翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker 用のカスタム Docker コンテナイメージを作成し、AWS Step Functions のモデルトレーニングに使用する
作成者: Julia Bluszcz (AWS)、Neha Sharma (AWS)、Aubrey Oosthuizen (AWS)、Mohan Gowda Purushothama (AWS)、Mateusz Zaremba (AWS)
概要
このパターンは、Amazon SageMaker 用の Docker コンテナイメージを作成し、AWS Step Functions のトレーニングモデルに使用する方法を示しています。アルゴリズムをコンテナにパッケージ化することにより、プログラミング言語、フレームワーク、依存関係に関係なく、ほぼすべてのコードを SageMaker 環境で実行できます。
提供されている SageMaker ノートブックの例では、カスタム Docker コンテナイメージは Amazon Elastic Container Registry (Amazon ECR) に保存されます。次に、Step Functions は Amazon ECR に保存されているコンテナを使用して SageMaker の Python 処理スクリプトを実行します。次に、コンテナはモデルを Amazon Simple Storage Service (Amazon S3) にエクスポートします。
前提条件と制限
前提条件
アクティブな AWS アカウント
Amazon S3 アクセス許可を持つ SageMaker の AWS Identity and Access Management (IAM) ロール Amazon S3
Python に精通
Amazon SageMaker Python SDK に精通していること
AWS Command Line Interface (AWS CLI) に精通していること
AWS SDK for Python (Boto3) に精通していること
Amazon ECR に精通している
Docker に精通していること
製品バージョン
AWS Step Functions データサイエンス SDK バージョン 2.3.0
Amazon SageMaker Python SDK バージョン 2.78.0
アーキテクチャ
次の図は、SageMaker 用の Docker コンテナイメージを作成し、それを Step Functions のトレーニングモデルに使用するためのワークフローの例を示しています。
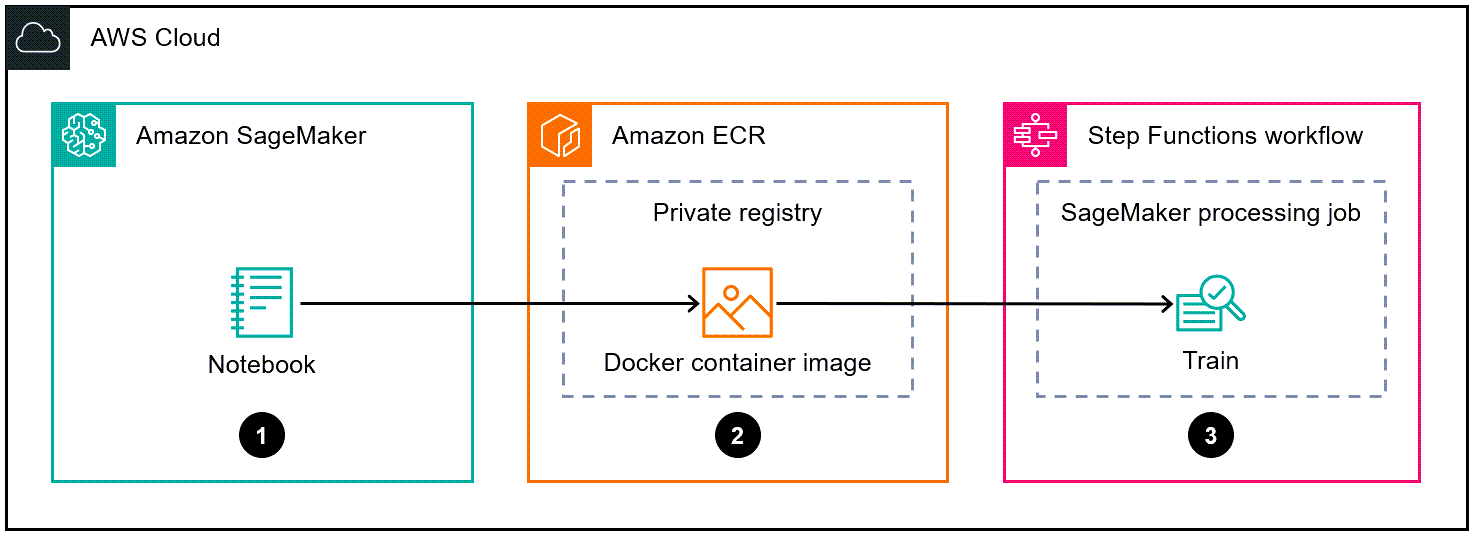
この図表は、次のワークフローを示しています:
データサイエンティストまたは DevOps エンジニアは、Amazon SageMaker ノートブックを使用してカスタム Docker コンテナイメージを作成します。
データサイエンティストまたは DevOps エンジニアは、Docker コンテナイメージをプライベートレジストリにおける Amazon ECR プライベートリポジトリに保存します。
データサイエンティストまたは DevOps エンジニアは、Docker コンテナで、Step Functions ワークフロー内の Python SageMaker 処理ジョブを実行します。
自動化とスケール
このパターンの SageMaker ノートブックの例としては、ml.m5.xlarge ノートブックインスタンスタイプを使用します。ユースケースに応じて、インスタンスタイプを変更することができます。SageMaker ノートブックインスタンスタイプの詳細については、「Amazon SageMaker の料金表
ツール
「Amazon Elastic Container Registry (Amazon ECR)」は、セキュリティ、スケーラビリティ、信頼性を備えたマネージドコンテナイメージレジストリサービスです。
「Amazon SageMaker」 はマネージド型の機械学習 (ML) サービスで、ML モデルの構築とトレーニングを行い、それらを本番稼働環境に対応したホスティング環境にデプロイします。
Amazon SageMaker Python SDK
は、SageMaker で機械学習モデルをトレーニングおよびデプロイするためのオープンソースライブラリです。 AWS Step Functionsは、AWS Lambda関数と他のAWS サービスを組み合わせてビジネスクリティカルなアプリケーションを構築できるサーバーレスオーケストレーションサービスです。
AWS Step Functions Data Science Python SDK
は、機械学習モデルを処理して公開する Step Functions ワークフローの作成に役立つオープンソースライブラリです。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
Amazon ECR をセットアップし、新しいプライベートレジストリを作成します。 | まだ Amazon ECR をセットアップしていない場合は、Amazon ECR ユーザーガイドの「Amazon ECR でセットアップ」における指示に従ってください。各 AWS アカウントには、デフォルトのプライベート Amazon ECR レジストリが提供されます。 | DevOps エンジニア |
Amazon ECR プライベートリポジトリを作成します。 | Amazon ECR ユーザーガイドの「プライベートリポジトリの作成」における指示に従ってください。 注記作成するリポジトリは、カスタム Docker コンテナイメージを保存する場所です。 | DevOps エンジニア |
SageMaker 処理ジョブの実行に必要な仕様を含む Docker ファイルを作成します。 | Dockerfile を設定して、SageMaker 処理ジョブの実行に必要な仕様を含む Dockerfile を作成します。手順については、Amazon SageMaker 開発者ガイドの「独自のトレーニングコンテナの調整」を参照してください。 Dockerfiles の詳細については、Docker ドキュメントの Dockerfile リファレンス 例:Jupyter Notebookのコードセルで[Dockerfile]を作成 セル 1
セル 2
| DevOps エンジニア |
Docker コンテナイメージを構築し、Amazon ECR にプッシュします。 |
詳細については、GitHub での独自のアルゴリズムコンテナの構築の「コンテナの構築と登録 Docker イメージを構築して登録する Jupyter Notebookのコードセルの例 重要次のセルを実行する前に、Dockerfile を作成し、 というディレクトリに保存していることを確認してください セル 1
セル 2
セル 3
セル 4
注記
| DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
カスタム処理とモデルトレーニングロジックを含む Python スクリプトを作成します。 | カスタム処理ロジックを書き込んでデータ処理スクリプトで実行します。その後、これを Python スクリプトとして、 詳細については、GitHub の「SageMaker スクリプトモードでモデルを自作 カスタム処理とモデルトレーニングロジックを含む Python スクリプトの例
| データサイエンティスト |
SageMaker 処理ジョブをステップの 1 つとして含むステップファンクションワークフローを作成します。 | 「AWS Step Functions データサイエンス SDK 重要AWS アカウントで Step Functions の IAM 実行ロールが作成され Amazon S3 にアップロードする環境設定例とカスタムトレーニングスクリプト
カスタム Amazon ECR イメージと Python スクリプトを使用する SageMaker 処理ステップ定義の例 注記必ず
SageMaker 処理ジョブを実行するStep Functions ワークフローの例 注記このサンプルワークフローには、完全な Step Functions ワークフローではなく、SageMaker 処理ジョブステップのみが含まれます。完全なワークフローの例については、「AWS Step Functions データサイエンス SDK ドキュメント」の「SageMaker のノートブック例
| データサイエンティスト |
関連リソース
「データの処理」(Amazon SageMaker デベロッパーガイド)
「独自のトレーニングコンテナを調整」(Amazon SageMaker 開発者ガイド)
