Apache Spark 프로그램을 AWS Glue로 마이그레이션
Apache Spark는 대규모 데이터 세트에서 수행되는 분산 컴퓨팅 워크로드를 위한 오픈 소스 플랫폼입니다. AWS Glue에서는 Spark의 기능을 활용하여 ETL에 최적화된 환경을 제공합니다. Spark 프로그램을 AWS Glue로 마이그레이션하여 기능을 활용할 수 있습니다. AWS Glue에서는 Amazon EMR의 Apache Spark에서 기대하는 것과 동일한 성능 향상을 제공합니다.
Spark 코드 실행
기본 Spark 코드는 기본 제공 AWS Glue 환경에서 실행될 수 있습니다. 스크립트는 대화형 세션에 적합한 워크플로우인 코드를 반복적으로 변경하여 개발되는 경우가 많습니다. 그러나 기존 코드는 AWS Glue 작업에서 실행되기에 더 적합하며 이를 통해 각 스크립트 실행에 대한 로그와 지표를 예약하고 일관되게 가져올 수 있습니다. 콘솔을 통해 기존 스크립트를 업로드하고 편집할 수 있습니다.
-
스크립트의 소스를 확보합니다. 이 예에서는 Apache Spark 리포지토리의 스크립트 예를 사용합니다. 이진화 메서드 예
-
AWS Glue 콘솔에서 왼쪽 탐색 창을 확장하고 ETL > 작업(Jobs)을 선택합니다.
작업 생성(Create job) 패널에서 Spark 스크립트 편집기(Spark script editor)를 선택합니다. 옵션(Options) 섹션이 나타납니다. 옵션(Options)에서 기존 스크립트 업로드 및 편집(Upload and edit an existing script)을 선택합니다.
파일 업로드(File upload) 섹션이 나타납니다. 파일 업로드(File upload)에서 파일 선택(Choose file)을 클릭합니다. 시스템 파일 선택기가 나타납니다.
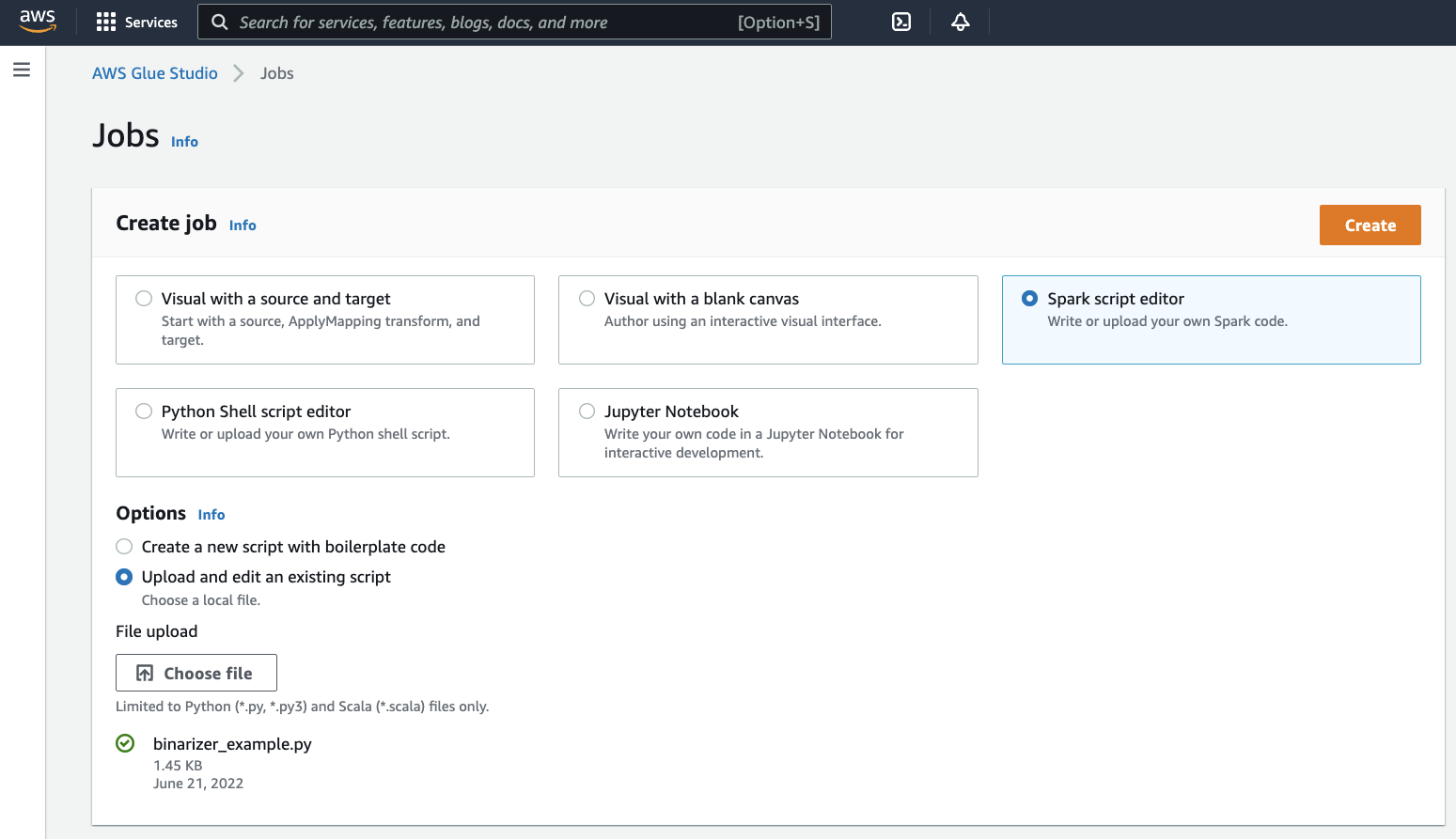
binarizer_example.py를 저장한 위치로 이동하여 선택하고 선택을 확인합니다.생성(Create) 버튼이 작업 생성(Create job) 패널의 머리글에 나타납니다. 이 버튼을 클릭합니다.
-
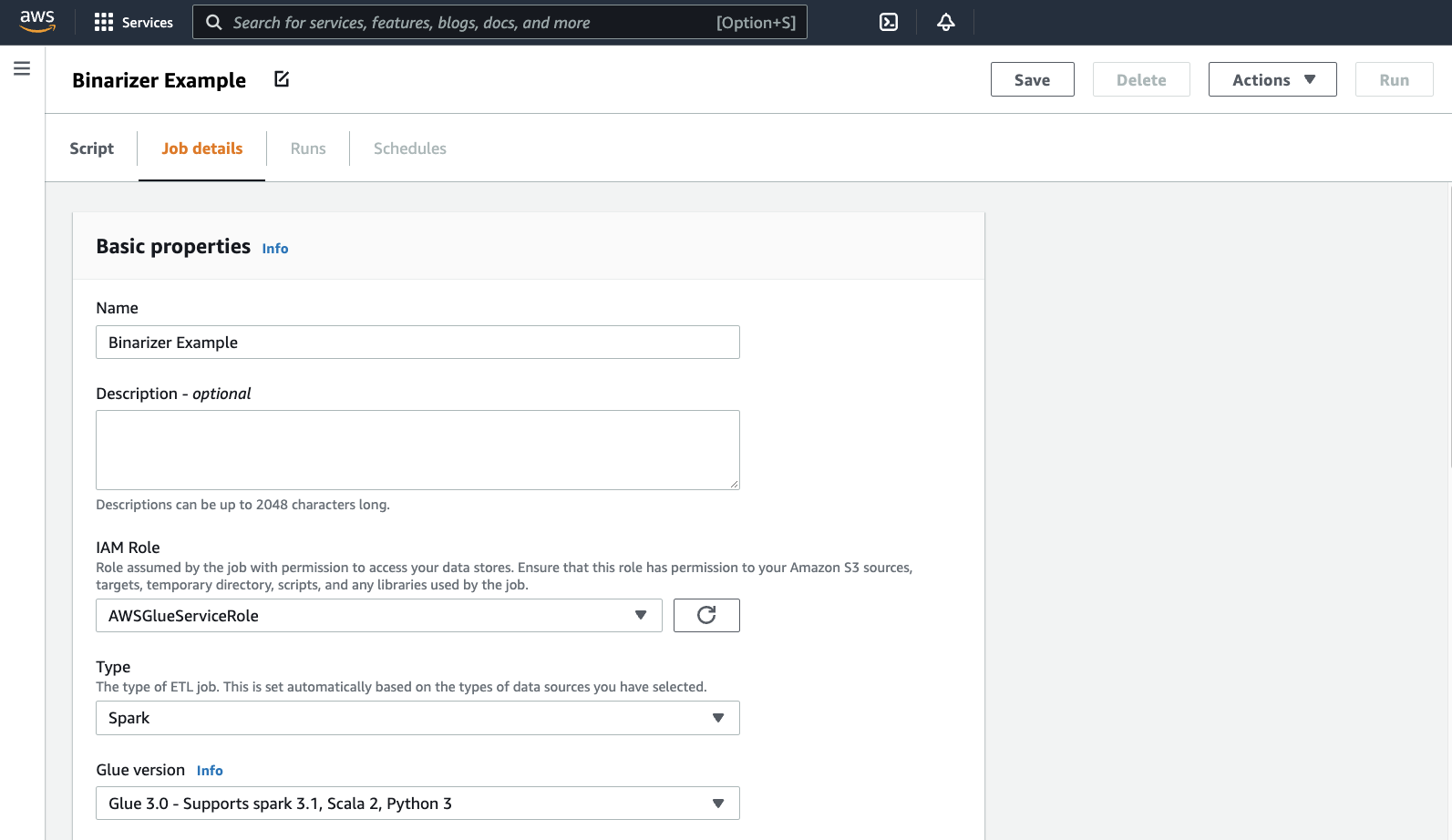
브라우저가 스크립트 편집기로 이동합니다. 머리글에서 Job 세부 정보(Job details) 탭을 클릭합니다. 이름 및 IAM 역할을 설정합니다. AWS Glue IAM 역할에 대한 지침은 AWS Glue에 대한 IAM 권한 설정 섹션을 참조하세요.
옵션 사항 - 요청된 작업자 수(Requested number of workers)를
2로, 재시도 횟수(Number of retries)를1로 설정합니다. 이러한 옵션은 프로덕션 작업을 실행할 때 유용하지만 이 옵션을 끄면 기능을 테스트하는 동안 사용 환경이 간소화됩니다.제목 표시줄에서 저장(Save)을 클릭한 다음 실행(Run)을 클릭합니다.
-
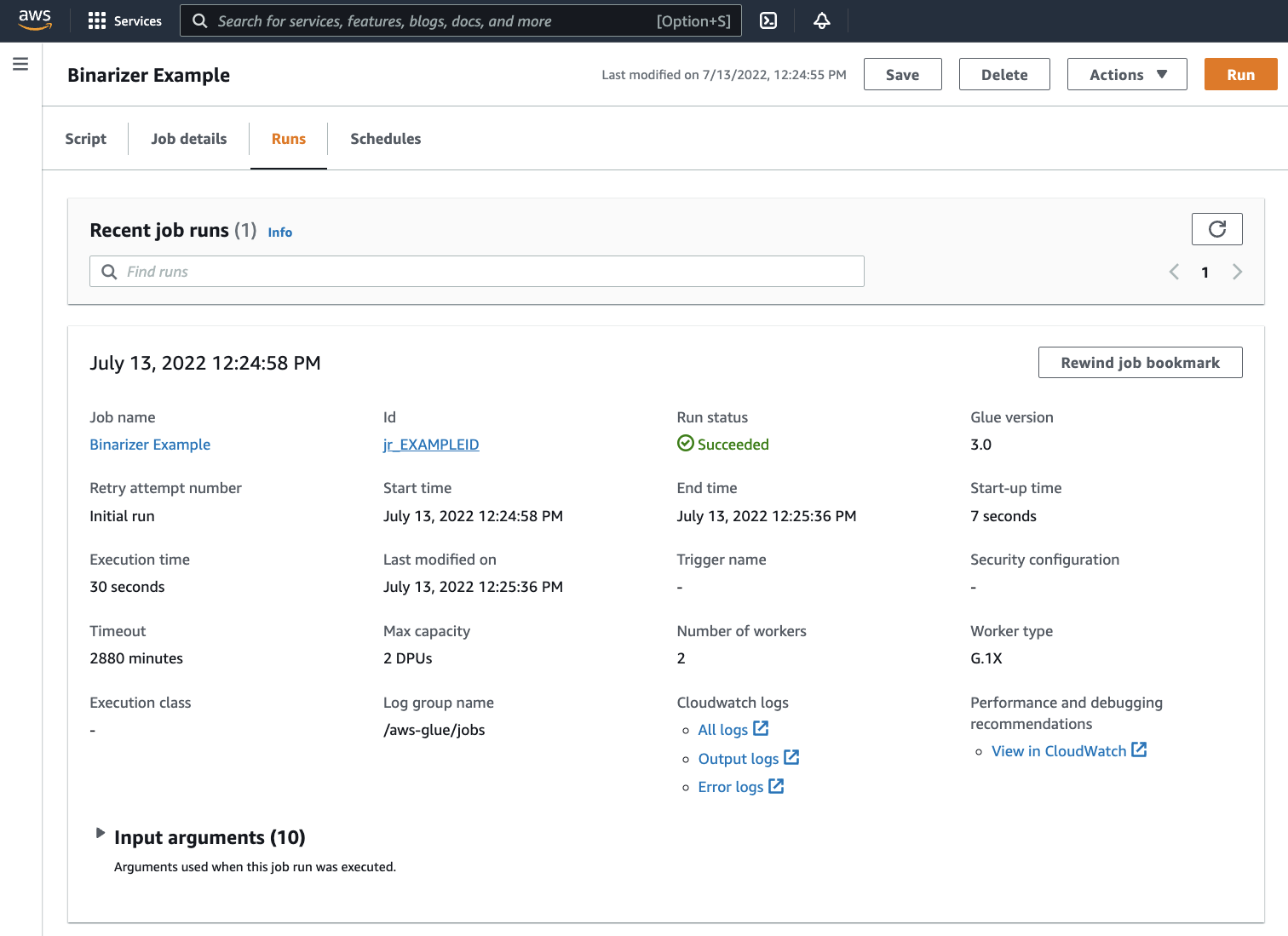
실행(Runs) 탭으로 이동합니다. 작업 실행에 해당하는 패널이 표시됩니다. 몇 분간 기다리면 페이지가 자동으로 새로 고침되어 실행 상태(Run status) 아래에 성공(Succeeded)이라고 표시됩니다.
-
출력을 검사하여 Spark 스크립트가 의도한 대로 실행되었는지 확인하려고 합니다. 이 Apache Spark 샘플 스크립트는 출력 스트림에 문자열을 기록해야 합니다. 성공적인 작업 실행에 대한 패널의 Cloudwatch 로그(Cloudwatch logs)에서 출력 로그(Output logs)로 이동하면 해당 문자열이 표시됩니다.
jr_로 시작하는 ID 레이블에서 생성된 ID인 작업 실행 ID를 기록해 둡니다.그러면 CloudWatch 콘솔이 열리고 작업 실행 ID에 대한 로그 스트림의 내용으로 필터링된 기본 AWS Glue 로그 그룹
/aws-glue/jobs/output의 내용을 시각화하도록 설정됩니다. 각 작업자는 로그 스트림(Log streams) 아래 행으로 표시된 로그 스트림을 생성하게 됩니다. 한 작업자가 요청된 코드를 실행했어야 합니다. 올바른 작업자를 식별하려면 모든 로그 스트림을 열어야 합니다. 적합한 작업자를 찾으면 다음 이미지에 표시된 것과 같이 스크립트의 출력이 표시되어야 합니다.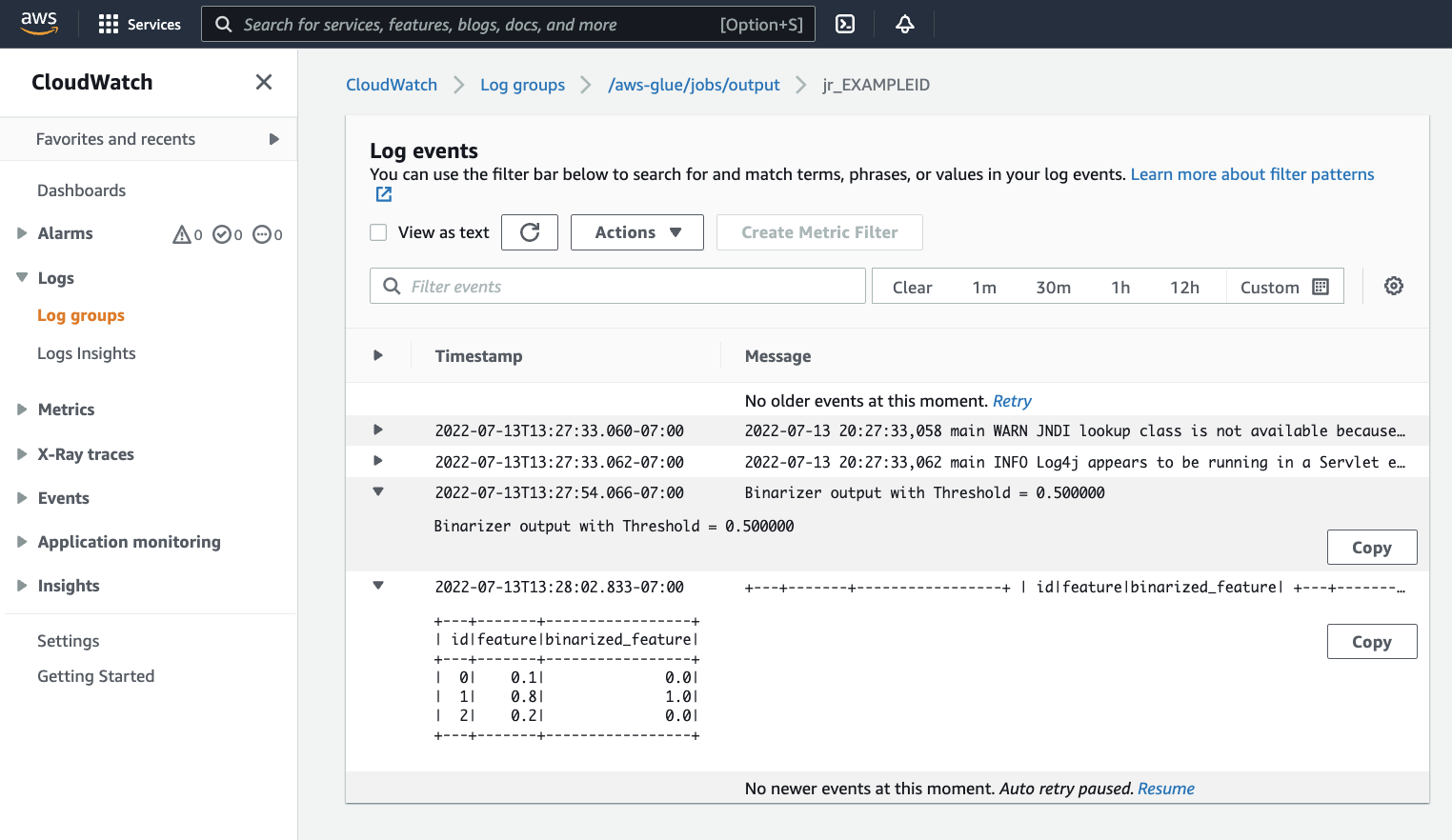
Spark 프로그램을 마이그레이션하는 데 필요한 일반적인 절차
Spark 버전 지원 평가
AWS Glue 릴리즈 버전에 따라 AWS Glue 작업에 사용할 수 있는 Apache Spark와 Python의 버전이 정해집니다. AWS Glue 버전 및 AWS Glue 버전의 지원 대상을 찾을 수 있습니다. 특정 AWS Glue 기능에 액세스하려면 최신 버전의 Spark와 호환되도록 Spark 프로그램을 업데이트해야 할 수 있습니다.
타사 라이브러리 포함
기존의 많은 Spark 프로그램에는 프라이빗 및 퍼블릭 아티팩트 모두에 대한 종속성이 있습니다. AWS Glue에서는 Scala 작업에 대한 JAR 스타일 종속성뿐만 아니라 Python 작업에 대한 휠 및 소스 퓨어-Python 종속성을 지원합니다.
Python - Python 종속성에 대한 자세한 정보는 AWS Glue와 함께 Python 라이브러리 사용 섹션을 참조하세요.
공통 Python 종속성은 일반적으로 요청되는 Pandas--additional-python-modules를 사용할 수 있습니다. 작업 인수에 대한 자세한 정보는 AWS Glue 작업에서 작업 파라미터 사용 섹션을 참조하세요.
--extra-py-files 작업 인수를 추가 Python 종속성에 제공할 수 있습니다. Spark 프로그램에서 작업을 마이그레이션하는 경우 이 파라미터는 PySpark의 --py-files 플래그와 기능적으로 동일하고 동일한 제한이 적용되므로 좋은 옵션입니다. --extra-py-files 파라미터에 대한 자세한 내용을 알아보려면 PySpark 네이티브 기능으로 Python 파일 포함 섹션을 참조하세요.
새 작업의 경우 --additional-python-modules 작업 인수를 사용하여 Python 종속성을 관리할 수 있습니다. 이 인수를 사용하면 종속성 관리를 보다 철저하게 수행할 수 있습니다. 이 파라미터는 Amazon Linux 2와 호환되는 기본 코드 바인딩이 있는 종속성을 포함하여 Wheel 스타일 종속성을 지원합니다.
Scala
--extra-jars 작업 인수를 추가 Scala 종속성에 제공할 수 있습니다. 종속성은 Amazon S3에서 호스팅되어야 하며, 인수 값은 공백 없이 쉼표로 구분된 Amazon S3 경로 목록이어야 합니다. 종속성을 호스팅하고 구성하기 전에 다시 번들링하여 구성을 관리하는 것이 더 쉬울 수 있습니다. AWS Glue JAR 종속성에는 모든 JVM 언어에서 생성될 수 있는 Java 바이트 코드가 포함됩니다. Java와 같은 다른 JVM 언어를 사용하여 사용자 정의 종속성을 작성할 수 있습니다.
데이터 소스 자격 증명 관리
기존 Spark 프로그램에는 데이터 소스에서 데이터를 가져오기 위한 복잡한 구성 또는 사용자 정의 구성이 제공될 수 있습니다. 일반적인 데이터 소스 인증 흐름은 AWS Glue 연결에서 지원됩니다. AWS Glue 연결에 대한 자세한 정보는 데이터에 연결 섹션을 참조하세요.
AWS Glue 연결은 라이브러리에 대한 메서드 호출 및 AWS 콘솔에서 추가 네트워크 연결(Additional network connection) 설정과 같은 두 가지 기본 방법으로 작업을 다양한 유형의 데이터 저장소에 쉽게 연결할 수 있도록 합니다. 작업 내에서 AWS SDK를 호출하여 연결에서 정보를 검색할 수도 있습니다.
메서드 호출(Method calls) – AWS Glue 연결은 데이터 세트 에 대한 정보를 큐레이팅할 수 있는 서비스인 AWS Glue Data Catalog와 밀접히 통합되며, AWS Glue 연결과 상호 작용할 수 있는 메서드가 그것을 반영합니다. 재사용하려는 기존 인증 구성이 있으면 JDBC 연결의 경우 GlueContext의 extract_jdbc_conf 메서드를 통해 AWS Glue 연결 구성에 액세스할 수 있습니다. 자세한 정보는 extract_jdbc_conf 섹션을 참조하세요.
콘솔 구성(Console configuration) – AWS Glue 작업은 관련된 AWS Glue 연결을 사용하여 Amazon VPC 서브넷에 대한 연결을 구성할 수 있습니다. 보안 자료를 직접 관리하는 경우 라우팅을 구성하는 AWS 콘솔에서 NETWORK 유형의 추가 네트워크 연결(Additional network connection)을 제공해야 할 수 있습니다. AWS Glue 연결에 대한 자세한 정보는 연결 API 섹션을 참조하세요.
Spark 프로그램에 사용자 지정 또는 일반적이지 않은 인증 흐름이 있는 경우 보안 자료를 직접 관리해야 할 수 있습니다. AWS Glue 연결이 적합하지 않은 것 같은 경우 Secrets Manager에서 보안 자료를 안전하게 호스팅하고 작업에서 제공되는 boto3 또는 AWS SDK를 통해 해당 자료에 액세스 할 수 있습니다.
Apache Spark 구성
복잡한 마이그레이션은 Spark 구성을 변경하여 워크로드를 수용하는 경우가 많습니다. 최신 버전의 Apache Spark를 사용하면 런타임 구성을 SparkSession으로 설정할 수 있습니다. AWS Glue 3.0+ 작업에 런타임 구성을 설정하기 위해 수정할 수 있는 SparkSession이 제공됩니다. Apache Spark 구성
사용자 지정 구성 설정
마이그레이션된 Spark 프로그램은 사용자 지정 구성을 사용하도록 설계될 수 있습니다. AWS Glue에서는 작업 인수를 통해 작업 및 작업 실행 수준에서 구성을 설정할 수 있습니다. 작업 인수에 대한 자세한 정보는 AWS Glue 작업에서 작업 파라미터 사용 섹션을 참조하세요. 라이브러리를 통해 작업 컨텍스트 내에서 작업 인수에 액세스할 수 있습니다. AWS Glue에서는 유틸리티 함수를 제공하여 작업에 설정된 인수와 작업 실행 시 설정된 인수 간에 일관된 보기를 유지합니다. Python의 getResolvedOptions를 사용한 파라미터 액세스 섹션 및 Scala의 AWS Glue Scala GlueArgParser API 섹션을 참조하세요.
Java 코드 마이그레이션
타사 라이브러리 포함에서 설명한 대로 종속성에는 Java 또는 Scala와 같은 JVM 언어로 생성된 클래스가 포함될 수 있습니다. 종속성에는 main 메서드가 포함될 수 있습니다. 종속성의 main 메소드를 AWS Glue Scala 작업에 대한 진입점으로 사용할 수 있습니다. 이를 통해 Java의 main 메서드를 작성하거나 자체 라이브러리 표준에 맞게 패키징된 main 메서드를 재사용할 수 있습니다.
종속성에서 main 메서드를 사용하려면 다음을 수행합니다. 기본 GlueApp 객체를 제공하는 편집 창의 내용을 삭제합니다. 종속성에 있는 클래스의 정규화된 이름을 키 --class를 통해 작업 인수로 제공합니다. 그러면 작업 실행을 트리거할 수 있습니다.
인수 AWS Glue의 순서나 구조가 main 메서드에 전달되도록 구성할 수 없습니다. 기존 코드에서 AWS Glue에 설정된 구성을 읽어야 하는 경우 이전 코드와 호환되지 않을 수 있습니다. getResolvedOptions를 사용하는 경우 이 메소드를 호출하기에 적합한 장소도 없을 것입니다. AWS Glue에 의해 생성된 기본 메서드에서 직접 종속성을 호출하는 것이 좋습니다. 이에 대한 예는 다음 AWS Glue ETL 스트립트에 표시됩니다.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
