Load format for openCypher data
To load openCypher data using the openCypher CSV format, you must specify nodes and relationships in separate files. The loader can load from multiple of these node files and relationship files in a single load job.
For each load command, the set of files to be loaded must have the same path prefix in an Amazon Simple Storage Service bucket. You specify that prefix in the source parameter. The actual file names and extensions are not important.
In Amazon Neptune, the openCypher CSV format conforms to the RFC 4180 CSV
specification. For more information, see Common
Format and MIME Type for CSV Files
Note
These files MUST be encoded in UTF-8 format.
Each file has a comma-separated header row that contains both system column headers and property column headers.
System column headers in openCypher data loading files
A given system column can only appear once in each file. All system column header labels are case-sensitive.
The system column headers that are required and allowed are different for openCypher node load files and relationship load files:
System column headers in node files
-
:ID– (Required) An ID for the node.An optional ID space can be added to the node
:IDcolumn header like this::ID(. An example isID Space):ID(movies).When loading relationships that connect the nodes in this file, use the same ID spaces in the relationship files'
:START_IDand/or:END_IDcolumns.The node
:IDcolumn can optionally be stored as a property in the form,property name:IDname:ID.Node IDs should be unique across all node files in the current and previous loads. If an ID space is used, node IDs should be unique across all node files that use the same ID space in the current and previous loads.
-
:LABEL– A label for the node.When using multiple label values for a single node, each label should be separated by semicolons(
;).
System column headers in relationship files
-
:ID– An ID for the relationship. This is required whenuserProvidedEdgeIdsis true (the default), but invalid whenuserProvidedEdgeIdsisfalse.Relationship IDs should be unique across all relationship files in current and previous loads.
-
:START_ID– (Required) The node ID of the node this relationship starts from.Optionally, an ID space can be associated with the start ID column in the form
:START_ID(. The ID space assigned to the start node ID should match the ID space assigned to the node in its node file.ID Space) -
:END_ID– (Required) The node ID of the node this relationship ends at.Optionally, an ID space can be associated with the end ID column in the form
:END_ID(. The ID space assigned to the end node ID should match the ID space assigned to the node in its node file.ID Space) -
:TYPE– A type for the relationship. Relationships can only have a single type.
Note
See Loading openCypher data for information about how duplicate node or relationship IDs are handled by the bulk load process.
Property column headers in openCypher data loading files
You can specify that a column holds the values for a particular property using a property column header in the following form:
propertyname:type
Space, comma, carriage return and newline characters are not allowed in the column headers, so property names
cannot include these characters. Here is an example of a column header for a property named
age of type Int:
age:Int
The column with age:Int as a column header would then have to contain
either an integer or an empty value in every row.
Data types in Neptune openCypher data loading files
-
BoolorBoolean– A Boolean field. Allowed values aretrueandfalse.Any value other than
trueis treated asfalse. -
Byte– A whole number in the range-128through127. -
Short– A whole number in the range-32,768through32,767. -
Int– A whole number in the range-2^31through2^31 - 1. -
Long– A whole number in the range-2^63through2^63 - 1. -
Float– A 32-bit IEEE 754 floating point number. Decimal notation and scientific notation are both supported.Infinity,-Infinity, andNaNare all recognized, butINFis not.Values with too many digits to fit are rounded to the nearest value (a midway value is rounded to 0 for the last remaining digit at the bit level).
-
Double– A 64-bit IEEE 754 floating point number. Decimal notation and scientific notation are both supported.Infinity,-Infinity, andNaNare all recognized, butINFis not.Values with too many digits to fit are rounded to the nearest value (a midway value is rounded to 0 for the last remaining digit at the bit level).
-
String– Quotation marks are optional. Comma, newline, and carriage return characters are automatically escaped if they are included in a string that is surrounded by double quotation marks (") like"Hello, World".You can include quotation marks in a quoted string by using two in a row, like
"Hello ""World""". -
DateTime– A Java date in one of the following ISO-8601 formats:yyyy-MM-ddyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ
Auto-cast data types in Neptune openCypher data loading files
Auto-cast data types are provided to load data types not currently supported natively by Neptune. Data in such columns are stored as strings, verbatim with no verification against their intended formats. The following auto-cast data types are allowed:
-
Char– ACharfield. Stored as a string. -
Date,LocalDate, andLocalDateTime, – See Neo4j Temporal Instantsfor a description of the date,localdate, andlocaldatetimetypes. The values are loaded verbatim as strings, without validation. -
Duration– See the Neo4j Duration format. The values are loaded verbatim as strings, without validation. -
Point – A point field, for storing spatial data. See Spatial instants
. The values are loaded verbatim as strings, without validation.
Example of the openCypher load format
The following diagram taken from the TinkerPop Modern Graph shows an example of two nodes and a relationship:
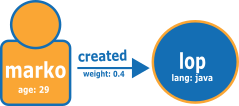
The following is the graph in the normal Neptune openCypher load format.
Node file:
:ID,name:String,age:Int,lang:String,:LABEL v1,"marko",29,,person v2,"lop",,"java",software
Relationship file:
:ID,:START_ID,:END_ID,:TYPE,weight:Double e1,v1,v2,created,0.4
Alternatively, you could use ID spaces and ID as a property, as follows:
First node file:
name:ID(person),age:Int,lang:String,:LABEL "marko",29,,person
Second node file:
name:ID(software),age:Int,lang:String,:LABEL "lop",,"java",software
Relationship file:
:ID,:START_ID(person),:END_ID(software),:TYPE,weight:Double e1,"marko","lop",created,0.4
