds/request) = 1,000
言い換えると、関数の平均所要時間が 200 ミリ秒の場合、その関数は 1 秒あたり 5 件のリクエストを処理できることになります。1 秒あたり 5,000 リクエストのワークロードを処理するには、1,000 個の実行環境インスタンスが必要です。したがって、同時実行の数は 1,000 になります。
Concurrency = (5,000 requests/second) / (5 requests/second) = 1,000
予約済み同時実行数とプロビジョニングされた同時実行数について
デフォルトで、アカウントの同時実行はリージョン内のすべての関数全体で 1,000 に制限されています。関数は、この 1,000 の同時実行のプールをオンデマンドで共有します。利用できる同時実行数が不足すると、関数でスロットリングが発生します (つまり、リクエストがドロップされ始めます)。
関数の中には、他の関数よりも重要なものがあります。そのため、重要な関数が必要な同時実行を利用できるように、同時実行を設定することをお勧めします。同時実行コントロールには、予約された同時実行とプロビジョニングされた同時実行の 2 つのタイプのコントロールがあります。
-
予約済み同時実行数を使用して、同時インスタンスの最大数と最小数の両方を設定し、アカウントの同時実行数の一部を関数用に予約します。これは、他の関数が利用可能な予約されていない同時実行のすべてを使い切ってしまわないようにするために役立ちます。ある関数が予約済み同時実行を使用している場合、他の関数はその同時実行を使用できません。
-
プロビジョニングされた同時実行は、関数用の多数の環境インスタンスを事前に初期化するために使用します。これはコールドスタートレイテンシーの削減に役立ちます。
予約された同時実行
関数のために一定数の同時実行が常に利用可能であることを確実にしたい場合は、予約された同時実行を使用します。
予約済み同時実行数で、関数に割り当てる同時インスタンスの最大数と最小数を設定します。予約された同時実行を 1 つの関数専用の同時実行にすると、他の関数がその同時実行を使用することはできません。つまり、予約された同時実行の設定は、他の関数が利用できる同時実行のプールに影響を与える可能性があります。予約された同時実行がない関数は、残りの予約されていない同時実行のプールを共有します。
予約された同時実行の設定は、アカウント全体の同時実行上限にカウントされます。関数に対して予約済み同時実行を設定する場合、料金はかかりません。
予約された同時実行に関する理解を深めるため、以下の図を検証しましょう。

この図では、このリージョン内のすべての関数に対するアカウントの同時実行上限が、デフォルト上限の 1,000 になっています。function-blue と function-orange の 2 つの重要な関数があり、大量の呼び出しが定期的に行われることが見込まれているとします。function-blue に予約された同時実行を 400 ユニット、function-orange にも予約された同時実行を 400 ユニット割り当てることにしました。この例では、アカウント内のその他すべての関数が、残りの予約されていない同時実行 200 ユニットを共有する必要があります。
この図には、以下の 5 つの注目点があります。
-
t1で、function-orangeとfunction-blueの両方がリクエストの受け取りを開始します。各関数は、それぞれに割り当てられている予約された同時実行ユニットを使用し始めます。 -
t2では、function-orangeとfunction-blueが受け取るリクエスト数が着実に増加します。それと同時に他の Lambda 関数がいくつかデプロイされ、それらもリクエストの受け取りを開始します。これらの他の関数には、予約された同時実行を割り当てません。これらの関数は、残りの予約されていない同時実行 200 ユニットの使用を開始します。 -
t3で、function-orangeが最大同時実行数の 400 に到達します。アカウントのどこかに未使用の同時実行はあるものの、function-orangeはそれらにアクセスできません。赤い線は、function-orangeでスロットリングが発生していることを示し、Lambda はリクエストをドロップする可能性があります。 -
t4では、function-orangeが受け取るリクエストの数が減り始め、スロットルされなくなります。しかし、他の関数ではトラフィックが急増し、スロットルされ始めます。アカウントのどこかに未使用の同時実行はあるものの、これらの他の関数はそれらにアクセスできません。赤い線は、他の関数でスロットリングが発生していることを示します。 -
t5では、他の関数が受け取るリクエストの数が減り始め、スロットルされなくなります。
この例から、予約された同時実行に以下の効果があることがわかります。
-
関数は、アカウント内の他の関数とは別個にスケーリングできる。同じリージョン内にあるアカウントの関数で、予約された同時実行がないすべての関数は、予約されていない同時実行のプールを共有します。予約された同時実行がないと、他の関数が利用可能なすべての同時実行を使い切る可能性があります。これは、重要な関数が必要に応じてスケールアップすることを妨げます。
-
関数は、際限なくスケールアウトできない。予約済み同時実行数により、関数の同時実行数の上限と下限が設定されます。つまり、関数は、他の関数用に予約されている同時実行や、予約されていない同時実行のプールを使用できません。さらに、予約済み同時実行数は下限と上限の両方として機能し、指定された容量を関数専用に予約すると同時に、その制限を超えてスケーリングすることを防止します。同時実行は、関数がアカウント内の利用可能な同時実行のすべてを使用したり、ダウンストリームリソースを過負荷状態にしたりすることがないように予約できます。
-
アカウントで利用可能な同時実行のすべてを使用できない場合がある。同時実行の予約は、アカウントの同時実行上限にカウントされますが、他の関数が予約された同時実行の部分を使用できないことも意味します。関数が予約された同時実行を使い切らない場合は、実質的にその同時実行を無駄にすることになります。アカウント内の他の関数が無駄になった同時実行からメリットを得られるならば、これは問題にはなりません。
関数用に予約された同時実行の設定を管理する方法については、「関数に対する予約済み同時実行数の設定」を参照してください。
プロビジョニングされた同時実行
予約された同時実行は、Lambda 関数用に予約されている実行環境の最大数を定義するために使用しますが、これらの環境は、いずれも事前に初期化されていません。その結果、関数の呼び出し時間が長くなる可能性があります。Lambda は、最初に新しい環境を初期化してから、それを使って関数を呼び出す必要があるためです。呼び出しを実行するために Lambda が新しい環境を初期化しなければならない状況は、コールドスタートと呼ばれます。コールドスタートを緩和するため、プロビジョニングされた同時実行を使用できます。
プロビジョニングされた同時実行は、関数に割り当てる、事前に初期化された実行環境の数です。関数にプロビジョニングされた同時実行を設定すると、Lambda はその数だけ実行環境を初期化して、関数リクエストに即座に応答できるようにしておきます。
注記
プロビジョニングされた同時実行を使用すると、アカウントに追加料金が請求されます。Java 11 または Java 17 のランタイムを使用している場合は、Lambda SnapStart を使用して、追加費用なしでコールドスタートの問題を軽減することもできます。SnapStart は、実行環境のキャッシュされたスナップショットを使用して、起動時のパフォーマンスを大幅に向上させます。SnapStart とプロビジョニングされた同時実行の両方を同じ関数バージョンで使用することはできません。SnapStart の機能、制限事項、サポートされているリージョンの詳細については、「Lambda SnapStart による起動パフォーマンスの向上」を参照してください。
プロビジョニングされた同時実行を使用するときも、Lambda は引き続き実行環境をバックグラウンドでリサイクルしますが、例えば、これは呼び出しが失敗した後に発生する可能性があります。Lambda は常に、事前に初期化された環境の数が、関数のプロビジョニングされた同時実行設定の値と等しくなることを確実にします。重要なのは、プロビジョニングされた同時実行を使用している場合でも、Lambda が実行環境をリセットする必要がある場合には、コールドスタートの遅延が発生する可能性があることです。
一方、予約された同時実行を使用している場合は、Lambda はアイドル状態が続いた後で環境を完全に終了することがあります。以下の図は、予約された同時実行を使用して関数を設定する場合と、プロビジョニングされた同時実行を使用して関数を設定する場合における、単一の実行環境のライフサイクルを比較することで、これを説明しています。

この図には、次の 4 つの注目点があります。
| 時間 | 予約された同時実行 | プロビジョニングされた同時実行 |
|---|---|---|
|
t1 |
何も実行されません。 |
Lambda が実行環境インスタンスを事前に初期化します。 |
|
t2 |
リクエスト 1 を受け取ります。Lambda は新しい実行環境インスタンスを初期化する必要があります。 |
リクエスト 1 を受け取ります。Lambda は事前に初期化された環境インスタンスを使用します。 |
|
t3 |
アイドル時間がしばらく続くと、Lambda がアクティブな環境インスタンスを終了します。 |
何も実行されません。 |
|
t4 |
リクエスト 2 を受け取ります。Lambda は新しい実行環境インスタンスを初期化する必要があります。 |
リクエスト 2 を受け取ります。Lambda は事前に初期化された環境インスタンスを使用します。 |
プロビジョニングされた同時実行に関する理解を深めるために、以下の図を検証しましょう。

この図では、アカウントの同時実行上限が 1,000 になっています。function-orange にプロビジョニングされた同時実行を 400 ユニット設定することにしました。function-orange を含めたアカウント内のすべての関数が、残りの予約されていない同時実行 600 ユニットを使用できます。
この図には、以下の 5 つの注目点があります。
-
t1で、function-orangeがリクエストの受け取りを開始します。Lambda には事前に初期化された実行環境インスタンスが 400 個あるので、function-orangeは即時呼び出しに対応できます。 -
t2では、function-orangeの同時リクエストが 400 件に到達します。その結果、function-orangeはプロビジョニングされた同時実行を使い切ってしまいます。しかし、予約されていない同時実行がまだ残っているので、Lambda はこれを使用してfunction-orangeへの追加のリクエストを処理できます (スロットリングは行われません)。Lambda はこれらのリクエストを処理するために新しいインスタンスを作成する必要があり、関数でコールドスタートレイテンシーが発生する可能性があります。 -
t3では、トラフィックの一時的な急増後にfunction-orangeの同時リクエスト数が 400 件に戻ります。Lambda は再び、コールドスタートレイテンシーなしですべてのリクエストを処理できるようになります。 -
t4で、アカウント内の関数のトラフィックが急増します。この急増は、function-orange、またはアカウント内の他の関数で発生したものになり得ます。Lambda は、予約されていない同時実行を使用して、これらのリクエストを処理します。 -
t5では、アカウント内の関数が同時実行上限の 1,000 に到達し、スロットリングが発生します。
上記の例では、プロビジョニングされた同時実行のみを検証しました。実際には、プロビジョニングされた同時実行と予約された同時実行の両方を関数に設定できます。これは、平日には一定量の呼び出しを処理する関数があるが、週末にはトラフィックの急増が定期的に発生するという場合に実行できます。この場合、プロビジョニングされた同時実行を使用して平日のリクエストを処理するための基本数の環境を設定し、予約された同時実行を使用して週末の急増を処理することができます。以下の図を検証しましょう。
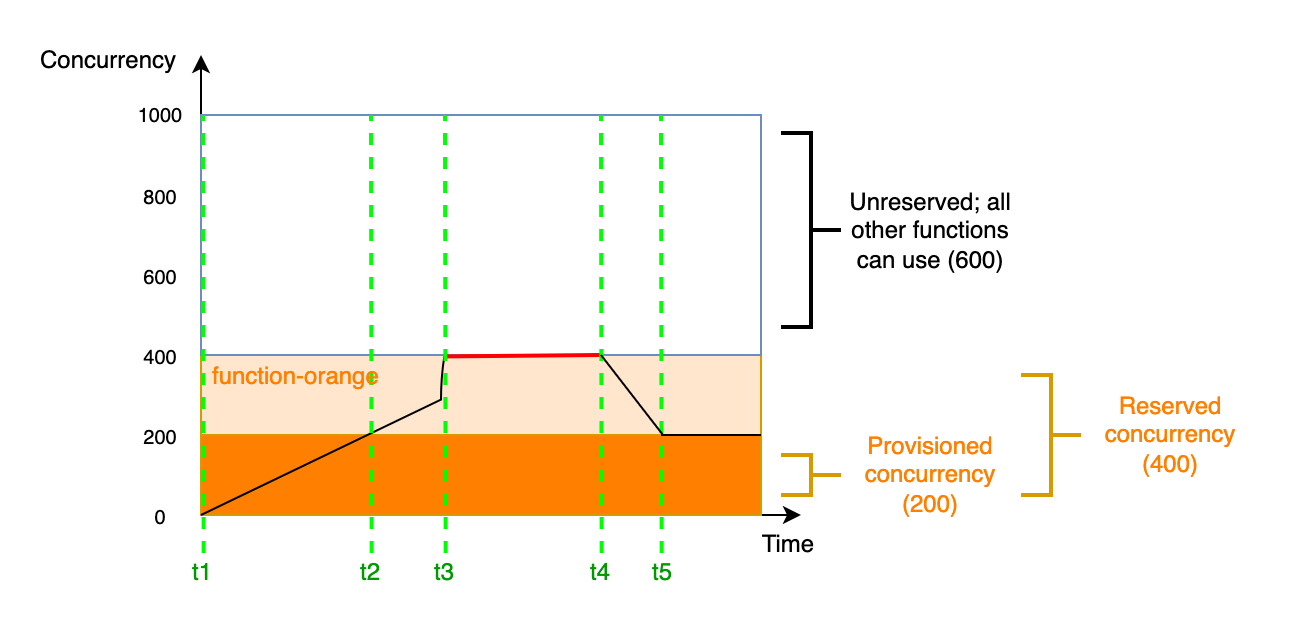
この図では、function-orange のために、プロビジョニングされた同時実行を 200 ユニット、および予約された同時実行を 400 ユニット設定するとします。予約された同時実行を設定したので、function-orange が 600 ユニットの予約されていない同時実行を使用することはできません。
この図には、以下の 5 つの注目点があります。
-
t1で、function-orangeがリクエストの受け取りを開始します。Lambda には事前に初期化された実行環境インスタンスが 200 個あるので、function-orangeは即時呼び出しに対応できます。 -
t2で、function-orangeはプロビジョニングされた同時実行のすべてを使い切ります。function-orangeは予約された同時実行を使用してリクエストの処理を継続できますが、これらのリクエストではコールドスタートレイテンシーが発生する可能性があります。 -
t3では、function-orangeの同時リクエストが 400 件に到達します。その結果、function-orangeは予約された同時実行のすべてを使い切ります。function-orangeは予約されていない同時実行を使用できないため、リクエストがスロットルされ始めます。 -
t4では、function-orangeが受け取るリクエストの数が減り始め、スロットルされなくなります。 -
t5では、function-orangeの同時リクエスト数が 200 件に減少するため、すべてのリクエストがプロビジョニングされた同時実行を再び使用できるようになります (つまり、コールドスタートレイテンシーは発生しません)。
予約された同時実行とプロビジョニングされた同時実行の両方が、アカウントの同時実行上限とリージョン別のクォータにカウントされます。つまり、予約された同時実行とプロビジョニングされた同時実行の割り当ては、他の関数が利用できる同時実行のプールに影響を与える可能性があります。プロビジョニング済み同時実行を設定すると、AWS アカウントに料金が請求されます。
注記
関数の Versions and Aliases に割り当てたプロビジョニングされた同時実行数が、関数の予約された同時実行数に達すると、すべての呼び出しはプロビジョニングされた同時実行数を使用して実行されます。この設定には、非公開バージョンの関数 ($LATEST) をスロットリングする効果もあるため、その関数は実行されません。関数に対し、予約済同時実行数よりも多くのプロビジョニングされた同時実行を割り当てることはできません。
関数用にプロビジョニングされた同時実行の設定を管理するには、「関数に対するプロビジョニングされた同時実行数の設定」を参照してください。スケジュールまたはアプリケーションの使用状況に基づいてプロビジョニングされた同時実行のスケーリングを自動化するには、「Application Auto Scaling を使用してプロビジョニングされた同時実行数の管理を自動化する」を参照してください。
Lambda がプロビジョニングされた同時実行性を割り当てる方法
プロビジョニング済み同時実行は、設定後すぐにはオンラインになりません。Lambda は、1~2 分の準備後に、プロビジョニング済み同時実行の割り当てをスタートします。AWS リージョン とは関係なく、Lambda は、関数ごとに 1 分あたり最大 6,000 個の実行環境をプロビジョニングできます。これは関数の同時実行スケーリングレートとまったく同じです。
プロビジョニングされた同時実行を割り当てるリクエストを送信すると、Lambda が割り当てを完全に完了するまで、それらの環境にはアクセスできません。例えば、5,000 個のプロビジョニングされた同時実行をリクエストした場合、Lambda が 5,000 個の実行環境の配分を完全に終了するまで、リクエストでプロビジョニングされた同時実行を使用することはできません。
予約された同時実行とプロビジョニングされた同時実行の比較
以下の表は、予約された同時実行とプロビジョニングされた同時実行を要約し、比較したものです。
| Topic | 予約された同時実行 | プロビジョニングされた同時実行 |
|---|---|---|
|
定義 |
関数の実行環境インスタンスの最大数。 |
関数用に事前にプロビジョニングされた、一定数の実行環境インスタンス。 |
|
プロビジョニング動作 |
Lambda が新しいインスタンスをオンデマンドベースでプロビジョニングします。 |
Lambda がインスタンスを事前に (つまり、関数がリクエストの受け取りを開始する前に) プロビジョニングします 。 |
|
コールドスタート動作 |
Lambda はオンデマンドで新しいインスタンスを作成する必要があることから、コールドスタートレイテンシーが発生する可能性があります。 |
Lambda はオンデマンドでインスタンスを作成する必要がないため、コールドスタートレイテンシーが発生することはありません。 |
|
スロットリング動作 |
予約された同時実行の上限に達すると、関数がスロットルされます。 |
予約された同時実行が設定されていない場合: プロビジョニングされた同時実行の上限に達すると、関数は予約されていない同時実行を使用します。 予約された同時実行数が設定されている場合: 予約された同時実行の上限に達すると、関数がスロットルされます。 |
|
設定されていない場合のデフォルト動作 |
関数は、アカウントで利用できる、予約されていない同時実行を使用します。 |
Lambda はインスタンスを事前にプロビジョニングしません。その代わり、予約された同時実行が設定されていない場合、関数はアカウントで利用できる、予約されていない同時実行を使用します。 予約された同時実行が設定されている場合: 関数は予約された同時実行を使用します。 |
|
料金 |
追加料金はありません。 |
追加料金が発生します。 |
同時実行数と 1 秒あたりのリクエスト数について
前のセクションで述べたように、同時実行の数は、秒あたりのリクエスト数とは異なります。この違いは、平均リクエスト時間が 100 ミリ秒未満の関数を扱う場合に特に重要になります。
アカウントのすべての関数で、Lambda はアカウントの同時実行数の 10 倍に相当する 1 秒あたりのリクエスト数の制限を適用します。例えば、デフォルトのアカウントの同時実行上限は 1,000 であるため、アカウントの関数は 1 秒あたり最大 10,000 件のリクエストを処理できます。
例えば、平均リクエスト時間が 50 ミリ秒の関数を考えてみましょう。1 秒あたり 20,000 件のリクエストの場合、この関数の同時実行数は次のようになります。
Concurrency = (20,000 requests/second) * (0.05 second/request) = 1,000
この結果に基づいて、アカウントの同時実行上限である 1,000 が、この負荷を処理するのに十分であると予想できます。ただし、1 秒あたりのリクエスト数が 10,000 に制限されているため、関数は合計 20,000 リクエストのうち 1 秒あたり 10,000 リクエストしか処理できません。この関数ではスロットリングが発生します。
ここで重要なのは、関数の同時実行設定を行う際には、同時実行と 1 秒あたりのリクエスト数の両方を考慮する必要があるということです。この場合、アカウントの同時実行上限を 2,000 に引き上げるようにリクエストする必要があります。そうすれば、1 秒あたりの合計リクエスト数を 20,000 に引き上げることができます。
注記
この 1 秒あたりのリクエスト数の制限に基づくと、各 Lambda 実行環境が 1 秒あたり最大 10 件のリクエストしか処理できないとするのは誤りです。個々の実行環境の負荷を観察する代わりに、Lambda は、クォータを計算するときに全体的な同時実行数と 1 秒あたりの全体的なリクエスト数のみを考慮します。
実行に平均 20 ミリ秒かかる関数があるとします。負荷のピーク時には、1 秒あたり 30,000 件のリクエストがあります。負荷のピーク時における関数の同時実行の数を計算してください。
関数の平均所要時間は 20 ミリ秒、つまり 0.02 秒です。同時実行の式を使用し、これらの数値を代入すると、同時実行の数は 600 になります。
Concurrency = (30,000 requests/second) * (0.02 seconds/request) = 600
デフォルトのアカウントの同時実行上限である 1,000 は、この負荷を処理するのに十分であると考えられます。ただし、1 秒あたりのリクエスト数が 10,000 に制限されると、1 秒あたり 30,000 件の受信リクエストを処理する場合に十分ではありません。30,000 件のリクエストに完全に対応するには、アカウントの同時実行上限を 3,000 以上に引き上げるようにリクエストする必要があります。
1 秒あたりのリクエスト数の制限は、同時実行を含む Lambda のすべてのクォータに適用されます。つまり、同期オンデマンド関数、プロビジョニングされた同時実行を使用する関数、および同時実行のスケーリング動作に適用されます。例えば、同時実行数と 1 秒あたりのリクエスト数の制限の両方を慎重に検討する必要があるシナリオを次に示します。
-
オンデマンド同時実行を使用する関数では、同時実行数と 1 秒あたりのリクエスト数のどちらかが、10 秒ごとにそれぞれ 500 と 5,000 まで急激に増加する可能性があります。
-
プロビジョニングされた同時実行割り当てが 10 の関数があるとします。この関数は、同時実行数と 1 秒あたりのリクエスト数のどちらかが、それぞれ 10 と 100 に達すると、オンデマンド同時実行にスピルオーバーします。
同時実行のクォータ
Lambda は、リージョン内のすべての関数全体で使用できる同時実行の合計数に対するクォータを設定しています。これらのクォータは、次の 2 つのレベルで設定されています。
-
アカウントレベルでは、関数がデフォルトで最大 1,000 ユニットの同時実行を使用できます。クォータの引き上げをリクエストするには、「Service Quotas User Guide」(Service Quotas ユーザーガイド) の「Requesting a quota increase」(クォータ引き上げのリクエスト) を参照してください。
-
関数レベルでは、すべての関数全体で最大 900 ユニットの同時実行をデフォルトで予約できます。アカウントの同時実行数の合計制限に関係なく、Lambda は同時実行を明示的に予約しない関数に対して常に 100 ユニットの同時実行を予約します。例えば、アカウントの同時実行上限を 2,000 に引き上げた場合、関数レベルでは最大 1,900 ユニットの同時実行を予約できます。
-
アカウントレベルと関数レベルの両方で、Lambda は対応する同時実行クォータの 10 倍に相当する 1 秒あたりのリクエスト数の制限も適用します。例えば、これはアカウントレベルの同時実行、オンデマンド同時実行を使用する関数、プロビジョニングされた同時実行を使用する関数、および同時実行のスケーリング動作に適用されます。詳細については、「同時実行数と 1 秒あたりのリクエスト数について」を参照してください。
現在のアカウントレベルの同時実行クォータを確認するには、AWS Command Line Interface (AWS CLI) を使用して以下のコマンドを実行します。
aws lambda get-account-settings
次のような出力が表示されます。
{ "AccountLimit": { "TotalCodeSize": 80530636800, "CodeSizeUnzipped": 262144000, "CodeSizeZipped": 52428800, "ConcurrentExecutions": 1000, "UnreservedConcurrentExecutions": 900 }, "AccountUsage": { "TotalCodeSize": 410759889, "FunctionCount": 8 } }
ConcurrentExecutions はアカウントレベルの同時実行クォータの合計です。UnreservedConcurrentExecutions は、まだ関数に割り当て可能な予約された同時実行の量です。
関数が受け取るリクエストが増えると、Lambda が実行環境数を自動的にスケールアップしてこれらのリクエストを処理します。これはアカウントが同時実行クォータに達するまで行われます。ただし、突然のトラフィック急増によるオーバースケーリングを防ぐために、Lambda では関数がスケールできる速度を制限しています。この同時実行のスケーリングレートは、アカウントの関数がリクエストの増加に応じてスケールできる最大レートです。(つまり、Lambda がどれだけ速く新しい実行環境を作成できるかということです。) 同時実行のスケーリングレートは、アカウントレベルの同時実行数の上限 (関数で利用できる同時実行の合計量) とは異なります。
各 AWS リージョン および各関数において、同時実行のスケーリングレートは 10 秒ごとに 1,000 の実行環境インスタンス (または 10 秒ごとに 1 秒あたり 10,000 リクエスト) です。つまり、Lambda は 10 秒ごとに最大 1,000 の追加実行環境インスタンスを各関数に割り当てるか、または 1 秒あたり 10,000 件の追加リクエストに対応できます。
通常、この制限について心配する必要はありません。ほとんどのユースケースでは、Lambda のスケーリングレートで十分です。
重要なのは、同時実行のスケーリングレートは関数レベルの上限であることです。つまり、アカウント内の各関数は、他の関数とは別個にスケールできます。
スケーリング動作の詳細については、「Lambda のスケーリング動作」を参照してください。
