翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データを変換する
Amazon SageMaker Data Wrangler は、データのクリーンアップ、変換、特徴化を効率化するために、多数の ML データ変換を提供します。変換を追加すると、データフローにステップが追加されます。追加する各変換によってデータセットが変更され、新しいデータフレームが生成されます。それ以降のすべての変換は、結果のデータフレームに適用されます。
Data Wrangler には、コードなしで列を変換するために使用できる組み込みの変換が含まれています。PySpark、Python (ユーザー定義関数)、Pandas、PySpark SQL を使用してカスタム変換を追加することもできます。一部の変換は所定の位置で動作しますが、その他の変換はデータセットに新しい出力列を作成します。
変換は複数の列に一度に適用できます。例えば、1 つのステップで複数の列を削除できます。
数値を処理変換および欠落を処理変換を適用できるのは 1 つの列のみです。
このページでは、これらの組み込みの変換とカスタム変換の詳細ついて説明します。
変換 UI
組み込みの変換のほとんどは、Data Wrangler の [Prepare] (準備) タブに配置されています。データフロービューから結合変換と連結変換にアクセスできます。次の表でこれらの 2 つのビューをプレビューします。
![[変換] セクションの上部にある [ステップを追加]。](images/studio/mohave/data-wrangler-add-step.png)
![[変換の追加] セクションの上部にある検索ボックス。](images/studio/mohave/data-wrangler-search.png)

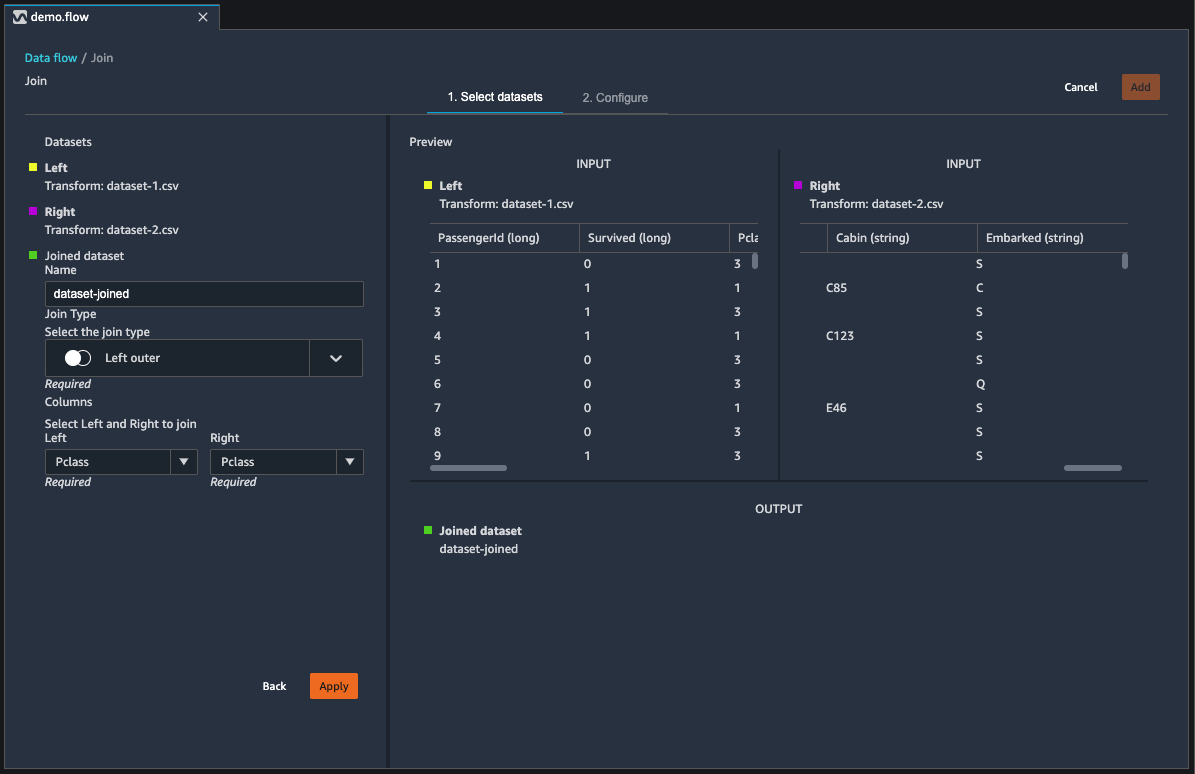
データセットを結合する
データフレームをデータフローに直接結合します。2 つのデータセットを結合すると、結合されたデータセットがフローに表示されます。Data Wrangler では以下の結合タイプがサポートされています。
-
Left Outer (左外部) - 左側のテーブルからすべての行を含めます。左側のテーブル行で結合された列の値が、右側のテーブル行の値と一致しない場合、その行には、結合されたテーブルの右側のテーブル列すべての NULL 値が含まれます。
-
Left Anti (左反) - 結合された列に対して右側のテーブルの値を含まない左側のテーブルから行を含めます。
-
左半 - join ステートメントの条件を満たすすべての同じ行について、左側のテーブルから 1 行を含めます。これにより、結合の条件に一致する重複行が左側のテーブルから除外されます。
-
Right Outer (右外部) - 右側のテーブルからすべての行を含めます。右側のテーブル行で結合された列の値が、左側のテーブル行のいずれかの値と一致しない場合、その行には、結合されたテーブルですべての左側のテーブル列に対する NULL 値が含まれます。
-
内部 - 結合された列で一致する値を含む左側と右側のテーブルから行を含めます。
-
Full Outer (完全外部) - 左側と右側のテーブルからすべての行を含めます。いずれかのテーブルで結合された列に対する行の値が一致しない場合、結合されたテーブルに別々の行が作成されます。結合されたテーブルで列の値が行に含まれていない場合、その列に null が挿入されます。
-
Cartesian Cross (デカルトクロス) - 最初のテーブルの各行と 2 番目のテーブルの各行を結合する行を含めます。これは結合内でテーブルからの行のデカルト積
です。この積の結果は、左側のテーブルのサイズに右側のテーブルのサイズを乗算したものです。したがって、非常に大きなデータセット間でこの結合を使用する場合は注意が必要です。
次の手順を使用して 2 つのデータフレームを結合します。
-
結合する左側のデータフレームの横にある [+] を選択します。最初に選択するデータフレームは、常に結合内の左側のテーブルになります。
-
[参加] を選択します。
-
右側のデータフレームを選択します。2 番目に選択するデータフレームは、常に結合内の右側のテーブルになります。
-
[設定] を選択して結合を設定します。
-
[Name] (名前) フィールドを使用して結合したデータセットに名前を付けます。
-
[Join type] (結合タイプ) を選択します。
-
結合する左側と右側のテーブルから列を選択します。
-
[適用] を選択して、右側で結合したデータセットをプレビューします。
-
結合したテーブルをデータフローに追加するには、[追加] を選択します。
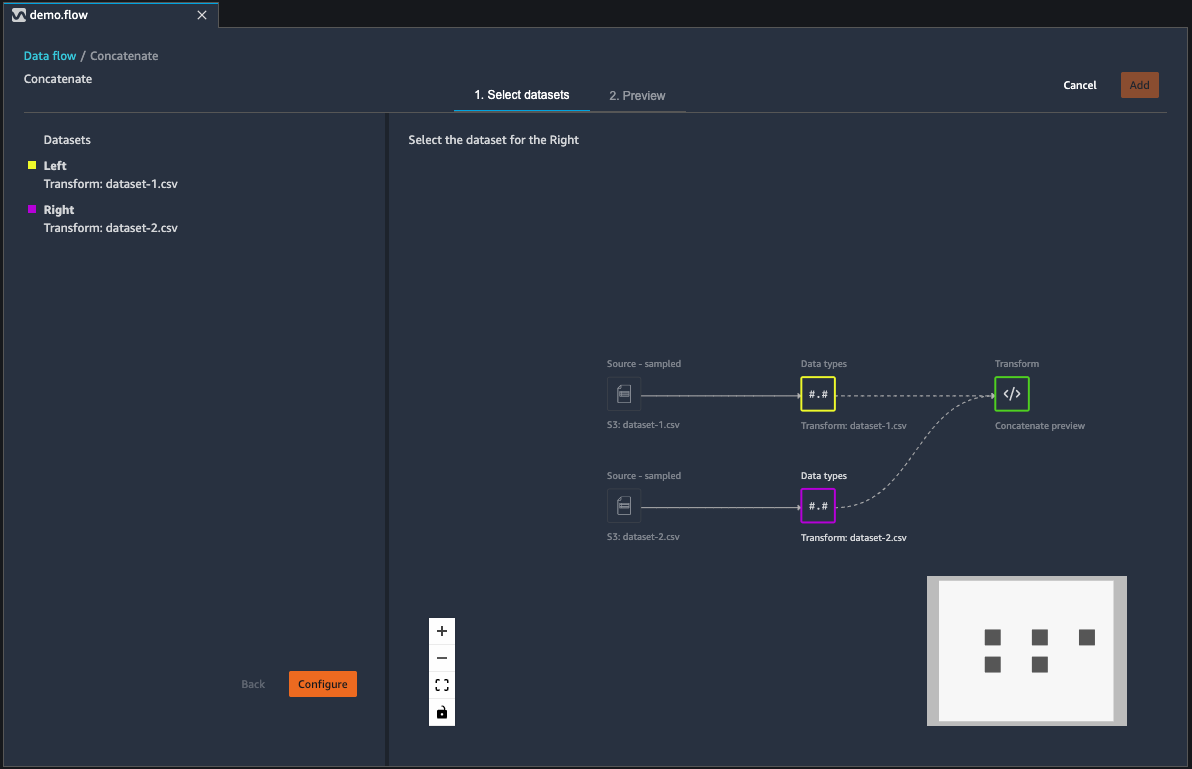
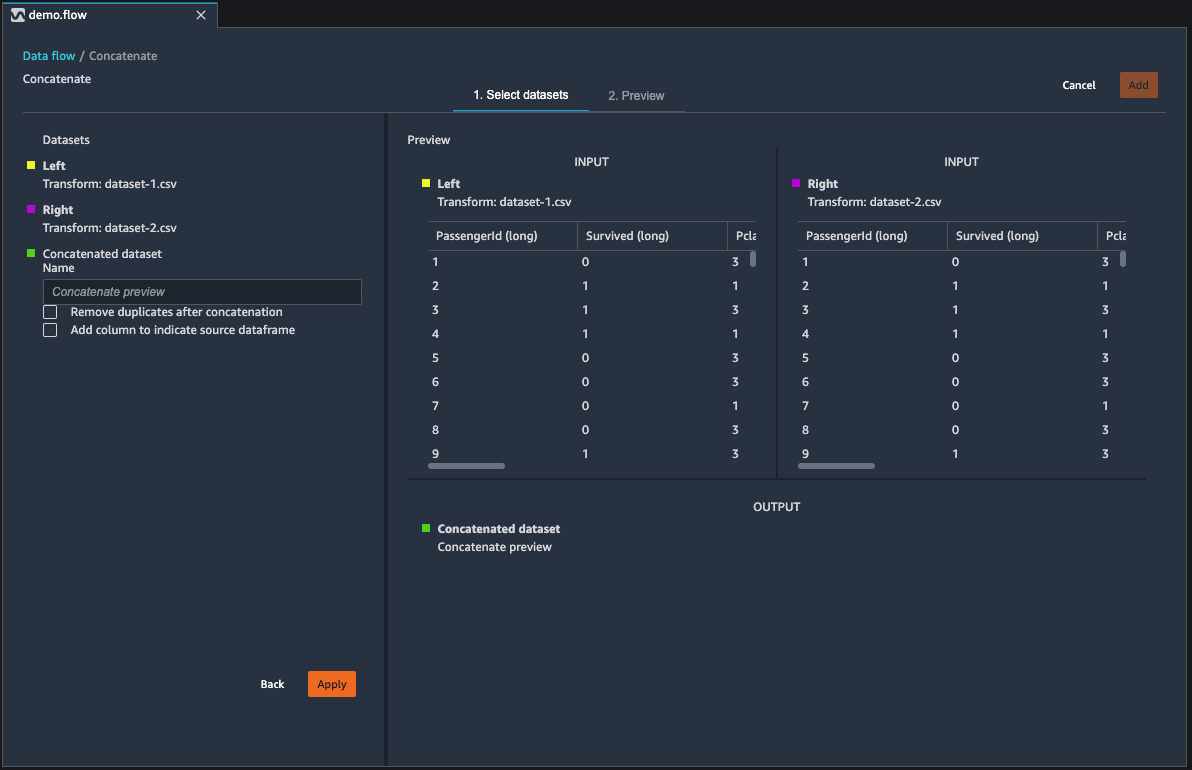
データセットを連結する
2 つのデータセットを連結します。
-
連結する左側のデータフレームの横にある [+] を選択します。最初に選択するデータフレームは、常に連結内の左側のテーブルになります。
-
[連結] を選択します。
-
右側のデータフレームを選択します。2 番目に選択するデータフレームは、常に連結内の右側のテーブルになります。
-
[設定] を選択して連結を設定します。
-
[Name] (名前) フィールドを使用して連結したデータセットに名前を付けます。
-
(オプション) [連結後に重複を削除] の横にあるチェックボックスをオンにして、重複する列を削除します。
-
(オプション) 新しいデータセット内の列ごとに列のソースのインジケータを追加する場合は、[ソースデータフレームを示す列を追加] チェックボックスをオンにします。
-
[適用] を選択して新しいデータセットをプレビューします。
-
[追加] を選択して、新しいデータセットをデータフローに追加します。
バランスデータ
データセットのデータを、過小評価のカテゴリでバランスを取ることができます。データセットのバランスをとることで、バイナリ分類に適したモデルを作成できます。
注記
列ベクトルを含むデータセットのバランスをとることはできません。
次のものを使用できます。バランスデータオペレーションを使用して、次のいずれかの演算子を使用してデータのバランスをとります。
-
ランダムオーバーサンプリング – 少数カテゴリ内のサンプルをランダムに複製します。例えば、不正を検出しようとしている場合、データの 10% に詐欺のケースしか発生しない可能性があります。不正ケースと非詐欺ケースが等しい割合の場合、このオペレーターはデータセット内の不正ケースを 8 回ランダムに複製します。
-
ランダムアンダーサンプリング — ランダムオーバーサンプリングとほぼ同等です。過剰表現されたカテゴリからサンプルをランダムに削除して、目的のサンプルの割合を取得します。
-
合成マイノリティオーバーサンプリング手法 (SMOTE) — 過小評価カテゴリのサンプルを使用して、新しい合成少数サンプルを補間します。SMOTE の詳細については、次の説明を参照してください。
数値特徴量と非数値特徴量の両方を含むデータセットには、すべての変換を使用できます。SMOTE は、隣接するサンプルを使用して値を補間します。Data Wrangler は R 二乗距離を使用して近傍を決定し、追加のサンプルを補間します。Data Wrangler は、数値特徴量のみを使用して、過小表現グループ内のサンプル間の距離を計算します。
過小表現のグループ内の 2 つの実サンプルについて、Data Wrangler は加重平均を使用して数値特徴量を内挿します。[0, 1] の範囲のサンプルにランダムに重みを割り当てます。数値特徴量の場合、Data Wrangler はサンプルの加重平均を使用してサンプルを補間します。サンプル A と B の場合、Data Wrangler は A に 0.7、0.3 を B にランダムに割り当てることができます。補間されたサンプルの値は 0.7A + 0.3B です。
Data Wrangler は、内挿された実サンプルからコピーして、数値以外の特徴を補間します。各サンプルにランダムに割り当てられる確率でサンプルをコピーします。サンプル A と B の場合、確率を A に 0.8、B に 0.2 を割り当てることができます。割り当てられた確率については、時間の A を 80% コピーします。
カスタム変換
[カスタム変換] グループでは常に Pyspark、Pandas、Pyspark (SQL) を使用してカスタム変換を定義できます。3 つのオプションすべてに対して、変数 df を使用し、変換を適用するデータフレームにアクセスします。カスタムコードをデータフレームに適用するには、df 変数に対して行った変換を含むデータフレームを割り当てます。Python (ユーザー定義関数) を使用していない場合は、return ステートメントを含める必要はありません。[プレビュー] を選択してカスタム変換の結果をプレビューします。[追加] を選択して、カスタム変換を前のステップのリストに追加します。
一般的なライブラリは、次のようなカスタム変換コードブロック内の import ステートメントでインポートできます。
-
NumPy バージョン 1.19.0
-
scikit-learn バージョン 0.23.2
-
SciPy バージョン 1.5.4
-
pandas バージョン 1.0.3
-
PySpark バージョン 3.0.0
重要
[カスタム変換] では、名前にスペースや特殊文字が含まれる列はサポートされません。英数字とアンダースコアのみを含む列名を指定することをお勧めします。[Manage columns] (列を管理) 変換グループで [Rename column] (列名を変更) を使用し、列の名前からスペースを削除できます。次のように、Python (Pandas) カスタム変換を追加して 1 つのステップで複数の列からスペースを削除することもできます。この例では、A
column と B column という名前の列を、A_column と B_column にそれぞれ変更します。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
コードブロックに print ステートメントを含めると、[プレビュー] の選択時に結果が表示されます。カスタムコードトランスフォーマーパネルのサイズは変更できます。パネルのサイズを変更すると、コードを記述するためのスペースが増えます。以下の画像は、パネルのサイズ変更を示しています。
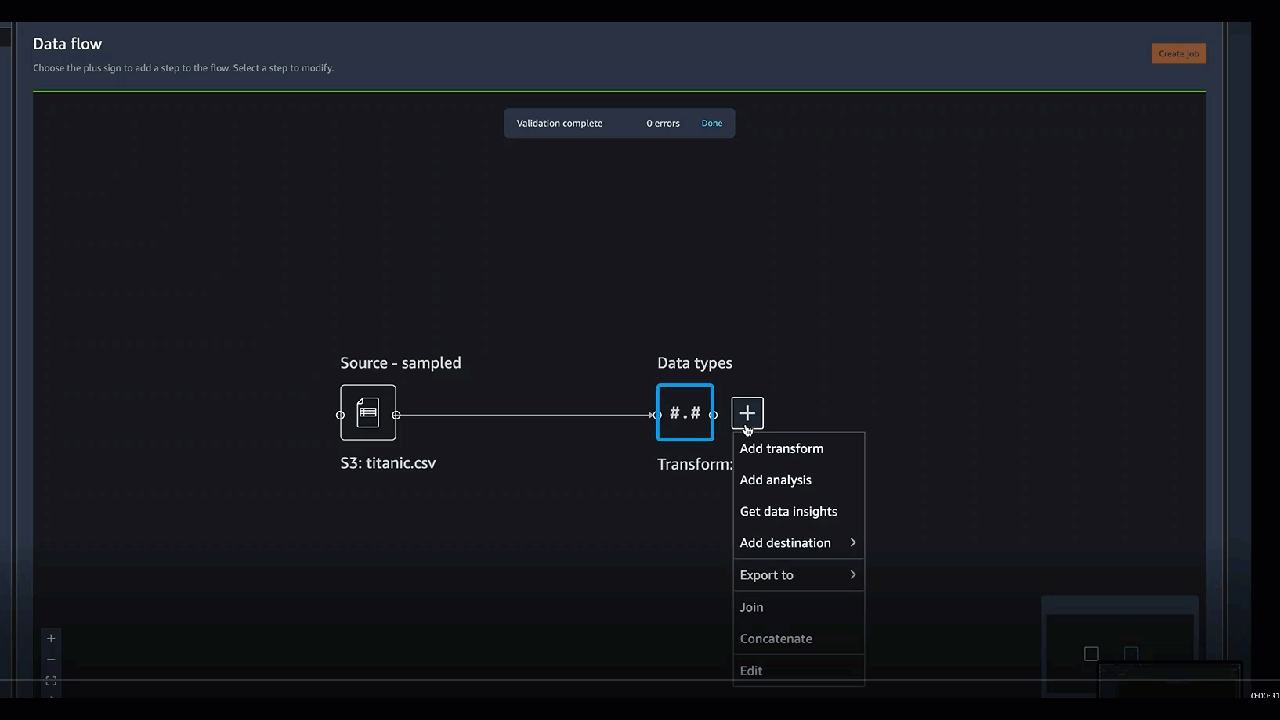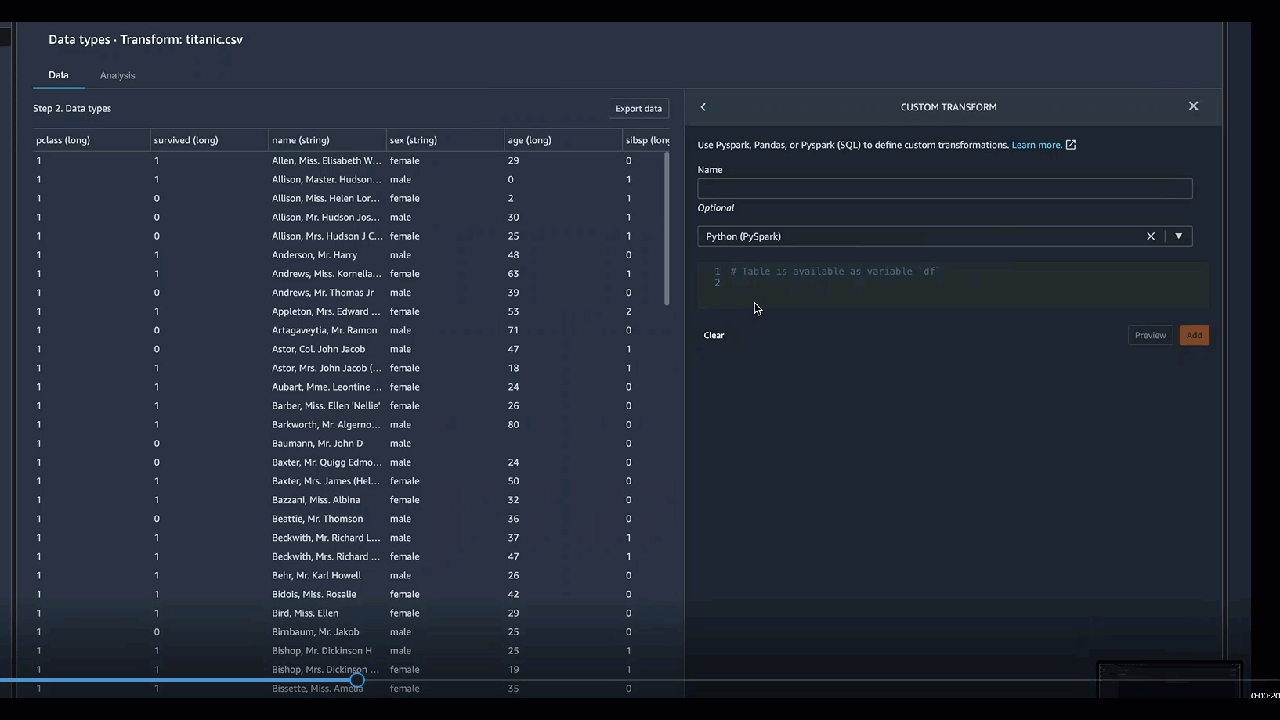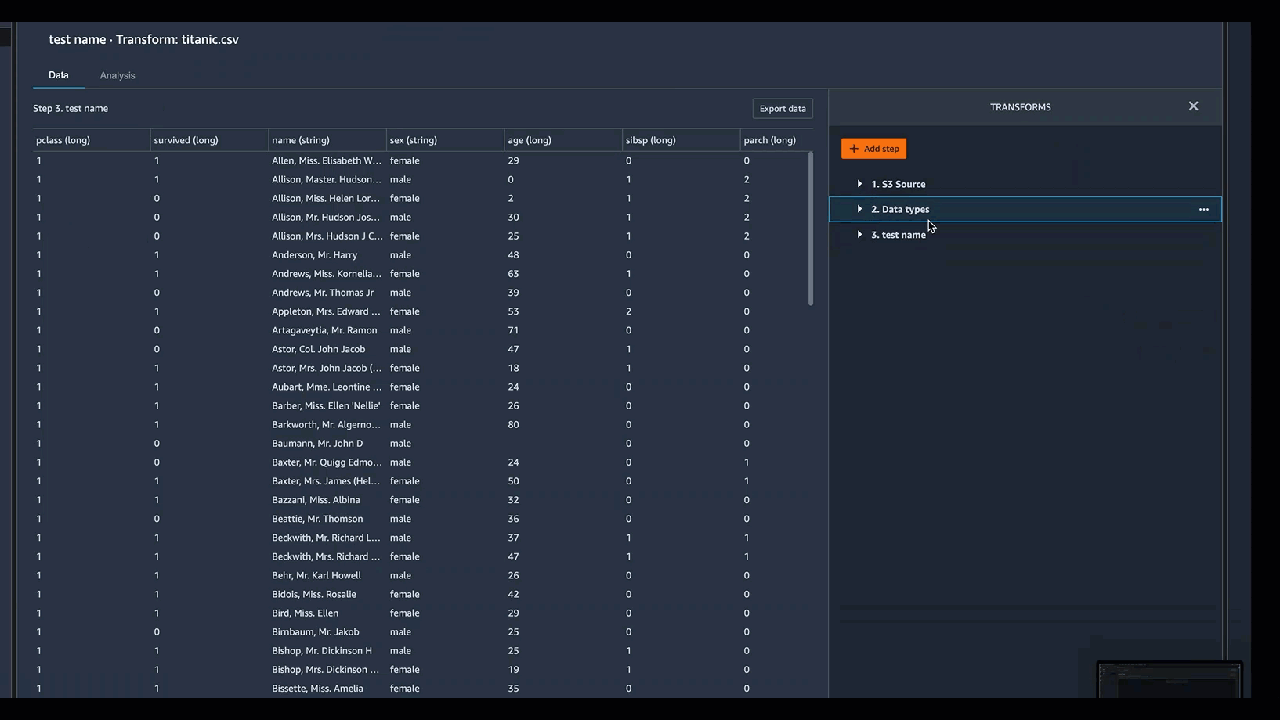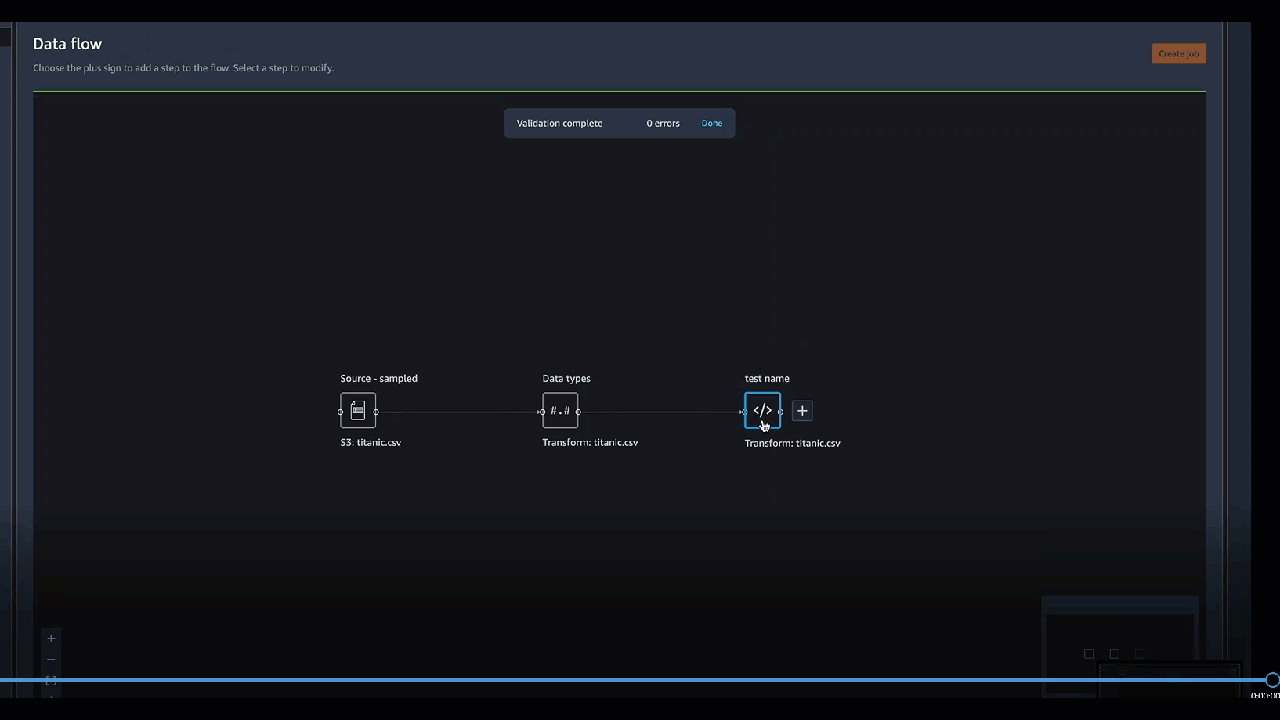
以下のセクションでは、カスタム変換コードを作成するための追加のコンテキストと例を紹介します。
Python (ユーザー定義関数)
Python 関数を使うと、Apache Spark や pandas のことを知らなくてもカスタム変換を書くことができます。Data Wrangler は、カスタムコードをすばやく実行できるように最適化されています。カスタム Python コードと Apache Spark プラグインを使用しても、同様のパフォーマンスが得られます。
Python (ユーザー定義関数) コードブロックを使用するには、次のように指定します。
-
入力列 – 変換を適用する入力列。
-
モード – pandas または Python のスクリプトモード。
-
戻り値の型 – 返す値のデータ型。
pandas モードを使用するとパフォーマンスが向上します。Python モードでは、純粋な Python 関数を使用して変換を簡単に記述できます。
次の動画は、カスタムコードを使用して変換を作成する方法の例を示しています。Titanic データセット
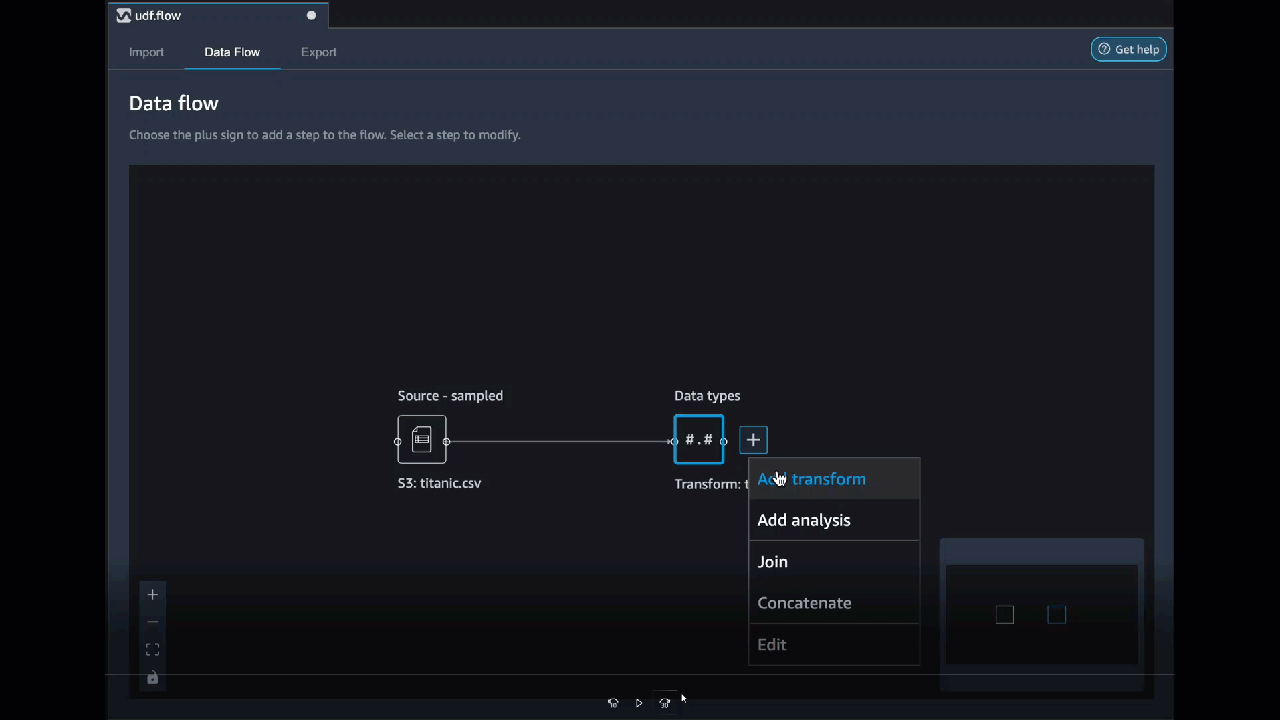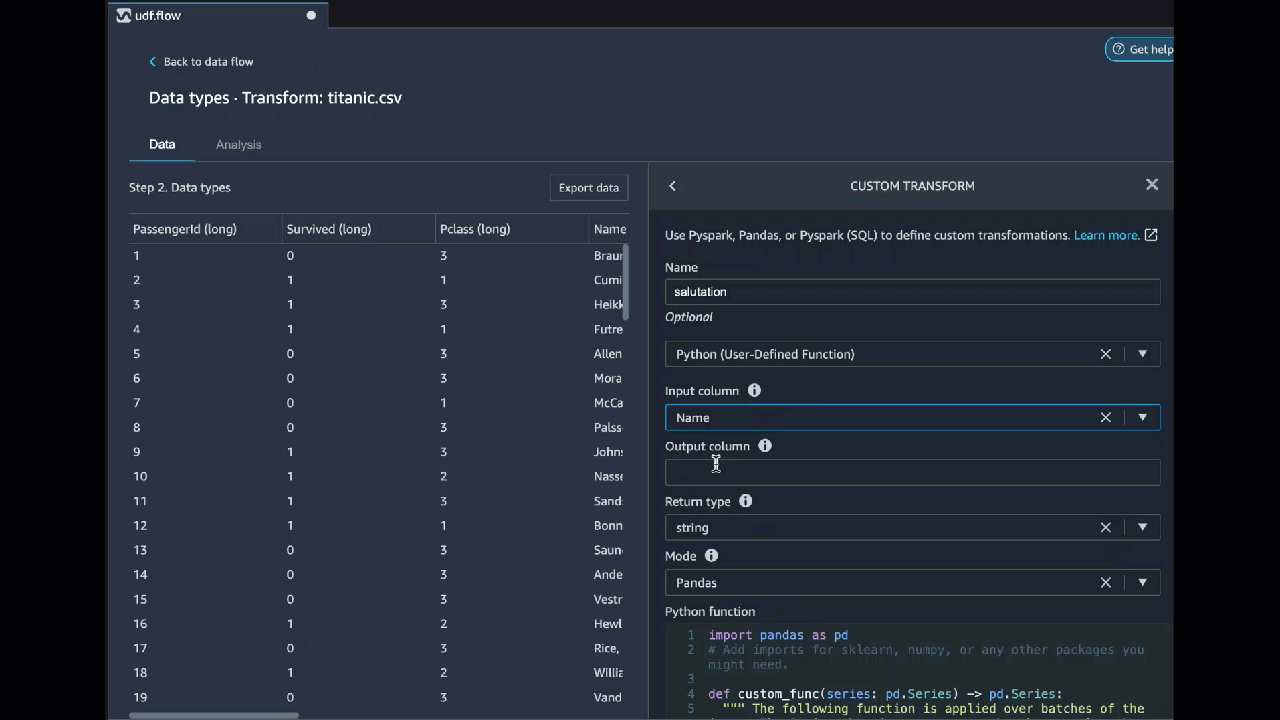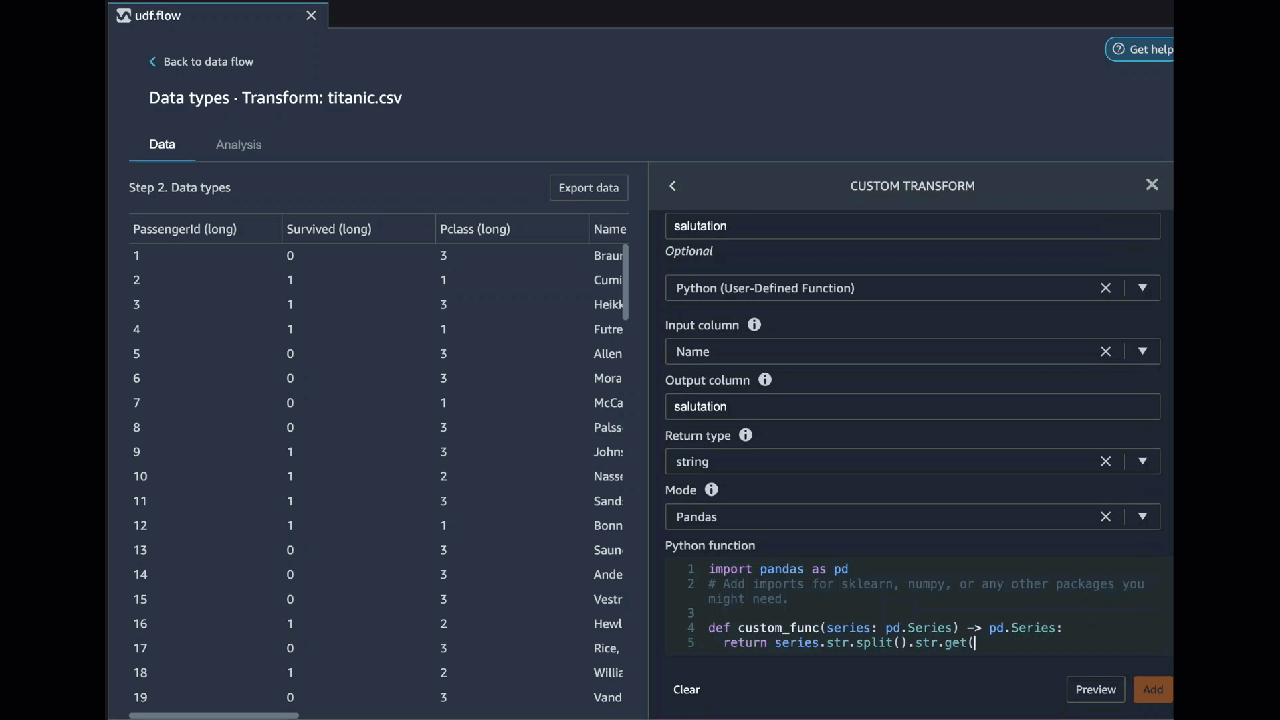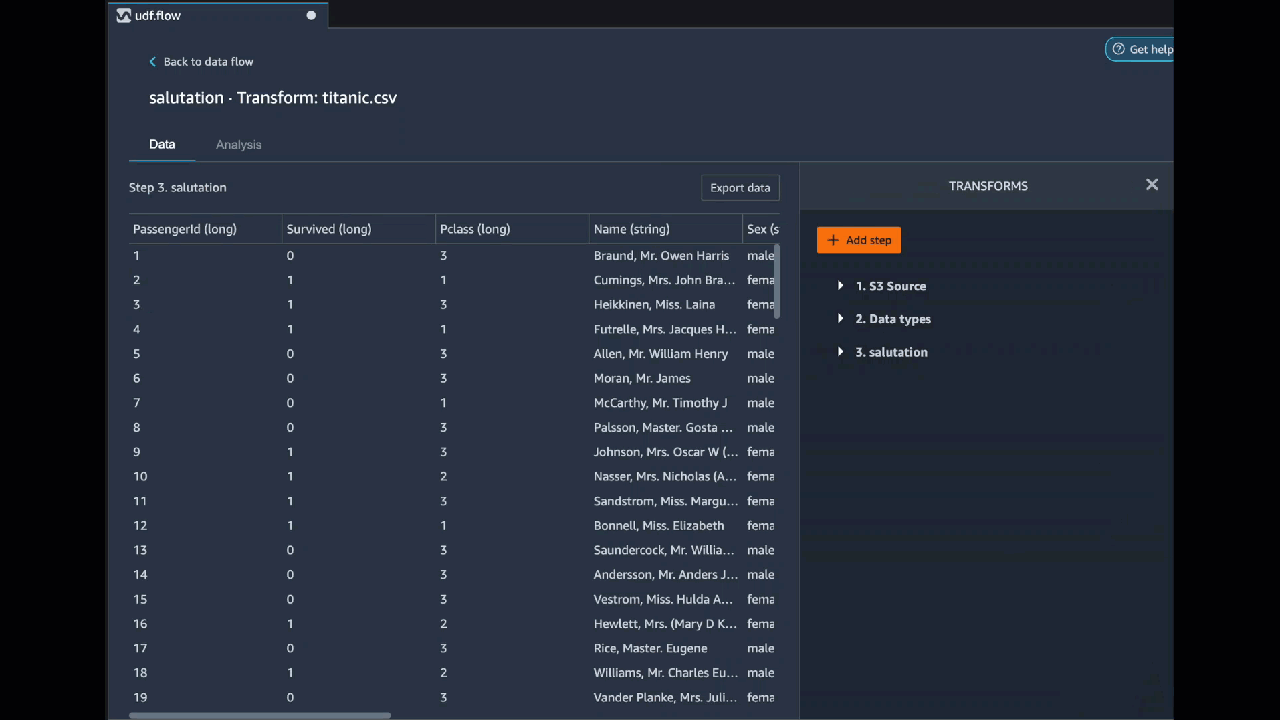
PySpark
次の例では、タイムスタンプから日付と時刻が抽出されます。
from pyspark.sql.functions import from_unixtime, to_date, date_format df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP')) df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
pandas
次の例は、変換を追加するデータフレームの概要を示します。
df.info()
PySpark (SQL)
次の例では、name、fare、pclass、survival の 4 つの列を持つ新しいデータフレームを作成します。
SELECT name, fare, pclass, survived FROM df
PySpark の使用方法がわからない場合は、カスタムコードスニペットを使用して始めることができます。
Data Wrangler には、検索可能なコードスニペットのコレクションがあります。コードスニペットを使用して、列の削除、列ごとのグループ化、モデリングなどのタスクを実行できます。
コードスニペットを使用するには、[サンプルスニペットを検索] を選択し、検索バーにクエリを指定します。クエリで指定するテキストは、コードスニペットの名前と完全に一致する必要はありません。
次の例は、データセット内の類似データを含む行を削除できる Drop duplicate rows コードスニペットを示しています。次のいずれかを検索すると、コードスニペットを見つけることができます。
-
Duplicates
-
Identical
-
Remove
次のスニペットには、必要な変更を理解するのに役立つコメントがあります。ほとんどのスニペットでは、コード内でデータセットの列名を指定する必要があります。
# Specify the subset of columns # all rows having identical values in these columns will be dropped subset = ["col1", "col2", "col3"] df = df.dropDuplicates(subset) # to drop the full-duplicate rows run # df = df.dropDuplicates()
スニペットを使用するには、その内容をコピーして [カスタム変換] フィールドに貼り付けます。複数のコードスニペットをコピーして [カスタム変換] フィールドに貼り付けることができます。
カスタム計算式
カスタム計算式を使用し、Spark SQL 式を使用して現在のデータフレーム内のデータをクエリする新しい列を定義します。クエリでは、Spark SQL 式の表記規則を使用する必要があります。
重要
カスタム計算式では、名前にスペースや特殊文字が含まれる列はサポートされません。英数字とアンダースコアのみを含む列名を指定することをお勧めします。[Manage columns] (列を管理) 変換グループで [Rename column] (列名を変更) を使用し、列の名前からスペースを削除できます。次のように、Python (Pandas) カスタム変換を追加して 1 つのステップで複数の列からスペースを削除することもできます。この例では、A
column と B column という名前の列を、A_column と B_column にそれぞれ変更します。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
この変換を使用して列を名前で参照し、列に対してオペレーションを実行できます。例えば、現在のデータフレームに col_a と col_b という名前の列が含まれていると仮定する場合、次のオペレーションを使用して次のコードを含む 2 つの列の積である出力列を生成できます。
col_a * col_b
データフレームに col_a と col_b 列が含まれることを仮定した、以下のような一般的なオペレーションがあります。
-
2 つの列を連結する:
concat(col_a, col_b) -
2 つの列を追加する:
col_a + col_b -
2 つの列を減算する:
col_a - col_b -
2 つの列を分割する:
col_a / col_b -
列の絶対値を取得する:
abs(col_a)
データの選択の詳細については、Spark ドキュメント
データセット内の次元を減らす
主成分分析 (PCA) を使用してデータの次元を減らします。データセットの次元は特徴量の数に対応します。Data Wrangler で次元削減を使用すると、コンポーネントと呼ばれる新しい機能セットが得られます。各コンポーネントは、データ内のある程度の変動を考慮します。
最初のコンポーネントは、データの変動の最大の原因です。2 番目のコンポーネントはデータの 2 番目に大きい変動量を占め、以降も同様です。
次元削減を使用すると、モデルのトレーニングに使用するデータセットのサイズを小さくすることができます。データセット内の特徴量を使用する代わりに、プリンシパルコンポーネントを使用することもできます。
PCA を実行するために、Data Wrangler はデータの軸を作成します。軸はデータセット内の列のアフィン結合です。最初のプリンシパルコンポーネントは、最大の分散量を持つ軸上の値です。2 番目のプリンシパルコンポーネントは、2 番目に大きな分散量を持つ軸上の値です。n 番目のプリンシパルコンポーネントは、n 番目に大きな分散量を持つ軸上の値です。
Data Wrangler が返すプリンシパルコンポーネントの数は設定できます。プリンシパルコンポーネントの数を直接指定することも、分散しきい値のパーセンテージを指定することもできます。プリンシパルコンポーネントはデータの変動量を説明します。例えば、値が 0.5 のプリンシパルコンポーネントがあるとします。このコンポーネントはデータ変動の 50% を説明します。分散しきい値パーセンテージを指定すると、Data Wrangler は指定したパーセンテージを満たす最小数のコンポーネントを返します。
以下は、プリンシパルコンポーネントとそれによって説明される分散量の例をデータで示しています。
-
コンポーネント 1 – 0.5
-
コンポーネント 2 – 0.45
-
コンポーネント 3 – 0.05
分散しきい値のパーセンテージを 94 または 95 に指定すると、Data Wrangler はコンポーネント 1 とコンポーネント 2 を返します。分散しきい値のパーセンテージを 96 に指定すると、Data Wrangler は 3 つすべてのプリンシパルコンポーネントを返します。
次の手順を使用して、データセットに対して PCA を実行できます。
データセットに対して PCA を実行するには、次の手順を実行します。
-
Data Wrangler のデータフローを開きます。
-
+ を選択し、[変換を追加] を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[次元削減] を選択します。
-
[入力列] では、プリンシパルコンポーネントに削減する特徴量を選択します。
-
(オプション) [プリンシパルコンポーネント数] では、Data Wrangler がデータセットから返すプリンシパルコンポーネントの数を選択します。フィールドの値を指定する場合、[分散しきい値パーセンテージ] の値は指定できません。
-
(オプション) [分散しきい値パーセンテージ]、プリンシパルコンポーネントによって説明するデータの変動率を指定します。分散しきい値を指定しない場合、Data Wrangler はデフォルト値
95を使用します。[プリンシパルコンポーネント数] に値を指定した場合、分散しきい値パーセンテージは指定できません。 -
(オプション) 列の平均をデータの中心として使用しないためには、[中心] を選択解除します。デフォルトでは、Data Wrangler はスケーリング前にデータを平均でセンタリングします。
-
(オプション) データを単位標準偏差でスケールしないためには、[スケール] を選択解除します。
-
(オプション) コンポーネントを別の列に出力するには、[列] を選択します。コンポーネントを 1 つのベクトルとして出力するには、[ベクトル] を選択します。
-
(オプション) [出力列] で、出力列の名前を指定します。コンポーネントを別々の列に出力する場合、指定する名前はプレフィックスです。コンポーネントをベクトルに出力する場合、指定する名前はベクトル列の名前です。
-
(オプション) [入力列を保持] を選択します。モデルのトレーニングにプリンシパルコンポーネントのみを使用する予定がある場合は、このオプションを選択することはお勧めしません。
-
[プレビュー] を選択します。
-
[Add] (追加) を選択します。
カテゴリ別にエンコードする
カテゴリ別データは通常、有限数のカテゴリで構成され、各カテゴリは文字列で表されます。例えば、顧客データのテーブルがある場合、顧客が住んでいる国を示す列はカテゴリです。カテゴリはアフガニスタン、アルバニア、アルジェリアなど、さまざまです。カテゴリ別データは公称または序数にできます。序数カテゴリには固有の順序があり、公称カテゴリに固有の順序はありません。取得した最高学位 (高校、学士、修士) は、序数カテゴリの一例です。
カテゴリ別データのエンコーディングは、カテゴリの数値表現を作成するプロセスです。例えば、カテゴリが犬と猫の場合、犬を表す [1,0] と猫を表す [0,1] の 2 つのベクトルにこの情報をエンコードできます。
序数カテゴリをエンコードする場合、カテゴリの自然順序をエンコーディングに変換する必要があることがあります。例えば、{"High school": 1, "Bachelors": 2,
"Masters":3} のマップで得られた最高学位を表すことができます。
カテゴリ別エンコーディングを使用して、文字列形式のカテゴリ別データを整数の配列にエンコードします。
Data Wrangler カテゴリ別エンコーダは、ステップの定義時に列に存在するすべてのカテゴリのエンコーディングを作成します。Data Wrangler ジョブを開始して時間 t にデータセットを開始するときに新しいカテゴリが列に追加され、この列が時間 t-1 における Data Wrangler のカテゴリ別エンコーディング変換の入力であった場合、これらの新しいカテゴリは Data Wrangler ジョブで欠落していると見なされます。[無効な処理戦略] に対して選択するオプションはこれらの欠落した値に適用されます。この問題が発生する可能性がある例を以下に示します。
-
.flow ファイルを使用して Data Wrangler ジョブを作成し、データフローの作成後に更新されたデータセットを処理する場合。データフローを使用して毎月の売上データを定期的に処理する場合などです。売上データが毎週更新される場合、エンコードのカテゴリ別ステップが定義された列に新しいカテゴリが導入される可能性があります。
-
データセットのインポート時に [サンプリング] を選択した場合、一部のカテゴリがサンプルから除外されることがあります。
このような状況において、これらの新しいカテゴリは Data Wrangler ジョブで欠落した値と見なされます。
序数とワンホットエンコードから選択して設定できます。これらのオプションの詳細については、次のセクションを参照してください。
どちらの変換も、[出力列名] という名前の新しい列を作成します。この列の出力形式は、[出力スタイル] で指定します。
-
[ベクトル] を選択してスパースベクトルを含む 1 つの列を生成します。
-
[列] を選択し、元の列のテキストにそのカテゴリと等しい値が含まれているかどうかを示すインジケータ変数を使用して、すべてのカテゴリの列を作成します。
序数エンコード
[序数エンコード] を選択し、0 と、選択した [入力列] のカテゴリ総数との間の整数にカテゴリをエンコードします。
Invalid handing strategy (無効な処理戦略): 無効な値または欠落した値を処理する方法を選択します。
-
欠落した値のある行を省略する場合は [Skip] (省略) を選択します。
-
欠落した値を最後のカテゴリとして保持する場合は [Keep] (保持) を選択します。
-
欠落した値が [Input column] (入力列) で検出された場合に Data Wrangler でエラーをスローさせる場合は [Error] (エラー) を選択します。
-
欠落した値を NaN に置き換える場合は [NaN に置き換え] を選択します。このオプションは、ML アルゴリズムで欠落した値を処理できる場合に推奨されます。それ以外の場合、このリストの最初の 3 つのオプションから、より良い結果が得られる可能性があります。
ワンホットエンコード
[変換] に対して [ワンホットエンコード] を選択し、ワンホットエンコーディングを使用します。この変換は、以下を使用して設定します。
-
最後のカテゴリをドロップ:
Trueの場合、最後のカテゴリにワンホットエンコーディングに対応するインデックスはありません。欠落した値を使用できる場合、欠落しているカテゴリは常に最後のカテゴリになり、これをTrueに設定すると欠落した値がすべてゼロベクトルになることを意味します。 -
Invalid handing strategy (無効な処理戦略): 無効な値または欠落した値を処理する方法を選択します。
-
欠落した値のある行を省略する場合は [Skip] (省略) を選択します。
-
欠落した値を最後のカテゴリとして保持する場合は [Keep] (保持) を選択します。
-
欠落した値が [Input column] (入力列) で検出された場合に Data Wrangler でエラーをスローさせる場合は [Error] (エラー) を選択します。
-
-
入力の序数がエンコードされている: 入力ベクトルに序数でエンコードされたデータが含まれている場合、このオプションを選択します。このオプションでは、入力データに負でない整数が含まれている必要があります。True の場合、入力 i は、i 番目の場所のゼロ以外のベクトルとしてエンコードされます。
類似度エンコード
次のような場合は、類似度エンコーディングを使用します。
-
多数のカテゴリ変数
-
ノイズの多いデータ
類似度エンコーダーは、カテゴリカルデータを含む列の埋め込みを作成します。埋め込みとは、単語などの個別オブジェクトから実数のベクトルへのマッピングです。類似する文字列を、同様の値を含むベクトルにエンコードします。例えば、「California」と「Calfornia」に非常によく似たエンコーディングを作成します。
Data Wrangler は、3 グラムのトークナイザーを使用して、データセット内の各カテゴリをトークンのセットに変換します。これは、最小ハッシュエンコーディングを使用してトークンを埋め込みに変換します。
次の例は、類似度エンコーダーが文字列からベクトルを作成する方法を示しています。
![Data Wrangler コンソールでテーブルに [ENCODE CATEGORICAL] を使用する例](images/studio/mohave/destination-nodes/similarity-encode-example-screenshot-0.png)

Data Wrangler が作成する類似度エンコーディングは次のとおりです。
-
次元性が低い
-
多数のカテゴリに対応できるスケーラブルですか
-
堅牢でノイズに強いですか
上記の理由から、類似度エンコーディングは、ワンホットエンコーディングよりも汎用性が高いです。
類似度エンコーディング変換をデータセットに追加するには、以下の手順に従います。
類似度エンコーディングを使用するには、次の手順を実行します。
-
Amazon SageMaker AI コンソール
にサインインします。 -
[Studio Classic を開く] を選択します。
-
[アプリの起動] を選択します。
-
[Studio] を選択します。
-
データフローを指定します。
-
変換のあるステップを選択します。
-
[Add step] (ステップを追加) を選択します。
-
[カテゴリでエンコードする] を選択します。
-
次を指定します:
-
変換 – 類似度エンコード
-
入力列 – エンコードするカテゴリデータを含む列。
-
ターゲットディメンション – (オプション) カテゴリカル埋め込みベクトルの次元。デフォルト値は 30 です。多数のカテゴリを持つ大規模なデータセットがある場合は、より大きなターゲットディメンションを使用することをお勧めします。
-
出力スタイル – すべてのエンコードされた値を持つ 1 つのベクトルの場合は、[ベクトル] を選択します。エンコードされた値を別の列に含めるには、[列] を選択します。
-
出力列 – (オプション) ベクトルエンコードされた出力の出力列の名前。列エンコードされた出力の場合、これは列名のプレフィクスとその後にリストされた数字が続きます。
-
テキストを特徴化する
テキストを特徴化変換グループを使用して文字列型の列を検査し、テキストの埋め込みを使用してこれらの列を特徴化します。
この特徴グループには、文字統計とベクトル化の 2 つの特徴が含まれます。これらの変換の詳細については、次のセクションを参照してください。どちらのオプションでも、[入力列] にはテキストデータ (文字列型) を含める必要があります。
文字統計
[文字統計] を選択して、テキストデータを含む列の各行に対する統計を生成します。
この変換は、各行に対する次の比率とカウントを計算し、結果をレポートする新しい列を作成します。新しい列の名前は、入力列名をプレフィックスとして使用し、比率またはカウントに固有のサフィックスを使用します。
-
単語数: その行の合計単語数。この出力列のサフィックスは
-stats_word_countです。 -
文字数: その行の合計文字数。この出力列のサフィックスは
-stats_char_countです。 -
大文字の比率: A から Z までの大文字の数を、列のすべての文字数で割った数。この出力列のサフィックスは
-stats_capital_ratioです。 -
小文字の比率: a から z までの小文字の数を、列のすべての文字数で割った数。この出力列のサフィックスは
-stats_lower_ratioです。 -
桁の比率: 入力列の数字の桁の合計に対する 1 行の桁の比率。この出力列のサフィックスは
-stats_digit_ratioです。 -
特殊文字の比率: 入力列のすべての文字の合計数に対する英数字以外の文字 (#$&%:@ などの文字) の数の比率。この出力列のサフィックスは
-stats_special_ratioです。
ベクトル化
テキストの埋め込みには、語彙の単語やフレーズから実数のベクトルへのマッピングが含まれます。Data Wrangler のテキスト埋め込み変換を使用して、テキストデータを用語の頻度 — 逆文書の頻度 (TF-IDF) ベクトルにトークン化およびベクトル化します。
テキストデータの列について TF-IDF を計算すると、各文の各単語は、その意味的な重要性を表す実数に変換されます。数字が大きいほど頻度が低い単語に関連付けられ、より重要性が高くなる傾向があります。
ベクトル化変換ステップを定義すると、Data Wrangler はデータセット内のデータを使用してカウントベクトル化メソッドと TF-IDF メソッドを定義します。Data Wrangler ジョブの実行には、これらと同じメソッドを使用します。
この変換は、以下を使用して設定します。
-
出力列名: この変換により、テキストが埋め込まれた新しい列が作成されます このフィールドを使用して、この出力列の名前を指定します。
-
トークナイザ: トークナイザが文を単語のリスト、つまりトークンに変換します。
[スタンダード] を選択し、空白で区切って各単語を小文字に変換するトークナイザを使用します。例えば、
"Good dog"は["good","dog"]にトークン化されます。[カスタム] を選択し、カスタマイズしたトークナイザを使用します。[カスタム] を選択した場合、次のフィールドを使用してトークナイザを設定できます。
-
トークンの最小長: トークンが有効になる最小の長さ (文字単位)。デフォルトは
1です。例えば、トークンの最小長を3と指定した場合、a, at, inのような単語はトークン化された文から削除されます。 -
正規表現をギャップで分割: 選択した場合、[regex] がギャップで分割されます。それ以外の場合、トークンに一致します。デフォルトは
Trueです。 -
正規表現パターン: トークン化プロセスを定義する正規表現パターン。デフォルトは
' \\ s+'です。 -
小文字に変換: 選択すると、トークン化前にすべての文字が小文字に変換されます。デフォルトは
Trueです。
詳細については、Spark ドキュメントの「トークン化
」を参照してください。 -
-
ベクタライザ: ベクタライザはトークンのリストをスパース数値ベクトルに変換します。各トークンはベクトル内のインデックスに対応し、ゼロ以外の値は入力文中のトークンの存在を示します。2 つのベクタライザオプション [カウント] と [ハッシュ] から選択できます。
-
[カウントベクトル化] は頻度の低いトークンまたは一般的すぎるトークンをフィルタリングするカスタマイズを許可します。[カウントベクトル化パラメータ] には以下が含まれます。
-
[用語の最小頻度]: 各行で、頻度の小さい用語 (トークン) がフィルタリングされます。整数を指定する場合、これは絶対しきい値 (包括) です。0 (を含む) から 1 までの分数を指定すると、しきい値は用語の合計数を基準にします。デフォルトは
1です。 -
ドキュメントの最小頻度: 用語 (トークン) を含める必要がある行の最小数。整数を指定する場合、これは絶対しきい値 (包括) です。0 (を含む) から 1 までの分数を指定すると、しきい値は用語の合計数を基準にします。デフォルトは
1です。 -
ドキュメントの最大頻度: 用語 (トークン) を含めることができるドキュメント (行) の最大数。整数を指定する場合、これは絶対しきい値 (包括) です。0 (を含む) から 1 までの分数を指定すると、しきい値は用語の合計数を基準にします。デフォルトは
0.999です。 -
最大語彙サイズ: 語彙の最大サイズ。語彙は、列のすべての行のすべての用語 (トークン) で構成されています。デフォルトは
262144です。 -
バイナリ出力: 選択すると、ベクトル出力にドキュメント内の用語の出現数は含まれず、その出現のバイナリインジケータになります。デフォルトは
Falseです。
このオプションの詳細については、Spark ドキュメントの「CountVectorizer
」を参照してください。 -
-
[ハッシュ] は計算が高速です。[ハッシュベクタライズパラメータ] には以下が含まれます。
-
ハッシュ中の特徴の数: ハッシュベクタライザは、ハッシュ値に従ってトークンをベクトルインデックスにマッピングします。この機能は、使用可能なハッシュ値の数を決定します。値が大きいほどハッシュ値間の競合は少なくなりますが、次数の出力ベクトルは大きくなります。
このオプションの詳細については、Spark ドキュメントの「FeatureHasher
」を参照してください。 -
-
-
[IDF を適用] は、IDF 変換が適用され、それにより、TF-IDF 埋め込みに使用される標準の逆文書の頻度で用語の頻度が乗算されます。[IDF パラメータ] には、以下が含まれます。
-
ドキュメントの最小頻度: 用語 (トークン) を含める必要があるドキュメントの最小数。count_vectorize が、選択したベクトルである場合は、デフォルト値を維持し、[カウントベクタライズパラメータ] の min_doc_freq フィールドのみを変更することをお勧めします。デフォルトは
5です。
-
-
出力形式:各行の出力形式。
-
[Vector] (ベクトル) を選択してスパースベクトルを含む 1 つの列を生成します。
-
[フラット化] を選択し、元の列のテキストにそのカテゴリと等しい値が含まれているかどうかを示すインジケータ変数を使用して、すべてのカテゴリの列を作成します。フラット化を選択できるのは、[ベクタライザ] が [カウントベクタライザ] として設定されている場合のみです。
-
時系列を変換する
Data Wrangler では、時系列データを変換できます。時系列データセット内の値は、特定の時間にインデックス作成されます。例えば、1 日の各時間における店舗内の顧客数を示すデータセットは時系列データセットです。次の表は、時系列データセットの例を示しています。
店舗にいる 1 時間あたりの顧客数
| 顧客の数 | 時間 (時) |
|---|---|
| 4 | 09:00 |
| 10 | 10:00 |
| 14 | 11:00 |
| 25 | 12:00 |
| 20 | 13:00 |
| 18 | 14:00 |
前の表では、[顧客の数] 列には時系列データが含まれています。時系列データは、[時間 (時)] 列の時間ごとのデータ基づいてインデックス付けれます。
分析に使用できる形式でデータを取得するには、データに対して一連の変換を実行する必要がある場合があります。[Time series] (時系列) 変換グループを使用して時系列データを変換します。実行可能な変換の詳細については、次のセクションを参照してください。
トピック
時系列でグループ化する
グループ化操作を使用して、列内の特定の値の時系列データをグループ化できます。
例えば、世帯の 1 日の平均電力使用量を追跡した次の表があるとします。
1 日の平均世帯電力使用量
| 世帯 ID | 日次タイムスタンプ | 電力使用量 (kWh) | 世帯の占有人数 |
|---|---|---|---|
| household_0 | 1/1/2020 | 30 | 2 |
| household_0 | 1/2/2020 | 40 | 2 |
| household_0 | 1/4/2020 | 35 | 3 |
| household_1 | 1/2/2020 | 45 | 3 |
| household_1 | 1/3/2020 | 55 | 4 |
ID 別のグループ化を選択した場合、次の表が表示されます。
世帯 ID 別にグループ化された電力使用量
| 世帯 ID | 電力使用量シリーズ (kWh) | 世帯の占有人数シリーズ |
|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] |
| household_1 | [45, 55] | [3, 4] |
時系列シーケンスの各エントリは、対応するタイムスタンプ順に並べられます。シーケンスの最初の要素は、シリーズの最初のタイムスタンプに対応します。household_0、30 は、[電力使用量シリーズ] の最初の値です。30 の値は 1/1/2020 の最初のタイムスタンプに対応します。
開始タイムスタンプと終了タイムスタンプを含めることができます。次の表はその情報がどのように表示されるかを示しています。
世帯 ID 別にグループ化された電力使用量
| 世帯 ID | 電力使用量シリーズ (kWh) | 世帯の占有人数シリーズ | Start_time | End_time |
|---|---|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] | 1/1/2020 | 1/4/2020 |
| household_1 | [45, 55] | [3, 4] | 1/2/2020 | 1/3/2020 |
次の手順に従って、時系列の列別にグループ化できます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[時系列] を選択します。
-
[変換] で [グループ化] を選択します。
-
[この列でグループ化] で列を指定します。
-
[列に適用] の値を指定します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列データを再サンプリングする
時系列データには通常、取得される間隔が一定ではない観測値があります。例えば、データセットには 1 時間ごとに記録される観測値と 2 時間ごとに記録される別の観測値が含まれる場合があります。
予測アルゴリズムなど、多くの分析では、観測値を一定の間隔で取得する必要があります。再サンプリングにより、データセット内の観測値に対して一定の間隔を確立できます。
時系列をアップサンプリングまたはダウンサンプリングできます。ダウンサンプリングは、データセットの観測値の間隔を大きくします。例えば、1 時間ごとまたは 2 時間ごとに取得される観測値をダウンサンプリングすると、データセット内の各観測値は 2 時間ごとに取得されます。時間単位の観測値は、平均値や中央値などの集計方法を使用して 1 つの値に集計されます。
アップサンプリングは、データセットの観測値の間隔を小さくします。例えば、2 時間ごとに取得される観測値を 1 時間ごとに取得される観測値にアップサンプリングする場合、補間法を使用して 2 時間ごとに取得された観測値から 1 時間ごとに取得される観測値を推測できます。補間法の詳細については、「pandas.dataframe.interpolate
数値データと非数値データの両方を再サンプリングできます。
[再サンプル] オペレーションを使用して、時系列データを再サンプリングします。データセットに複数の時系列がある場合、Data Wrangler は各時系列の時間間隔を標準化します。
次の表は、平均値を集計方法として使用して時系列データをダウンサンプリングする例を示しています。データは 2 時間ごとから 1 時間ごとにダウンサンプリングされます。
ダウンサンプリング前日の 1 時間単位の温度読み取り値
| Timestamp | 温度 (摂氏) |
|---|---|
| 12:00 | 30 |
| 1:00 | 32 |
| 2:00 | 35 |
| 3:00 | 32 |
| 4:00 | 30 |
2 時間ごとにダウンサンプリングされた温度読み取り値
| Timestamp | 温度 (摂氏) |
|---|---|
| 12:00 | 30 |
| 2:00 | 33.5 |
| 4:00 | 35 |
次の手順を使用して、時系列データを再サンプリングできます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[再サンプリング] を選択します。
-
[タイムスタンプ] で、タイムスタンプ列を選択します。
-
[頻度単位] で、再サンプリングする頻度を指定します。
-
(オプション) [頻度の数] の値を指定します。
-
残りのフィールドを指定して変換を設定します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
欠落している時系列データを処理する
データセットに欠落した値がある場合、次のいずれかを実行できます。
-
複数の時系列を持つデータセットの場合、指定したしきい値よりも欠落した値が大きい時系列をドロップします。
-
時系列の他の値を使用して、時系列の欠落した値を帰属化します。
欠落した値を帰属化するには、値を指定するか、推論法を使用してデータを置き換えます。以下に、補間に使用できる方法を示します。
-
定数値 - データセットで欠落しているすべてのデータを、指定した値に置き換えます。
-
最も一般的な値 - 欠落しているすべてのデータを、データセットで最も頻度が高い値に置き換えます。
-
フォワードフィル - フォワードフィルを使用して、欠落値を欠落値より前にある欠落値以外の値に置き換えます。シーケンス [2, 4, 7, NaN, NaN, NaN, 8] の場合、欠落値はすべて 7 に置き換えられます。フォワードフィルを使用した場合のシーケンスは [2, 4, 7, 7, 7, 7, 8] です。
-
バックワードフィル - バックワードフィルを使用して、欠落値を欠落値の後にある欠落値以外の値に置き換えます。シーケンス [2, 4, 7, NaN, NaN, NaN, 8] の場合、欠落値はすべて 8 に置き換えられます。バックワードフィルを使用した場合のシーケンスは [2, 4, 7, 8, 8, 8, 8] です。
-
補間 - 補間関数を使用して欠落値を帰属化します。補間に使用できる関数の詳細については、「pandas.dataframe.interpolate
」を参照してください。
補間法によっては、データセット内の一部の欠落値を帰属化できない場合があります。例えば、[フォワードフィル] で時系列の先頭に表示される欠落値を計算することはできません。フォワードフィルまたはバックフィルを使用して値を帰属化できます。
セル内または列内の欠落値を帰属化できます。
次の例は、セル内で値がどのように帰属化されるかを示しています。
欠落値のある電力使用量
| 世帯 ID | 電力使用量シリーズ (kWh) |
|---|---|
| household_0 | [30, 40, 35, NaN, NaN] |
| household_1 | [45, NaN, 55] |
フォワードフィルを使用して帰属化した値による電力使用量
| 世帯 ID | 電力使用量シリーズ (kWh) |
|---|---|
| household_0 | [30, 40, 35, 35, 35] |
| household_1 | [45, 45, 55] |
次の例は、列内で値がどのように帰属化されるかを示しています。
欠落値のある 1 日の平均世帯電力使用量
| 世帯 ID | 電力使用量 (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | NaN |
| household_1 | NaN |
| household_1 | NaN |
フォワードフィルを使用して帰属化した値による平均日次電力使用量
| 世帯 ID | 電力使用量 (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | 40 |
| household_1 | 40 |
| household_1 | 40 |
次の手順に従って、欠落値を処理できます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[欠落値を処理] を選択します。
-
[時系列入力型] で、欠落値をセル内または列に沿って処理するかどうかを選択します。
-
[この列の欠落値を帰属化] で、欠落値がある列を指定します。
-
[値を帰属化する方法] で、方法を選択します。
-
残りのフィールドを指定して変換を設定します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
欠落値がある場合、[値を帰属化する方法] でそれらを帰属化する方法を指定できます。
-
[Add] (追加) を選択して、Data Wrangler データフローに変換を追加します。
時系列データのタイムスタンプを検証する
無効なタイムスタンプデータが含まれている可能性があります。[タイムスタンプを検証] 機能を使用して、データセット内のタイムスタンプが有効かどうかを判断できます。タイムスタンプは、次の 1 つ以上の理由で無効になる可能性があります。
-
タイムスタンプの列に欠落値がある。
-
タイムスタンプの列の値が正しい形式に設定されていない。
データセットに無効なタイムスタンプがある場合、分析を正常に実行することはできません。Data Wrangler を使用して無効なタイムスタンプを特定し、データを消去する必要がある場所を把握できます。
時系列の検証は、次の 2 つの方法のいずれかで動作します。
データセットに欠落値が見つかった場合に次のいずれかの操作を実行するように Data Wrangler を構成できます。
-
欠落した値または無効な値がある行をドロップする。
-
欠落した値または無効な値がある行を特定する。
-
データセットに欠落した値または無効な値が見つかった場合はエラーをスローする。
タイムスタンプは、timestamp 型または string 型がある列で検証できます。列に string 型がある場合、Data Wrangler はその列の型を timestamp に変換し、検証を実行します。
次の手順に従って、データセット内のタイムスタンプを検証できます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[タイムスタンプを検証] を選択します。
-
[タイムスタンプ列] で、タイムスタンプ列を選択します。
-
[ポリシー] で、欠落しているタイムスタンプを処理するかどうかを選択します。
-
(オプション) [出力列] で、出力列の名前を指定します。
-
日時列が文字列型用に形式が設定されている場合、[Cast to datetime] (日時にキャスト) を選択します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列の長さを標準化する
時系列データを配列として保存している場合、各時系列を同じ長さに標準化できます。時系列配列の長さを標準化すると、データの分析を簡単に実行できる場合があります。
データの長さを固定する必要があるデータ変換のために時系列を標準化できます。
多くの ML アルゴリズムでは、時系列データを使用する前にフラット化する必要があります。時系列データのフラット化とは、時系列の各値をデータセット内の独自の列に分割することです。データセット内の列数は変更できないため、各配列を特徴セットにフラット化して時系列の長さを標準化する必要があります。
各時系列は、時系列セットの分位または百分位として指定した長さに設定されます。例えば、次の長さの 3 つのシーケンスを使用できます。
-
3
-
4
-
5
すべてのシーケンスの長さを 50 番目の百分位の長さとして設定できます。
指定した長さより短い時系列配列には、欠落値が追加されます。次に、時系列をより長い [2, 4, 5, NaN, NaN, NaN] に標準化する形式の例を示します。
さまざまなアプローチを使用して欠落値を処理できます。これらのアプローチの詳細については、「欠落している時系列データを処理する」を参照してください。
指定した長さよりも長い時系列配列は切り捨てられます。
次の手順を使用して、時系列の長さを標準化できます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[長さを標準化] を選択します。
-
[列の時系列長を標準化] で列を選択します。
-
(オプション) [出力列] で、出力列の名前を指定します。名前を指定しない場合、変換はそのまま行われます。
-
日時列が文字列型用に形式が設定されている場合、[日時にキャスト] を選択します。
-
[カットオフ分位] で分位を指定し,シーケンスの長さを設定します。
-
[出力をフラット化] を選択して、時系列の値を別々の列に出力します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列データから特徴を抽出する
時系列データに対して分類または回帰アルゴリズムを実行している場合、アルゴリズムを実行する前に時系列から特徴量を抽出することをお勧めします。特徴を抽出すると、アルゴリズムのパフォーマンスが向上する可能性があります。
次のオプションを使用して、データから特徴を抽出する方法を選択します。
-
[最小サブセット] を使用して、下流の分析で有用であることがわかっている 8 つの特徴の抽出を指定します。計算をすばやく実行する必要がある場合は、最小サブセットを使用できます。ML アルゴリズムが過適合するリスクが高く、より少ない特徴を提供する場合にも使用できます。
-
[効率的なサブセット] を使用して、分析で大量の演算を行う特徴を抽出せずに、可能な限り多くの特徴を抽出するように指定します。
-
[すべての特徴] を使用して、チューニングシリーズから全特徴の抽出を指定します。
-
[手動サブセット] を使用して、データのバリエーションを適切に説明している思われる特徴のリストを選択します。
次の手順を使用して、時系列データから特徴を抽出します。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[特徴を抽出] を選択します。
-
[この列の特徴を抽出] に対する列を選択します。
-
(オプション) [フラット化] を選択して特徴量を別々の列に出力します。
-
[戦略] で、特徴を抽出する戦略を選択します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列データから遅延特徴を使用する
多くのユースケースにおいて、時系列の将来の動作を予測する最良の方法は、最新の動作を使用することです。
遅延特徴の最も一般的な用途は次のとおりです。
-
過去の値を少しだけ収集する。例えば、時間 t + 1 の場合、t、t - 1、t - 2、t - 3 を収集します。
-
データで季節的な動作に対応する値を収集する。例えば、午後 1 時のレストランの利用率を予測するために、前日の午後 1 時の特徴量を使用できます。同じ日の午前 12 時または午前 11 時からの特徴量を使用しても、前日の特徴量を使用した場合ほどには予測できない可能性があります。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[遅延特徴] を選択します。
-
[この列の特徴を生成] に対する列を選択します。
-
[タイムスタンプ列] で、タイムスタンプを含む列を選択します。
-
[遅延] で、遅延の長さを指定します。
-
(オプション) 次のいずれかのオプションを使用して出力を設定します。
-
遅延期間全体を含める
-
出力をフラット化
-
履歴のない行をドロップ
-
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列に日時範囲を作成する
タイムスタンプのない時系列データが含まれている場合があります。観測値が一定の間隔で取得されたことがわかっている場合、個別の列で時系列のタイムスタンプを生成できます。タイムスタンプを生成するには、開始タイムスタンプの値とタイムスタンプの頻度を指定します。
例えば、レストランの顧客数に関する次のような時系列データがあるとします。
レストランの顧客数に関する時系列データ
| 顧客の数 |
|---|
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
レストランが午後 5 時にオープンし、観測値が 1 時間ごとに取得されることがわかっている場合、時系列データに対応するタイムスタンプ列を追加できます。次の表にタイムスタンプの列を示します。
レストランの顧客数に関する時系列データ
| 顧客の数 | Timestamp |
|---|---|
| 10 | 1:00 PM |
| 14 | 2:00 PM |
| 24 | 3:00 PM |
| 40 | 4:00 PM |
| 30 | 5:00 PM |
| 20 | 6:00 PM |
次の手順に従って、データに日時範囲を追加します。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[日時範囲] を選択します。
-
[頻度タイプ] で、タイムスタンプの頻度を測定するために使用する単位を選択します。
-
[開始タイムスタンプ] で、開始タイムスタンプを指定します。
-
[出力列] で、出力列の名前を指定します。
-
(オプション) 残りのフィールドを使用して出力を設定します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列でローリングウィンドウを使用する
一定の期間にわたって特徴を抽出できます。例えば、時間 t、時間枠長 3、t 番目のタイムスタンプを示す行の場合、時系列から抽出される特徴を時間 t - 3、t -2、t - 1 で追加します。特徴の抽出の詳細については、「時系列データから特徴を抽出する」を参照してください。
次の手順に従って、一定の期間にわたって特徴を抽出できます。
-
Data Wrangler のデータフローを開きます。
-
データセットをまだインポートしていない場合は、[Import data] (データをインポート) タブからインポートします。
-
データフローの [Data types] (データ型) で [+] を選択し、[Add transform] (変換を追加) を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[ローリングウィンドウの特徴] を選択します。
-
[この列のローリングウィンドウの特徴を生成] に対する列を選択します。
-
[タイムスタンプ列] で、タイムスタンプを含む列を選択します。
-
(オプション) [出力列] で、出力列の名前を指定します。
-
[ウィンドウサイズ] で、ウィンドウサイズを指定します。
-
[戦略] で、抽出戦略を選択します。
-
[プレビュー] を選択して、変換のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
日時を特徴化
[日付/時刻を特徴化] を使用して、日時フィールドを表すベクトルの埋め込みを作成します。この変換を使用するには、日時データが次のいずれかの形式で指定されている必要があります。
-
"January 1st, 2020, 12:44pm"など、日時を記述する文字列。 -
UNIX タイムスタンプ: UNIX タイムスタンプは、1970 年 1 月 1 日からの秒、ミリ秒、マイクロ秒、ナノ秒の数を表します。
[日時形式を推測] を選択して [日時形式] を指定できます。日時の形式を指定する場合、「Python ドキュメント
-
手動による計算が最速のオプションは、[日時形式] を選択し、[日時形式を推測] に対して [いいえ] を選択することです。
-
[日時形式を推測] を選択し、日時の形式を指定しないことで、手動による作業を削減できます。また、これは計算が早いオペレーションでもあります。ただし、入力列で最初に検出された日時の形式が、列全体の形式と見なされます。列に他の形式がある場合、これらの値は最終出力で NaN になります。日時の形式を推測すると、解析されていない文字列が得られる可能性があります。
-
形式を指定せずに [日時形式を推測] で [いいえ] を選択すると、最も堅牢な結果が得られます。有効な日時文字列がすべて解析されます。ただし、このオペレーションは、このリストの最初の 2 つのオプションよりも大幅に遅くなる可能性があります。
この変換を使用する場合、前述したいずれかの形式の日時データが含まれている [入力列] を指定します。この変換により、[出力列名] という名前の出力列が作成されます。出力列の形式は、次を使用した構成によって異なります。
-
ベクトル: 1 つの列をベクトルとして出力します。
-
列: 特徴ごとに新しい列を作成します。例えば、出力に年、月、日が含まれる場合、年、月、日に対して 3 つの別々の列が作成されます。
また、[埋め込みモード] を選択する必要があります。線形モデルと深層ネットワークの場合、[周期的] が推奨されます。ツリーベースのアルゴリズムでは、[序数] が推奨されます。
文字列の形式を設定する
[文字列の形式を設定] 変換には、標準の文字列形式を設定するオペレーションが含まれます。例えば、これらのオペレーションを使用して、特殊文字の削除、文字列長の正規化、文字列の大文字と小文字の更新を行うことができます。
この特徴グループには、次の変換が含まれます。すべての変換は、[入力列] で文字列のコピーを返し、結果を新しい出力列に追加します。
| 名前 | 関数 |
|---|---|
| 左パディング |
指定された [文字を入力] の文字列を、指定された [幅] に左パディングします。文字列が [幅] より長い場合、戻り値は [幅] の文字まで短縮されます。 |
| 右パディング |
指定された [文字を入力] の文字列を、指定された [幅] に右パディングします。文字列が [幅] より長い場合、戻り値は [幅] の文字まで短縮されます。 |
| 中央 (両側パディング) |
指定された [文字を入力] の文字列を、指定された [幅] に中央パディング (文字列の両側にパディング) します。文字列が [幅] より長い場合、戻り値は [幅] の文字まで短縮されます。 |
| ゼロに付加 |
指定された [幅] まで、数値文字列をゼロで左に入力します。文字列が [幅] より長い場合、戻り値は [幅] の文字まで短縮されます。 |
| 左および右を削除 |
先頭と末尾の文字を削除した文字列のコピーを返します。 |
| 左から文字を削除 |
先頭の文字を削除した文字列のコピーを返します。 |
| 右から文字を削除 |
末尾の文字を削除した文字列のコピーを返します。 |
| 小文字 |
テキスト内のすべての文字を小文字に変換します。 |
| 大文字 |
テキスト内のすべての文字を大文字に変換します。 |
| 大文字にする |
各文の最初の文字を大文字にします。 |
| 大文字と小文字を変換 | 指定した文字列のすべての大文字を小文字に変換し、すべての小文字を大文字に変換して返します。 |
| プレフィックスまたはサフィックスを追加 |
文字列列にプレフィックスとサフィックスを追加します。[プレフィックス] と [サフィックス] を少なくとも 1 つ指定する必要があります。 |
| 記号を削除 |
指定された記号を文字列から削除します。一覧表示された文字はすべて削除されます。デフォルトは空白に設定されます。 |
外れ値を処理する
機械学習モデルは、特徴値のディストリビューションと範囲の影響を受けます。外れ値や、希少値は、モデルの精度に悪影響を及ぼし、トレーニング時間が長くなる可能性があります。この特徴グループを使用して、データセット内の外れ値を検出して更新します。
[外れ値を処理] 変換ステップを定義すると、外れ値の検出に使用される統計が、このステップの定義時に Data Wrangler で使用可能なデータに対して生成されます。Data Wrangler ジョブの実行時に、これらの同じ統計が使用されます。
このグループに含まれる変換の詳細については、次のセクションを参照してください。[出力名] を指定すると、これらの各変換により、結果データを含む出力列が生成されます。
堅牢な標準偏差の数値外れ値
この変換は、外れ値に堅牢な統計を使用して、数値特徴の外れ値を検出して修正します。
[上限分位] と [下限分位] を定義する必要があります。これは外れ値の計算に使われる統計で使用されます。また、値を外れ値と見なすために必要な平均値からの変化として、[標準偏差] の数値を指定する必要があります。例えば、[標準偏差] に 3 を指定した場合、外れ値と見なすには、値が平均値から 3 標準偏差より離れていなければなりません。
[修正方法] は、検出された外れ値の処理に使用する方法です。次から選択できます。
-
[クリップ]: このオプションを使用して、対応する外れ値の検出範囲に外れ値をクリップします。
-
[削除]: このオプションは、外れ値が含まれる行をデータフレームから削除する場合に使用します。
-
[無効化]: このオプションは、外れ値を無効な値に置き換える場合に使用します。
標準偏差の数値外れ値
この変換は、平均値と標準偏差を使用して、数値特徴の外れ値を検出して修正します。
値を外れ値と見なすために平均値から逸脱していなければならない [標準偏差] の数を指定します。例えば、[標準偏差] に 3 を指定した場合、外れ値と見なすには、値が平均値から 3 標準偏差より離れていなければなりません。
[修正方法] は、検出された外れ値の処理に使用する方法です。次から選択できます。
-
[クリップ]: このオプションを使用して、対応する外れ値の検出範囲に外れ値をクリップします。
-
[削除]: このオプションは、外れ値が含まれる行をデータフレームから削除する場合に使用します。
-
[無効化]: このオプションは、外れ値を無効な値に置き換える場合に使用します。
分位数の外れ値
この変換を使用して、分位数を使った数値特徴の外れ値を検出して修正します。[上限分位] と [下位分位] を定義できます。上限分位を上回る値または下位分位を下回る値はすべて外れ値と見なされます。
[修正方法] は、検出された外れ値の処理に使用する方法です。次から選択できます。
-
[クリップ]: このオプションを使用して、対応する外れ値の検出範囲に外れ値をクリップします。
-
[削除]: このオプションは、外れ値が含まれる行をデータフレームから削除する場合に使用します。
-
[無効化]: このオプションは、外れ値を無効な値に置き換える場合に使用します。
最小-最大数値外れ値
この変換は、上限と下限しきい値を使用して、数値特徴の外れ値を検出して修正します。外れ値を定めるしきい値がわかっている場合は、この方法を使用します。
[上限しきい値] と [下限しきい値] を指定していて、値がこれらのしきい値をそれぞれ上回っているか、下回っている場合、外れ値と見なされます。
[修正方法] は、検出された外れ値の処理に使用する方法です。次から選択できます。
-
[クリップ]: このオプションを使用して、対応する外れ値の検出範囲に外れ値をクリップします。
-
[削除]: このオプションは、外れ値が含まれる行をデータフレームから削除する場合に使用します。
-
[無効化]: このオプションは、外れ値を無効な値に置き換える場合に使用します。
希少値を置き換え
[希少値を置き換え] 変換を使用してしきい値を指定すると、Data Wrangler はそのしきい値を満たすすべての値を検出し、指定した文字列に置き換えます。例えば、この変換を使用して、列のすべての外れ値を「その他」カテゴリに分類できます。
-
置換文字列: 外れ値に置き換える文字列。
-
絶対しきい値: インスタンスの数がこの絶対しきい値以下の場合、このカテゴリは希少値です。
-
割合しきい値: インスタンスの数がこの割合しきい値に行数を乗算した値以下次の場合、このカテゴリは希少値です。
-
最大共通カテゴリ: オペレーション後に残る希少ではない最大カテゴリ。しきい値が十分なカテゴリをフィルタリングしない場合、出現数が上位のカテゴリは希少ではないと分類されます。0 (デフォルト) に設定する場合、カテゴリ数に対するハード制限はありません。
欠落した値を処理する
欠落値は機械学習データセットで一般的に発生します。状況によっては、欠落したデータを、平均値やカテゴリで共通の値などの計算値で帰属化することが推奨されます。欠落した値は、[欠落値を処理] 変換グループを使用して処理できます。このグループには、次の変換が含まれます。
欠落値を入力する
[欠落値を入力] 変換を使用して、定義した [入力値] に欠落値を置き換えます。
欠落値を帰属化する
[欠落値を帰属化] 変換を使用して、入力カテゴリと数値データで欠落値が見つかった場所の、帰属化された値を含む新しい列を作成します。設定は、データ型によって異なります。
数値データの場合、帰属化する新しい値を決定するために使用する戦略として、計算戦略を選択します。データセットに存在する値に対して平均値または中央値を帰属化するかを選択できます。Data Wrangler は、計算した値を使用して欠落値を帰属化します。
カテゴリ別データの場合、Data Wrangler は列内で最も頻度の高い値を使用して欠落値を帰属化します。カスタム文字列を帰属化するには、代わりに [欠落値を入力] 変換を使用します。
欠落値のインジケータを追加する
[欠落値のインジケータを追加] 変換を使用して、行に値が含まれている場合は "false"、行に欠落値が含まれている場合は "true" のブール値を含む新しいインジケータ列を作成します。
欠落値をドロップする
[欠落値をドロップ] オプションを使用して、欠落値を含む行を [入力列] からドロップします。
列を管理する
次の変換を使用して、データセットの列をすばやく更新および管理できます。
| 名前 | 関数 |
|---|---|
| 列をドロップ | 列を削除します。 |
| 列を複製 | 列を複製します。 |
| 列名を変更 | 列名を変更します。 |
| 列を移動 |
データセット内の列の位置を移動します。列をデータセットの先頭/末尾、参照列の前/後、または特定のインデックスに移動することを選択します。 |
行を管理する
この変換グループを使用して、行の並べ替えとシャッフルオペレーションをすばやく実行できます。このグループには、次が含まれます。
-
並べ替え: データフレーム全体を特定の列で並べ替えます。このオプションの [昇順] の横にあるチェックボックスをオンにします。それ以外の場合はこのチェックボックスをオフにし、並べ替えに降順を使用します。
-
シャッフル: データセット内のすべての行をランダムにシャッフルします。
ベクトルを管理する
この変換グループを使用して、ベクトル列を結合またはフラット化します。このグループには、次の変換が含まれます。
-
組み合わせ: この変換を使用して、Spark ベクトルと数値データを 1 つの列に結合します。例えば、3 つの列 (数値データを含む 2 つの列とベクトルを含む 1 つの列) を組み合わせることができます。結合するすべての列を [入力列] に追加し、結合したデータの [出力列名] を指定します。
-
フラット化: この変換を使用して、ベクトルデータを含む 1 つの列をフラット化します。入力列には PySpark ベクトル、または配列のようなオブジェクトが含まれている必要があります。[出力数を検出する方法] を指定して作成される列の数を制御できます。例えば、[最初のベクトルの長さ] を選択すると、列で見つかった最初の有効なベクトルまたは配列の要素の数によって、作成される出力列の数が決まります。項目が多すぎる他のすべての入力ベクトルは切り捨てられます。項目が少なすぎる入力には NaN が入力されます。
また、出力列ごとにプレフィックスとして使用される [出力プレフィックス] を指定することもできます。
数値を処理する
[数値を処理] 特徴量グループを使用して数値データを処理できます。このグループの各スカラーは Spark ライブラリを使用して定義されます。以下のスケーラーがサポートされています。
-
標準スケーラー: 各値から平均値を減算し、単位分散にスケーリングして入力列を標準化します。詳細については、Spark のドキュメントの「StandardScaler」を参照してください。
-
堅牢なスケーラー: 外れ値に対して堅牢な統計を使用し、入力列をスケーリングします。詳細については、Spark のドキュメントの「RobustScaler
」を参照してください。 -
最小最大スケーラー: 各特徴量を指定された範囲にスケーリングして、入力列を変換します。詳細については、Spark のドキュメントの「minMaxScaler
」を参照してください。 -
最大絶対スケーラー: 各値を最大絶対値で分割し、入力列をスケーリングします。詳細については、Spark のドキュメントの「maxAbsScaler
」を参照してください。
サンプリング
データをインポートしたら、サンプリングトランスフォーマーを使用して、データの 1 つ以上のサンプルを取得できます。サンプリングトランスフォーマーを使用すると、Data Wrangler は元のデータセットをサンプリングします。
次のいずれかのサンプリング方法を選択できます。
-
上限: 最初の行から指定した上限までデータセットをサンプリングします。
-
ランダム化: 指定したサイズのランダムサンプルを取得します。
-
層別化: 層別化されたランダムなサンプルを取得します。
ランダム化されたサンプルを層別化して、それがデータセットの元の分布を表していることを確認できます。
複数のユースケースに対してデータ準備を行っている場合があります。ユースケースごとに異なるサンプルを採取し、異なる変換セットを適用できます。
以下の手順では、ランダムサンプルを作成するプロセスを説明します。
データからランダムサンプルを取得するには。
-
インポートしたデータセットの右にある [+] を選択します。データセットの名前は [+] の下にあります。
-
[変換を追加] を選択します。
-
[サンプリング] を選択します。
-
[サンプリング方法] では、サンプリング方法を選択します。
-
[おおよそのサンプルサイズ] では、サンプルに含める観測値のおおよその数を選択します。
-
(オプション) 再現性のあるサンプルを作成するには、[ランダムシード] に整数を指定します。
以下の手順では、層別化サンプルを作成するプロセスを説明します。
データから層別化サンプルを取得するには。
-
インポートしたデータセットの右にある [+] を選択します。データセットの名前は [+] の下にあります。
-
[変換を追加] を選択します。
-
[サンプリング] を選択します。
-
[サンプリング方法] では、サンプリング方法を選択します。
-
[おおよそのサンプルサイズ] では、サンプルに含める観測値のおおよその数を選択します。
-
[層別化列] には、層別化する列の名前を指定します。
-
(オプション) 再現性のあるサンプルを作成するには、[ランダムシード] に整数を指定します。
検索および編集
このセクションでは、文字列内の特定のパターンを検索および編集する方法について説明します。例えば、文やドキュメント内の文字列を検索して更新したり、区切り文字で文字列を分割したり、特定の文字列の出現を検索したりできます。
次の変換は、[検索および編集] でサポートされています。すべての変換は、[入力列] で文字列のコピーを返し、結果を新しい出力列に追加します。
| 名前 | 関数 |
|---|---|
|
部分文字列を検索 |
検索した [部分文字列] の最初に出現したインデックスを返します。検索はそれぞれ [開始] で開始して [終了] で終了します。 |
|
部分文字列を右から検索 |
検索した [部分文字列] が最後に見つかった位置のインデックスを返します。検索はそれぞれ [開始] で開始して [終了] で終了します。 |
|
プレフィックスに一致 |
文字列に指定された [パターン] が含まれている場合にブール値を返します。パターンには、文字シーケンスまたは正規表現のいずれかを指定できます。オプションで、パターンの大文字と小文字を区別できます。 |
|
すべての出現を検索 |
指定されたパターンのすべての出現を含む配列を返します。パターンには、文字シーケンスまたは正規表現のいずれかを指定できます。 |
|
正規表現を使用して抽出 |
指定された正規表現パターンに一致する文字列を返します。 |
|
区切り文字間を抽出 |
[左区切り文字] と [右区切り文字] の間に見つかったすべての文字を含む文字列を返します。 |
|
位置から抽出 |
入力文字列の [開始位置] から開始し、開始位置に [長さ] を足した位置までのすべての文字が含まれる文字列を返します。 |
|
部分文字列を検索して置換 |
指定された [パターン] (正規表現) のすべての一致が [置換文字列] で置き換えられた文字列を返します。 |
|
区切り文字を置き換え |
[左区切り記号] の最初の出現と [右の区切り記号] の最後の出現との間に見つかった部分文字列が [置換文字列] に置き換えられた文字列を返します。一致が見つからない場合、何も置き換えられません。 |
|
位置から置き換え |
[開始位置] と [開始位置] に [長さ] を足した位置との間の部分文字列が [置換文字列] に置き換えられた文字列を返します。[Start position] (開始位置) に [length] (長さ) を足すと、置換文字列の長さよりも長くなる場合、出力に … が含まれます。 |
|
正規表現を欠落値に変換 |
文字列が無効な場合は |
|
区切り文字で文字列を分割 |
[区切り記号] で [最大分割数] (オプション) まで分割された入力文字列から文字列の配列を返します。区切り文字のデフォルトは空白です。 |
データの分割
[データの分割] 変換を使用して、データセットを 2 つまたは 3 つのデータセットに分割します。例えば、データセットをモデルのトレーニングに使用するデータセットとテストに使用するデータセットに分割できます。各分割に含まれるデータセットの割合を決定できます。例えば、1 つのデータセットを 2 つのデータセットに分割する場合、トレーニングデータセットには 80% のデータが含まれ、テストデータセットには 20% のデータが含まれるようにできます。
データを 3 つのデータセットに分割すると、トレーニング、検証、テストのデータセットを作成できます。ターゲット列をドロップすると、テストデータセットでのモデルのパフォーマンスを確認できます。
ユースケースによって、各データセットが取得する元のデータセットの量と、データの分割に使用する方法が決まります。例えば、層別化分割を使用して、ターゲット列の観測値の分布がデータセット全体で同じになるようにしたいかもしれません。次の分割変換を使用できます。
-
ランダム分割 – 各分割は、元のデータセットのランダムで重複しないサンプルです。データセットが大きい場合、ランダム分割を使用すると計算コストが高くなり、順序付き分割よりも時間がかかる場合があります。
-
順序付き分割 – 観測値の順序に基づいてデータセットを分割します。例えば、トレーニングテストを 80/20 に分割すると、データセットの 80% を占める最初の観測値がトレーニングデータセットに送られます。観測値の最後の 20% はテストデータセットに送られます。順序付き分割は、分割間でデータの既存の順序を維持するのに効果的です。
-
層別化分割 – データセットを分割して、入力列の観測数が比例表現になるようにします。観測値 1、1、1、1、1、1、2、2、2、2、2、2、2、2、3、3、3、3、3、3、3 を持つ入力列の場合、列を 80/20 に分割すると、1 の約 80%、2 の 80%、3 の 80%がトレーニングセットに送られます。各タイプの観測値の約 20% がテストセットに送られます。
-
キーによる分割 – 同じキーを持つデータが複数回分割されるのを防ぎます。例えば、「customer_id」という列を持つデータセットがあり、それをキーとして使用している場合、顧客 ID が複数分割されることはありません。
データを分割したら、各データセットに追加の変換を適用できます。ほとんどのユースケースでは、これらは必要ありません。
Data Wrangler は分割の比率を計算してパフォーマンスを向上させます。誤差のしきい値を選択して分割の精度を設定できます。誤差のしきい値を低くすると、分割に指定した比率がより正確に反映されます。誤差のしきい値を高く設定すると、パフォーマンスは向上しますが、精度は低下します。
データを完全に分割するには、エラーしきい値を 0 に設定します。パフォーマンスを向上させるために 0 から 1 までのしきい値を指定できます。1 より大きい値を指定した場合、Data Wrangler はその値を 1 と解釈します。
データセットに 10,000 行あり、誤差 0.001 で 80/20 の分割を指定した場合、次の結果のいずれかに近い観測値が得られます。
-
トレーニングセットには 8,010 個の観測値、テストセットには 1,990 個の観測値
-
トレーニングセットには 7,990 個の観測値、テストセットには 2,010 個の観測値
前の例のテストセットの観測値の数は 8,010~7,990 の間です。
デフォルトでは、Data Wrangler はランダムシードを使用して分割を再現できるようにします。シードに別の値を指定して、再現可能な別の分割を作成できます。
値を型として解析
この変換を使用して、列を新しい型にキャストします。サポートされている Data Wrangler のデータ型は次のとおりです。
-
Long
-
浮動小数点数
-
ブール値
-
日付 (日、月、年をそれぞれ表す dd-MM-yyyy 形式)
-
String
文字列を検証する
[文字列を検証] 変換で、テキストデータの行が、指定された条件を満たしていることを示す新しい列を作成します。例えば、[文字列を検証] 変換を使用して、文字列に小文字のみが含まれていることを確認します。次の変換が、[文字列を検証] でサポートされています。
この変換グループには、次の変換が含まれています。変換がブール値を出力する場合、True は 1 で、False は 0 で表されます。
| 名前 | 関数 |
|---|---|
|
文字列の長さ |
文字列の長さが指定された長さに等しい場合、 |
|
Starts with (で始まる) |
文字列が指定されたプレフィックスで始まる場合、 |
|
で終わる |
文字列の長さが指定された長さに等しい場合、 |
|
英数字 |
文字列に数字と文字のみが含まれている場合, |
|
英字 |
文字列に文字のみが含まれている場合、 |
|
数字 |
文字列に数字のみが含まれている場合、 |
|
スペース |
文字列に数字と文字のみが含まれている場合, |
|
タイトル |
文字列に空白が含まれている場合、 |
|
小文字 |
文字列に小文字のみが含まれている場合、 |
|
大文字 |
文字列に大文字のみが含まれている場合、 |
|
数値 |
文字列に数値のみが含まれている場合, |
|
小数 |
文字列に小数のみが含まれている場合, |
JSON データのネスト解除
.csv ファイルがある場合、データセットに JSON 文字列の値が含まれている可能性があります。同様に、Parquet ファイルまたは JSON ドキュメントの列にネストされたデータがある場合があります。
構造化されたフラット化演算子を使用して、最初のレベルのキーを別々の列に分割します。第 1 レベルのキーは、値内にネストされていないキーです。
例えば、データセットに JSON 文字列として保存された各人物のデモグラフィック情報含む人列を持つデータセットがあるとします。JSON 文字列は次のようになります。
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
構造化されたフラット化演算子は、次の第 1 レベルのキーをデータセット内の追加の列に変換します。
-
seq
-
名前
-
age
-
city
-
state
Data Wrangler はキーの値を列の下の値として配置します。次に、JSON の列名と値を示します。
seq, name, age, city, state 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
JSON を含むデータセット内の各値について、構造化されたフラット化演算子は、第 1 レベルのキーの列を作成します。ネストされたキーの列を作成するには、演算子を再度呼び出します。前述の例では、演算子を呼び出すと列が作成されます。
-
name_first
-
name_last
次の例は、オペレーションを再度呼び出した結果のデータセットを示しています。
seq, name, age, city, state, name_first, name_last 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
[フラット化するキー] を選択して、個別の列として抽出する第 1 レベルのキーを指定します。キーを指定しない場合、Data Wrangler はデフォルトですべてのキーを抽出します。
配列の分解
[配列の分解] を使用して、配列の値を個別の出力行に展開します。例えば、このオペレーションでは、配列 [[1, 2, 3,], [4, 5, 6], [7, 8, 9]] の各値を取得し、次の行を含む新しい列を作成できます。
[1, 2, 3] [4, 5, 6] [7, 8, 9]
Data Wrangler は、新しい列に input_column_name_flatten という名前を付けます。
[配列の分解] オペレーションを複数回呼び出して、配列のネストされた値を個別の出力列に取得できます。次の例は、ネストされた配列を持つデータセットに対してオペレーションを複数回呼び出した結果を示しています。
ネストされた配列の値を別の列に配置する
| id | 配列 | id | array_items | id | array_items_items |
|---|---|---|---|---|---|
| 1 | [[猫、犬]、[コウモリ、カエル]] | 1 | [猫、犬] | 1 | cat |
| 2 |
[[バラ、ペチュニア]、[ユリ、デイジー]] |
1 | [コウモリ、カエル] | 1 | 犬 |
| 2 | [バラ、ペチュニア] | 1 | bat | ||
| 2 | [ユリ、デイジー] | 1 | カエル | ||
| 2 | 2 | バラ | |||
| 2 | 2 | ペチュニア | |||
| 2 | 2 | ユリ | |||
| 2 | 2 | デイジー |
画像データを変換する
Data Wrangler を使用して、機械学習 (ML) パイプラインに使用している画像をインポートして変換します。画像データを準備したら、それを Data Wrangler フローから ML パイプラインにエクスポートできます。
ここに記載されている情報を使用して、Data Wrangler での画像データのインポートと変換に慣れることができます。Data Wrangler は OpenCV を使用して画像をインポートします。サポートされている画像形式について詳しくは、「Image file reading and writing
画像データの変換の概念を理解したら、次のチュートリアル「Amazon SageMaker Data Wrangler によるイメージデータの準備
次の業界とユースケースは、変換された画像データへの機械学習の適用が役立つ例です。
-
製造 – 組立ラインからの品目の欠陥の特定
-
食品 – 痛んだ食品や腐った食品の識別
-
医学 – 組織内の病変の特定
Data Wrangler で画像データを操作する場合、次のプロセスを実行します。
-
インポート – Amazon S3 バケット内の画像が含まれるディレクトリを選択して、画像を選択します。
-
変換 – 組み込みの変換を使用して、機械学習パイプライン用の画像を準備します。
-
エクスポート – 変換した画像を、パイプラインからアクセスできる場所にエクスポートします。
次の手順に従って、画像データをインポートします。
画像データをインポートするには
-
[接続の作成] ページに移動します。
-
[Amazon S3] を選択します。
-
画像データを含む Amazon S3 ファイルのパスを指定します。
-
[ファイルタイプ] で [画像] を選択します。
-
(オプション) 複数の Amazon S3 パスから画像をインポートするには、[ネストされたディレクトリをインポート] を選択します。
-
[インポート] を選択します。
Data Wrangler は、組み込みの画像変換にオープンソースの imgaug
-
[ResizeImage]
-
[EnhanceImage]
-
[CorruptImage]
-
[SplitImage]
-
[DropCorruptedImages]
-
[DropImageDuplicates]
-
[Brightness]
-
[ColorChannels]
-
[Grayscale]
-
[Rotate]
コードを記述せずに画像を変換するには、以下の手順を使用します。
コードを書かずに画像データを変換するには
-
Data Wrangler フローから、インポートした画像を表すノードの横にある [+] を選択します。
-
[変換を追加] を選択します。
-
[Add step] (ステップを追加) を選択します。
-
変換を選択して設定します。
-
[プレビュー] を選択します。
-
[Add] (追加) を選択します。
Data Wrangler が提供する変換を使用するだけでなく、独自のカスタムコードスニペットを使用することもできます。カスタムコードスニペットの使用の詳細については、「カスタム変換」を参照してください。OpenCV ライブラリと imgaug ライブラリをコードスニペットにインポートすれば、それらに関連する変換を使用できます。以下は、画像内のエッジを検出するコードスニペットの例です。
# A table with your image data is stored in the `df` variable import cv2 import numpy as np from pyspark.sql.functions import column from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator @BasicImageOperationDecorator def my_transform(image: np.ndarray) -> np.ndarray: # To use the code snippet on your image data, modify the following lines within the function HYST_THRLD_1, HYST_THRLD_2 = 100, 200 edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2) return edges @PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE) def custom_image_udf(image_row): return my_transform(image_row) df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
Data Wrangler フローで変換を適用すると、Data Wrangler はデータセット内の画像のサンプルにのみ変換を適用します。アプリケーションの操作性を最適化するため、Data Wrangler は変換をすべての画像に適用するわけではありません。
すべての画像に変換を適用するには、Data Wrangler フローを Amazon S3 の場所にエクスポートします。エクスポートした画像は、トレーニング パイプラインまたは推論パイプラインで使用できます。データをエクスポートするには、デスティネーションノードまたは Jupyter Notebook を使用します。Data Wrangler フローからデータをエクスポートする場合、どちらの方法でもアクセスできます。これらの方法の使用については、「Amazon S3 へのエクスポート」を参照してください。
データのフィルタリング
Data Wrangler を使用して列内のデータをフィルターします。列内のデータをフィルターするときは、次のフィールドを指定します。
-
列名 – データのフィルターに使用する列の名前。
-
条件 – 列の値に適用するフィルターのタイプ。
-
値 – フィルターを適用する列の値またはカテゴリ。
以下でフィルターできます。
-
= – 指定した値またはカテゴリと一致する値を返します。
-
!= – 指定した値またはカテゴリと一致しない値を返します。
-
>= – Long または Float データの場合、指定した値以上の値をフィルターします。
-
=> – Long または Float データの場合、指定した値以下の値をフィルターします。
-
> – Long または Float データの場合、指定した値より大きい値をフィルターします。
-
< – Long または Float データの場合、指定した値より小さい値をフィルターします。
カテゴリ male および female を含む列の場合は、male の値をすべて除外できます。また、すべての female の値をフィルターすることもできます。列には male と female の値しかないため、フィルターは female の値のみを含む列を返します。
複数のフィルターを追加することもできます。フィルターは複数の列または同じ列に適用できます。例えば、特定の範囲内の値のみを含む列を作成する場合は、2 つの異なるフィルターを追加します。1 つのフィルターでは、列には指定した値より大きい値が必要であることを指定します。もう 1 つのフィルターでは、列には指定した値より小さい値が必要であることを指定します。
次の手順を使用して、フィルター変換をデータに追加します。
データをフィルターするには
-
Data Wrangler フローから、フィルタリングするデータを含むノードの横にある [+] を選択します。
-
[変換を追加] を選択します。
-
[Add step] (ステップを追加) を選択します。
-
[データをフィルターする] を選択します。
-
以下のフィールドを指定します。
-
列名 – フィルターする列。
-
条件 – フィルターの条件。
-
値 – フィルターを適用する列の値またはカテゴリ。
-
-
(オプション) 作成したフィルターの後の [+] を選択します。
-
フィルターを設定します。
-
[プレビュー] を選択します。
-
[Add] (追加) を選択します。
Amazon Personalize のマップ列
Data Wrangler は、アイテムの推奨事項とユーザーセグメントを生成する完全マネージド型の機械学習サービスである Amazon Personalize と統合されています。Amazon Personalize のマップ列変換を使用すると、データを Amazon Personalize が解釈できる形式に変換できます。Amazon Personalize に固有の変換の詳細については、「Importing data using Amazon SageMaker Data Wrangler」を参照してください。Amazon Personalize の詳細については、「What is Amazon Personalize?」を参照してください。
