기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Redshift에서 SQL 쿼리 처리
Amazon Redshift는 제출된 SQL 쿼리를 구문 분석기와 옵티마이저를 통해 라우팅하여 쿼리 계획을 작성합니다. 그러면 실행 엔진이 쿼리 계획을 코드로 변환한 후 해당 코드를 실행할 수 있도록 컴퓨팅 노드로 전송합니다. 쿼리 계획을 설계하기 전에 쿼리 처리의 작동 방식을 이해하는 것이 중요합니다.
쿼리 계획 및 실행 워크플로우
다음 다이어그램은 쿼리 계획 및 실행 워크플로를 전체적으로 보여줍니다.
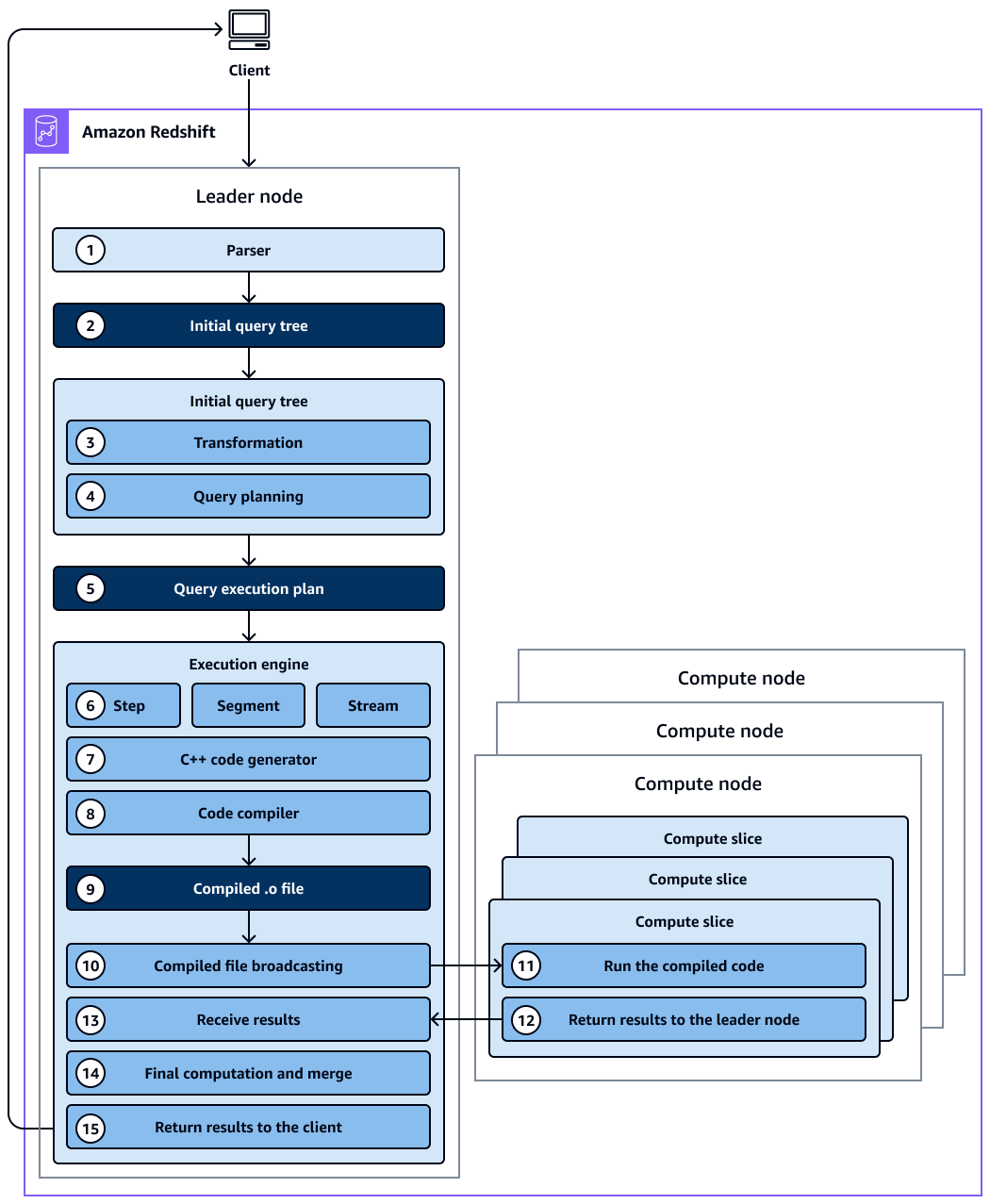
이 다이어그램은 다음 워크플로를 보여줍니다.
-
Amazon Redshift 클러스터의 리더 노드는 쿼리를 수신하고 SQL 문을 구문 분석합니다.
-
구문 분석기는 원본 쿼리의 논리적 표현인 초기 쿼리 트리를 생성합니다.
-
쿼리 최적화 프로그램은 초기 쿼리 트리를 가져와서 평가하고, 테이블 통계를 분석하여 조인 순서를 결정하고, 선택도를 조건부로 지정하고, 필요한 경우 쿼리를 다시 작성하여 효율성을 극대화합니다. 경우에 따라 단일 쿼리를 백그라운드에 여러 종속 문으로 쓸 수 있습니다.
-
옵티마이저가 성능을 극대화하는 쿼리 실행 계획(이전 단계에서 다수의 쿼리를 생성한 경우에는 쿼리 실행 계획들)을 작성합니다. 쿼리 계획은 실행 순서, 네트워크 작업, 조인 유형, 조인 순서, 집계 옵션 및 데이터 배포와 같은 실행 옵션을 지정합니다.
-
쿼리 계획에는 쿼리를 실행하는 데 필요한 개별 작업에 대한 정보가 포함되어 있습니다.
EXPLAIN명령을 사용하면 쿼리 계획을 확인할 수 있습니다. 쿼리 계획은 복합 쿼리를 분석하여 튜닝할 수 있는 기본 도구입니다. -
쿼리 최적화 프로그램은 쿼리 계획을 실행 엔진으로 전송합니다. 실행 엔진은 컴파일된 계획 캐시에서 쿼리 계획 일치를 확인하고 컴파일된 캐시(찾은 경우)를 사용합니다. 그렇지 않으면 실행 엔진이 쿼리 계획을 단계, 세그먼트 및 스트림으로 변환합니다.
-
단계는 쿼리 실행 중에 발생하는 개별 작업입니다. 단계는 레이블(예: ,
scan,disthjoin또는merge)로 식별됩니다. 단계는 가장 작은 단위입니다. 컴퓨팅 노드가 쿼리, 조인 또는 다른 데이터베이스 작업을 수행할 수 있도록 단계를 결합할 수 있습니다. -
세그먼트는 쿼리의 세그먼트를 가리키며 단일 프로세스로 수행할 수 있는 여러 단계를 결합합니다. 세그먼트는 컴퓨팅 노드 조각에서 가장 작은 컴파일 단위 실행 파일입니다. 여기서 조각이란 Amazon Redshift의 병렬 처리 유닛을 말합니다.
-
스트림은 사용 가능한 컴퓨팅 노드 조각을 통해 파셀 아웃할 세그먼트 모음입니다. 스트림의 세그먼트는 노드 조각 간에 병렬로 실행됩니다. 따라서 동일한 세그먼트의 동일한 단계가 여러 조각에서 병렬로 실행됩니다.
-
-
코드 생성기는 변환된 계획을 수신하고 각 세그먼트에 대해 C++ 함수를 생성합니다.
-
생성된 C++ 함수는 GNU 컴파일러 컬렉션에 의해 컴파일되고 O(
.o) 파일로 변환됩니다. -
컴파일된 코드(O 파일)가 실행됩니다. 컴파일 코드는 인터프리터 코드보다 실행 속도가 빠르고 사용하는 컴퓨팅 용량도 적습니다.
-
그런 다음 컴파일된 O 파일이 컴퓨팅 노드로 브로드캐스팅됩니다.
-
각 컴퓨팅 노드는 여러 컴퓨팅 조각으로 구성됩니다. 컴퓨팅 조각은 쿼리 세그먼트를 병렬로 실행합니다. Amazon Redshift는 최적화된 네트워크 통신, 메모리 및 디스크 관리를 활용하여 한 쿼리 계획 단계에서 다음 쿼리 계획 단계로 중간 결과를 전달합니다. 또한 쿼리 실행 속도를 높이는 데도 도움이 됩니다. 다음을 고려하세요.
-
6, 7, 8, 9, 10, 11단계는 각 스트림에 대해 한 번 발생합니다.
-
엔진은 한 스트림에 대한 실행 세그먼트를 생성하고 이러한 세그먼트를 컴퓨팅 노드로 보냅니다.
-
이전 스트림의 세그먼트가 완료되면 엔진은 다음 스트림에 대한 세그먼트를 생성합니다. 이러한 방식으로 엔진은 이전 스트림의 작업 내용(작업의 디스크 기반 여부 등)을 분석하여 다음 스트림의 세그먼트 생성에도 영향을 미칩니다.
-
-
컴퓨팅 노드가 완료되면 최종 처리를 위해 쿼리 결과를 리더 노드로 반환합니다. 리더 노드는 데이터를 단일 결과 세트로 병합하고 필요한 정렬 또는 집계를 처리합니다.
-
리더 노드는 클라이언트에 결과를 반환합니다.
다음 다이어그램은 스트림, 세그먼트, 단계 및 컴퓨팅 노드 조각의 실행 워크플로를 보여줍니다. 다음 사항에 유의하세요.
-
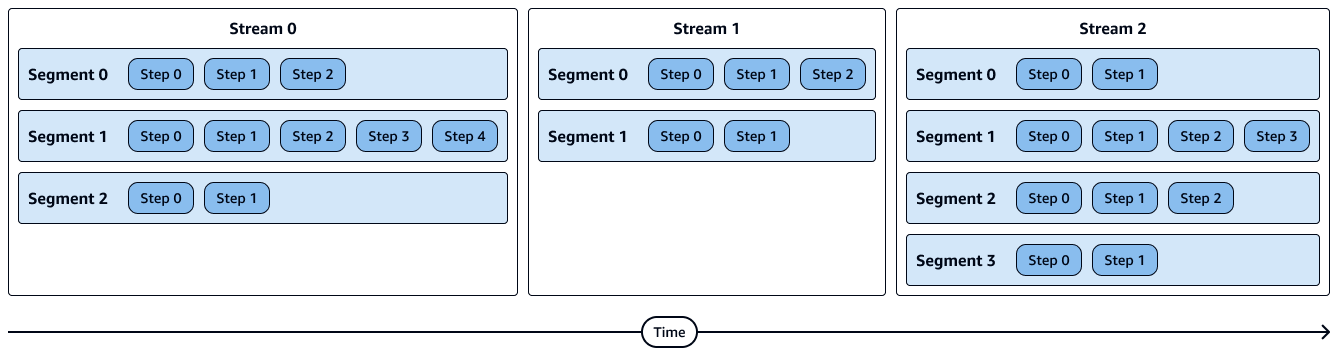
세그먼트의 단계는 순차적으로 실행됩니다.
-
스트림의 세그먼트는 병렬로 실행됩니다.
-
스트림은 순차적으로 실행됩니다.
-
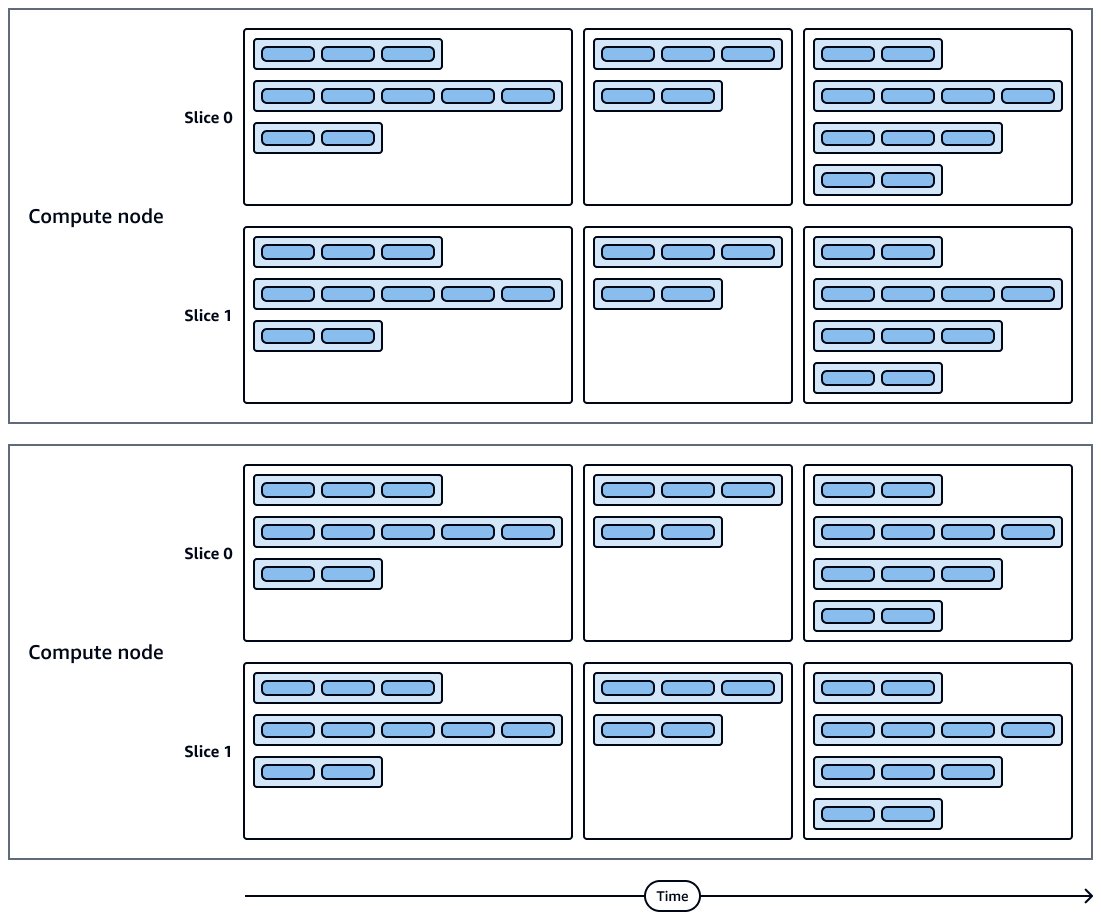
컴퓨팅 노드 조각은 병렬로 실행됩니다.
다음 다이어그램은 스트림, 세그먼트 및 단계의 시각적 표현을 보여줍니다. 각 세그먼트에는 여러 단계가 포함되며 각 스트림에는 여러 세그먼트가 포함됩니다.
다음 다이어그램은 쿼리 실행 및 컴퓨팅 노드 조각의 시각적 표현을 보여줍니다. 각 컴퓨팅 노드에는 여러 조각, 스트림, 세그먼트 및 단계가 포함되어 있습니다.
추가 고려 사항
쿼리 처리와 관련하여 다음을 고려하는 것이 좋습니다.
-
캐싱된 컴파일된 코드는 동일한 클러스터의 세션 간에 공유되므로 동일한 쿼리의 후속 실행이 더 빠르며, 종종 파라미터가 다르더라도 더 빠릅니다.
-
쿼리를 벤치마킹할 때 첫 번째 실행 시간에는 코드 컴파일 오버헤드가 포함되므로 항상 쿼리의 두 번째 실행 시간을 비교하는 것이 좋습니다. 자세한 내용은 Amazon Redshift에 대한 쿼리 모범 사례 가이드의 쿼리 성능 요소를 참조하세요.
-
필요한 경우 컴퓨팅 노드는 쿼리 실행 중에 리더 노드에 일부 데이터를 반환할 수 있습니다. 예를 들어
LIMIT절이 있는 하위 쿼리가 있는 경우 추가 처리를 위해 클러스터 전체에 데이터를 재배포하기 전에 리더 노드에 제한이 적용됩니다.
