翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
マルチモデルエンドポイント
マルチモデルエンドポイントは、多数のモデルをデプロイするためのスケーラブルで費用対効果の高いソリューションを提供します。同じリソース群と共有サービングコンテナを使用して、すべてのモデルをホストします。これにより、単一モデルエンドポイントを使用する場合と比較して、エンドポイントの使用率が向上し、ホスティングコストが削減されます。また、Amazon SageMaker AI がメモリへのモデルのロードを管理し、エンドポイントへのトラフィックパターンに基づいてモデルをスケーリングするため、デプロイのオーバーヘッドも削減されます。
次の図は、マルチモデルエンドポイントが単一モデルのエンドポイントと比較してどのように機能するかを示しています。
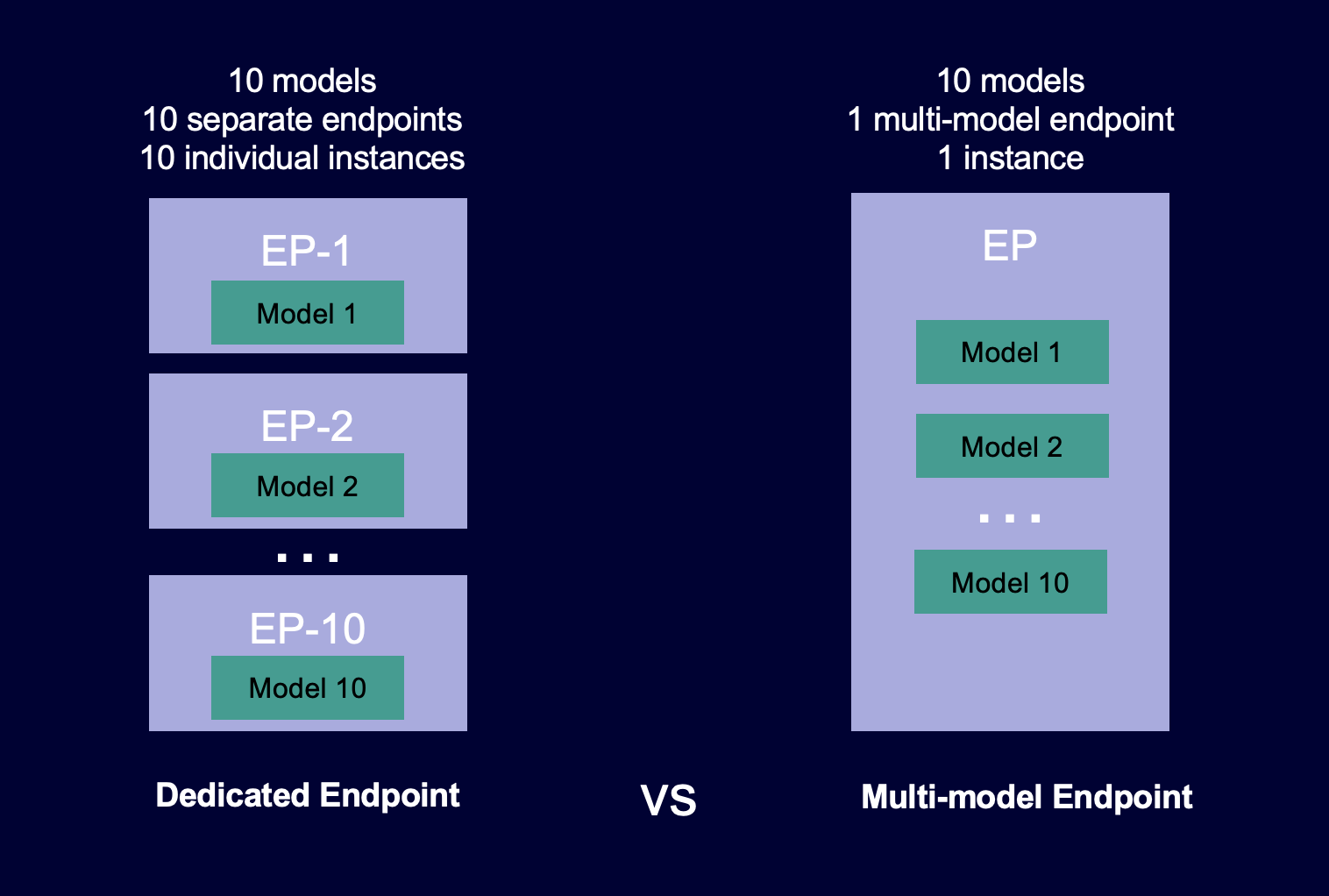
マルチモデルエンドポイントは、共有サービングコンテナ上で同じ ML フレームワークを使用する多数のモデルをホストするのに理想的です。アクセス頻度の高いモデルとアクセス頻度の低いモデルが混在している場合、マルチモデルエンドポイントは、より少ないリソースと高いコスト削減でトラフィックを効率的に処理できます。使用頻度の低いモデルを呼び出すときに発生する、コールドスタート関連のレイテンシーのペナルティをアプリケーション側で許容する必要があります。
マルチモデルエンドポイントは、CPU と GPU ベースのモデル両方のホスティングをサポートします。GPU ベースのモデルを使用すると、エンドポイントとその基盤となる高速コンピューティングインスタンスの使用率が高まるため、モデルのデプロイコストを削減できます。
マルチモデルエンドポイントにより、モデル間でメモリリソースのタイムシェアリングが可能になります。これは、モデル間でサイズと呼び出しレイテンシーが酷似している場合に最適です。この場合、マルチモデルエンドポイントは、すべてのモデル間でインスタンスを効果的に使用できます。1 秒あたりのトランザクション (TPS) やレイテンシーの要件が非常に高いモデルがある場合は、専用のエンドポイントでそれらのモデルをホストすることをお勧めします。
以下の機能を備えたマルチモデルエンドポイントを使用できます。
-
AWS PrivateLink VPCs
-
シリアル推論パイプライン (ただし、推論パイプラインに含めることができるマルチモデル対応コンテナは 1 つだけです)
-
A/B テスト
AWS SDK for Python (Boto) または SageMaker AI コンソールを使用して、マルチモデルエンドポイントを作成できます。CPU ベースのマルチモデルエンドポイントでは、Multi Model Server
トピック
マルチモデルエンドポイントの仕組み
SageMaker AI は、コンテナのメモリ内のマルチモデルエンドポイントでホストされるモデルのライフサイクルを管理します。SageMaker AI は、エンドポイントの作成時に Amazon S3 バケットからコンテナにすべてのモデルをダウンロードする代わりに、呼び出し時にモデルを動的にロードしてキャッシュします。SageMaker AI は、特定のモデルの呼び出しリクエストを受け取ると、次の処理を行います。
-
エンドポイントの背後にあるインスタンスにリクエストをルーティングします。
-
S3 バケットからインスタンスのストレージボリュームにモデルをダウンロードします。
-
その高速コンピューティングインスタンス上のコンテナのメモリ (CPU と GPU ベースのインスタンスのどちらを使用しているかによって CPU または GPU) にモデルをロードします。モデルがコンテナのメモリに既にロードされている場合、SageMaker AI はモデルをダウンロードしてロードする必要がないため、呼び出しが高速になります。
SageMaker AI は、モデルのリクエストを、モデルがすでにロードされているインスタンスに引き続きルーティングします。ただし、モデルが多数の呼び出しリクエストを受信し、マルチモデルエンドポイントに追加のインスタンスがある場合、SageMaker AI はトラフィックに対応するために一部のリクエストを別のインスタンスにルーティングします。モデルが 2 番目のインスタンスにまだロードされていない場合、モデルはそのインスタンスのストレージボリュームにダウンロードされ、コンテナのメモリにロードされます。
インスタンスのメモリ使用率が高く、SageMaker AI が別のモデルをメモリにロードする必要がある場合、そのインスタンスのコンテナから未使用のモデルをアンロードして、モデルをロードするのに十分なメモリがあることを確認します。アンロードされたモデルはインスタンスのストレージボリュームに残り、S3 バケットから再度ダウンロードすることなく、後でコンテナのメモリにロードできます。インスタンスのストレージボリュームが容量に達すると、SageMaker AI は未使用のモデルをストレージボリュームから削除します。
モデルを削除するには、リクエストの送信を停止し、そのモデルを S3 バケットから削除します。SageMaker AI は、サービングコンテナにマルチモデルエンドポイント機能を提供します。マルチモデルエンドポイントに対するモデルの追加と削除では、エンドポイント自体を更新する必要はありません。モデルを追加するには、そのモデルを S3 バケットにアップロードして、その呼び出しを開始します。この機能を使用するためにコードを変更する必要はありません。
注記
マルチモデルエンドポイントを更新すると、マルチモデルエンドポイントのスマートルーティングがトラフィックパターンに適応するため、エンドポイントでの初回呼び出しリクエストの待ち時間が長くなる可能性があります。ただし、トラフィックパターンを学習すると、最も頻繁に使用されるモデルのレイテンシーは短くなります。使用頻度の低いモデルでは、モデルがインスタンスに動的に読み込まれるため、コールドスタートのレイテンシーが発生する可能性があります。
マルチモデルエンドポイントのサンプルノートブック
マルチモデルエンドポイントの使用方法の詳細については、以下のサンプルノートブックを試すことができます。
-
CPU ベースのインスタンスを使用するマルチモデルエンドポイントの例。
-
マルチモデルエンドポイント XGBoost サンプルノートブック
– このノートブックでは、複数の XGBoost モデルをエンドポイントにデプロイする方法を示します。 -
マルチモデルエンドポイント BYOC サンプルノートブック
– このノートブックでは、SageMaker AI でマルチモデルエンドポイントをサポートするカスタマーコンテナをセットアップしてデプロイする方法を示します。
-
-
GPU ベースのインスタンスを使用するマルチモデルエンドポイントの例。
-
Amazon SageMaker AI マルチモデルエンドポイント (MME) を使用して GPUs で複数の深層学習モデル
を実行する – このノートブックでは、NVIDIA Triton 推論コンテナを使用して ResNet-50 モデルをマルチモデルエンドポイントにデプロイする方法を示します。
-
SageMaker AI で前の例を実行するために使用できる Jupyter Notebook インスタンスを作成してアクセスする方法については、「」を参照してくださいAmazon SageMaker ノートブックインスタンス。ノートブックインスタンスを作成して開いたら、SageMaker AI Examples タブを選択して、すべての SageMaker AI サンプルのリストを表示します。マルチモデルエンドポイントノートブックは [高度な機能] セクションにあります。ノートブックを開くには、その [Use (使用)] タブを選択し、[Create copy (コピーを作成)] を選択します。
マルチモデルエンドポイントのユースケースの詳細については、以下のブログとリソースを参照してください。
-
ケーススタディ: Veeva Systems
