翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
検索拡張生成
基盤モデルは通常オフラインでトレーニングされるため、モデルはモデルのトレーニング後に作成されたどのデータにも依存しません。さらに、基盤モデルは非常に一般的なドメインコーパスでトレーニングされるため、ドメイン固有のタスクにはあまり効果的ではありません。取得拡張生成 (RAG) を使用すると、基盤モデルの外部からデータを取得し、取得した関連データをコンテキストに追加することでプロンプトを拡張することができます。RAG モデルアーキテクチャの詳細については、「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
RAG では、プロンプトの補強に使用される外部データを、ドキュメントリポジトリ、データベース、API などの複数のデータソースから取得できます。最初のステップは、関連性検索を実行するために、ドキュメントとユーザークエリを互換性のある形式に変換することです。形式を互換性のあるものにするために、ドキュメントコレクションまたはナレッジライブラリ、およびユーザーが送信したクエリを、埋め込み言語モデルを使用して数値表現に変換します。埋め込みとは、ベクトル空間でテキストに数値表現を与えるプロセスです。RAG モデルアーキテクチャは、ナレッジライブラリのベクトル内にあるユーザークエリの埋め込みを比較します。その後、元のユーザープロンプトに、ナレッジライブラリ内の類似ドキュメントからの関連コンテキストが追加されます。次に、この拡張プロンプトが基盤モデルに送信されます。ナレッジライブラリと関連する埋め込みは非同期で更新できます。
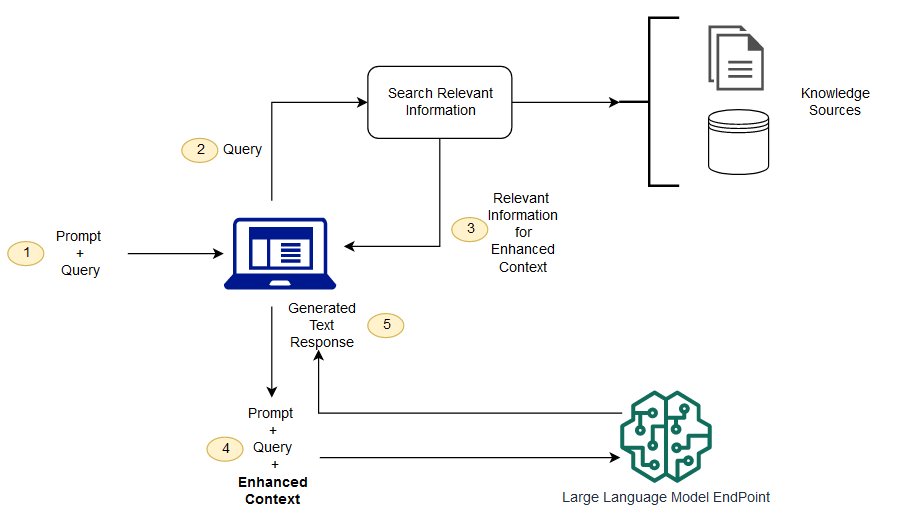
取得するドキュメントは、プロンプトの補完に役立つコンテキストを含む程度には大きく、プロンプトの最大シーケンス長に収まる程度に小さい必要があります。Hugging Face の General Text Embeddings (GTE) モデルなど、タスク固有の JumpStart モデルを使用して、プロンプトとナレッジライブラリドキュメントの埋め込みを提供できます。プロンプトとドキュメントの埋め込みを比較して最も関連性の高いドキュメントを特定したら、補足コンテキストを加味した新しいプロンプトを作成します。その後、拡張したプロンプトを、選択したテキスト生成モデルに渡します。
サンプルノートブックの例
RAG 基盤モデルソリューションの詳細については、次のサンプルノートブックを参照してください。
Amazon SageMaker AI サンプルリポジトリのクローンを作成して
