翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
新製品需要予測のベストプラクティス
このセクションでは、新製品の需要予測に関する以下のベストプラクティスについて説明します。
データ駆動型のNPI需要予測のためのデータ準備状況要件を満たす
NPI 需要予測にデータ駆動型のアプローチを採用するには、組織はデータサイエンス部門や分析部門のマネージャー、サプライチェーン、マーケティング、IT 部門など、関連するすべてのステークホルダーからサポートを受ける必要があります。その後、組織は以下を特定する必要があります。
-
既存の内部データおよび関連する外部データのソース
-
これらのデータソースの所有者
-
これらのデータソースをイニシアチブに使用するために必要な手順とアクセス許可
データの準備状況は、次の種類の必須データセットとオプションのデータセットに対して評価できます。オプションの種類を含め、できるだけ多くのデータセットを使用すると、機械学習モデルがより正確なNPI需要予測を生成するのに役立ちます。
必要な内部データソースの例を次に示します。
-
すべての製品、または起動する新製品と同様の属性を持つ製品のサブセットについて、販売履歴 (製品の起動から中止まで) を完了します。販売履歴は、複数の販売チャネルから取得することも、すべてのチャネルで組み合わせることもできます。
-
製品属性マッピングは、起動される新しい製品と同様の属性を持つ製品のサブセットを識別します。
オプションの内部データソースの例を次に示します。
-
類似製品のプロモーションと割引を追跡するマーケティングデータ。このデータは、販売履歴の長さ以上である必要があります。
-
製品レビュー、評価、ウェブトラフィックデータ。このデータは、販売履歴の長さ以上である必要があります。
-
コンシューマー属性データ
以下は、内部データを補完できるオプションの外部データソースの例です。
-
コンシューマーインデックスデータ
-
競合製品の売上データ
-
アンケートデータ
費用対効果の高いデータ取り込みメカニズムを構築する
データ準備要件が満たされたら、組織は最適なデータ取り込みとデータストレージのメカニズムを選択できます。組織の主な売上データがさまざまなチャネルから毎日収集されている場合は、バッチデータの取り込みを検討してください。ストリーミングデータの取り込みは、最新のデータを持つことからメリットを得るセルフサービス予測が必要な場合のもう 1 つのオプションです。
raw データ取り込みパイプラインでは、軽量な変換のために抽出、変換、ロード (ETL) パイプラインを使用する必要があります。パイプラインは、データ品質チェックを実行し、処理されたデータをデータベースに保存してダウンストリームで使用する必要があります。
AWS のサービス、、AWS GlueAWS Glue Data CatalogAmazon Data Firehose、Amazon Simple Storage Service (Amazon S3) などの を使用して、コスト効率の高いデータの取り込みとストレージを実現できます。 AWS Glueは、さまざまなデータストア間でデータを分類、クリーニング、変換、および確実に転送できるフルマネージドサーバーレスETLサービスです。のコアコンポーネント AWS Glue は、 と呼ばれる中央メタデータリポジトリと AWS Glue Data Catalog、Python および Scala コードを自動的に生成してETLジョブを管理する ETLジョブシステムで構成されます。Amazon Data Firehose は、あらゆる規模でリアルタイムのストリーミングデータを収集、処理、分析するのに役立ちます。Firehose は、リアルタイムのストリーミングデータをデータレイク (Amazon S3 など)、データストア、分析サービスに直接配信して、さらに処理することができます。Amazon S3 は、スケーラビリティ、データ可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスです。
NPI 需要を予測するための実行可能な ML アプローチを決定する
特定のユースケースに応じて、組織はさまざまな予測オプションを検討できます。
Bass 拡散モデル
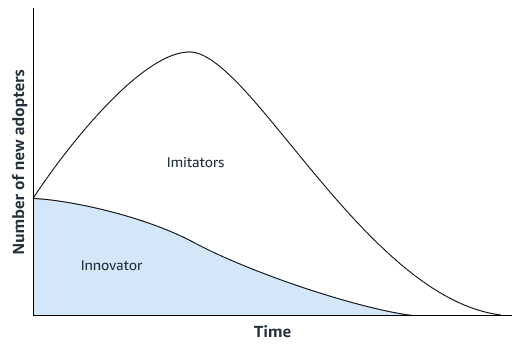
新製品に大幅なイノベーションが見られない場合、組織は新製品に最も近い製品の販売履歴に基づいて運用される時系列予測モデルを使用できます。Amazon SageMaker AI DeepAR 予測アルゴリズムなどの ML ベースの予測アルゴリズムを使用できます。このアルゴリズムは、複数の類似製品の時系列売上データを使用できます。これは、時系列の予測を生成するが、既存の履歴データがほとんどまたはまったくない場合のコールドスタート予測シナリオに適しています。次の図は、関連製品の時系列データを使用して、新しい類似製品の予測を生成する方法を示しています。
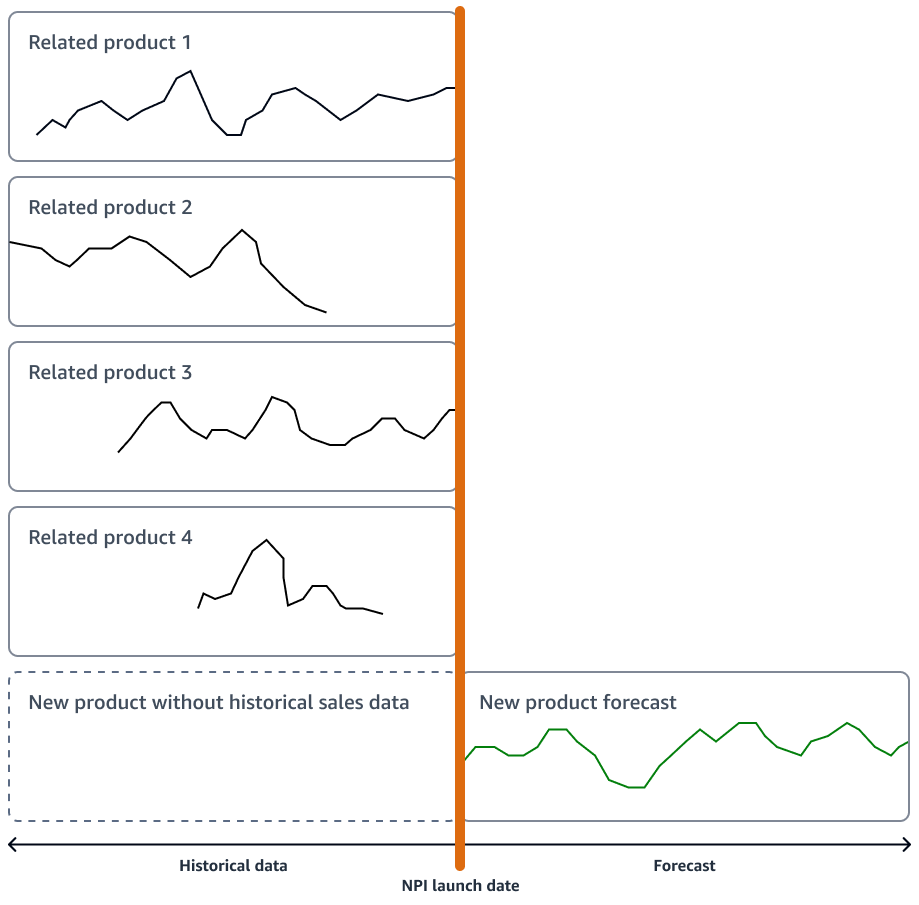
新製品の発売タイムラインに沿った予測の生成を検討する必要があります。ロジスティック修正に十分なバッファを確保するために、事前に予測を生成します。
予測効果のスケーリングと追跡
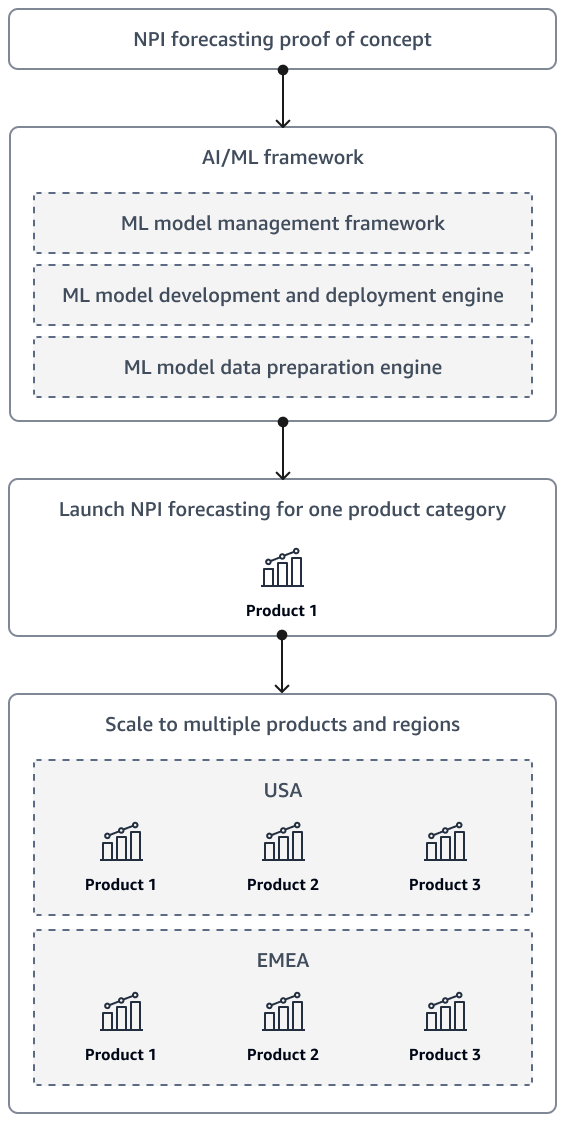
NPI 需要予測の概念実証を完了した後、ソリューションは最終的に追加の製品と複数のリージョンを含めるようにスケーリングする必要があります。人工知能と機械学習 (AI/ML) フレームワークを使用して、データを準備し、モデルを開発、デプロイ、モニタリングします。
次の図は、組織のNPI予測ソリューションが成熟するにつれて起動およびスケール戦略を示しています。
また、経営幹部や利害関係者が予測をセルフサービスできるようにソリューションを設計することをお勧めします。例えば、ステークホルダーがオンデマンドで最新の予測にアクセスできるように Amazon QuickSight ダッシュボードを作成できます。
予測精度を注意深くモニタリングし、逸脱を徹底的に調査して、合理的な投資収益率 () を確保しますROI。Amazon SageMaker AI Model Monitor でモデルモニタリングを設定すると、ライブデータに対してリアルタイムの予測を行う際にモデルのパフォーマンスを追跡できます。Amazon SageMaker Model Dashboard を使用して、データ品質、モデル品質、バイアス、説明可能性に設定したしきい値に違反するモデルを検索できます。詳細については、Amazon SageMaker AI ドキュメントの「ガバナンスを使用してアクセス許可を管理し、モデルのパフォーマンスを追跡する」を参照してください。
