기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker Processing을 사용한 데이터 변환 워크로드
SageMaker Processing은 SageMaker AI의 완전관리형 인프라에서 데이터 사전 및 사후 처리, 특성 엔지니어링 및 모델 평가 작업을 실행하는 SageMaker AI의 기능을 말합니다. 이러한 작업은 처리 작업으로 실행됩니다. 다음은 SageMaker Processing에 대해 알아볼 수 있는 정보와 리소스를 제공합니다.
데이터 과학자는 SageMaker Processing API를 사용하여 스크립트와 노트북을 실행하여 데이터세트를 처리, 변환 및 분석하여 기계 학습을 준비할 수 있습니다. 훈련 및 호스팅과 같이 SageMaker AI에서 제공하는 다른 중요한 기계 학습 작업과 결합하면 Processing은 SageMaker AI에 내장된 모든 보안 및 규정 준수 지원을 포함하여 완전 관리형 기계 학습 환경의 이점을 제공합니다. 내장된 데이터 처리 컨테이너를 사용하거나 사용자 지정 처리 로직에 자체 컨테이너를 가져온 다음 SageMaker AI 관리형 인프라에서 실행할 작업을 제출할 수 있는 유연성이 있습니다.
참고
SageMaker AI에서 지원하는 모든 언어로 CreateProcessingJob API 작업을 호출하거나를 사용하여 프로그래밍 방식으로 처리 작업을 생성할 수 있습니다 AWS CLI. 이 API 작업이 선택한 언어의 함수로 변환되는 방식에 대한 자세한 내용은 CreateProcessingJob의 추가 참고 사항 섹션 및 SDK 선택을 참조하세요. 예를 들어 Python 사용자의 경우 SageMaker Python SDK의 Amazon SageMaker Processing
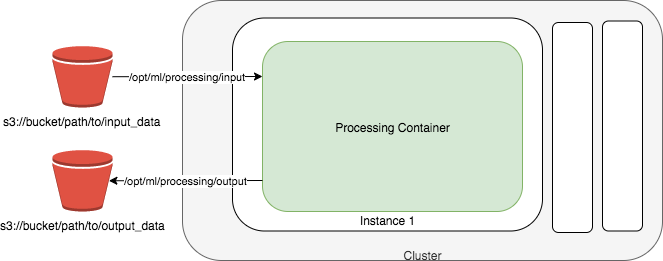
다음 다이어그램은 Amazon SageMaker AI가 처리 작업을 실행하는 방법을 보여줍니다. Amazon SageMaker AI는 스크립트를 가져와 Amazon Simple Storage Service(Amazon S3)에서 데이터를 복사한 다음 처리 컨테이너를 가져옵니다. 처리 작업의 기본 인프라는 Amazon SageMaker AI에서 완벽하게 관리됩니다. 처리 작업을 제출한 후 SageMaker AI는 컴퓨팅 인스턴스를 시작하고, 입력 데이터를 처리 및 분석하고, 완료 시 리소스를 릴리스합니다. 프로세싱 작업의 출력은 지정하는 Amazon S3 버킷에 저장됩니다.
참고
입력 데이터는 Amazon S3 버킷에 저장해야 합니다. 아니면, Amazon Athena 또는 Amazon Redshift를 입력 소스로 사용할 수 있습니다.
작은 정보
기계 학습(ML) 훈련 및 처리 작업의 분산형 컴퓨팅에 대한 일반적인 모범 사례를 알아보려면 SageMaker AI 모범 사례를 사용한 분산 컴퓨팅 섹션을 참고하세요.
Amazon SageMaker 프로세싱 샘플 노트북 사용
데이터 사전 처리, 모델 평가 또는 두 가지 모두를 수행하는 방법을 보여주는 2개의 샘플 Jupyter notebook을 제공합니다.
프로세싱용 SageMaker Python SDK를 사용하여 데이터 전처리 및 모델 훈련 및 평가를 수행하기 위해 scikit-learn 스크립트를 실행하는 방법을 보여주는 샘플 노트북은 scikit-learn 프로세싱
Amazon SageMaker Processing이 Spark를 사용하여 Spark에서 분산 데이터 사전 처리를 수행하는 방법을 보여 주는 샘플 노트북의 경우 분산 처리(Spark)
SageMaker AI에서 이러한 샘플을 실행하는 데 사용할 수 있는 Jupyter 노트북 인스턴스를 생성하고 액세스하는 방법에 대한 지침은 섹션을 참조하세요Amazon SageMaker 노트북 인스턴스. 노트북 인스턴스를 생성하고 연 후 SageMaker AI 예제 탭을 선택하여 모든 SageMaker AI 샘플 목록을 확인합니다. 노트북을 열려면 사용 탭을 선택한 후 사본 생성을 선택합니다.
CloudWatch 로그 및 지표를 사용하여 Amazon SageMaker 프로세싱 작업 모니터링하기
Amazon SageMaker 프로세싱은 프로세싱 작업을 모니터링하기 위해 Amazon CloudWatch 로그 및 지표를 제공합니다. CloudWatch는 CPU, GPU, 메모리, GPU 메모리, 디스크 지표, 이벤트 로깅을 제공합니다. 자세한 내용은 Amazon CloudWatch의 Amazon SageMaker AI 지표 Amazon CloudWatch 및 Amazon SageMaker AI용 CloudWatch Logs 섹션을 참조하세요.
