기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Aurora PostgreSQL 및 Amazon RDS for PostgreSQLPostgreSQL 연결 배열 에뮬레이션
Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada, Sachin Khanna, Amazon Web Services
요약
이 패턴은 Amazon Aurora PostgreSQL
Oracle 데이터베이스를 마이그레이션할 때 빈 인덱스 위치를 처리하는 aws_oracle_ext 함수를 사용하는 대신 PostgreSQL 대안을 제공합니다. 이 패턴은 추가 열을 사용하여 인덱스 위치를 저장하고 기본 PostgreSQL 기능을 통합하면서 Oracle의 희소 배열 처리를 유지합니다.
Oracle
Oracle에서는 배열에 NULL 요소를 추가하는 수집 방법을 사용하여 EXTEND 컬렉션을 빈 것으로 초기화하고 채울 수 있습니다. 로 인덱싱된 PL/SQL 연결 배열로 작업할 때 EXTEND 메서드PLS_INTEGER는 NULL 요소를 순차적으로 추가하지만 요소는 비순차 인덱스 위치에서 초기화할 수도 있습니다. 명시적으로 초기화되지 않은 인덱스 위치는 비어 있습니다.
이러한 유연성을 통해 임의의 위치에 요소를 채울 수 있는 희소 배열 구조가 가능합니다. FIRST 및 LAST 경계FOR LOOP가 있는를 사용하여 컬렉션을 반복할 때 초기화된 요소(NULL또는 정의된 값이 있는 요소)만 처리되고 빈 위치는 건너뜁니다.
PostgreSQL(Amazon Aurora 및 Amazon RDS)
PostgreSQL은 빈 값을 NULL 값과 다르게 처리합니다. 빈 값은 1바이트의 스토리지를 사용하는 개별 엔터티로 저장됩니다. 배열에 빈 값이 있는 경우 PostgreSQL은 비어 있지 않은 값과 마찬가지로 순차적 인덱스 위치를 할당합니다. 그러나 시스템이 빈 위치를 포함하여 인덱싱된 모든 위치를 반복해야 하므로 순차 인덱싱에는 추가 처리가 필요합니다. 따라서 희소 데이터 세트에는 기존 배열 생성이 비효율적입니다.
AWS Schema Conversion Tool
AWS Schema Conversion Tool (AWS SCT)는 일반적으로 aws_oracle_ext 함수Oracle-to-PostgreSQL 마이그레이션을 처리합니다. 이 패턴에서는 PostgreSQL 배열 유형을 인덱스 위치를 저장하기 위한 추가 열과 결합하는 기본 PostgreSQL 기능을 사용하는 대체 접근 방식을 제안합니다. 그런 다음 시스템은 인덱스 열만 사용하여 배열을 반복할 수 있습니다.
사전 조건 및 제한 사항
사전 조건
활성. AWS 계정
관리자 권한이 있는 AWS Identity and Access Management (IAM) 사용자.
Amazon RDS 또는 Aurora PostgreSQL과 호환되는 인스턴스입니다.
관계형 데이터베이스에 대한 기본적인 이해.
제한 사항
일부 AWS 서비스 는 전혀 사용할 수 없습니다 AWS 리전. 리전 가용성은 AWS 서비스 리전별
섹션을 참조하세요. 특정 엔드포인트는 서비스 엔드포인트 및 할당량 페이지를 참조하고 서비스 링크를 선택합니다.
제품 버전
이 패턴은 다음 버전으로 테스트되었습니다.
Amazon Aurora PostgreSQL 13.3
Amazon RDS for PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
아키텍처
소스 기술 스택
온프레미스 Oracle 데이터베이스
대상 기술 스택
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
대상 아키텍처
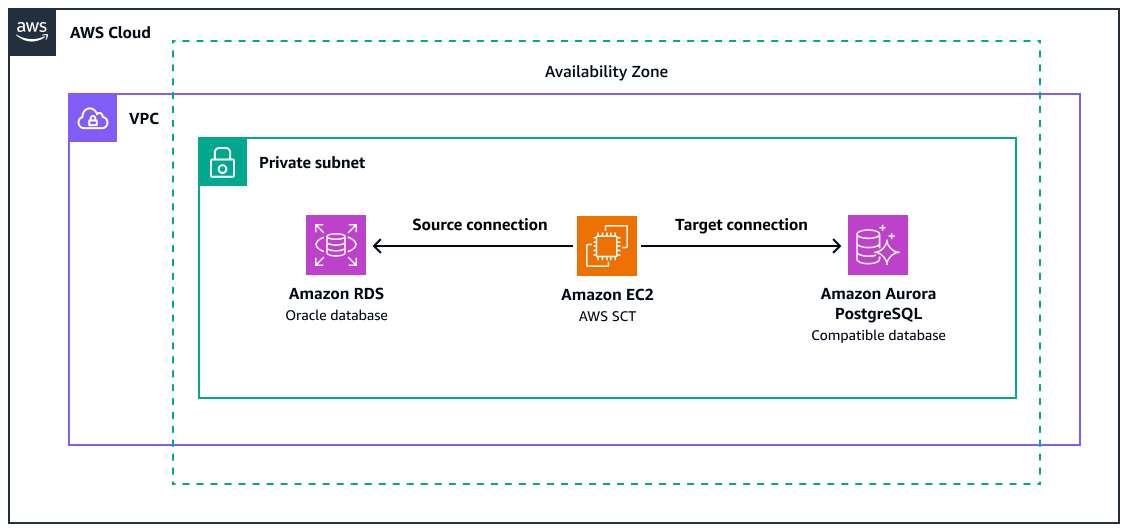
이 다이어그램은 다음을 보여 줍니다.
소스 Amazon RDS for Oracle 데이터베이스 인스턴스
Oracle 함수를 PostgreSQL로 변환하기 AWS SCT 위한가 있는 Amazon EC2 인스턴스
Amazon Aurora PostgreSQL과 호환되는 대상 데이터베이스
도구
서비스
Amazon Aurora는 클라우드용으로 구축되었으며 MySQL 및 PostgreSQL과 호환되는 완전 관리형 관계형 데이터베이스 엔진입니다.
Amazon Aurora PostgreSQL 호환 버전은 PostgreSQL 배포를 설정, 운영 및 확장할 수 있고 ACID를 준수하는 완전 관리형 관계형 데이터베이스 엔진입니다.
Amazon Elastic Compute Cloud(Amazon EC2)는 AWS 클라우드에서 확장 가능한 컴퓨팅 용량을 제공합니다. 필요한 만큼 가상 서버를 시작하고 빠르게 스케일 업하거나 스케일 다운할 수 있습니다.
Amazon Relational Database Service(RDS)를 사용하면에서 관계형 데이터베이스를 설정, 운영 및 확장할 수 있습니다 AWS 클라우드.
Amazon Relational Database Service(RDS) for Oracle은에서 Oracle 관계형 데이터베이스를 설정, 운영 및 확장하는 데 도움이 됩니다 AWS 클라우드.
Amazon Relational Database Service(RDS) for PostgreSQL은에서 PostgreSQL 관계형 데이터베이스를 설정, 운영 및 확장하는 데 도움이 됩니다 AWS 클라우드.
AWS Schema Conversion Tool (AWS SCT)는 소스 데이터베이스 스키마와 대부분의 사용자 지정 코드를 대상 데이터베이스와 호환되는 형식으로 자동 변환하여 이기종 데이터베이스 마이그레이션을 지원합니다.
기타 도구
Oracle SQL Developer
는 기존 배포와 클라우드 기반 배포 모두에서 Oracle 데이터베이스의 개발 및 관리를 간소화하는 통합 개발 환경입니다. pgAdmin
은 PostgreSQL을 위한 오픈 소스 관리 도구입니다. 데이터베이스 객체를 생성, 유지 관리 및 사용하는 데 도움이 되는 그래픽 인터페이스를 제공합니다. 이 패턴에서 pgAdmin은 RDS for PostgreSQL 데이터베이스 인스턴스에 연결하고 데이터를 쿼리합니다. 또는 psql 명령줄 클라이언트를 사용할 수 있습니다.
모범 사례
데이터 세트 경계 및 엣지 시나리오를 테스트합니다.
out-of-bounds 것이 좋습니다.
희소 데이터 세트를 스캔하지 않도록 쿼리를 최적화합니다.
에픽
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
Oracle에서 소스 PL/SQL 블록을 생성합니다. | Oracle에서 다음 연결 배열을 사용하는 소스 PL/SQL 블록을 생성합니다.
| DBA |
PL/SQL 블록을 실행합니다. | Oracle에서 소스 PL/SQL 블록을 실행합니다. 연결 배열의 인덱스 값 사이에 간격이 있는 경우 해당 간격에 데이터가 저장되지 않습니다. 이렇게 하면 Oracle 루프가 인덱스 위치를 통해서만 반복할 수 있습니다. | DBA |
출력 결과를 검토합니다. | 5개의 요소가 비연속 간격으로 배열(
| DBA |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
PostgreSQL에서 대상 PL/pgSQL 블록을 생성합니다. PostgreSQL | PostgreSQL에서 다음 연결 배열을 사용하는 대상 PL/pgSQL PostgreSQL 블록을 생성합니다.
| DBA |
PL/pgSQL 블록을 실행합니다. | PostgreSQL에서 대상 PL/pgSQL 블록을 실행합니다. PostgreSQL 연결 배열의 인덱스 값 사이에 간격이 있는 경우 해당 간격에 데이터가 저장되지 않습니다. 이렇게 하면 Oracle 루프가 인덱스 위치를 통해서만 반복할 수 있습니다. | DBA |
출력 결과를 검토합니다. | 는 인덱스 위치 사이의 간격에
| DBA |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
배열 및 사용자 정의 유형을 사용하여 대상 PL/pgSQL 블록을 생성합니다. | 성능을 최적화하고 Oracle의 기능과 일치시키기 위해 인덱스 위치와 해당 데이터를 모두 저장하는 사용자 정의 유형을 생성할 수 있습니다. 이 접근 방식은 인덱스와 값 간의 직접 연결을 유지하여 불필요한 반복을 줄입니다.
| DBA |
PL/pgSQL 블록을 실행합니다. | 대상 PL/pgSQL 블록을 실행합니다. 연결 배열의 인덱스 값 사이에 간격이 있는 경우 해당 간격에 데이터가 저장되지 않습니다. 이렇게 하면 Oracle 루프가 인덱스 위치를 통해서만 반복할 수 있습니다. | DBA |
출력 결과를 검토합니다. | 다음 출력과 같이 사용자 정의 유형은 채워진 데이터 요소만 저장합니다. 즉, 배열 길이는 값 수와 일치합니다. 따라서 기존 데이터만 처리하도록
| DBA |
관련 리소스
AWS 설명서
기타 설명서
