翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データセットを準備する
このステップでは、SHAP (SHapley Additive exPlanations) ライブラリを使用して、ノートブックインスタンスに成人国勢調査データセット
次のサンプルを実行するには、サンプルコードをノートブックインスタンスのセルに貼り付けます。
SHAP を使用して成人国勢調査データセットを読み込む
次の手順を実行し、SHAP ライブラリを使用して成人国勢調査データセットをインポートします。
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
注記
最新の Jupyter カーネルに SHAP ライブラリがない場合は、次の conda コマンドを実行してライブラリをインストールします。
%conda install -c conda-forge shap
JupyterLab を使用する場合は、インストールと更新の完了後にカーネルを手動で更新する必要があります。次の IPython スクリプトを実行して、カーネルをシャットダウンします (カーネルは自動的に再起動します)。
import IPython IPython.Application.instance().kernel.do_shutdown(True)
feature_names リストオブジェクトにより、次のような機能のリストが返されます。
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
ヒント
ラベルのないデータから始める場合は、Amazon SageMaker Ground Truth を使用することによって、数分でデータラベリングワークフローを作成できます。詳細については、「データをラベル付けする」を参照してください。
データセットの概要
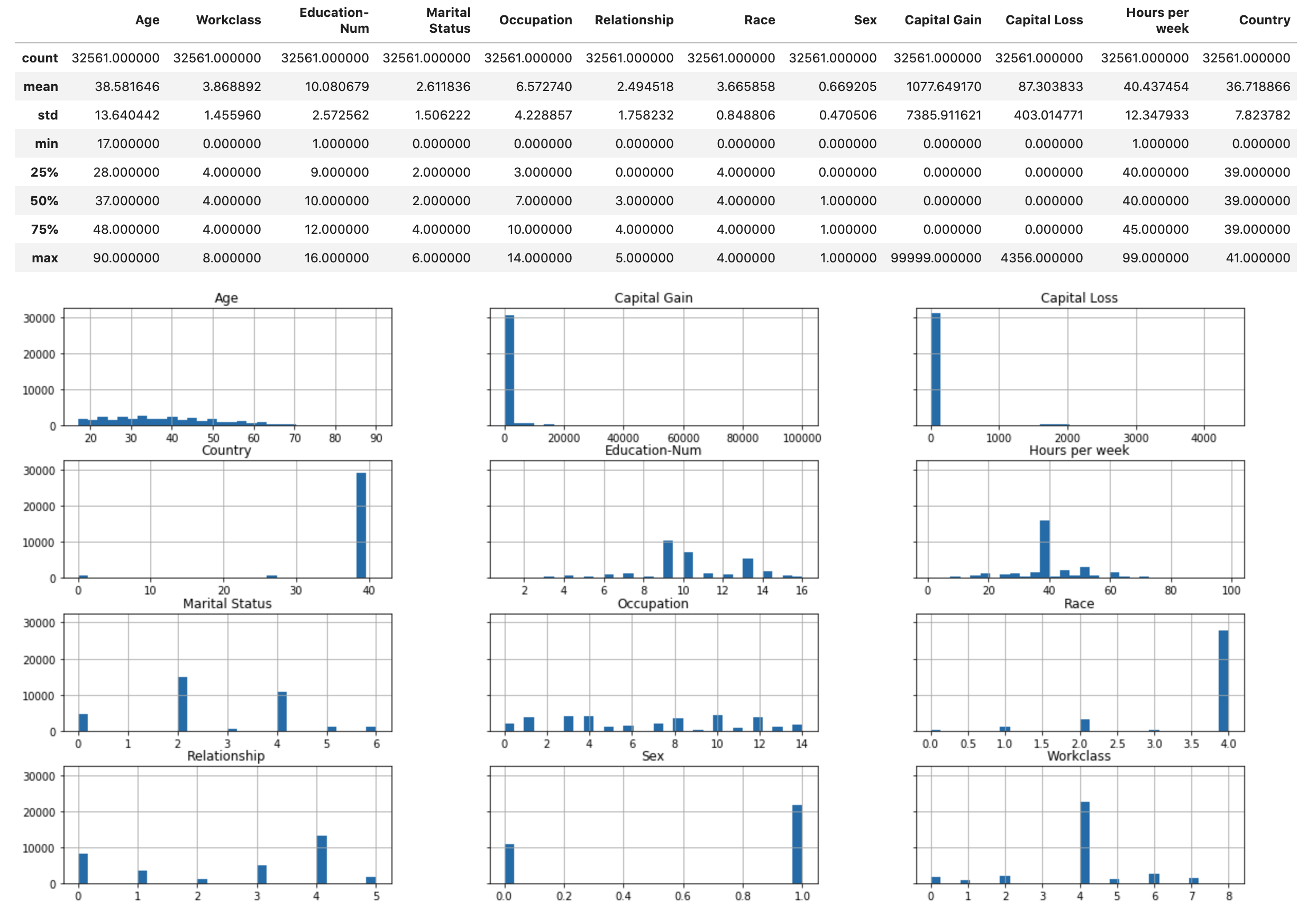
次のスクリプトを実行すると、データセットの統計概要と数値特徴のヒストグラムが表示されます。
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
ヒント
クリーンアップと変換が必要なデータセットを使用する場合は、Amazon SageMaker Data Wrangler を使用することによって、データの前処理と特徴量エンジニアリングを簡素化および合理化できます。詳細については、「Prepare ML Data with Amazon SageMaker Data Wrangler」を参照してください。
データセットをトレーニング、検証、テストデータセットに分割する
Sklearn を使用して、データセットをトレーニングセットとテストセットに分割します。トレーニングセットはモデルのトレーニングに使用し、テストセットは最終的なトレーニング済みモデルのパフォーマンスを評価するために使用します。データセットは、固定ランダムシード (データセットの 80% がトレーニングセット、20% がテストセット) でランダムにソートされます。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
トレーニングセットを分割して、検証セットを分離します。検証セットは、トレーニング済みモデルのパフォーマンスを評価するとともに、モデルのハイパーパラメータを調整するために使用します。トレーニングセットの 75% が最終的なトレーニングセットになり、残りは検証セットになります。
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
pandas パッケージを使用して、数値特徴と実際のラベルを連結し、各データセットを明示的に整列させます。
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
データセットが以下のように期待どおりに分割され、構成されているかどうかを確認します。
train
validation
test
トレーニングデータセットと検証データセットを CSV ファイルに変換する
train と validation のデータフレームオブジェクトを CSV ファイルに変換し、XGBoost アルゴリズムの入力ファイル形式に合わせます。
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
データセットを Amazon S3 にアップロードする
SageMaker AI と Boto3 を使用して、トレーニングデータセットと検証データセットをデフォルトの Amazon S3 バケットにアップロードします。S3 バケット内のデータセットは、Amazon EC2 のコンピューティングに最適化された SageMaker インスタンスによってトレーニングに使用されます。
次のコードは、現在の SageMaker AI セッションのデフォルトの S3 バケット URI を設定し、新しいdemo-sagemaker-xgboost-adult-income-predictionフォルダを作成し、トレーニングデータセットと検証データセットをdataサブフォルダにアップロードします。 SageMaker
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
以下を実行して AWS CLI 、CSV ファイルが S3 バケットに正常にアップロードされたかどうかを確認します。
! aws s3 ls {bucket}/{prefix}/data --recursive
以下のような出力が返されます。

