Minimize planning overhead
As discussed Key topics in Apache Spark, the Spark driver generates the execution plan. Based on that plan, tasks are assigned to the Spark executor for distributed processing. However, the Spark driver can become a bottleneck if there is a large number of small files or if the AWS Glue Data Catalog contains a large number of partitions. To identify high planning overhead, assess the following metrics.
CloudWatch metrics
Check CPU Load and Memory Utilization for the following situations:
-
Spark driver CPU Load and Memory Utilization are recorded as high. Normally, the Spark driver doesn't process your data, so CPU load and memory utilization don't spike. However, if the Amazon S3 data source has too many small files, listing all the S3 objects and managing a large number of tasks might cause resource utilization to be high.
-
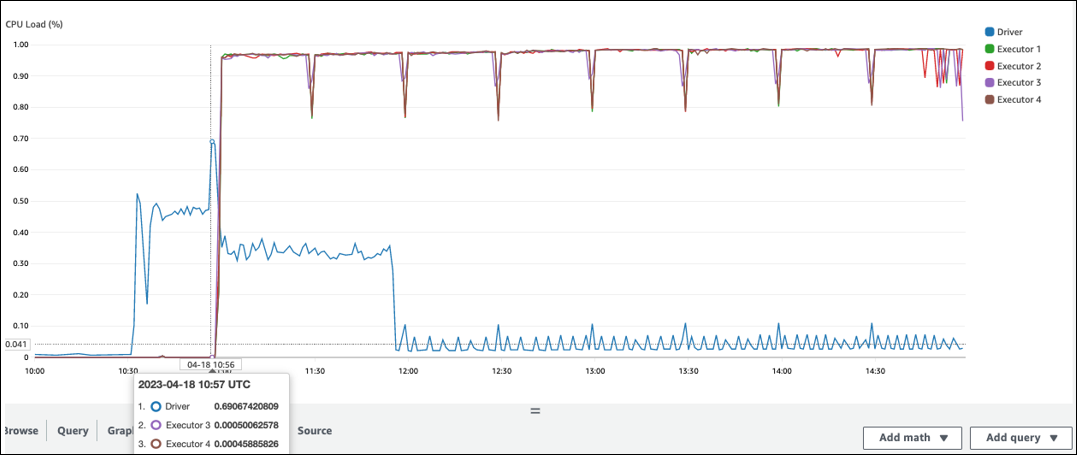
There is a long gap before processing starts in Spark executor. In the following example screenshot, the Spark executor's CPU Load is too low until 10:57, even though the AWS Glue job started at 10:00. This indicates that the Spark driver might be taking a long time to generate an execution plan. In this example, retrieving the large number of partitions in the Data Catalog and listing the large number of small files in the Spark driver is taking a long time.
Spark UI
On the Job tab in the Spark UI, you can see the Submitted time. In the following example, the Spark driver started job0 at 10:56:46, even though the AWS Glue job started at 10:00:00.

You can also see the Tasks (for all stages):
Succeeded/Total time on the Job tab.
In this case, the number of tasks is recorded as 58100. As explained in the Amazon S3
section of the Parallelize
tasks page, the number of tasks approximately corresponds to the number
of S3 objects. This means that there are about 58,100 objects in Amazon S3.
For more details about this job and timeline, review the Stage tab. If you observe a bottleneck with the Spark driver, consider the following solutions:
-
When Amazon S3 has too many files, consider the guidance on excessive parallelism in the Too many partitions section of the Parallelize tasks page.
-
When Amazon S3 has too many partitions, consider the guidance on excessive partitioning in the Too many Amazon S3 partitions section of the Reduce the amount of data scan page. Enable AWS Glue partition indexes if there are many partitions to reduce latency for retrieving partition metadata from the Data Catalog. For more information, see Improve query performance using AWS Glue partition indexes
. -
When JDBC has too many partitions, lower the
hashpartitionvalue. -
When DynamoDB has too many partitions, lower the
dynamodb.splitsvalue. -
When streaming jobs have too many partitions, lower the number of shards.
