Gremlin load data format
To load Apache TinkerPop Gremlin data using the CSV format, you must specify the vertices and the edges in separate files.
The loader can load from multiple vertex files and multiple edge files in a single load job.
For each load command, the set of files to be loaded must be in the same folder in the
Amazon S3 bucket, and you specify the folder name for the source parameter. The file
names and file name extensions are not important.
The Amazon Neptune CSV format follows the RFC 4180 CSV specification. For more
information, see Common Format and MIME
Type for CSV Files
Note
All files must be encoded in UTF-8 format.
Each file has a comma-separated header row. The header row consists of both system column headers and property column headers.
System Column Headers
The required and allowed system column headers are different for vertex files and edge files.
Each system column can appear only once in a header.
All labels are case sensitive.
Vertex headers
-
~id- RequiredAn ID for the vertex.
-
~labelA label for the vertex. Multiple label values are allowed, separated by semicolons (
;).If
~labelis not present, TinkerPop supplies a label with the valuevertex, because every vertex must have at least one label.
Edge headers
-
~id- RequiredAn ID for the edge.
-
~from- RequiredThe vertex ID of the from vertex.
-
~to- RequiredThe vertex ID of the to vertex.
-
~labelA label for the edge. Edges can only have a single label.
If
~labelis not present, TinkerPop supplies a label with the valueedge, because every edge must have a label.
Property Column Headers
You can specify a column (:) for a property by using the following syntax.
The type names are not case sensitive. Note, however, that if a colon appears within a
property name, it must be escaped by preceding it with a backslash: \:.
propertyname:type
Note
Space, comma, carriage return and newline characters are not allowed in the column headers, so property names cannot include these characters.
You can specify a column for an array type by adding [] to the
type:
propertyname:type[]
Note
Edge properties can only have a single value and will cause an error if an array type is specified or a second value is specified.
The following example shows the column header for a property named age of
type Int.
age:Int
Every row in the file would be required to have an integer in that position or be left empty.
Arrays of strings are allowed, but strings in an array cannot include the semicolon
(;) character unless it is escaped using a backslash (like this: \;).
Specifying the Cardinality of a Column
The column header can be used to specify cardinality for the property identified by the column. This allows the bulk loader to honor cardinality similarly to the way Gremlin queries do.
You specify the cardinality of a column like this:
propertyname:type(cardinality)
The cardinality value can be either single or
set. The default is assumed to be set, meaning that the column
can accept multiple values. In the case of edge files, cardinality is always single and
specifying any other cardinality causes the loader to throw an exception.
If the cardinality is single, the loader throws an error if
a previous value is already present when a value is loaded, or if multiple values are loaded.
This behavior can be overridden so that an existing value is replaced when a new value
is loaded by using the updateSingleCardinalityProperties flag. See
Loader Command.
It is possible to use a cardinality setting with an array type, although this is not generally necessary. Here are the possible combinations:
name:type– the cardinality isset, and the content is single-valued.name:type[]– the cardinality isset, and the content is multi-valued.name:type(single)– the cardinality issingle, and the content is single-valued.name:type(set)– the cardinality isset, which is the same as the default, and the content is single-valued.name:type(set)[]– the cardinality isset, and the content is multi-valued.name:type(single)[]– this is contradictory and causes an error to be thrown.
The following section lists all the available Gremlin data types.
Gremlin Data Types
This is a list of the allowed property types, with a description of each type.
Bool (or Boolean)
Indicates a Boolean field. Allowed values: false,
true
Note
Any value other than true will be treated as false.
Whole Number Types
Values outside of the defined ranges result in an error.
| Type | Range |
|---|---|
| Byte | -128 to 127 |
| Short | -32768 to 32767 |
| Int | -2^31 to 2^31-1 |
| Long | -2^63 to 2^63-1 |
Decimal Number Types
Supports both decimal notation or scientific notation. Also allows symbols such as (+/-) Infinity or NaN. INF is not supported.
| Type | Range |
|---|---|
| Float | 32-bit IEEE 754 floating point |
| Double | 64-bit IEEE 754 floating point |
Float and double values that are too long are loaded and rounded to the nearest value for 24-bit (float) and 53-bit (double) precision. A midway value is rounded to 0 for the last remaining digit at the bit level.
String
Quotation marks are optional. Commas, newline, and carriage return characters are
automatically escaped if they are included in a string surrounded by double quotation
marks ("). Example: "Hello,
World"
To include quotation marks in a quoted string, you can escape the quotation mark by
using two in a row: Example: "Hello
""World"""
Arrays of strings are allowed, but strings in an array cannot include the semicolon
(;) character unless it is escaped using a backslash (like this: \;).
If you want to surround strings in an array with quotation marks, you must surround
the whole array with one set of quotation marks.
Example: "String one; String 2; String 3"
Date
Java date in ISO-8601 format. Supports the following formats:
yyyy-MM-dd, yyyy-MM-ddTHH:mm,
yyyy-MM-ddTHH:mm:ss, yyyy-MM-ddTHH:mm:ssZ.
The values are converted to epoch time and stored.
Datetime
Java date in ISO-8601 format. Supports the following formats:
yyyy-MM-dd, yyyy-MM-ddTHH:mm,
yyyy-MM-ddTHH:mm:ss, yyyy-MM-ddTHH:mm:ssZ.
The values are converted to epoch time and stored.
Gremlin Row Format
Delimiters
Fields in a row are separated by a comma. Records are separated by a newline or a newline followed by a carriage return.
Blank Fields
Blank fields are allowed for non-required columns (such as user-defined properties). A blank field still requires a comma separator. Blank fields on required columns will result in a parsing error. Empty string values are interpreted as empty string value for the field; not as a blank field. The example in the next section has a blank field in each example vertex.
Vertex IDs
~id values must be unique for all vertices in every vertex file.
Multiple vertex rows with identical ~id values are applied to a single
vertex in the graph. Empty string ("") is a valid id, and the vertex
is created with an empty string as the id.
Edge IDs
Additionally, ~id values must be unique for all edges in every edge
file. Multiple edge rows with identical ~id values are applied to the
single edge in the graph. Empty string ("") is a valid id, and the edge
is created with an empty string as the id.
Labels
Labels are case sensitive and cannot be empty. A value of "" will result in an error.
String Values
Quotation marks are optional. Commas, newline, and carriage return characters are
automatically escaped if they are included in a string surrounded by double quotation
marks ("). Empty string values ("") are interpreted as an
empty string value for the field; not as a blank field.
CSV Format Specification
The Neptune CSV format follows the RFC 4180 CSV specification, including the following requirements.
Both Unix and Windows style line endings are supported (\n or \r\n).
Any field can be quoted (using double quotation marks).
Fields containing a line-break, double-quote, or commas must be quoted. (If they are not, load aborts immediately.)
A double quotation mark character (
") in a field must be represented by two (double) quotation mark characters. For example, a stringHello "World"must be present as"Hello ""World"""in the data.Surrounding spaces between delimiters are ignored. If a row is present as
value1, value2, they are stored as"value1"and"value2".Any other escape characters are stored verbatim. For example,
"data1\tdata2"is stored as"data1\tdata2". No further escaping is needed as long as these characters are enclosed within quotation marks.Blank fields are allowed. A blank field is considered an empty value.
Multiple values for a field are specified with a semicolon (
;) between values.
For more information, see Common
Format and MIME Type for CSV Files
Gremlin Example
The following diagram shows an example of two vertices and an edge taken from the TinkerPop Modern Graph.
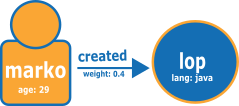
The following is the graph in Neptune CSV load format.
Vertex file:
~id,name:String,age:Int,lang:String,interests:String[],~label v1,"marko",29,,"sailing;graphs",person v2,"lop",,"java",,software
Tabular view of the vertex file:
| ~id | name:String | age:Int | lang:String | interests:String[] | ~label |
| v1 | "marko" | 29 | ["sailing", "graphs"] | person | |
| v2 | "lop" | "java" | software |
Edge file:
~id,~from,~to,~label,weight:Double e1,v1,v2,created,0.4
Tabular view of the edge file:
| ~id | ~from | ~to | ~label | weight:Double |
| e1 | v1 | v2 | created | 0.4 |
Next Steps
Now that you know more about the loading formats, see Example: Loading Data into a Neptune DB Instance.
