HA/DR options and considerations
Although the possibility of an AWS Availability Zone or Region going completely offline is
extremely rare, we recommend a multi-pronged approach to backup and recovery in the event of a
disaster for redundancy and to minimize data loss. Backup and recovery processes should include
the appropriate level of granularity to meet the the recovery time objective (RTO) and recovery
point objective (RPO) for the workload and to support business processes, and are often
dependent on the application. In the case of databases, AWS also supports all Microsoft
recommendations for SQL Server setup and configuration for high availability and disaster
recovery (HA/DR). Different editions of SQL Server support various HA/DR options, and you should
consider special cases such as very large databases (VLDBs) on a case-by-case basis. As with any
DR configuration, testing is essential to ensure that each application meets its service-level
agreements (SLAs) for HA/DR. For your test/development environment, consider using SQL Server Developer edition
For a use case that requires an RPO of 15 minutes and an RTO of 4 hours, you can consider a combination of the following HA/DR options:
-
SQL Server native HA/DR options with a warm standby (database level) – For illustrations of some of these architectures, see the SQL Server on Amazon EC2 architecture diagrams section later in this guide.
-
Two-node, Multi-AZ in a single Region (synchronous-commit mode) or in multiple Regions (asynchronous-commit mode, basic availability group)
-
Three-node (or more), Multi-AZ in multiple Regions (synchronous-commit and asynchronous-commit modes)
-
Two-node, Multi-AZ and log shipping in multiple Regions (with log backups every 5 minutes)
-
-
SQL Server native backups to Amazon S3 (database level, DR only) – Full backups (one time daily)
-
Differential backups (every 2–4 hours).
-
Log backups (every 5–10 minutes).
-
Backups need to be taken and copied to Amazon Simple Storage Service (Amazon S3) by using custom scripting or an option such as a File Gateway
for efficient backup and transfer. -
If you have hundreds of databases, you can continue to use your existing backup tools (such as Commvault or Litespeed) to efficiently manage backups and store them directly in Amazon S3.
-
Use Amazon S3 Cross-Region Replication (CRR) with S3 Replication Time Control (RTC) to control and monitor object replication within an SLA of 15 minutes.
-
For compliance and cost savings, you can also use S3 Lifecycle management to move and store older backups for long-term storage.
-
If you take SQL Server native backups and move them to Amazon S3 regularly, in the event of a disaster, backups will be readily available in the target Region. This eliminates the need to transfer backups or restore snapshots.
-
We recommend using SQL Native Backup Compression to reduce file sizes.
-
-
AWS snapshots (instance and volume level, DR only)
-
Amazon Elastic Compute Cloud (Amazon EC2) Amazon Machine Image (AMI) backups to rebuild databases from scratch
-
Amazon Elastic Block Store (Amazon EBS) volume snapshots to attach EBS volumes to Amazon EC2
-
Managing HA/DR resources in AWS Backup
AWS Backup is a fully managed service that offers the ability to create backup plans and schedules, and assign AWS resources that are involved in HA/DR configuration—such as Amazon EBS volumes to create snapshots and Amazon EC2 AMIs—to these backup plans. You can also use AWS Backup to schedule multi-Region copies of these EBS snapshots. For optimal usage, AWS Backup requires an efficient tagging mechanism for resources to be in place. AWS Backup also supports application-consistent backups through the Windows Volume Shadow Copy Service (VSS), which you can use for SQL Server. For storage-level protection, we recommend using EBS snapshots. Initial EBS snapshots are full, and subsequent snapshots are incremental. Although EBS snapshots offer storage-level protection, they do not replace SQL Server file-based native backups that offer point-in-time recovery.
Using AWS DMS for HA/DR
If you’re looking for an alternative to SQL Server Always On options for replication or if you have heterogeneous source and target databases, either in a hybrid setup or in AWS, you can use AWS Database Migration Service (AWS DMS) in the following ways.
If you use AWS DMS with SQL Server in a self-managed context (hosted on Amazon EC2 or on premises), it supports one-time and ongoing replication in two modes: by using MS-REPLICATION (to capture changes to tables that have primary keys) and MS-CDC (to capture changes to tables that don’t have primary keys). However, if you use Amazon Relational Database Service (Amazon RDS) as a source for AWS DMS, only MS-CDC is supported. AWS DMS offers a range of source and target endpoints, supports heterogeneous database engines, and offers fine-grained control over the replication process. You can also use the AWS Schema Conversion Tool (AWS SCT) with AWS DMS for heterogeneous database migrations. AWS SCT automates schema-level changes and also produces reports for migration readiness and planning.
You add source and target databases as end points in AWS DMS, as illustrated in the following diagram. This service implements a logical replication process by using either MS-REPLICATION or MS-CDC. If you have a hybrid setup, you can configure AWS DMS for ongoing replication between on premises and AWS. During the cutover, the AWS DMS migration task can be stopped and the application will be able to connect to the database that is already in sync with the on-premises database without further delay. Using AWS DMS for SQL Server as a source has a few limitations, which are outlined in the AWS DMS documentation.
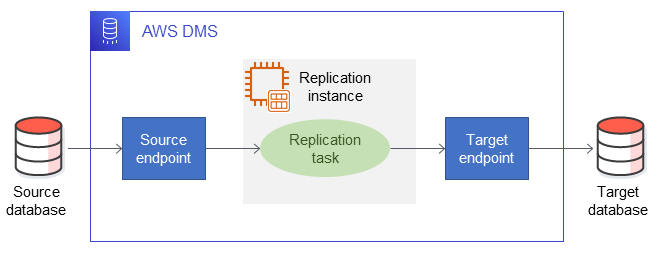
Consider using AWS DMS instead of native HA/DR methods in the following scenarios:
-
When you want to save on licensing costs. For example, if you’re using an advanced version such as SQL Server Enterprise edition only for its Always On options, you might consider setting up AWS DMS instead, because it can provide a logical replication option without the cost of an Enterprise edition license.
-
When you have heterogeneous sources and targets. SQL Server versions on primary and disaster recovery nodes do not need to match (within AWS DMS limitations), which provides significant flexibility.
-
To avoid the overhead of Windows, SQL Server clustering, and distributed availability group setup and management. AWS DMS offers a straightforward setup and easy management of replication tasks.
-
For business use cases such as near real-time transfer (depending on replication instance, network configuration, and data volume), data masking, selective filtering, schema/table mapping (homogeneous and heterogeneous), pre-migration assessments, and JSON support.
-
To easily duplicate, stop, and start tasks as needed based on log sequence numbers (LSNs), timestamps, and similar options.
The following diagram shows an alternative approach to how AWS DMS can provide replication support. In this configuration, the source is a SQL Server Always On availability group cluster, and AWS DMS uses the change data capture (CDC) option to continuously replicate data to a target in a different AWS Region. For the most optimal performance, is critical to ensure that the replication instance is right-sized and remains in the source Region.

The source and target engines do not have to match. In the diagram, the primary and secondary nodes marked as (1) can be a SQL Server cluster in a Single-AZ or Multi-AZ configuration. Or the source can be a single SQL Server node that supports MS-CDC or MS-REPLICATION.
The target DB instance, marked as (2) in the diagram, can be any version of SQL Server on Amazon RDS, Amazon EC2, or any other heterogeneous target. It doesn't have to match the primary and secondary instances or support Always On availability groups. For example, the source can be a SQL Server Always On availability group cluster, and the target can be Amazon Aurora PostgreSQL-Compatible Edition.
Using AWS Application Migration Service for DR
We recommend using the AWS Application Migration Service for lift-and-shift migrations to AWS. Application Migration Service continuously replicates your machines (including the operating system, system state configuration, databases, applications, and files) into a low-cost staging area in your target AWS account and preferred Region. In the case of a disaster, you can use Application Migration Service to automatically launch thousands of your machines in their fully provisioned state in minutes.
Additional considerations
The following list identifies the possible bottlenecks you should consider when you design an HA/DR strategy.
-
Bandwidth, latency, network complexity, and connectivity in a multi-Region node setup.
-
Size of the Amazon EBS or Amazon EC2 snapshots, and the time it takes to copy them over by using AWS Backup.
-
Amazon EBS and Amazon EC2 snapshots are stored in Amazon S3 by using AWS Backup.
-
An EBS snapshot does not replicate to the target Region in Amazon S3 until the current snapshot is completed. The duration of replication also depends on the size of the volume.
-
When the snapshot is complete, the duration of time to copy snapshots can be as little as 15 minutes for 99.99% of the objects. However, thorough testing is required for specific use cases and critical large volumes.
-
-
Time required to restore EBS volumes in the target Availability Zone and Region.
-
Time required to restore Amazon EC2 images in the target Availability Zone and Region.
-
If building from scratch, time required to provision infrastructure for the Amazon EC2 image or restored EBS snapshots in the target Availability Zone and Region.
-
If restoring from scratch, time required to restore SQL Server native full, differential, and log backups in the target Availability Zone and Region.
-
Application and external dependencies that need to be available across Regions.
-
Limitations on file sizes for volumes and for uploading to Amazon S3.
