기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
처리 단계
Amazon Textract는 다운스트림 애플리케이션에서 직접 사용할 수 없는 문자열로 PDF 파일 콘텐츠를 추출합니다(예: 숫자를 집계하여 통계 생성). 다운스트림 애플리케이션에서 보다 쉽게 사용할 수 있으므로(예: 비용 추세를 시계열로 표시하기 위해) 올바르게 식별되고 변환된 데이터 값이 필요합니다. PDF 파일 처리를 구현하려면 Amazon Textract를 통해 각 새 PDF 파일 유형에서 하나의 PDF 파일을 한 번 처리해야 합니다. 그러면 JSON 형식Template의 파일이 생성됩니다.
에서 AWS Lambda 함수가 시작되면 다음 다이어그램에 표시된 단계를 수집 단계실행합니다.
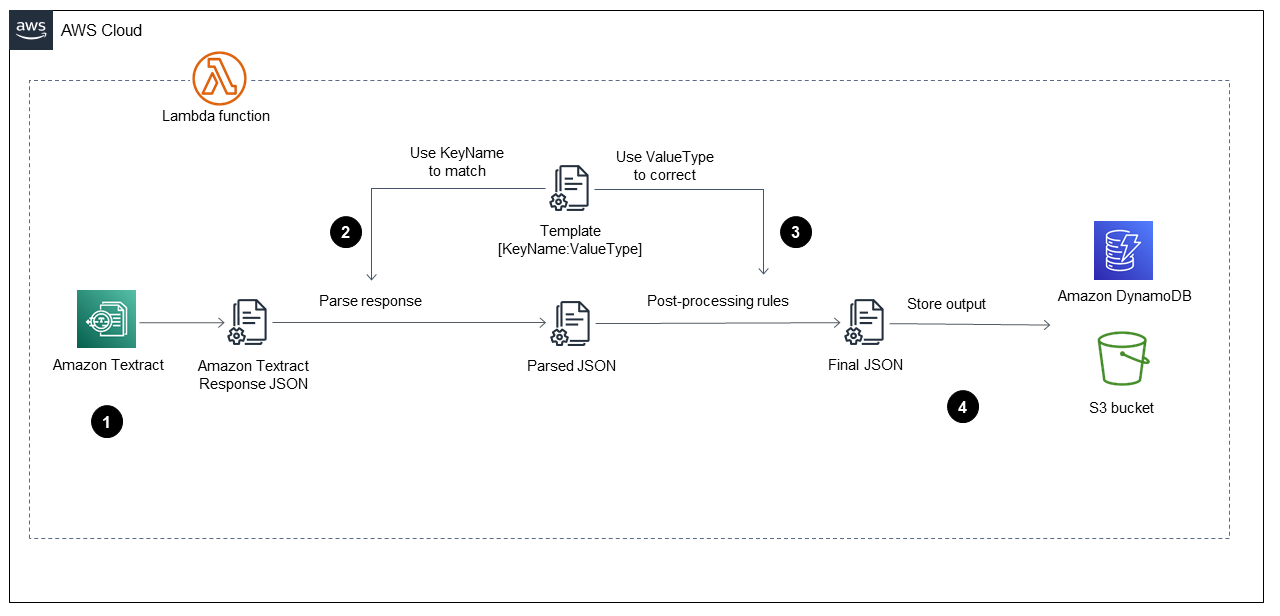
다이어그램은 다음 단계를 구현하는 Lambda 함수를 보여줍니다.
-
Amazon Textract를 호출하여 PDF 파일을 처리하고, 콘텐츠를 추출하고, JSON 형식의 파일을 반환합니다.
-
JSON 파일을 가져와서 각 필드에 대해 올바른 키 이름과 값 유형을 가진 사전 정의된
TemplateJSON 파일을 사용하여 양식과 테이블을 구문 분석합니다. 이 프로세스는 구문 분석된 JSON 파일을 제공합니다. -
사후 처리 규칙을 적용하고
TemplateJSON 파일을 사용하여 구문 분석된 JSON 파일의 각 값을 수정합니다. 그러면FinalJSON 파일이 생성됩니다. 사전 정의된TemplateJSON 파일은 S3 버킷에 저장할 수 있습니다. -
Amazon DynamoDB에
FinalJSON 파일을 S3 출력 버킷의 각 PDF 파일에 대해 하나의 JSON 파일 외에도 각 PDF 파일에 대해 하나의 레코드로 저장합니다.
Amazon Textract를 사용하여 PDF 파일에서 콘텐츠를 자동으로 추출하고 깨끗한 출력으로 처리하는 step-by-step 워크플로는 AWS 권장 가이드 웹 사이트의 Amazon Textract를 사용하여 PDF 파일에서 콘텐츠를 자동으로 추출하는 패턴을 참조하세요. 이 패턴은 템플릿 매칭 기법을 사용하여 필수 필드, 키 이름 및 테이블을 정확하게 식별한 후 각 데이터 유형에 사후 처리 수정 사항을 적용합니다.
처리 단계의 모범 사례
다음 네 가지 모범 사례를 사용하여 성공적인 처리 단계를 보장합니다.
-
처리하려는 각 PDF 파일 유형에 대해 템플릿 JSON 파일을 생성합니다. Lambda 함수에서 호출하는 S3 버킷에 이러한 다양한 템플릿 JSON 파일을 저장할 수 있습니다. 하나의 Lambda 함수에서 서로 다른 PDF 파일 유형을 처리하려면 각 PDF 파일 유형에 고유한 식별자(예: S3 버킷의 PDF 파일 유형 폴더 이름)를 사용해야 합니다. Lambda 함수가 호출되면 적절한 템플릿 JSON 파일을 검색하여 처리합니다.
-
Lambda 함수에서 각 단계의 상태를 정확하게 추적하는 메커니즘을 설정합니다. 예를 들어 Amazon Textract 호출 후, 최종 JSON 파일이 Amazon DynamoDB 테이블에 저장되는 경우 또는 PDF 파일이 S3 버킷에 저장되는 경우의
Success상태를 추가할 수 있습니다. 또한 별도의 DynamoDB 테이블을 생성하여 여러 단계에서 각 PDF 파일의 상태를 추적하여 프로세스에 대한 가시성을 제공할 수 있습니다. -
많은 PDF 파일을 일괄 처리할 때 실패한 작업을 자동으로 재시도하여 제한 및 삭제된 연결을 관리합니다. 연결이 끊어지거나 초당 최대 트랜잭션 수(TPS)를 초과하는 경우 Amazon Textract에서 제한이 발생할 수 있습니다. 실패한 작업을 자동으로 재시도하는 자세한 내용과 단계는 Amazon Textract 설명서의 제한된 호출 및 삭제된 연결 처리를 참조하세요.
-
여러 페이지가 있는 PDF 파일이 있는 경우 비동기 작업을 사용하여 전체 파일을 처리하거나 PDF 파일을 개별 페이지로 나누고 동기 작업을 사용하여 각 페이지를 처리한 다음 각 페이지의 결과를 결합할 수 있습니다. 비동기 작업의 전체 코드 구현은 Amazon Textract 설명서의 여러 페이지 문서에서 텍스트 감지 및 분석을 참조하세요. 동기식 작업 사용에 대한 자세한 내용은 Amazon Textract 설명서의 단일 페이지 문서에서 텍스트 감지 및 분석을 참조하세요.
