Best practices for new product demand forecasting
This section discusses the following best practices for new product demand forecasting:
Meet data readiness requirements for data-driven NPI demand forecasting
To adopt data-driven approaches for NPI demand forecasting, your organization should get support from all relevant stakeholders, such as managers in the data science or analytics department, supply chain, marketing, and IT. Your organization should then identify the following:
-
The sources of existing internal data and relevant external data
-
The owners of these data sources
-
The procedures and permissions required to use these data sources for the initiative
You can evaluate your data readiness against the following kinds of required and optional datasets. Using as many datasets as possible, including the optional kind, helps machine learning models generate more accurate NPI demand forecasts.
The following are examples of required internal data sources:
-
Complete sales history (from product launch through discontinuation) for all products or subset of products that have similar attributes to the new product being launched. The sales history can be from multiple sales channels or combined across all channels.
-
Product attribute mapping to identify the subset of products that have similar attributes to the new product being launched.
The following are examples of optional internal data sources:
-
Marketing data that tracks promotions and discounts for similar products. This data should be equal to or greater than the length of the sales history.
-
Product reviews, ratings, and web traffic data. This data should be equal to or greater than the length of the sales history.
-
Consumer demographic data
The following are examples of optional external data sources that can complement your internal data:
-
Consumer index data
-
Competitor sales data
-
Survey data
Build cost-effective data ingestion mechanisms
After your data readiness requirement is met, your organization can choose the most suitable data ingestion and data storage mechanisms. If your organization's main sources of sales data are collected on daily basis from different channels, consider batch data ingestion. Streaming data ingestion is another option if you want self-service forecasts that benefit from having the most recent data.
The raw data ingestion pipeline should use an extract, transform, and load (ETL) pipeline for lightweight transformation. The pipeline should perform data quality checks and store the processed data in a database for downstream consumption.
You can use AWS services, such as AWS Glue, AWS Glue Data Catalog, Amazon Data Firehose, and Amazon Simple Storage Service (Amazon S3), for cost-effective data ingestion and storage. AWS Glue is a fully managed serverless ETL service that helps you categorize, clean, transform, and reliably transfer data between different data stores. The core components of AWS Glue consists of a central metadata repository, known as AWS Glue Data Catalog, and an ETL job system that automatically generates Python and Scala code and manages ETL jobs. Amazon Data Firehose helps you collect, process, and analyze real-time streaming data at any scale. Firehose can deliver real-time streaming data directly to data lakes (such as Amazon S3), data stores, and analytical services for further processing. Amazon S3 is an object storage service that offers scalability, data availability, security, and performance.
Determine the feasible ML approaches to forecast NPI demand
Depending on the specific use case, your organization can consider different forecasting options.
A statistical forecasting approach, like the Bass diffusion
model
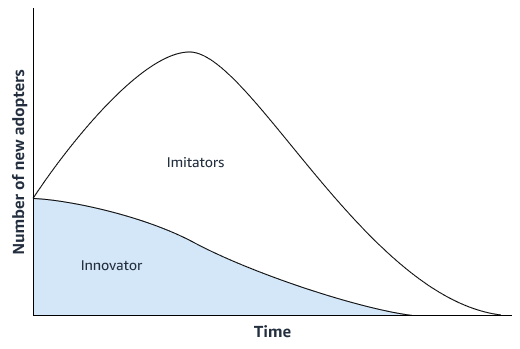
If the new product doesn't feature significant innovation, your organization can use time-series forecasting models that operate on the sales history of the product that is the most similar to the new product. You can use ML-based forecasting algorithms, such as the Amazon SageMaker AI DeepAR forecasting algorithm, that can use time-series sales data from multiple similar products. This is well-suited for cold start forecasting scenarios, which is when you want to generate a forecast for a time series but have little or no existing historical data. The following image shows how you can use time-series data from related products to generate a forecast for a new, similar product.

You should consider generating forecasts that align with your new product launch timeline. Generate forecasts well ahead of time to allow sufficient buffer for any logistic corrections.
Scale and track forecast effects
After completing a proof of concept for NPI demand forecasting, the solution should eventually scale to include additional products and multiple regions. Use an artificial intelligence and machine learning (AI/ML) framework to prepare data and to develop, deploy, and monitor the model.
The following diagram demonstrates the launch and scale strategy as the organization's NPI forecasting solution matures.
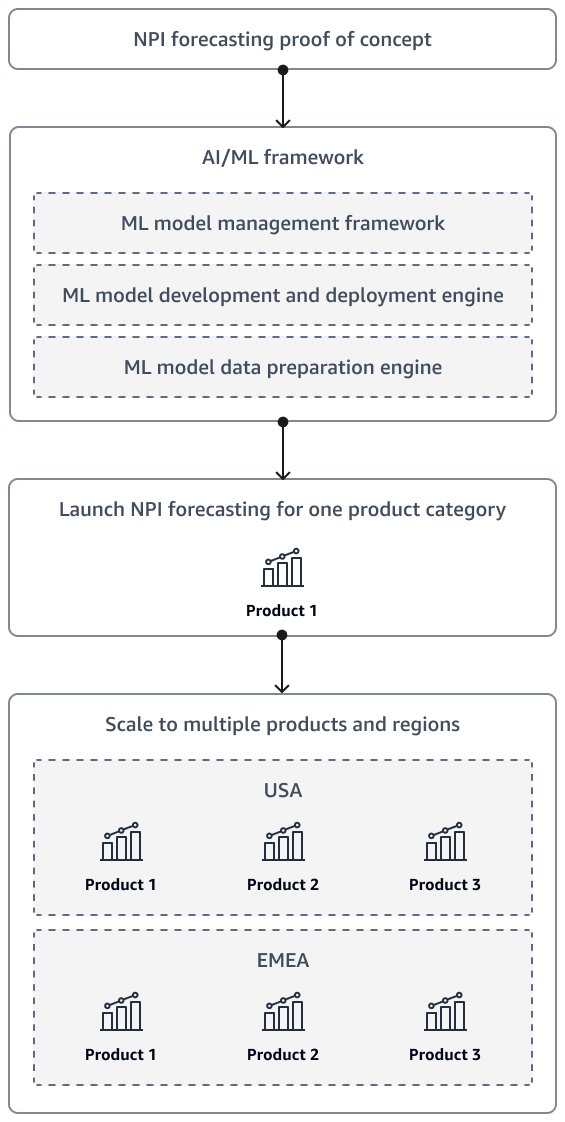
It is also recommended that you design the solution so that executives and stakeholders can self-serve forecasts. For example, you can create Amazon QuickSight dashboards so that stakeholders can access the latest forecasts on demand.
Closely monitor the forecasting accuracy, and thoroughly investigate deviations to ensure a reasonable return on investment (ROI). If you set up model monitoring with Amazon SageMaker AI Model Monitor, you can track the performance of your models as they make real-time predictions on live data. You can use the Amazon SageMaker Model Dashboard to find models that violate thresholds you set for data quality, model quality, bias, and explainability. For more information, see Use governance to manage permissions and track model performance in the Amazon SageMaker AI documentation.
