Reference architecture
The following diagram shows the workflow after you apply this guide’s automated solution to a daily operations report. When new files are ingested into Amazon Simple Storage Service (Amazon S3), they can be immediately visualized in an Quick Suite dashboard after they are processed.
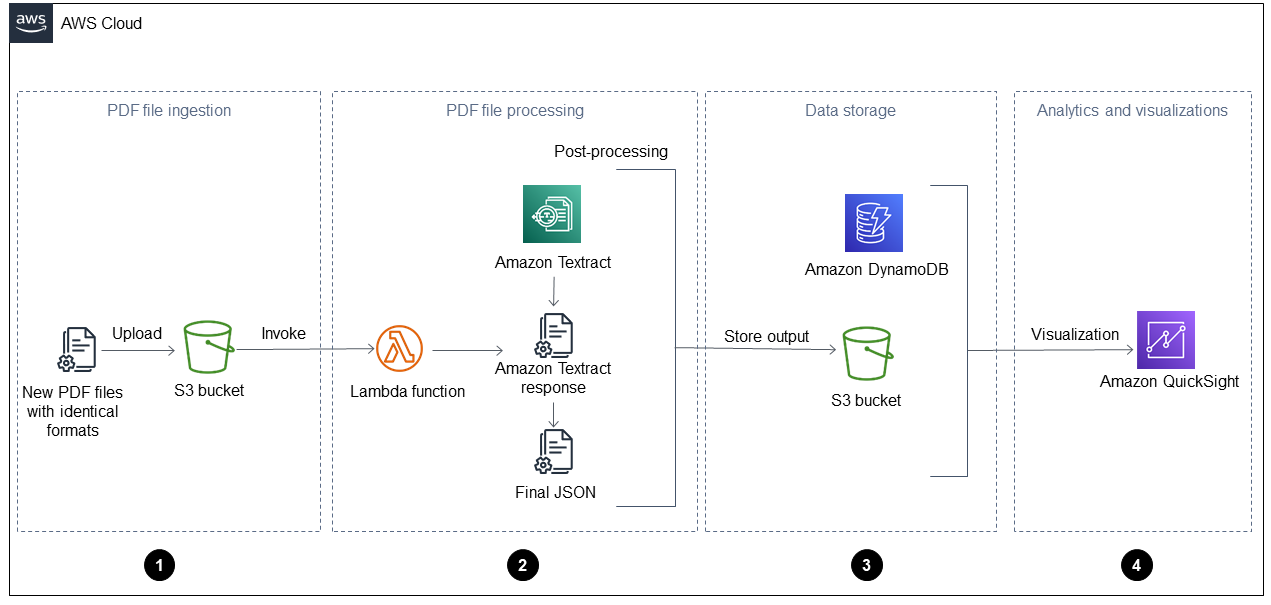
The diagram shows the following four phases:
-
PDF file ingestion – Your application automatically ingests new PDF files with an identical format (for example, a daily operations report) into an Amazon Simple Storage Service (Amazon S3) bucket. Amazon S3 initiates an
ObjectCreatedevent when new PDF files are added to the bucket and this invokes an AWS Lambda function. For more information about this, see Using an Amazon S3 trigger to invoke a Lambda function in the Amazon S3 documentation. -
PDF file processing – The Lambda function sends one PDF file to Amazon Textract, which extracts the content. A post-processing script runs and parses the Amazon Textract response and uses a predefined template for this type of PDF file. This template contains the correct attributes and helps correctly extract all key-value pairs, tables, and other raw text. For more information about this, see the pattern Automatically extract content from PDF files using Amazon Textract on the AWS Prescriptive Guidance website.
-
Data storage – The extracted and corrected data is stored in an Amazon DynamoDB table, in addition to a JSON file for each PDF file. The JSON files are stored in an S3 bucket that can be used by downstream processing and analytics services, such as Amazon Athena, Quick Suite, or Amazon SageMaker AI.
-
Analytics and visualizations – Quick Suite analyzes the data and creates visualizations that help generate insights for all processed PDF files. After dashboards are created in Quick Suite, you can share them with your end users and business teams.
Considerations
This guide's solution is appropriate for processing PDF files that have an identical format and a consistent layout of forms and tables. However, you must define a template and edit it in advance to fully automate the process and make extracted data available for analysis. This template is then used during processing with the Lambda function.
Although this solution can be applied to different PDF file types at the same time, you must create and define separate templates for each PDF file type and store them in an accessible location (for example, Amazon S3). We recommend that you use a unique identifier for each PDF file type, such as a PDF file name or different folders in your S3 bucket. The Lambda function can then call the appropriate template when processing the PDF file type.
