This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Launch AWS services needed to run a POC
The diagrams in preceding sections showed connectivity, data movement, user access, and license server access separately. The following figure brings those elements together, and adds Amazon EC2 instances used for the compute fleet and for design data. This environment is recommended for initial testing and POCs.
When launching services on AWS for your test or POC, you should be using repeatable
mechanisms. For example, AWS CloudFormation

Services needed to run a POC
Prior to building the environment shown in the preceding figure, you should be familiar with the compute, storage, file system, and network options recommended for semiconductor design workflows.
Amazon Elastic Compute Cloud (Amazon EC2)
Amazon Elastic Compute Cloud (Amazon EC2)
Amazon EC2 offers the broadest and deepest compute platform with choice of processor, storage, networking, operating system, and purchase model. We offer the fastest processors in the cloud and we are the only cloud with 400 Gbps ethernet networking. We have the most powerful GPU instances for machine learning training and graphics workloads, as well as the lowest cost-per-inference instances in the cloud.
Amazon EC2 instances use a hypervisor to divide resources on the server, so that each customer has separate CPU, memory, and storage resources for just that customer’s instance. The hypervisor is not used to share resources between instances, except for the T* instance type family. In current-generation instances, for example M6g, R6g, C5, and Z1d, these instances use a specialized piece of hardware and a highly customized hypervisor based on KVM. This hypervisor system is called the AWS Nitro System.
Although there are older instance types (not using the AWS Nitro System) that can run
your workflows, this guide focuses on current generation instance types that use the AWS Nitro System
Instance capabilities
Many of the Amazon EC2 instances have features that are specified in the name of the
instance family and type. For example, for the instance family R5
AWS Nitro System
The AWS Nitro System
Launching Nitro-based instances requires specific drivers for networking and storage be installed and enabled before the instance can be launched. Many operating systems that can run design workflows have the necessary drivers already installed and configured. The recommended operating systems in this guide will already have the necessary drivers installed and configured.
AWS Graviton powered instances
AWS Graviton processors
The Amazon EC2 instances M6g, C6g, R6g, and X2gd and their disk variants with local NVMe-based SSD storage deliver up to 40% better price/performance over comparable x86-based instances for a broad spectrum of workloads, including application servers, microservices, high-performance computing, CPU-based machine learning inference, electronic design automation, game applications, open-source databases, and in-memory caches. To optimize for price and performance, we suggest using AWS Graviton instances for tools and workloads that are compatible with the AWS Graviton processor. As of this writing, the primary EDA ISVs offer Arm versions of several of their tools. Contact your tool provider to learn which tools are available for AWS Graviton2-based instances.
Choice of instance types for semiconductor design
Although AWS has many different types and sizes of instances, the instance types in the compute-optimized and memory-optimized categories are typically best suited for chip design workloads.
Compute-Optimized instances
The compute-optimized instance family
The C6g, M6g, M5zn, Z1d, C5, and X2gd (and their disk variants) are appropriate for semiconductor design workloads. Typical EDA use cases for compute-optimized instance types include:
-
Digital, analog, and mixed-signal simulations
-
Physical synthesis
-
Formal verification
-
Regression tests
-
IP characterization
Memory-Optimized Instances
The memory-optimized instance family
You can choose from the R6g, Z1d, and R5 (and their disk variants) memory-optimized instances. Typical use cases for memory-optimized instance types:
-
Place and route
-
Timing and power analysis
-
Physical verification
-
Design rule checking (DRC)
-
Batch mode RTL simulation (multithread optimized tools)
The following table provides detailed information for the instance types and the corresponding design tools or infrastructure use case recommended for chip design workflows.
Note
AWS uses vCPU to denote processors or symmetric multi-threading. This table uses physical cores.
Table 3 – Instance types and corresponding design tools or infrastructure usage
| Name** | Max Physical Cores | Max RAM in GiB and (GiB/core) |
Local NVMe |
Design Tool or Application |
|---|---|---|---|---|
|
64 64 24 24 48 |
256 (4) 128 (2) 192 (8) 384 (16) 384 (8) |
Yes* Yes* No Yes Yes* |
Formal verification RTL Simulation Batch RTL Simulation Interactive RTL Gate Level Simulation Synthesis/Compilation Library Characterization |
|
|
64 48 |
512 (8) 768 (16) |
Yes* Yes* |
RTL Simulation Multi-Threaded Extraction DRC Optical Proximity Correction Library Characterization |
|
|
64 48 |
256 (4) 384 (16) |
Yes* Yes* |
Remote Desktop Sessions | |
|
C6g |
64 | 128 (2) | Yes* |
RTL Simulation Interactive RTL Gate Level Simulation |
|
C5 |
36 | 144 (4) | Yes* |
RTL Simulation Interactive RTL Gate Level Simulation |
| X2gd |
64 | 1,024 (16) | Yes* |
Place & Route Static Timing Analysis Full Chip Simulation Optical Proximity Correction |
|
64 |
3,904 (61) |
Yes* |
Place & Route Static Timing Analysis Full Chip Simulation |
* Supported on disk variant (e.g., M6gd, C5d, etc.)
** g - uses AWS Graviton Processors; z - higher clock frequency; n - enhanced networking of up to 100 Gbps
Hyper-Threading for EC2 instances with Intel Processor Technologies
Amazon EC2 instances with Intel processors support Intel Hyper-Threading Technology (HT Technology), which enables multiple threads to run concurrently on a single Intel CPU core. Each thread is represented as a virtual CPU (vCPU) on the instance. Each vCPU is a hyperthread of an Intel CPU core, except for T2 instances. To determine the physical cores, you divide the vCPU number by 2. If you determine that it has a negative impact on your application’s performance, you can disable HT Technology when you launch an instance using CPU Options (which is an EC2 feature).
CPU options (EC2 instance feature)
You can specify the following CPU options to optimize your instance:
-
Number of CPU cores – You can customize the number of CPU cores for the instance. This customization may optimize the licensing costs of your software with an instance that has sufficient amounts of RAM for memory-intensive workloads but fewer CPU cores.
-
Threads per core – For AWS Graviton powered instances, there is one thread per core. For instances with Intel processors, you can disable Intel Hyper-Threading Technology by specifying a single thread per CPU core. This scenario applies to certain workloads, such as high performance computing (HPC) workloads.
You can only specify the CPU options during instance launch (for running instances,
you can still disable multi-threading.) For details, see the Semiconductor Design on
AWS GitHub repository
AMI and operating system
AWS has built-in support for numerous operating systems. For semiconductor design, CentOS, Red Hat Enterprise Linux, and Amazon Linux 2 are used more than other operating systems. The operating system and the customizations that you have made in your on-premises environment are the baseline for building out your architecture on AWS. Before you can launch an EC2 instance, you must decide which Amazon Machine Image (AMI) to use. An AMI is used to boot EC2 instances, contains the OS, has any required OS and driver customizations, and may also include tools and applications. For EDA, one approach is to launch an instance from an existing AMI, customize the instance after launch, and then save this updated configuration as a custom AMI. Instances launched from this new custom AMI include the customizations that you made when you created the AMI.
The following figure shows the process of customizing an AMI.
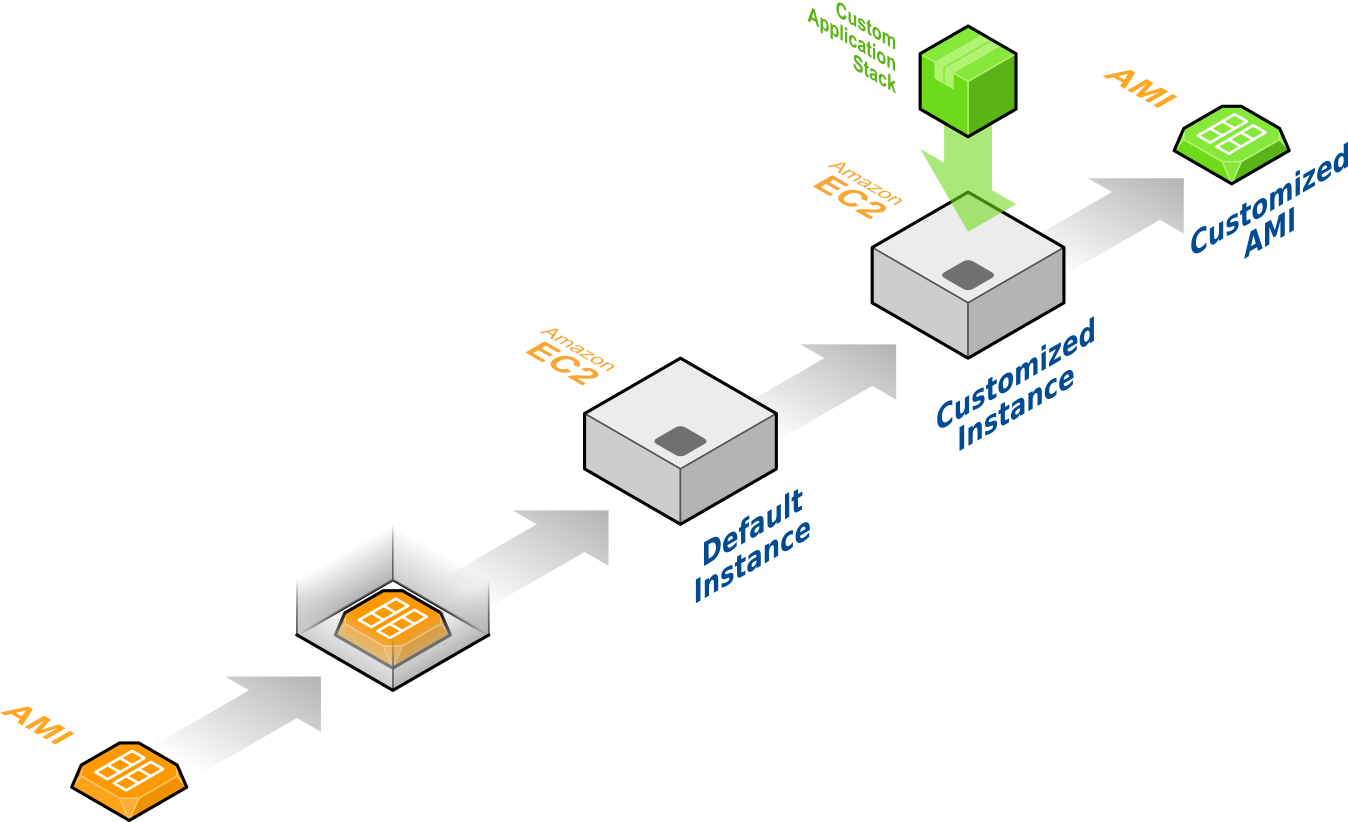
Use the Amazon provided AMI to build a customized AMI
You can select the AMI from the AWS Management Console or from the AWS Marketplace, and then customize that instance by installing your EDA tools and configuring the environment to match what is running on-premises. After that, you can use the customized instance to create a new, customized AMI that you can then use to launch your entire EDA environment on AWS. Note also that the customized AMI that you created can be further customized at instance launch. For example, you can customize the AMI to add additional application software, load additional libraries, or apply patches, each time the customized AMI is launched onto an EC2 instance (this is done using the User data option at instance launch).
As of this writing, we recommend these OS levels for tools, infrastructure, and file system support:
-
Amazon Linux 2 (verify certification with EDA tool vendors)
-
CentOS 7.5 or newer
-
Red Hat Enterprise Linux 7.5 or newer
-
SUSE Linux Enterprise Server 12 Service Pack 4 or newer
These OS levels have the necessary drivers already included to support the current
instance types, which include Nitro based instances. If you are not using one of these
levels, you may need to perform extra steps to take advantage of the features of our current
instances. Specifically, you may need to build and enable enhanced networking, and install
and configure the NVMe drivers. For detailed information on AMI drivers, see the Semiconductor Design on
AWS GitHub repository
You can import your own on-premises image to use for your AMI. This process includes
extra steps, but may result in time savings. Before importing an on-premises OS image, you
first build a virtual machine (VM) image for your OS. AWS supports certain VM formats (for
example, Linux VMs that use VMware ESX) that must be uploaded to an S3 bucket, and
subsequently converted into an AMI. For detailed information and instructions, see VM Import/Export
To verify that you can launch your AMI on a Nitro based instance, first launch the AMI
on a Xen based instance type (e.g., C4), and then run the NitroInstanceChecks
Network
Amazon enhanced networking technology enables instances to communicate at up to 100 Gbps and 25 Gbps for current-generation instances, and up to 10 Gbps for previous-generation instances. In addition, enhanced networking reduces latency and network jitter. The recommended AMIs in the previous section include the required Elastic Network Adapter (ENA) module and have ENA support enabled. If you are unsure if your AMI or instance supports enhanced networking, see Enhanced Networking on Linux in the Amazon Elastic Compute Cloud User Guide for Linux Instances. This reference includes which instance types are currently supported, and if necessary, the steps required to enable support.
Storage
For semiconductor design flows running at scale, storage can be the bottleneck that reduces job throughput. Traditionally, centralized filers serving network file systems (NFS) are commonly purchased from hardware vendors at significant costs in support of high throughout. However, these centralized filers can quickly become a bottleneck, resulting in increased job run times and correspondingly higher license costs. As the amount of data increases, the need to access that data across a fast-growing cluster means that the filers eventually run out of storage space, or become bandwidth constrained by either the network or storage tier.
The following sections provide information on currently available storage options recommended for semiconductor workflows:
-
Object storage - Amazon S3
-
Block storage - Amazon Elastic Block Store (Amazon EBS), and Amazon EC2 instance store (NVMe storage local to Amazon EC2 instances)
-
File storage - Amazon Elastic File System (Amazon EFS), and Amazon FSx for Lustre
With the combination of these storage options, you can enable an elastic, cost-optimized, storage solution for your entire workflow that will eliminate storage bottlenecks typically found in chip design flows.
Object Storage - Amazon S3
Amazon Simple Storage Service (Amazon S3)
Amazon S3 has various features you can use to organize and manage your data in ways that
support specific use cases, enable cost efficiencies, enforce security, and meet
compliance requirements. Data is stored as objects within resources called “buckets”, and
a single object can be up to 5 terabytes in size. Amazon S3 features include capabilities to
append metadata tags to objects, move and store data across the Amazon S3 storage classes
In particular, Amazon S3 storage classes can be used to define a data lifecycle strategy that can significantly reduce storage costs, without sacrificing access to critical data.
For semiconductor design workflows, we recommend Amazon S3 for your primary data storage solution. Today, EDA tools do not provide a built-in interface to object storage, so you will need to move data to a POSIX compliant file system before running jobs. This task can easily be performed as the file system is created, or when instances are being launched. Amazon S3 provides flexibility and agility to quickly move your data from object storage, to block storage, to file storage, and back to object storage. For example, you can quickly and efficiently copy data from Amazon S3 to Amazon EC2 instances and Amazon EBS storage to populate a high performance shared file system prior to launching a large batch regression test or timing analysis. Additionally, the same Amazon S3 bucket can be used to populate an Amazon FSx for Lustre file system that is used only once, or is persistent and used for large chip designs.
Block storage - Amazon EBS
Amazon Elastic Block Store (Amazon EBS)
Amazon EBS volumes appear as local block storage that can be formatted with a file system on the instance itself. Amazon EBS volumes offer the consistent and low-latency performance required to run semiconductor workloads.
When selecting your instance type, you should select an instance that is Amazon EBS-optimized by default. The previously recommended instances are all EBS-optimized by default. If your application requires an instance that is not Amazon EBS optimized, see the EBS optimization section in the Amazon Elastic Compute Cloud User Guide for Linux Instances.
Additionally, there are several EBS volume types that you can choose from, with
varying performance characteristics and pricing options. At the time of this writing, we
recommend using Amazon EBS gp3 general
purpose volumes
Although we recommend using AWS managed storage services, if you plan on building and
maintaining your own NFS file servers on AWS, you need to use instance types and EBS
volume types that are more suited for high performance throughput and lower latency. For
example, the Amazon EC2 C6gn
instance
For more information about EBS-optimized instances, and to determine which instance meets your file system server requirements, see Amazon EBS-optimized instances in the Amazon Elastic Compute Cloud User Guide for Linux Instances.
Amazon EC2 instance store
For use cases where the performance of Amazon EBS is not sufficient on a single instance, Amazon EC2 instances with Amazon EC2 instance store are available. An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host computer, and the data on the instance store does not persist when you stop or terminate the instance. Additionally, hardware failures on the instance would likely result in data loss. For these reasons, instance store is recommended for temporary storage of information that changes frequently, such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances. You can replicate data off of the instance (for example, to Amazon S3), and increase durability by choosing an instance with multiple instance store volumes, and create a RAID set with one or more parity volumes.
Table 1 includes instances that are well-suited for chip design workloads requiring a
significant amount of fast local storage, such as scratch data. The disk variants of these
instances have Amazon EC2 instance store volumes that use NVMe based SSD storage devices. Each
instance type has a different amount of instance store available, and increases with the
size of the instance type. For more information about the NVMe volumes for each instance,
see the Instance Storage column on the Amazon EC2 Instance Types
File systems
Currently, semiconductor design flows require a POSIX compliant file system. This requirement has traditionally been met with NFS file servers, that are built with third-party vendors and expensive licensing. Building your environment on AWS allows you to choose from multiple managed services that can be used for the entire design workflow, and reduce expensive licensing costs.
Amazon FSx for Lustre
Amazon FSx for Lustre
For semiconductor design workflows, we recommend using FSx for Lustre for, at minimum, testing and POCs. Management of the file system is part of the FSx for Lustre service. This eliminates the time consuming management overhead that is normally associated with high performance file systems. FSx for Lustre offers sub-millisecond latencies, up to hundreds of gigabytes per second of throughput, and millions of IOPS. FSx for Lustre file systems can also be linked to Amazon S3 buckets, allowing you to populate file systems when they are created, and subsequently push data into S3 on an as needed basis.
Specifically, physical design workloads are particularly well suited for FSx for Lustre. This includes static timing analysis (STA), extraction, and design rule checking (DRC). Front-end workloads can run on FSx for Lustre, but may see a scaling limit for millions of small files and metadata heavy I/O. We encourage our customers to run their entire flow on FSx for Lustre for testing and verification. From there, you can optimize by tuning FSx for Lustre, or potentially use another file system. For information about tuning, see Amazon FSx for Lustre Performance in the Amazon FSx for Lustre User Guide.
Amazon Elastic File System (Amazon EFS)
Amazon Elastic File System (Amazon EFS)
For semiconductor design workflows, Amazon EFS can be used for multiple applications. Customers use Amazon EFS for home directories, infrastructure support (installation and configuration files), and application binaries. We recommend using EFS for large sequential I/O, as large amounts of small files and metadata heavy I/O may not perform at the required throughput and IOPS.
Traditional NFS file systems
For EDA workflow migration to AWS, you should start with migrating data to an environment that is similar to your on-premises environment. This allows you to migrate applications quickly without having to rearchitect your workflow. Both FSx for Lustre and EFS provide POSIX compliant file systems, and your workflows should be compatible with either. If you still require a more traditional NFS server, you can create a storage server by launching an Amazon EC2 instance, attaching the appropriate EBS volumes, and sharing the file system to your compute instances using NFS.
If the data is temporary or scratch data, you can use an instance with locally attached (Amazon EC2 instance store) NVMe volumes to optimize the backend storage. For example, you can use the i3en.24xlarge that has 8 NVMe volumes (60 TB total) and is capable of up to 16 GB/s of sequential throughput and 2M IOPS for local access (using 4K block sizes). The 100 Gbps network connection to the i3en.24xlarge then becomes the rate limiting factor, and not the backend storage. This configuration results in an NFS server capable of over 10 GB/s. If you want to preserve the data stored on the NVMe volumes, you can attach EBS volumes and rsync the data to EBS, or you can copy the data to an Amazon S3 bucket.
For workloads that require more performance in aggregate than can be provided by a
single instance, you can build multiple NFS servers that are delegated to specific mount
points. Typically, this means that you build servers for shared scratch, tools
directories, and individual projects. By building servers this way, you can right size the
server and the storage allocated according to the demands of a specific workload. When
projects are finished, you can archive the data to a low cost, long term storage service
like Amazon S3 Glacier
Cloud Storage Approaches
Cloud-optimized semiconductor design workflows use a combination of Amazon FSx for Lustre, Amazon EFS, Amazon EBS, Amazon EC2 instance store, and Amazon S3 to achieve extreme scalability at very low costs, without being bottlenecked by traditional storage systems.
To take advantage of a solution like this, your EDA organization and your supporting IT teams might need to untangle many years of legacy tools, file system sprawl, and large numbers of symbolic links to understand what data you need for specific projects (or job deck) and pre-package the data along with the job that requires it. The typical first step in this approach is to separate out the static data (for example, application binaries, compilers, and so on) from dynamically changing data and IP in order to build a front-end workflow that doesn’t require any shared file systems. This step is important for optimized cloud migration, and also provides the benefit of increasing the scalability and reliability of your workflows.
By using this less NFS centric approach to manage EDA storage, operating system images can be regularly updated with static assets so that they’re available when the instance is launched. Then, when a job is dispatched to the instance, it can be configured to first download the dynamic data from Amazon S3 to local or Amazon EBS storage before launching the application. When complete, results are uploaded back to Amazon S3 to be aggregated and processed when all jobs are finished. This method for decoupling compute from storage can provide substantial performance and reliability benefits, in particular for front-end register transfer language (RTL) batch regressions.
Orchestration
Orchestration refers to the dynamic management of compute and storage, as well as the management of individual jobs being processed in a complex workflow (scheduling and monitoring), for example during RTL regression testing or IP characterization. For these and many other typical chip design workflows, the efficient use of compute and storage resources—as well as the efficient use of software licenses—depends on having a well-orchestrated, well-architected batch computing environment.
Chip design workflows gain new levels of flexibility in the cloud, making resource and
job orchestration an important consideration for your workload. AWS provides a range of
solutions for workload orchestration. Describing all possible methods of orchestration is
beyond the scope of this document; however, it is important to note that the same
orchestration methods and job scheduling software used in typical, legacy chip design
environments can also be used on AWS. For example, commercial and open-source job scheduling
software can be migrated to AWS, and be enhanced by the addition of automatic scaling (for
dynamic resizing of EDA clusters in response to demand or other triggers), AWS CloudWatch
AWS Solutions Implementation: Scale-Out Computing on AWS
The AWS Solutions Implementation Scale-Out Computing on
AWS
The services and recommendations that are covered in this guide can be launched and
customized using Scale-Out Computing on
AWS
Job scheduler integration
The semiconductor design workflow that you build on AWS can be a similar environment to the one you have in your on-premises data center. Many, if not all, of the same tools and applications running in your data center, as well as orchestration software, can also be run on AWS. Job schedulers, such as IBM Platform LSF, Altair PBS Pro, and Grid Engine (or their open source alternatives), are typically used in the semiconductor industry to manage compute resources, optimize license usage, and coordinate and prioritize jobs. When you migrate to AWS, you may choose to use these existing schedulers essentially unchanged, to minimize the impact on your end-user workflows and processes. Most of these job schedulers already have some form of cloud-optimized integration with AWS, allowing you to use the scheduler node to automatically launch cloud resources when there are jobs pending in the queue. Be sure to refer to the documentation of your specific job management tool for the steps to automate resource allocation and management on AWS.
