翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Athena と Amazon QuickSight を使用してネストされた JSON データを分析および視覚化する
Anoop Singh、Amazon Web Services
概要
このパターンでは、Amazon Athena を使用してネストされた JSON 形式のデータ構造を表形式ビューに変換し、Amazon QuickSight でデータを視覚化する方法について説明します。
運用システムからの API を活用したデータフィードに JSON 形式のデータを使用して、データ製品を作成できます。このデータは、顧客と製品とのやり取りをよりよく理解するのに役立つため、ユーザーエクスペリエンスを調整し、結果を予測できます。
前提条件と制限
前提条件
アクティブな AWS アカウント
ネストされたデータ構造を表す JSON ファイル (このパターンはサンプルファイルを提供します)
[Limitations:] (制限:)
JSON 機能は、Athena の既存の SQL 指向関数とうまく統合されています。ただし、これらは ANSI SQL 互換ではなく、JSON ファイルは各レコードを別々の行に格納することが期待されます。Athena の
ignore.malformed.jsonプロパティを使用して、不正な形式の JSON レコードを null 文字に変換するか、エラーを生成するかを示す必要がある場合があります。詳細については、Athena ドキュメントの「JSON データを読み取るためのベストプラクティス」を参照してください。このパターンでは、JSON 形式の単純データおよび少量のデータのみを考慮します。これらの概念を大規模に使用する場合は、データのパーティショニングを適用し、データをより大きなファイルに統合することを検討してください。
アーキテクチャ
次の図は、このパターンのアーキテクチャとワークフローを示しています。ネストされたデータ構造は、JSON 形式で Amazon Simple Storage Service (Amazon S3) に保存されます。Athena では、JSON データは Athena データ構造にマッピングされます。次に、データを分析するためのビューを作成し、QuickSight でデータ構造を視覚化します。
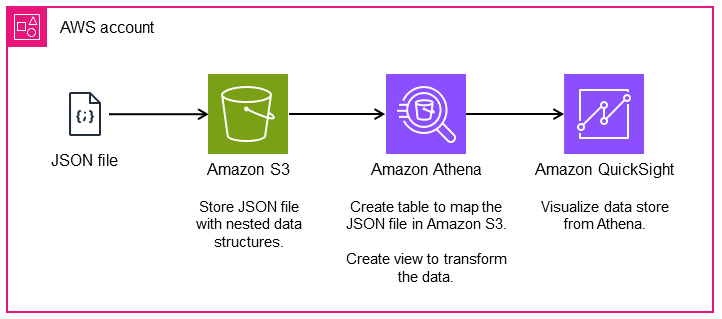
ツール
AWS サービス
Amazon Simple Storage Service (Amazon S3) は、量にかかわらず、データを保存、保護、取得するのに役立つクラウドベースのオブジェクトストレージサービスです。このパターンでは、Amazon S3 を使用して JSON ファイルを保存します。
Amazon Athena は、標準 SQL を使用して Amazon S3 でデータを直接分析するのに役立つ対話型のクエリサービスです。このパターンでは、Athena を使用して JSON データをクエリおよび変換します。でいくつかのアクションを使用すると AWS Management Console、Amazon S3 のデータに Athena をポイントし、標準 SQL を使用して 1 回限りのクエリを実行できます。Athena はサーバーレスであるため、設定または管理するインフラストラクチャはなく、実行したクエリに対してのみ料金が発生します。Athena は自動的にスケーリングされ、クエリが並行して実行されるため、大規模なデータセットや複雑なクエリでも結果が高速になります。
Amazon QuickSight は、単一のダッシュボードでデータを視覚化、分析、レポートするのに役立つクラウド規模のビジネスインテリジェンス (BI) サービスです。QuickSight を使用すると、機械学習 (ML) インサイトを含むインタラクティブなダッシュボードを簡単に作成して公開できます。これらのダッシュボードには任意のデバイスからアクセスし、アプリケーション、ポータル、ウェブサイトに埋め込むことができます。
コードの例
次の JSON ファイルは、このパターンで使用できるネストされたデータ構造を提供します。
{ "symbol": "AAPL", "financials": [ { "reportDate": "2017-03-31", "grossProfit": 20591000000, "costOfRevenue": 32305000000, "operatingRevenue": 52896000000, "totalRevenue": 52896000000, "operatingIncome": 14097000000, "netIncome": 11029000000, "researchAndDevelopment": 2776000000, "operatingExpense": 6494000000, "currentAssets": 101990000000, "totalAssets": 334532000000, "totalLiabilities": 200450000000, "currentCash": 15157000000, "currentDebt": 13991000000, "totalCash": 67101000000, "totalDebt": 98522000000, "shareholderEquity": 134082000000, "cashChange": -1214000000, "cashFlow": 12523000000, "operatingGainsLosses": null } ] }
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
S3 バケットを作成する。 | JSON ファイルを保存するバケットを作成するには、 にサインインし AWS Management Console、Amazon S3 コンソール | システム管理者 |
ネストされた JSON データを追加します。 | JSON ファイルを S3 バケットにアップロードします。サンプル JSON ファイルについては、前のセクションを参照してください。手順については、Amazon S3 ドキュメントの「オブジェクトのアップロード」を参照してください。 | システム管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
JSON データをマッピングするためのテーブルを作成します。 |
テーブルの作成の詳細については、Athena のドキュメントを参照してください。 | 開発者 |
データ分析用のビューを作成します。 |
ビューの作成の詳細については、Athena ドキュメントを参照してください。 | 開発者 |
データを分析して検証します。 |
| 開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
QuickSight で Athena をデータソースとして設定します。 |
| システム管理者 |
QuickSight でデータを視覚化します。 |
| データアナリスト |
関連リソース
