Redshift 연결
AWS Glue for Spark를 사용하여 Amazon Redshift 데이터베이스의 테이블에서 읽고 쓸 수 있습니다. Amazon Redshift 데이터베이스에 연결할 때 AWS Glue는 Amazon Redshift SQL COPY 및 UNLOAD 명령을 사용하여 Amazon S3를 통해 데이터를 이동함으로써 처리량을 극대화합니다. AWS Glue 4.0 이상에서는 Apache Spark용 Amazon Redshift 통합을 사용하여 이전 버전을 통해 연결할 때 사용할 수 있었던 기능 외에도 Amazon Redshift에서만 지원하는 기능 및 최적화를 사용하여 읽고 쓸 수 있습니다.
Amazon Redshift 사용자가 AWS Glue를 사용하여 서버리스 데이터 통합 및 ETL을 위해 보다 쉽게 AWS로 마이그레이션하는 방법에 대해 알아보세요.
Redshift 연결 구성
AWS Glue에서 Amazon Redshift 클러스터를 사용하려면 다음과 같은 몇 가지 필수 조건이 필요합니다.
-
데이터베이스에서 읽고 쓸 때 임시 스토리지로 사용하는 Amazon S3 디렉터리.
-
Amazon Redshift 클러스터, AWS Glue 작업 및 Amazon S3 디렉터리 간 통신을 지원하는 Amazon VPC.
-
AWS Glue 작업 및 Amazon Redshift 클러스터에 대한 적절한 IAM 권한.
IAM 역할 구성
Amazon Redshift 클러스터의 역할 설정
AWS Glue 작업과 통합하려면 Amazon Redshift 클러스터는 Amazon S3에서 읽고 쓸 수 있어야 합니다. 이를 허용하기 위해 연결하려는 Amazon Redshift 클러스터에 IAM 역할을 연결할 수 있습니다. 역할에는 Amazon S3 임시 디렉터리에서의 읽기 및 쓰기를 허용하는 정책이 있어야 합니다. 역할에는 AssumeRole을 위해 redshift.amazonaws.com 서비스를 허용하는 신뢰 관계가 있어야 합니다.
IAM 역할을 Amazon Redshift에 연결하려면
필수 조건: 파일의 임시 저장에 사용되는 Amazon S3 버킷 또는 디렉터리.
-
Amazon Redshift 클러스터에 필요한 Amazon S3 권한을 식별합니다. Amazon Redshift 클러스터 간에 데이터를 이동하는 경우 AWS Glue 작업이 Amazon Redshift에 대해 COPY 및 UNLOAD 문을 실행합니다. 작업에서 Amazon Redshift의 테이블을 수정하는 경우 AWS Glue는 CREATE LIBRARY 문도 실행합니다. Amazon Redshift에서 이러한 명령문을 실행하는 데 필요한 특정 Amazon S3 권한에 대한 자세한 내용은 Amazon Redshift 설명서, Amazon Redshift: 다른 AWS 리소스에 대한 액세스 권한을 참조하세요.
IAM 콘솔에서 필요한 권한이 포함된 IAM 정책을 생성합니다. IAM 정책 생성에 대한 자세한 내용은 IAM 정책 생성을 참조하세요.
IAM 콘솔에서 Amazon Redshift가 역할을 수임할 수 있는 역할 및 신뢰 관계를 생성합니다. IAM 설명서의 지침, AWS 서비스에 대한 역할 생성(콘솔)을 수행합니다.
AWS 서비스 사용 사례를 선택하라는 메시지가 표시되면 'Redshift - 사용자 지정 가능'을 선택합니다.
정책을 연결하라는 메시지가 표시되면 이전에 정의한 정책을 선택합니다.
참고
Amazon Redshift의 역할을 구성하는 방법에 대한 자세한 내용은 Amazon Redshift 설명서에서 Amazon Redshift가 사용자를 대신하여 다른 AWS 서비스에 액세스할 수 있도록 권한 부여를 참조하세요.
Amazon Redshift 콘솔에서 Amazon Redshift 클러스터에 역할을 연결합니다. Amazon Redshift 설명서의 지침을 수행합니다.
Amazon Redshift 콘솔에서 강조 표시된 옵션을 선택하여 다음 설정을 구성합니다.
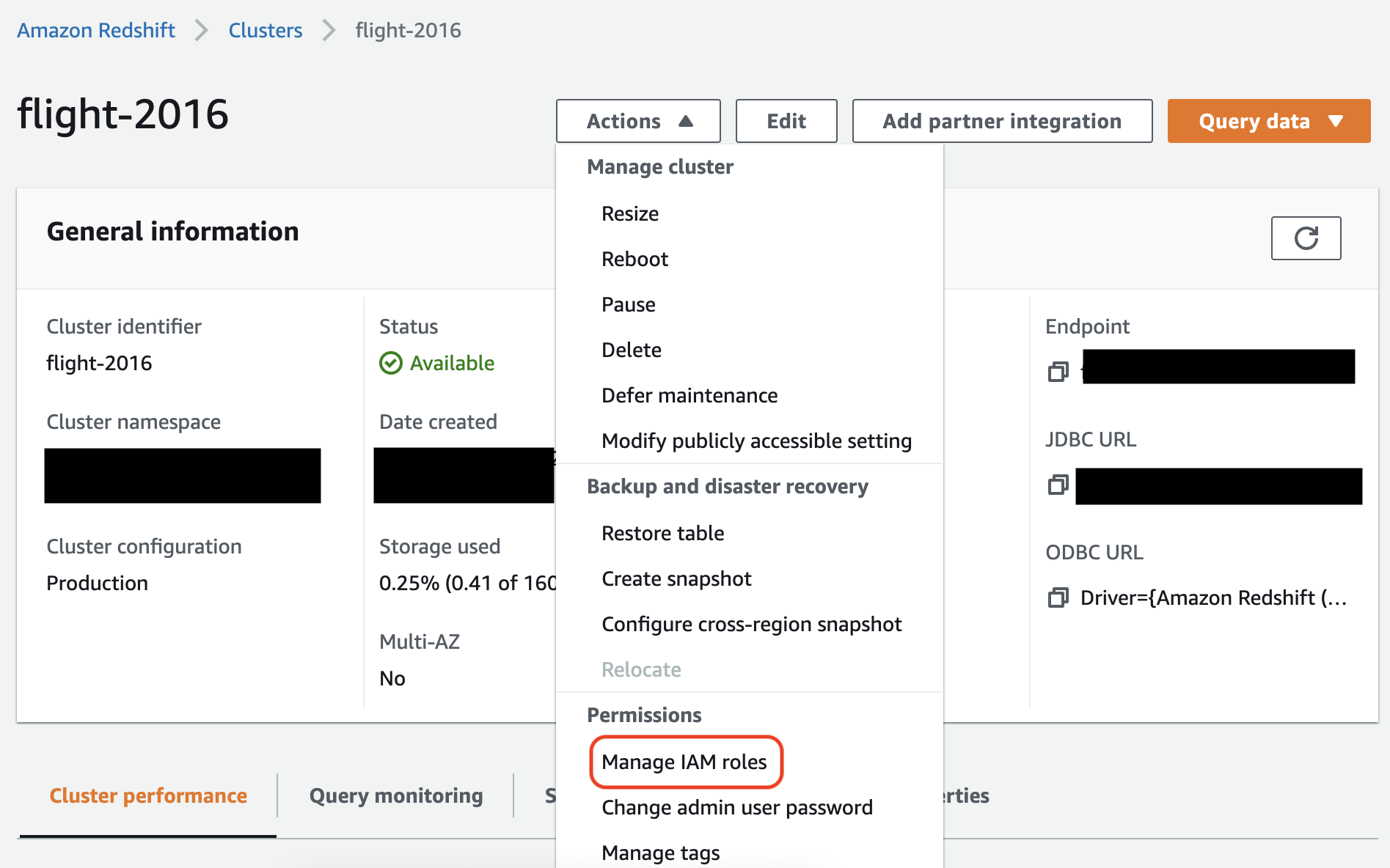
참고
기본적으로 AWS Glue는 작업을 실행하기 위해 사용자가 지정한 역할을 사용하여 생성되는 Amazon Redshift의 임시 보안 인증을 전달합니다. 이 보안 인증은 사용하지 않는 것이 좋습니다. 보안을 위해 이러한 보안 인증은 1시간 후에 만료됩니다.
AWS Glue 작업의 역할 설정
AWS Glue 작업에는 Amazon S3 버킷에 액세스하기 위한 역할이 필요합니다. Amazon Redshift 클러스터에는 IAM 권한이 필요하지 않습니다. 액세스는 데이터베이스 보안 인증 및 Amazon VPC의 연결을 통해 제어됩니다.
Amazon VPC 설정
Amazon Redshift 데이터 스토어에 대한 액세스를 설정하려면
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/redshiftv2/
에서 Amazon Redshift 콘솔을 엽니다. -
좌측 탐색 창에서 클러스터를 선택합니다.
-
AWS Glue로부터 액세스하고자 하는 클러스터 이름을 선택합니다.
-
Cluster Properties(클러스터 속성) 섹션에서 VPC security groups(VPC 보안 그룹)에서 보안 그룹을 선택하여 사용할 AWS Glue를 허용합니다. 미래 참조를 위해 선택하는 보안 그룹의 이름을 기록합니다. 보안 그룹을 선택하면 Amazon EC2 콘솔 [보안 그룹(Security Groups)] 목록을 엽니다.
-
보안 그룹을 선택하여 [Inbound(인바운드)] 탭으로 수정하고 탐색합니다.
-
자기 참조 규칙을 추가하여 AWS Glue 구성 요소를 허용하여 통신합니다. 특히, [Type(유형)]
All TCP의 규칙을 추가하고 확인합니다. [Protocol(프로토콜)]는TCP이고 [Port Range(포트 범위)]는 모든 포트를 포함하고 포트의 [Source(원본)]은 [Group ID(그룹 ID)]이라는 동일한 보안 그룹입니다.인바운드 규칙은 다음과 비슷하게 보입니다.
유형 프로토콜 포트 범위 소스 모든 TCP
TCP
0~65535
database-security-group
예:
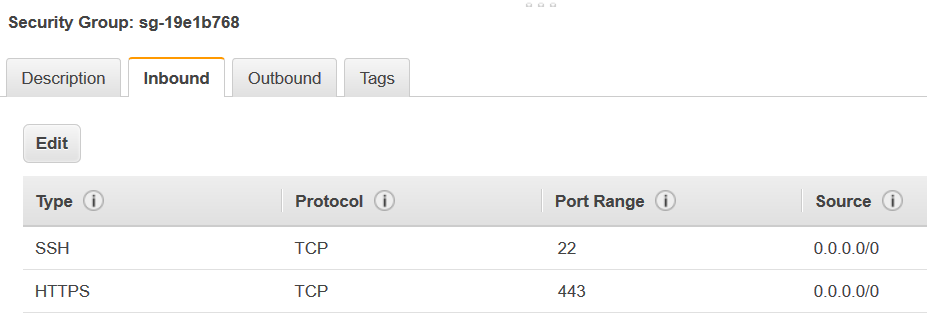
-
아웃바운드 트래픽 규칙도 추가합니다. 예를 들어 아웃바운드 트래픽을 모든 포트로 엽니다.
유형 프로토콜 포트 범위 대상 모든 트래픽
ALL
ALL
0.0.0.0/0
또는 자기 참조 규칙을 생성합니다. 여기서 Type(유형) 은
All TCP이고 Protocol(프로토콜)은TCP이고 Port Range(포트 범위)는 모든 포트를 포함하고 포트의 Destination(대상)은 Group ID(그룹 ID)와 동일한 보안 그룹 이름입니다. Amazon S3 VPC 엔드포인트를 사용할 경우 Amazon S3 액세스에 대한 HTTPS 규칙도 추가합니다.s3-prefix-list-id는 VPC에서 Amazon S3 VPC 엔드포인트로 트래픽을 허용하기 위해 보안 그룹에 필요합니다.예:
유형 프로토콜 포트 범위 대상 모든 TCP
TCP
0~65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
AWS Glue 설정
Amazon VPC 연결 정보를 제공하는 AWS Glue 데이터 카탈로그 연결을 생성해야 합니다.
콘솔에서 AWS Glue에 대한 Amazon Redshift Amazon VPC 연결을 구성하려면
-
AWS Glue 연결 추가의 단계에 따라 데이터 카탈로그 연결을 생성합니다. 연결을 생성한 후에는 다음 단계를 위해 연결 이름,
connectionName을 유지합니다.연결 유형을 선택할 때는 Amazon Redshift를 선택합니다.
Redshift 클러스터를 선택할 때는 이름을 기준으로 클러스터를 선택합니다.
클러스터의 Amazon Redshift 사용자에 대한 기본 연결 정보를 제공합니다.
Amazon VPC 설정이 자동으로 구성됩니다.
참고
AWS SDK를 통해 Amazon Redshift 연결을 생성할 때는 Amazon VPC에 대한
PhysicalConnectionRequirements를 수동으로 제공해야 합니다. -
AWS Glue 작업 구성에서 추가 네트워크 연결로
connectionName을 제공합니다.
예제: Amazon Redshift 테이블에서 읽기
Amazon Redshift 클러스터와 Amazon Redshift 서버리스 환경에서 읽을 수 있습니다.
필수 조건: 읽으려는 Amazon Redshift 테이블. 임시 디렉터리로 Amazon S3 URI(temp-s3-dir) 및 IAM 역할(role-account-id 계정에 있는 rs-role-name)을 보유한 후에 이전 Redshift 연결 구성 섹션의 단계를 수행합니다.
예제: Amazon Redshift 테이블에 쓰기
Amazon Redshift 클러스터와 Amazon Redshift 서버리스 환경에 쓸 수 있습니다.
필수 조건: Amazon Redshift 클러스터. 그리고 임시 디렉터리로 Amazon S3 URI(temp-s3-dir) 및 IAM 역할(role-account-id 계정에 있는 rs-role-name)을 보유한 후에 이전 Redshift 연결 구성 섹션의 단계를 수행합니다. 또한 데이터베이스에 해당 콘텐츠를 쓰려는 DynamicFrame도 필요합니다.
Amazon Redshift 연결 옵션 참조
모든 AWS Glue JDBC 연결에서 url, user 및 password와 같은 정보를 설정하는 데 사용되는 기본 연결 옵션은 모든 JDBC 유형에서 일관됩니다. 표준 JDBC 클러스터 파라미터에 대한 자세한 내용은 JDBC 연결 옵션 참조 섹션을 참조하세요.
Amazon Redshift 연결 유형에는 다음과 같은 몇 가지 추가 연결 옵션이 있습니다.
-
"redshiftTmpDir": (필수) 데이터베이스 외부에서 복사할 때 임시 데이터를 스테이징할 수 있는 Amazon S3 경로. -
"aws_iam_role": (선택 사항) IAM 역할의 ARN. AWS Glue 작업에서는 이 역할을 Amazon Redshift 클러스터로 전달하여 작업의 지침을 완료하는 데 필요한 권한을 클러스터에 부여합니다.
AWS Glue 4.0 이상에서 사용할 수 있는 추가 연결 옵션
AWS Glue 연결 옵션을 통해 새로운 Amazon Redshift 커넥터의 옵션을 전달할 수도 있습니다. 지원되는 커넥터 옵션의 전체 목록은 Apache Spark용 Amazon Redshift 통합의 Spark SQL 파라미터 섹션을 참조하세요.
편의를 위해 다음과 같은 새로운 특정 옵션을 다시 설명합니다.
| 명칭 | 필수 | 기본값 | 설명 |
|---|---|---|---|
| autopushdown |
아니요 | TRUE | SQL 작업에 대한 Spark 논리 계획을 캡처하고 분석하여 조건자 및 쿼리 푸시다운을 적용합니다. 작업은 SQL 쿼리로 변환된 다음 Amazon Redshift에서 실행되어 성능이 향상됩니다. |
| autopushdown.s3_result_cache |
아니요 | FALSE | 동일한 쿼리가 동일한 Spark 세션에서 다시 실행될 필요가 없도록 SQL 쿼리를 캐시하여 Amazon S3 경로 매핑 데이터를 메모리에서 언로드합니다. |
| unload_s3_format |
아니요 | PARQUET | PARQUET - 쿼리 결과를 Parquet 형식으로 언로드합니다. TEXT - 쿼리 결과를 파이프로 구분된 텍스트 형식으로 언로드합니다. |
| sse_kms_key |
아니요 | N/A | AWS의 기본 암호화 대신 |
| extracopyoptions |
아니요 | N/A | 데이터를 로드할 때 Amazon Redshift 이러한 옵션은 |
| csvnullstring(실험용) |
아니요 | NULL | CSV |
이러한 새 파라미터는 다음과 같은 방법으로 사용할 수 있습니다.
성능 개선을 위한 새로운 옵션
새 커넥터에는 몇 가지 새로운 성능 개선 옵션이 도입되었습니다.
-
autopushdown: 기본적으로 활성화됩니다. -
autopushdown.s3_result_cache: 기본적으로 비활성화됩니다. -
unload_s3_format: 기본적으로PARQUET입니다.
이러한 옵션을 사용하는 방법에 대한 자세한 내용은 Apache Spark용 Amazon Redshift 통합을 참조하세요. 캐시된 결과에 오래된 정보가 포함될 수 있으므로 읽기 작업과 쓰기 작업이 혼합된 경우
autopushdown.s3_result_cache를 켜지 않는 것이 좋습니다. 성능을 개선하고 스토리지 비용을 절감하기 위해 UNLOAD 명령의 unload_s3_format 옵션은 기본적으로 PARQUET로 설정됩니다. UNLOAD 명령 기본 동작을 사용하려면 옵션을 TEXT로 재설정합니다.
읽기를 위한 새 암호화 옵션
Amazon Redshift 테이블에서 데이터를 읽을 때 AWS Glue가 사용하는 임시 폴더의 데이터는 기본값으로 SSE-S3 암호화를 사용하여 암호화됩니다. AWS Key Management Service(AWS KMS)의 고객 관리 키를 사용하여 데이터를 암호화하려면 AWS Glue 3.0 버전의 레거시 설정 옵션 ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") 대신 ksmKey가 AWS KMS의 키 ID인 ("sse_kms_key"
→ kmsKey)를 설정할 수 있습니다.
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
IAM 기반 JDBC URL 지원
새 커넥터는 IAM 기반 JDBC URL을 지원하므로 사용자 및 암호 또는 보안 암호를 전달할 필요가 없습니다. IAM 기반 JDBC URL을 사용하는 커넥터에서는 작업 런타임 역할을 사용하여 Amazon Redshift 데이터 소스에 액세스합니다.
1단계: 다음과 같은 최소 필수 정책을 AWS Glue 작업 런타임 역할에 연결합니다.
2단계: IAM 기반 JDBC URL을 다음과 같이 사용합니다. 연결하려는 Amazon Redshift 사용자 이름을 사용하여 새 옵션 DbUser를 지정합니다.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
참고
DynamicFrame은 현재 GlueContext.create_dynamic_frame.from_options 워크플로에
DbUser가 있는 IAM 기반 JDBC URL만 지원합니다.
AWS Glue 3.0 버전에서 4.0 버전으로 마이그레이션
AWS Glue 4.0에서 ETL 작업은 다양한 옵션 및 구성을 통해 새로운 Amazon Redshift Spark 커넥터 및 새로운 JDBC 드라이버에 액세스할 수 있습니다. 새로운 Amazon Redshift 커넥터 및 드라이버는 성능을 염두에 두고 작성되었으며 데이터의 트랜잭션 일관성을 유지합니다. 이러한 제품은 Amazon Redshift 설명서에 문서화되어 있습니다. 자세한 내용은 다음을 참조하세요.
테이블/열 이름 및 식별자 제한
새로운 Amazon Redshift Spark 커넥터 및 드라이버에서는 Redshift 테이블 이름에 대한 요구 사항이 더 제한적입니다. 자세한 내용은 Amazon Redshift 테이블 이름을 정의하기 위한 이름 및 식별자를 참조하세요. 규칙을 따르지 않는 테이블 이름 및 특정 문자(예: 공백)에서는 작업 북마크 워크플로가 작동하지 않을 수 있습니다.
이름 및 식별자 규칙을 따르지 않는 이름을 가진 레거시 테이블이 있고 북마크에 문제가 있는 경우(이전 Amazon Redshift 테이블 데이터를 재처리하는 작업) 테이블 이름을 변경하는 것이 좋습니다. 자세한 내용은 ALTER TABLE 예를 참조하세요.
DataFrame의 기본 tempformat 변경
AWS Glue 3.0 버전 Spark 커넥터에서는 Amazon Redshift Redshift에 쓰는 동안 기본적으로 tempformat이 CSV로 지정됩니다. 일관성을 유지하기 위해 AWS Glue 3.0 버전에서는
DynamicFrame의 기본 tempformat로 CSV를 계속 사용합니다. 이전에 Amazon Redshift Spark 커넥터에서 Spark Dataframe API를 직접 사용한 적이 있다면 DataframeReader 및 Writer 옵션에서 tempformat을 CSV로 명시적으로 설정할 수 있습니다. 그렇지 않으면 새 Spark 커넥터에서 tempformat이 기본적으로 AVRO로 설정됩니다.
동작 변경: Amazon Redshift 데이터 형식 REAL을 DOUBLE 대신 Spark 데이터 형식 FLOAT에 매핑합니다.
AWS Glue 3.0 버전에서는 Amazon Redshift REAL이 Spark
DOUBLE 유형으로 변환됩니다. Amazon Redshift
REAL 유형과 Spark FLOAT 유형 간에 상호 변환되도록 새로운 Amazon Redshift Spark 커넥터의 동작을 업데이트했습니다. 레거시 사용 사례에서 Amazon RedshiftREAL 유형을 SparkDOUBLE 유형에 계속 매핑하려는 경우 다음 해결 방법을 사용할 수 있습니다.
-
DynamicFrame의 경우DynamicFrame.ApplyMapping을 사용하여Float유형을Double유형에 매핑합니다.Dataframe의 경우cast를 사용해야 합니다.
코드 예제:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
VARBYTE 데이터 형식 처리
AWS Glue 3.0 및 Amazon Redshift 데이터 형식으로 작업할 때, AWS Glue 3.0은 Amazon Redshift VARBYTE를 Spark STRING 형식으로 변환합니다. 그러나 최신 Amazon Redshift Spark 커넥터는 VARBYTE 데이터 형식을 지원하지 않습니다. 이 제한을 해결하려면 VARBYTE 열을 지원되는 데이터 형식으로 변환하는 Redshift 뷰를 생성합니다. 그런 다음 새 커넥터를 사용하여 원래 테이블 대신 이 뷰에서 데이터를 로드하면 호환성을 보장하는 동시에 VARBYTE 데이터에 대한 액세스를 유지할 수 있습니다.
Redshift 쿼리의 예:
CREATE VIEWview_nameAS SELECT FROM_VARBYTE(varbyte_column, 'hex') FROMtable_name
