翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
[Export] (エクスポート)
Data Wrangler フローでは、データ処理パイプラインに加えた変換の一部またはすべてをエクスポートできます。
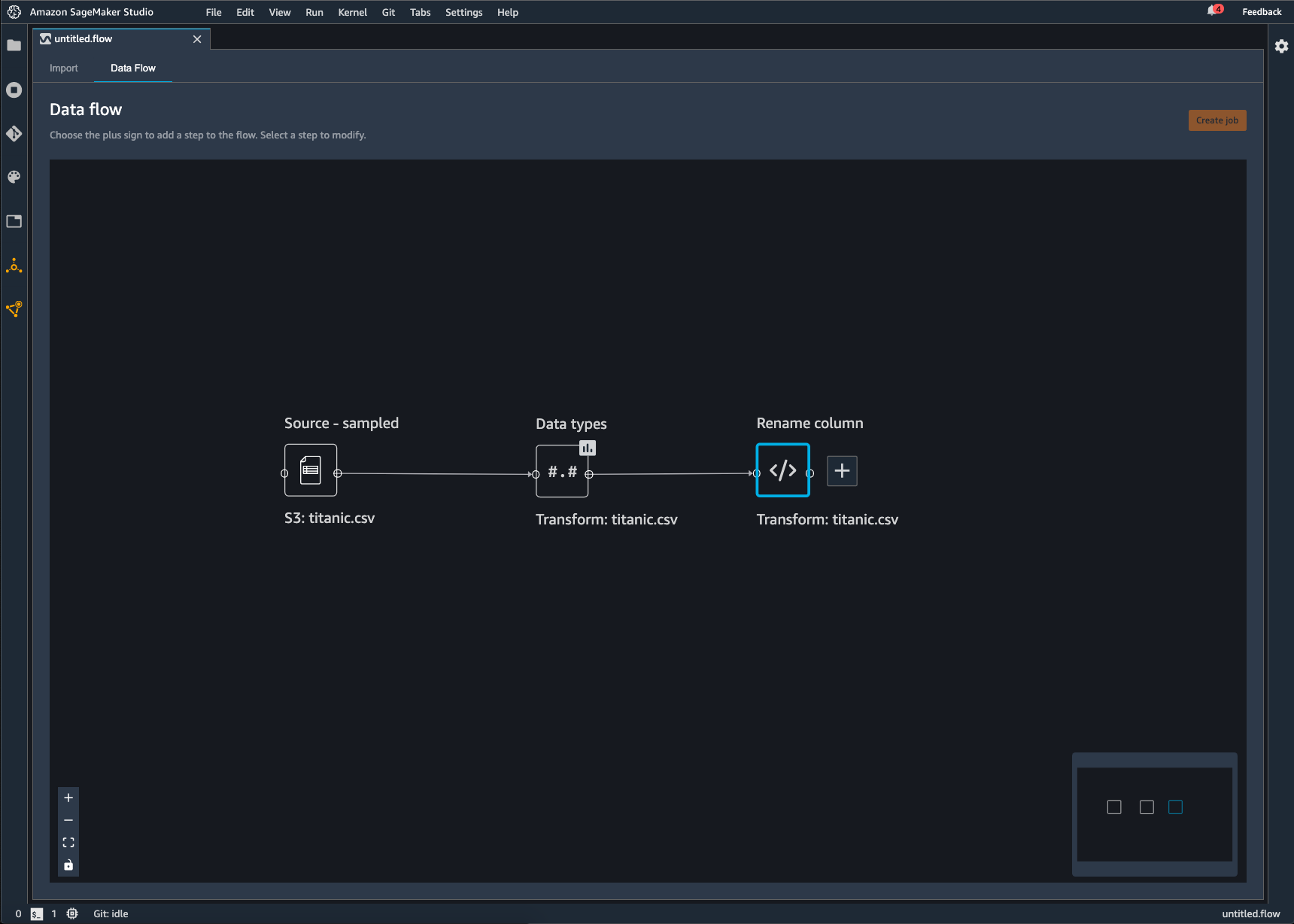
Data Wrangler フローは、データに対して実行した一連のデータ準備手順です。データの準備では、データに対して 1 つ以上の変換を実行します。各変換は、変換ステップを使用して行われます。フローには、データのインポートと実行した変換を表す一連のノードがあります。例については、以下のイメージを参照してください。

上の図は、2 つのノードを持つデータラングラーフローを示しています。ソース – サンプリングノードはデータのインポート元のデータソースです。データ型ノードは、Data Wrangler がデータセットを使用可能な形式に変換するための変換を実行したことを示します。
Data Wrangler フローに追加する各変換は、追加のノードとして表示されます。追加できるその他の変換の詳細については、「データを変換する」を参照してください。次の図は、データセット内の列の名前を変更するための Rename-column ノードを持つ Data Wrangler フローを示しています。
データ変換を次にエクスポートできます。
-
Amazon S3
-
パイプライン
-
Amazon SageMaker Feature Store
-
Python コード
重要
IAM AmazonSageMakerFullAccess 管理ポリシーを使用して を付与することをお勧めします。 AWS Data Wrangler を使用するための アクセス許可。管理ポリシーを使用しない場合は、Data Wrangler に Amazon S3 バケットへのアクセスを許可する IAMポリシーを使用できます。管理ポリシーの詳細については、「セキュリティと権限」を参照してください。
データフローをエクスポートすると、 AWS 使用する リソース。コスト配分タグを使用して、これらのリソースのコストを整理および管理できます。ユーザープロファイル用にこれらのタグを作成すると、Data Wrangler はデータフローのエクスポートに使用されるリソースにタグを自動的に適用します。詳細については、「コスト配分タグの使用」を参照してください。
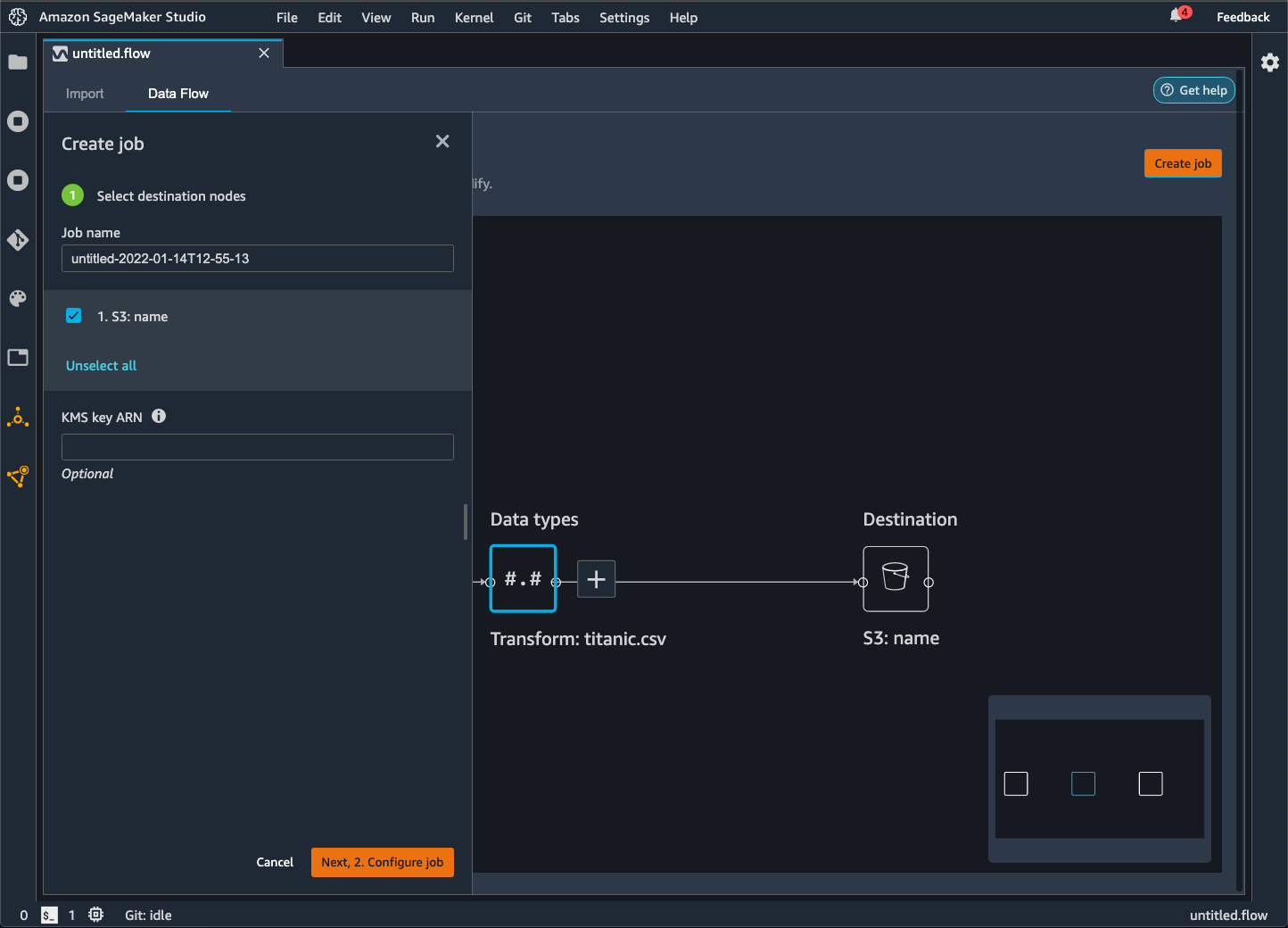
Amazon S3 へのエクスポート
Data Wrangler を使用すると、Amazon S3 バケット内の場所にデータをエクスポートできます。次の方法のいずれかを使用して、場所を指定できます。
-
宛先ノード – Data Wrangler がデータを処理した後にデータを保存する場所。
-
エクスポート先 – 変換の結果データを Amazon S3 にエクスポートします。
-
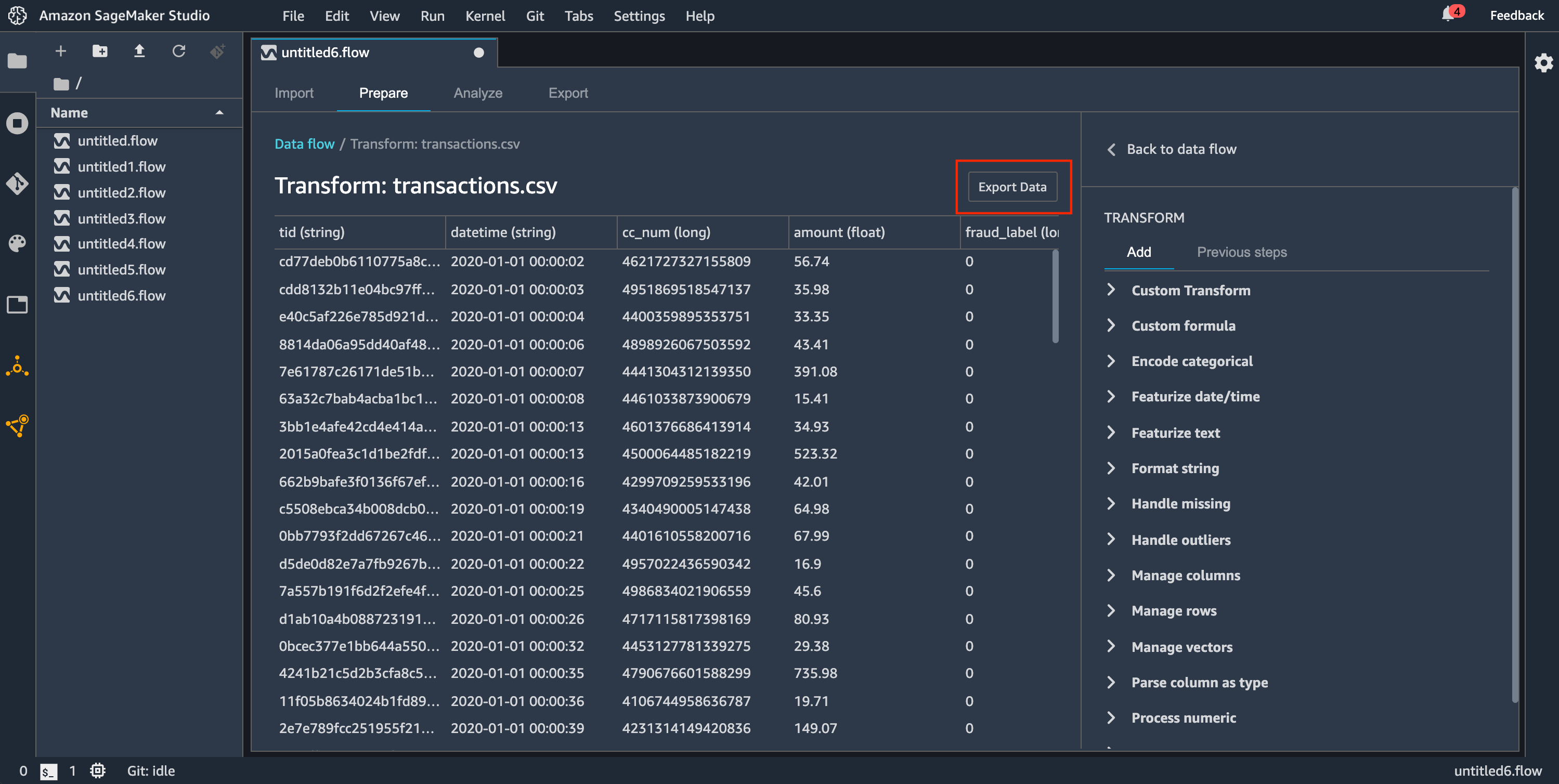
エクスポートデータ – 小さなデータセットの場合、変換したデータをすばやくエクスポートできます。
これらの各方法の詳細については、次のセクションを参照してください。


データフローを Amazon S3 バケットにエクスポートすると、Data Wrangler はフローファイルのコピーを S3 バケットに保存します。フローファイルには data_wrangler_flows プレフィックスが使われます。デフォルトの Amazon S3 バケットを使用してフローファイルを保存する場合、sagemaker- という命名規則が使用されます。例えば、アカウント番号が 111122223333 で、us-east-1 で Studio Classic を使用している場合、インポートされたデータセットは に保存されますregion-account
numbersagemaker-us-east-1-111122223333。この例では、us-east-1 で作成された .flow ファイルは s3://sagemaker- に保存されます。region-account
number/data_wrangler_flows/
パイプラインへのエクスポート
大規模な機械学習 (ML) ワークフローを構築してデプロイする場合は、Pipelines を使用して SageMaker ジョブを管理およびデプロイするワークフローを作成できます。Pipelines を使用すると、 SageMaker データ準備、モデルトレーニング、モデルデプロイジョブを管理するワークフローを構築できます。Pipelines を使用すると、 SageMaker が提供するファーストパーティーアルゴリズムを使用できます。パイプラインの詳細については、SageMaker 「パイプライン」を参照してください。
データフローからパイプラインに 1 つ以上のステップをエクスポートすると、Data Wrangler はパイプラインの定義、インスタンス化、実行、管理に使用できる Jupyter Notebook を作成します。
Jupyter Notebook を使用してパイプラインを作成する
次の手順を使用して Jupyter Notebook を作成し、Data Wrangler フローを Pipelines にエクスポートします。
次の手順を使用して Jupyter Notebook を生成し、それを実行して Data Wrangler フローを Pipelines にエクスポートします。
-
エクスポートするノードの横にある [+] を選択します。
-
[エクスポート先] を選択します。
-
パイプライン (Jupyter Notebook 経由) を選択します。
-
Jupyter Notebook を実行します。

Data Wrangler が生成する Jupyter Notebook を使用して、パイプラインを定義できます。パイプラインには、Data Wrangler フローで定義されるデータ処理ステップが含まれています。
ノートブックの次のコードで steps リストにステップを追加すると、パイプラインにステップを追加できます。
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
パイプラインの定義の詳細については、「パイプラインの定義 SageMaker」を参照してください。
推論エンドポイントへのエクスポート
Data Wrangler フローから SageMaker シリアル推論パイプラインを作成して、Data Wrangler フローを使用して推論時にデータを処理します。推論パイプラインは、トレーニングを受けたモデルに新しいデータを予測させる一連のステップです。Data Wrangler 内のシリアル推論パイプラインが Raw データを変換し、機械学習モデルに提供して予測を行います。Studio Classic 内の Jupyter Notebook から推論パイプラインを作成、実行、管理します。ノートブックへのアクセスの詳細については、「Jupyter Notebook を使用して推論エンドポイントを作成する」を参照してください。
ノートブック内では、機械学習モデルをトレーニングすることも、既にトレーニングしたモデルを指定することもできます。Amazon SageMaker Autopilot または を使用してXGBoost、Data Wrangler フローで変換したデータを使用してモデルをトレーニングできます。
パイプラインでは、バッチ推論またはリアルタイム推論のいずれかを実行できます。Data Wrangler フローを SageMaker Model Registry に追加することもできます。モデルのホスティングの詳細については、「1 つのエンドポイントの背後にある 1 つのコンテナで複数のモデルをホストする」を参照してください。
重要
Data Wrangler フローに以下の変換がある場合、推論エンドポイントにエクスポートすることはできません。
-
Join
-
連結
-
グループ化
データを準備するために前述の変換を使用する必要がある場合は、次の手順を使用します。
サポートされていない変換による推論に備えてデータを準備するには
-
Data Wrangler フローを作成します。
-
サポートされていない前述の変換を適用します。
-
データを Amazon S3 バケットにエクスポートします。
-
別の Data Wrangler フローを作成します。
-
前のフローからエクスポートしたデータをインポートします。
-
残りの変換を適用します。
-
当社が提供する Jupyter Notebook を使用してシリアル推論パイプラインを作成します。
データを Amazon S3 バケットにエクスポートする方法については、「Amazon S3 へのエクスポート」を参照してください。シリアル推論パイプラインの作成に使用した Jupyter Notebook を開く方法については、「Jupyter Notebook を使用して推論エンドポイントを作成する」を参照してください。
Data Wrangler は、推論時にデータを削除する変換を無視します。例えば、Data Wrangler は [欠落をドロップ] 設定を使用すると 欠落した値を処理する 変換を無視します。
データセット全体に変換を再適用した場合、その変換は推論パイプラインに引き継がれます。例えば、中央値を使用して欠損値を代入した場合、変換を再適用した中央値が推論リクエストに適用されます。Jupyter Notebook を使用している場合、または推論パイプラインにデータをエクスポートしている場合、Data Wrangler フローから変換を再適用できます。変換の再適用の詳細については、「変換をデータセット全体に再適用してエクスポートする」を参照してください。
シリアル推論パイプラインは、入力文字列と出力文字列として次のデータ型をサポートします。各データ型には一連の要件があります。
サポートされるデータ型
-
text/csv– CSV文字列のデータ型-
文字列にヘッダーを含めることはできません。
-
推論パイプラインに使用される特徴量は、トレーニングデータセット内の特徴量と同じ順序でなければなりません。
-
特徴量間にはカンマ区切り文字が必要です。
-
レコードは改行文字で区切る必要があります。
以下は、推論リクエストで指定できる有効な形式のCSV文字列の例です。
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json– JSON文字列のデータ型-
推論パイプラインのデータセットで使用される特徴量は、トレーニングデータセット内の特徴量と同じ順序でなければなりません。
-
データには特定のスキーマが必要です。スキーマは、一連の
featuresを含む単一のinstancesオブジェクトとして定義します。各featuresオブジェクトは観測値を表します。
以下は、推論リクエストで指定できる有効な形式のJSON文字列の例です。
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
Jupyter Notebook を使用して推論エンドポイントを作成する
次の手順を使用して Data Wrangler フローをエクスポートし、推論パイプラインを作成します。
Jupyter Notebook を使用して推論パイプラインを作成するには、以下を実行します。
-
エクスポートするノードの横にある [+] を選択します。
-
[エクスポート先] を選択します。
-
SageMaker 推論パイプライン (Jupyter Notebook 経由) を選択します。
-
Jupyter Notebook を実行します。
Jupyter Notebook を実行すると、推論フローアーティファクトが作成されます。推論フローアーティファクトは、シリアル推論パイプラインの作成に使用されるメタデータが追加された Data Wrangler フローファイルです。エクスポートするノードには、先行ノードのすべての変換が含まれます。
重要
Data Wrangler は、推論パイプラインを実行するために推論フローアーティファクトを必要とします。独自のフローファイルをアーティファクトとして使用することはできません。前述の手順を使用して作成する必要があります。
Python コードにエクスポートする
データフローのすべてのステップを、任意のデータ処理ワークフローに手動で統合できる Python ファイルにエクスポートするには、次の手順を使用します。
次の手順を使用して Jupyter Notebook を生成し、それを実行して Data Wrangler フローを Python コードにエクスポートします。
-
エクスポートするノードの横にある [+] を選択します。
-
[エクスポート先] を選択します。
-
[Python コード] を選択します。
-
Jupyter Notebook を実行します。
Python スクリプトをパイプラインで実行するように設定する必要がある場合があります。例えば、Spark 環境を実行している場合は、 へのアクセス許可を持つ環境からスクリプトを実行している必要があります。 AWS リソースの使用料金を見積もることができます。
Amazon SageMaker Feature Store へのエクスポート
Data Wrangler を使用して、作成した機能を Amazon SageMaker Feature Store にエクスポートできます。特徴量はデータセットの列です。特徴量ストアは、特徴量とそれに関連するメタデータの一元的なストアです。特徴量ストアを使用すれば、機械学習 (ML) 開発用の厳選されたデータを作成、共有、管理できます。一元化されたストアにより、データをより見つけやすく、再利用しやすくなります。Feature Store の詳細については、「Amazon SageMaker Feature Store」を参照してください。
特徴量ストアの中核となる概念は特徴量グループです。特徴量グループは、特徴量、そのレコード (観測値)、および関連するメタデータの集まりです。これはデータベースのテーブルに似ています。
Data Wrangler を使用して、次のいずれかを実行できます。
-
既存の特徴量グループを新しいレコードで更新します。レコードはデータセット内の観測値です。
-
Data Wrangler フロー内のノードから新しい特徴量グループを作成します。Data Wrangler は、データセットの観測データを特徴量グループのレコードとして追加します。
既存の特徴量グループを更新する場合は、データセットのスキーマが特徴量グループのスキーマと一致する必要があります。特徴量グループのすべてのレコードは、データセットの観測値に置き換えられます。
Jupyter Notebook または宛先ノードのいずれかを使用して、データセット内の観測データで特徴量グループを更新できます。
Iceberg テーブル形式の特徴量グループにカスタムオフラインストア暗号化キーがある場合は、Amazon SageMaker Processing IAM ジョブで使用している に、それを使用するためのアクセス許可を付与してください。少なくとも、Amazon S3 に書き込むデータを暗号化するアクセス許可を付与する必要があります。アクセス許可を付与するには、IAMロールに を使用する機能を付与しますGenerateDataKey。を使用するアクセス許可をIAMロールに付与する方法の詳細については、「」を参照してください。 AWS KMS キーについては、https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html「��

ノートブックはこれらの設定を使用して特徴グループを作成し、データを大規模に処理して、処理されたデータをオンラインおよびオフラインの Feature Store に取り込みます。詳細については、「データソースと取り込み」を参照してください。
変換をデータセット全体に再適用してエクスポートする
データをインポートすると、Data Wrangler はデータのサンプルを使用してエンコーディングを適用します。デフォルトでは、Data Wrangler は最初の 50,000 行をサンプルとして使用しますが、データセット全体をインポートすることも、別のサンプリング方法を使用することもできます。詳細については、「[Import](インポート)」を参照してください。
次の変換では、データを使用してデータセットに列を作成します。
サンプリングを使用してデータをインポートした場合、前述の変換ではサンプルのデータのみを使用して列を作成します。この変換では、関連するデータがすべて使用されていない可能性があります。例えば、[カテゴリ別にエンコードする] 変換を使用する場合、データセット全体に、サンプルには存在しなかったカテゴリがあった可能性があります。
宛先ノードまたは Jupyter Notebook を使用して、変換をデータセット全体に再適用できます。Data Wrangler がフロー内の変換をエクスポートすると、 SageMaker 処理ジョブが作成されます。処理ジョブが完了すると、Data Wrangler は次のファイルをデフォルトの Amazon S3 の場所または指定した S3 の場所のいずれかに保存します。
-
データセットに再適用する変換を指定する Data Wrangler フローファイル
-
再適用変換が適用されたデータセット
Data Wrangler 内で Data Wrangler フローファイルを開き、その変換を別のデータセットに適用できます。例えば、トレーニングデータセットに変換を適用した場合、Data Wrangler フローファイルを開いて使用すると、推論に使用されるデータセットに変換を適用できます。
宛先ノードを使用して変換を再適用してエクスポートする方法については、以下のページを参照してください。
以下の手順に従って、Jupyter Notebook を実行して変換を再適用し、データをエクスポートします。
Jupyter Notebook を実行し、変換を再適用して Data Wrangler フローをエクスポートするには、以下の手順に従います。
-
エクスポートするノードの横にある [+] を選択します。
-
[エクスポート先] を選択します。
-
データをエクスポートする場所を選択します。
-
refit_trained_paramsオブジェクトの場合、refitをTrueに設定します。 -
output_flowフィールドには、再適用変換を含む出力フローファイルの名前を指定します。 -
Jupyter Notebook を実行します。
新しいデータを自動的に処理するスケジュールを作成する
データを定期的に処理する場合は、処理ジョブを自動的に実行するスケジュールを作成できます。例えば、新しいデータを取得したときに処理ジョブを自動的に実行するスケジュールを作成できます。ジョブの処理の詳細については、「Amazon S3 へのエクスポート」および「Amazon SageMaker Feature Store へのエクスポート」を参照してください。
ジョブを作成するときは、ジョブを作成するアクセス許可を持つ IAMロールを指定する必要があります。デフォルトでは、Data Wrangler へのアクセスに使用するIAMロールは ですSageMakerExecutionRole。
次のアクセス許可により、Data Wrangler は にアクセスして処理ジョブを実行 EventBridge EventBridge できるようになります。
-
以下を追加する AWS Data Wrangler に を使用するアクセス許可を付与する Amazon SageMaker Studio Classic 実行ロールへの管理ポリシー EventBridge:
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccessポリシーの詳細については、「」を参照してください。 AWS の マネージドポリシー EventBridge。
-
Data Wrangler でジョブを作成するときに指定するIAMロールに次のポリシーを追加します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sagemaker:StartPipelineExecution", "Resource": "arn:aws:sagemaker:Region:AWS-account-id:pipeline/data-wrangler-*" } ] }デフォルトIAMロールを使用している場合は、前述のポリシーを Amazon SageMaker Studio Classic 実行ロールに追加します。
次の信頼ポリシーをロールに追加して、 が EventBridge 引き受けることを許可します。
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
重要
スケジュールを作成すると、Data Wrangler は eventRuleに を作成します EventBridge。作成したイベントルールと、処理ジョブの実行に使用したインスタンスの両方に料金が発生します。
EventBridge 料金の詳細については、「Amazon の EventBridge 料金
次のいずれかの方法を使用して、ジョブのスケジュールを設定できます。
以下のセクションでは、ジョブの作成手順について説明します。
Amazon SageMaker Studio Classic を使用して、実行がスケジュールされているジョブを表示できます。処理ジョブはパイプライン内で実行されます。処理ジョブにはそれぞれ独自のパイプラインがあります。これはパイプライン内の処理ステップとして実行されます。パイプライン内で作成したスケジュールを表示できます。パイプラインの表示の詳細については、「パイプラインの表示」を参照してください。
スケジュールしたジョブを表示するには、次の手順を使用します。
スケジュールしたジョブを表示するには、以下を実行します。
-
Amazon SageMaker Studio Classic を開きます。
-
オープンパイプライン
-
作成したジョブのパイプラインを表示します。
ジョブを実行するパイプラインは、ジョブ名をプレフィックスとして使用します。例えば、
housing-data-feature-enginneringという名前のジョブを作成した場合、パイプラインの名前はdata-wrangler-housing-data-feature-engineeringです。 -
ジョブを含むパイプラインを選択します。
-
パイプラインのステータスを表示します。[ステータス] が [成功] のパイプラインは、処理ジョブを正常に実行しています。
処理ジョブの実行を停止するには、以下を実行します。
処理ジョブの実行を停止するには、スケジュールを指定するイベントルールを削除します。イベントルールを削除すると、そのスケジュールに関連するすべてのジョブの実行が停止します。ルールの削除については、「Amazon EventBridge ルールの無効化または削除」を参照してください。
スケジュールに関連付けられているパイプラインを停止したり削除したりすることもできます。パイプラインの停止については、「」を参照してくださいStopPipelineExecution。パイプラインの削除については、「」を参照してくださいDeletePipeline。
