翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL で Oracle PL/SQL 関連付け配列をエミュレートする
Rajkumar Raghuwanshi、Bhanu Ganesh Gudivada、および Sachin Khanna、Amazon Web Services
概要
このパターンでは、Amazon Aurora PostgreSQL
Oracle データベースの移行時に空のインデックス位置を処理するための aws_oracle_ext 関数を使用する代わりに PostgreSQL が用意されています。このパターンでは、追加の列を使用してインデックス位置を保存し、ネイティブ PostgreSQL 機能を組み込みながら、Oracle によるスパース配列の処理を維持します。
Oracle
Oracle では、コレクションを空として初期化し、配列にNULL要素を追加するEXTENDコレクションメソッドを使用して入力できます。によってインデックス付けされた PL/SQL 関連付け配列を使用する場合PLS_INTEGER、 EXTENDメソッドはNULL要素を順番に追加しますが、要素は非連続インデックス位置で初期化することもできます。明示的に初期化されていないインデックス位置は空のままです。
この柔軟性により、要素を任意の位置に入力できる疎配列構造が可能になります。FOR LOOP FIRST と のLAST境界を使用してコレクションを反復処理する場合、初期化された要素 (値が定義されているNULLかどうかにかかわらず) のみが処理され、空の位置はスキップされます。
PostgreSQL (Amazon Aurora および Amazon RDS)
PostgreSQL は、空の値をNULL値とは異なる方法で処理します。空の値は、1 バイトのストレージを使用する個別のエンティティとして保存されます。配列に空の値がある場合、PostgreSQL は空でない値と同様にシーケンシャルインデックス位置を割り当てます。ただし、シーケンシャルインデックス作成には追加の処理が必要です。システムは、空の位置を含むすべてのインデックス付き位置を反復処理する必要があるためです。これにより、従来の配列の作成は疎データセットでは非効率になります。
AWS Schema Conversion Tool
AWS Schema Conversion Tool (AWS SCT) は通常、 aws_oracle_ext関数を使用して Oracle-to-PostgreSQLを処理します。このパターンでは、ネイティブ PostgreSQL 機能を使用する代替アプローチを提案します。これは、PostgreSQL 配列タイプとインデックス位置を保存するための追加の列を組み合わせたものです。その後、システムはインデックス列のみを使用して配列を反復処理できます。
前提条件と制限
前提条件
アクティブ AWS アカウント。
管理者権限を持つ AWS Identity and Access Management (IAM) ユーザー。
Amazon RDS または Aurora PostgreSQL と互換性のあるインスタンス。
リレーショナルデータベースの基本的な理解。
制約事項
一部の AWS のサービス は では使用できません AWS リージョン。リージョンの可用性については、AWS のサービス 「リージョン別
」を参照してください。特定のエンドポイントについては、「サービスエンドポイントとクォータ」ページを参照して、サービスのリンクを選択します。
製品バージョン
このパターンは、次のバージョンでテストされています。
Amazon Aurora PostgreSQL 13.3
Amazon RDS for PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
アーキテクチャ
ソーステクノロジースタック
オンプレミスの Oracle データベース
ターゲットテクノロジースタック
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
ターゲット アーキテクチャ
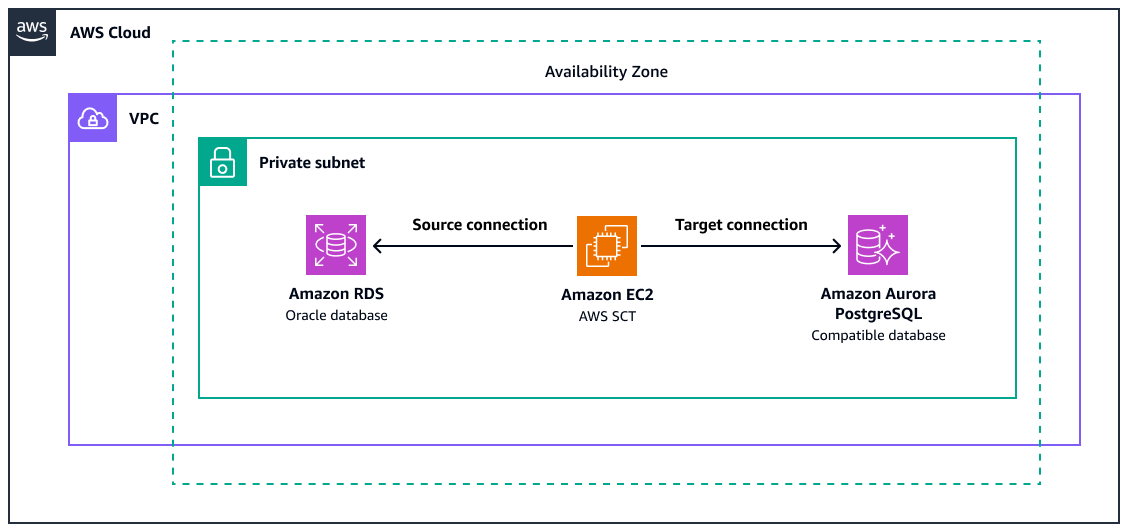
図に示す内容は以下のとおりです。
ソース Amazon RDS for Oracle データベースインスタンス
Oracle 関数を PostgreSQL と同等の関数に変換 AWS SCT するための を備えた Amazon EC2 インスタンス
Amazon Aurora PostgreSQL と互換性のあるターゲットデータベース
ツール
AWS サービス
「Amazon Aurora」はクラウド用に構築されたフルマネージド型のリレーショナルデータベースエンジンで、MySQL および PostgreSQL と互換性があります。
Amazon Aurora PostgreSQL 互換版は、PostgreSQL デプロイのセットアップ、運用、スケーリングを支援するフルマネージド型のリレーショナルデータベースエンジンです。
Amazon Elastic Compute Cloud (Amazon EC2) は、 AWS クラウドでスケーラブルなコンピューティング容量を提供します。必要な数の仮想サーバーを起動することができ、迅速にスケールアップまたはスケールダウンができます。
Amazon Relational Database Service (Amazon RDS) は、 でリレーショナルデータベースをセットアップ、運用、スケーリングするのに役立ちます AWS クラウド。
Oracle 用 Amazon Relational Database Service (Amazon RDS) は、 で Oracle リレーショナルデータベースをセットアップ、運用、スケーリングするのに役立ちます AWS クラウド。
Amazon Relational Database Service (Amazon RDS) for PostgreSQL は、 で PostgreSQL リレーショナルデータベースをセットアップ、運用、スケーリングするのに役立ちます AWS クラウド。
AWS Schema Conversion Tool (AWS SCT) は、ソースデータベーススキーマとカスタムコードの大部分をターゲットデータベースと互換性のある形式に自動的に変換することで、異種データベースの移行をサポートします。
その他のツール
「Oracle SQL Developer
」 は、従来のデプロイとクラウドベースのデプロイの両方で Oracle データベースの開発と管理を簡素化する統合開発環境です。 「pgAdmin
」 は PostgreSQL 用のオープンソース管理ツールです。データベースオブジェクトの作成、管理、使用を支援するグラフィカルインターフェイスを提供します。このパターンでは、pgAdmin は RDS for PostgreSQL データベースインスタンスに接続し、データをクエリします。または、psql コマンドラインクライアントを使用することもできます。
ベストプラクティス
データセットの境界とエッジシナリオをテストします。
out-of-boundsインデックス条件にエラー処理を実装することを検討してください。
スパースデータセットのスキャンを避けるためにクエリを最適化します。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
Oracle でソース PL/SQL ブロックを作成します。 | 次の関連付け配列を使用するソース PL/SQL ブロックを Oracle で作成します。
| DBA |
PL/SQL ブロックを実行します。 | Oracle でソース PL/SQL ブロックを実行します。関連付け配列のインデックス値の間にギャップがある場合、それらのギャップにデータは保存されません。これにより、Oracle ループはインデックス位置を介してのみ反復できます。 | DBA |
出力を確認します。 | 連続しない間隔で 5 つの要素が配列 (
| DBA |
| タスク | 説明 | 必要なスキル |
|---|---|---|
PostgreSQL でターゲット PL/pgSQL ブロックを作成します。 PostgreSQL | 次の関連付け配列を使用するターゲット PL/pgSQL ブロックを PostgreSQL に作成します。
| DBA |
PL/pgSQL ブロックを実行します。 | PostgreSQL でターゲット PL/pgSQL ブロックを実行します。 PostgreSQL 関連付け配列のインデックス値の間にギャップがある場合、それらのギャップにデータは保存されません。これにより、Oracle ループはインデックス位置を介してのみ反復できます。 | DBA |
出力を確認します。 |
| DBA |
| タスク | 説明 | 必要なスキル |
|---|---|---|
配列とユーザー定義タイプを使用してターゲット PL/pgSQL ブロックを作成します。 | パフォーマンスを最適化し、Oracle の機能に合わせて、インデックス位置と対応するデータの両方を保存するユーザー定義タイプを作成できます。このアプローチは、インデックスと値間の直接的な関連付けを維持することで、不要な反復を減らします。
| DBA |
PL/pgSQL ブロックを実行します。 | ターゲット PL/pgSQL ブロックを実行します。関連付け配列のインデックス値の間にギャップがある場合、それらのギャップにデータは保存されません。これにより、Oracle ループはインデックス位置を介してのみ反復できます。 | DBA |
出力を確認します。 | 次の出力に示すように、ユーザー定義型は入力済みのデータ要素のみを保存します。つまり、配列の長さは値の数と一致します。その結果、
| DBA |
関連リソース
AWS ドキュメント
その他のドキュメント
