翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルを微調整する
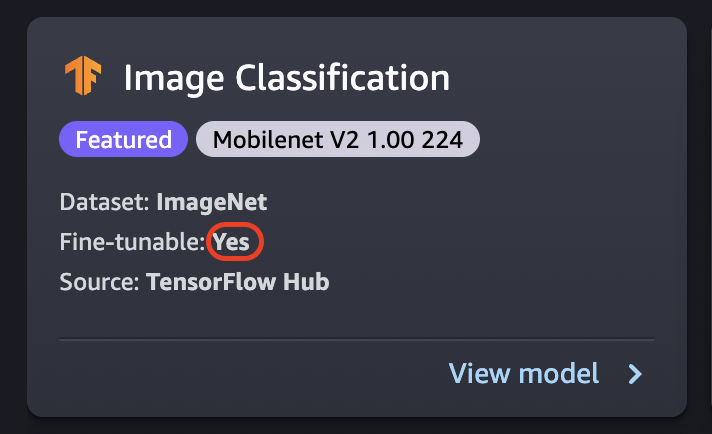
微調整では、ゼロからトレーニングするのではなく、新しいデータセットを使用して事前トレーニング済みのモデルをトレーニングします。転移学習とも呼ばれるこのプロセスでは、より小さなデータセットを使用し、より短時間のトレーニングで正確なモデルを生成できます。カードの [微調整可能] 属性が [はい] に設定されている場合は、モデルを微調整できます。
重要
2023 年 11 月 30 日以降、従来の Amazon SageMaker Studio のエクスペリエンスは Amazon SageMaker Studio Classic と名前が変更されました。以下のセクションは、Studio Classic アプリケーションの使用を前提とした内容です。更新後の Studio エクスペリエンスを使用する場合は、「Amazon SageMaker Studio」を参照してください。
注記
Studio での JumpStart モデルのファインチューニングの詳細については、「Studio でモデルをファインチューニングする」を参照してください。
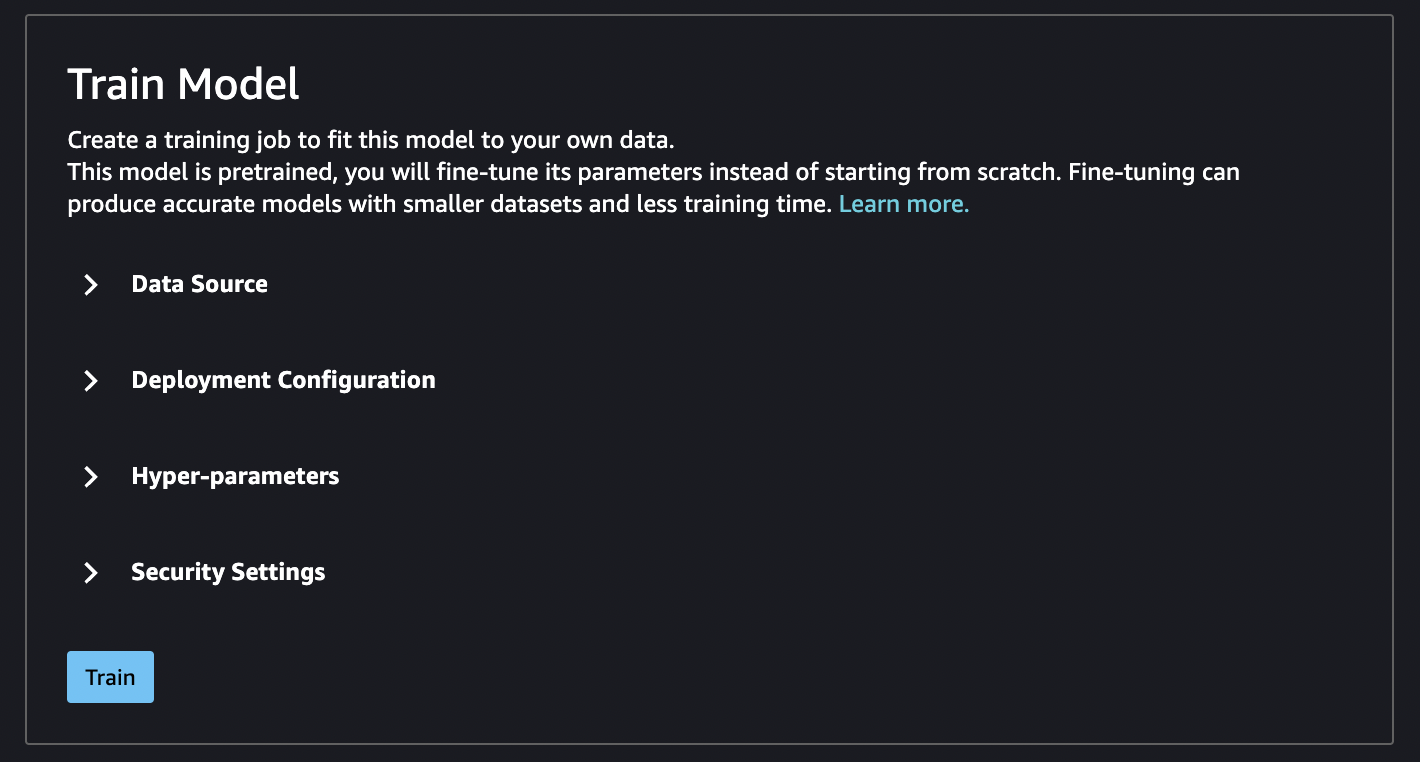
データソースの微調整
モデルを微調整するときは、デフォルトのデータセットを使用するか、Amazon S3 バケットにある独自のデータを選択できます。
使用可能なバケットを参照するには、[Find S3 bucket] (S3 バケットを検索) を選択します。利用可能なバケットは、Studio Classic アカウントの設定に使用されたアクセス許可によって制限されます。[Enter S3 bucket location] (S3 バケットの場所を入力) を選択して、Amazon S3 URI を指定することもできます。
ヒント
バケット内のデータのフォーマット形式を確認するには、[Learn more] (詳細) を選択します。モデルの説明セクションには、入力と出力に関する詳細情報があります。
テキストモデルの場合:
-
バケットには data.csv ファイルが必要です。
-
最初の列は、クラスラベルの一意の整数である必要があります。例:
1、2、3、4、n -
2 番目の列は文字列である必要があります。
-
2 番目の列には、モデルのタイプと言語に一致する対応するテキストが入ります。
ビジョンモデルの場合:
-
バケットには、クラスの数と同じ数のサブディレクトリが必要です。
-
各サブディレクトリには、そのクラスに属する .jpg 形式のイメージが必要です。
注記
SageMaker AI はクロスリージョンリクエストを許可しないため、Amazon S3 バケットは SageMaker Studio Classic を実行している AWS リージョン のと同じ にある必要があります。
デプロイ設定を微調整する
深層学習トレーニングには、最速の p3 ファミリーがお勧めです。モデルの微調整にも推奨されます。次のグラフは、各インスタンスタイプの GPU の数を示しています。p2 および g4 のインスタンスタイプなど、その他のオプションからも選択できます。
| インスタンスタイプ | GPU |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
ハイパーパラメータ
モデルの微調整に使用するトレーニングジョブのハイパーパラメータはカスタマイズが可能です。微調整可能な各モデルで使用できるハイパーパラメータは、モデルによって異なります。使用可能な各ハイパーパラメータの詳細については、「Amazon SageMaker の組み込みアルゴリズムと事前トレーニング済みモデル」で選択したモデルのハイパーパラメータのドキュメントを参照してください。例えば、微調整可能なイメージ分類 - TensorFlow ハイパーパラメータの詳細については、「画像分類 - TensorFlow ハイパーパラメータ」を参照してください。
ハイパーパラメータを変更せずにテキストモデルのデフォルトのデータセットを使用すると、結果としてほぼ同じモデルが得られます。ビジョンモデルの場合、デフォルトのデータセットは事前トレーニング済みモデルのトレーニングに使用されるデータセットとは異なるため、結果として異なるモデルになります。
以下のハイパーパラメータはモデル間で共通です。
-
Epocs (エポック) - 1 エポックは、データセット全体の 1 サイクルです。複数のインターバルで 1 つのバッチとなり、複数のバッチで 1 つのエポックとなります。モデルの精度が許容レベルに達するまで、またはエラー率が許容レベルを下回るまで、複数のエポックが実行されます。
-
Learning rate (学習レート) - エポック間で変更する値の量です。モデルが改善されるにしたがって、内部の重みが調整され、エラー率がチェックされ、モデルが進化したかどうかがチェックされます。一般的な学習レートは 0.1 または 0.01 です。0.01 は調整幅が非常に小さく、学習が収束するまでに長い時間がかかることがあります。一方、0.1 は非常に大きな値であり、トレーニングがオーバーシュートする可能性があります。モデルトレーニングの調整に使用する主要なハイパーパラメータの 1 つです。テキストモデルの場合、学習レートを非常に小さくすると (BERT の場合 5e-5)、より正確なモデルが得られます。
-
Batch size (バッチサイズ) - トレーニング目的で GPU に送信するために間隔ごとにデータセットから選択するレコードの数です。
画像の例では、GPU あたり 32 個のイメージを送信することから、バッチサイズは 32 になります。複数の GPU を持つインスタンスタイプを選択した場合、バッチは GPU の数で割った数になります。推奨バッチサイズは、使用するデータとモデルによって異なります。例えば、イメージデータの最適化方法は、言語データの処理方法とは異なります。
インスタンスタイプごとの GPU の数は、デプロイ設定セクションのインスタンスタイプのグラフで確認できます。最初は、標準の推奨バッチサイズから始めます (例: ビジョンモデルの場合 32)。次に、この数字に、選択したインスタンスタイプの GPU の数を乗算します。例えば、
p3.8xlargeを使用する場合、バッチサイズは GPU の数に合わせて調整されるため、これは 32 (バッチサイズ) に 4 (GPU 数) を乗算して合計 128 となります。BERT などのテキストモデルの場合は、64 のバッチサイズから始めて、必要に応じて値を減らします。
トレーニング出力
微調整プロセスが完了すると、親モデル、トレーニングジョブ名、トレーニングジョブの ARN、トレーニング時間、出力パスなど、モデルに関する情報が JumpStart から提供されます。出力パスは、新しいモデルを確認できる Amazon S3 バケット内の場所です。フォルダ構造には、指定したモデル名が使用されます。モデルファイルは /output サブフォルダにあり、名前は常に model.tar.gz となります。
例: s3://bucket/model-name/output/model.tar.gz
モデルトレーニングのデフォルト値を設定する
IAM ロール、VPC、KMS キーなどのパラメータのデフォルト値を設定して、JumpStart モデルのデプロイとトレーニングに事前入力することができます。詳細については、「JumpStart モデルのデフォルト値を設定する」を参照してください。
