기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker AI를 사용한 기계 학습 개요
이 섹션에서는 일반적인 기계 학습(ML) 워크플로와 Amazon SageMaker AI를 사용하여 이러한 작업을 수행하는 방법을 설명합니다.
기계 학습에서는 컴퓨터를 교육하여 예측, 이른바 추론을 만들어냅니다. 우선 알고리즘과 예제 데이터를 사용하여 모델을 훈련합니다. 그런 다음 모델을 애플리케이션에 통합하여 실시간으로 규모에 따라 추론을 생성합니다.
다음 다이어그램은 ML 모델을 생성하기 위한 일반적인 워크플로를 보여줍니다. 여기에는 다이어그램을 진행하는 방법에 대해 자세히 설명하는 순환 흐름의 세 단계가 포함됩니다.
-
예제 데이터 생성
-
모델 훈련
-
모델 배포
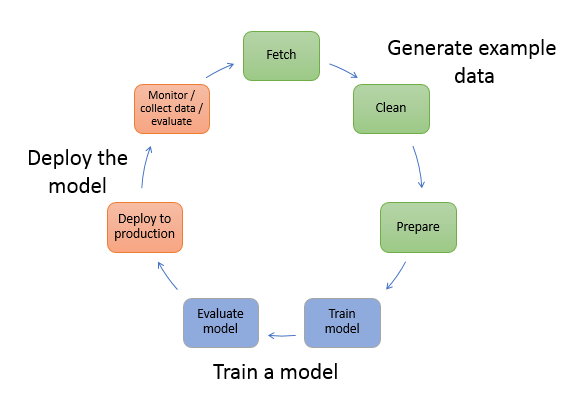
다이어그램은 대부분의 일반적인 시나리오에서 다음 작업을 수행하는 방법을 보여줍니다.
-
예제 데이터 생성 – 모델을 훈련시키려면 예제 데이터가 필요합니다. 필요한 데이터의 유형은 모델을 사용하여 해결하고자 하는 비즈니스 문제에 따라 다릅니다. 이는 모델을 생성하려는 추론과 관련이 있습니다. 예를 들어, 손으로 쓴 숫자의 입력 이미지를 고려하여 숫자를 예측하는 모델을 생성하려고 합니다. 이 모델을 훈련하려면 수기 숫자의 예제 이미지가 필요합니다.
데이터 과학자는 모델 훈련에 사용하기 전에 예제 데이터를 찾고 사전 처리하는 시간을 할애합니다. 데이터를 사전 처리하려면 일반적으로 다음을 수행합니다.
-
데이터 가져오기 - 사내 예제 데이터 리포지토리를 보유하거나 공개적으로 사용 가능한 데이터세트를 사용할 수 있습니다. 일반적으로 데이터세트를 단일 리포지토리로 끌어옵니다.
-
데이터 정리 - 모델 훈련을 개선하려면 데이터를 검사하고 필요에 따라 정리합니다. 예를 들어 데이터의
country name속성의 값이United States및US인 경우 데이터를 일관적인 것으로 편집할 수 있습니다. -
데이터 준비 또는 변환 - 성능을 개선하기 위해 추가 데이터 변환을 수행할 수 있습니다. 예를 들어, 항공기의 제빙이 필요한 조건을 예측하는 모델의 속성을 결합하도록 선택할 수 있습니다. 온도 및 습도 속성을 별도로 사용하는 대신 이러한 속성을 새 속성으로 결합하여 더 나은 모델을 얻을 수 있습니다.
SageMaker AI에서는 통합 개발 환경(IDE)에서 SageMaker Python SDK와 함께 SageMaker APIs를 사용하여 예제 데이터를 사전 처리할 수 있습니다. SageMaker
SDK for Python(Boto3)을 사용하면 모델 훈련을 위한 데이터를 가져오고 탐색하고 준비할 수 있습니다. 데이터 준비, 처리 및 변환에 대한 자세한 내용은 SageMaker AI에서 올바른 데이터 준비 도구를 선택하기 위한 권장 사항, SageMaker Processing을 사용한 데이터 변환 워크로드 및 Feature Store로 특성 만들기, 저장 및 공유 섹션을 참조하세요. -
-
모델 훈련 - 모델 훈련에는 다음과 같은 모델 훈련 및 평가가 모두 포함됩니다.
-
모델 훈련 - 모델을 훈련시키려면 알고리즘이나 사전 훈련된 기본 모델이 필요합니다. 선택하는 알고리즘은 요인의 수에 따라 다릅니다. 기본 제공 솔루션의 경우 SageMaker가 제공하는 알고리즘 중 하나를 사용할 수 있습니다. SageMaker가 제공하는 알고리즘 목록 및 관련 고려 사항은 Amazon SageMaker 기본 제공 알고리즘 또는 사전 훈련된 모델 사용을 참조하세요. 알고리즘과 모델을 제공하는 UI 기반 훈련 솔루션에 대한 내용은 SageMaker JumpStart 사전 훈련된 모델을 참조하세요.
또한 훈련용 컴퓨팅 리소스가 필요합니다. 리소스 사용은 훈련 데이터세트의 크기와 결과가 필요한 속도에 따라 달라집니다. 단일 범용 인스턴스에서 분산 GPU 인스턴스 클러스터에 이르는 리소스를 사용할 수 있습니다. 자세한 내용은 Amazon SageMaker를 사용한 모델 훈련 섹션을 참조하세요.
-
모델 평가 - 모델을 훈련시킨 후 모델을 평가하여 추론의 정확도가 허용 가능한지 여부를 결정합니다. 모델을 훈련하고 평가하려면 SageMaker Python SDK
를 사용하여 사용 가능한 IDEs 중 하나를 통해 추론에 대한 요청을 모델에 전송합니다. 모델 평가에 대한 자세한 내용은 Amazon SageMaker Model Monitor를 사용한 데이터 및 모델 품질 모니터링 항목을 참조하세요.
-
-
모델 배포 - 사용자는 일반적으로 모델을 애플리케이션과 통합하여 배포하기 전에 모델을 리엔지니어링합니다. SageMaker AI 호스팅 서비스를 사용하면 모델을 독립적으로 배포하여 애플리케이션 코드에서 분리할 수 있습니다. 자세한 내용은 추론 모델 배포 단원을 참조하십시오.
기계 학습은 연속적인 순환입니다. 모델 배포 이후 추론을 모니터링하고 양질의 데이터를 수집하고 모델을 평가하여 차이를 식별합니다. 그런 다음 새로 수집한 양질의 데이터를 포함하도록 훈련 데이터를 업데이트하여 추론의 정확도를 높입니다. 사용 가능한 예제 데이터가 증가함에 따라 모델을 다시 훈련하여 정확도를 높입니다.
