Reduce the amount of data scan
To begin, consider loading only the data that you need. You can improve performance just by reducing the amount of data loaded into your Spark cluster for each data source. To assess whether this approach is appropriate, use the following metrics.
You can check read bytes from Amazon S3 in CloudWatch metrics and more details in the Spark UI as described in the Spark UI section.
CloudWatch metrics
You can see the approximate read size from Amazon S3 in ETL Data Movement (Bytes). This metric shows the number of bytes read from Amazon S3 by all executors since the previous report. You can use it to monitor ETL data movement from Amazon S3, and you can compare reads to ingestion rates from external data sources.
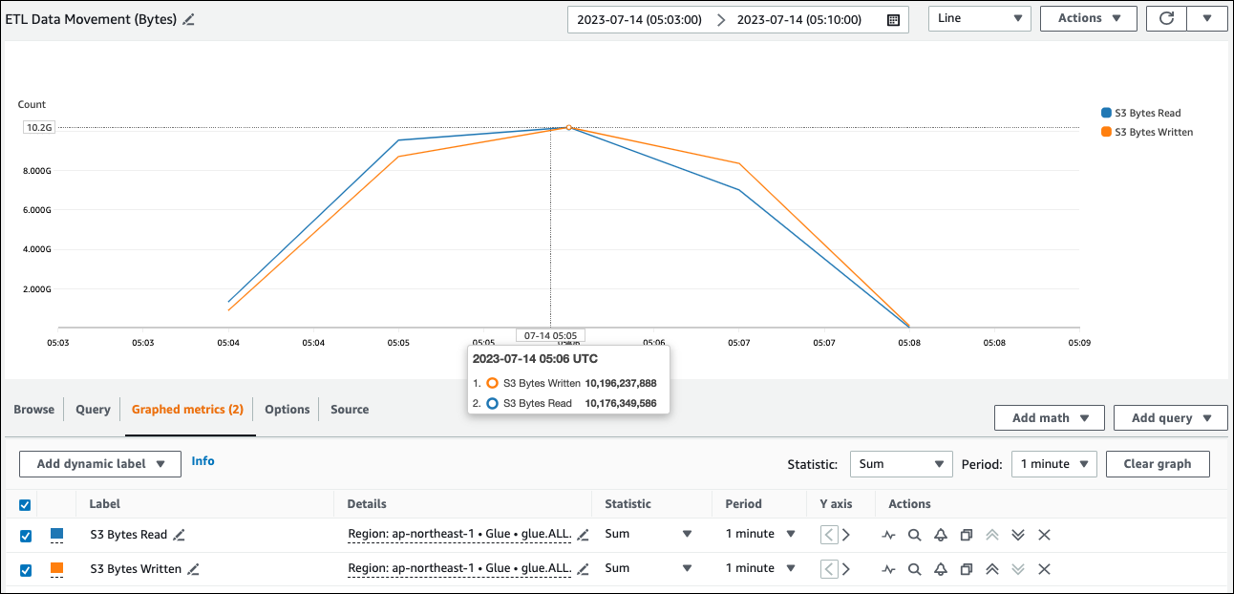
If you observe a larger S3 Bytes Read data point than you expected, consider the following solutions.
Spark UI
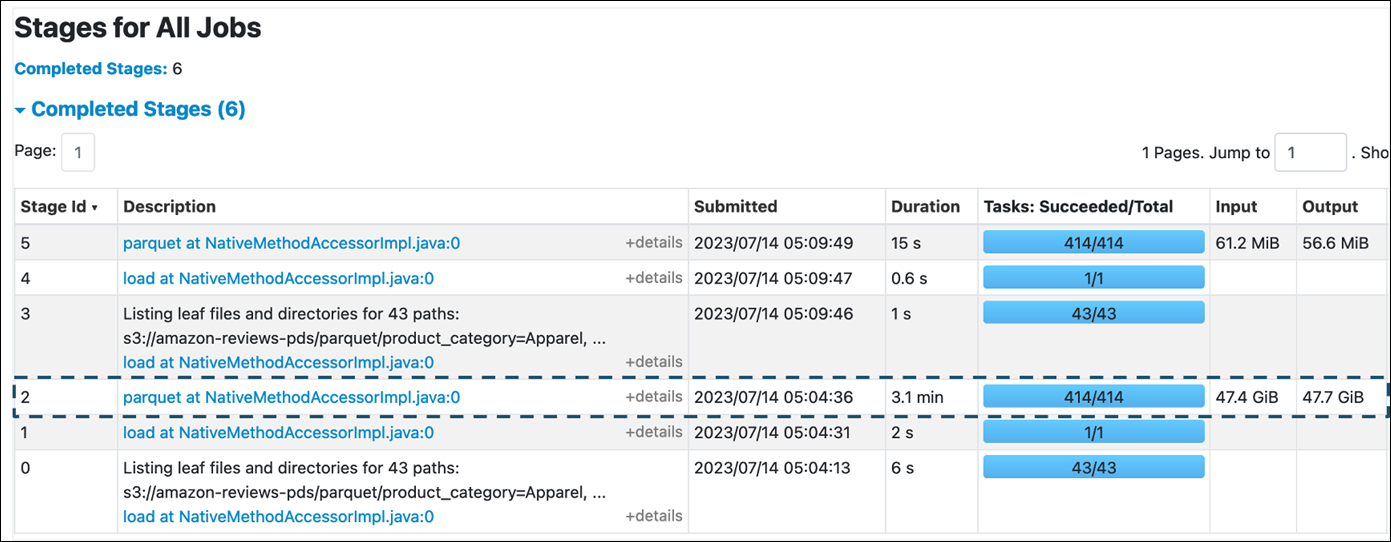
On the Stage tab in the AWS Glue for Spark UI, you can see the Input and Output size. In the following example, stage 2 reads 47.4 GiB input and 47.7 GiB output, while stage 5 reads 61.2 MiB input and 56.6 MiB output.
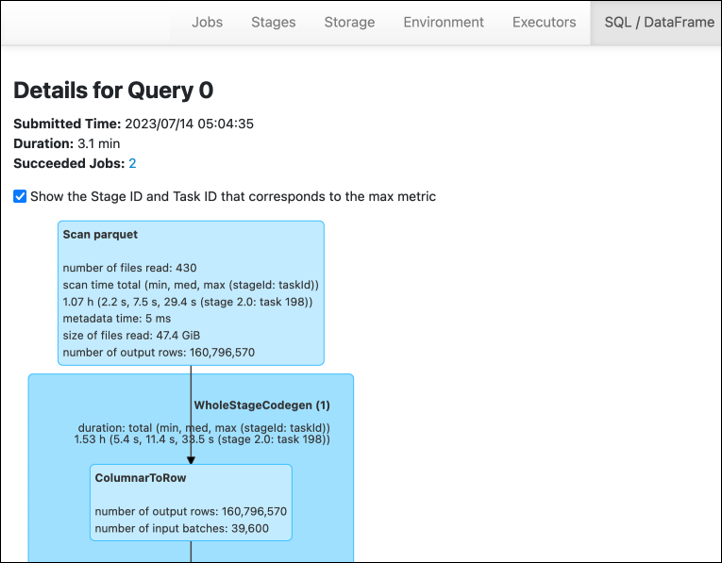
When you use the Spark SQL or DataFrame approaches in your AWS Glue job, the SQL /D ataFrame tab shows more statistics about these stages. In this case, stage 2 shows number of files read: 430, size of files read: 47.4 GiB, and number of output rows: 160,796,570.
If you observe that there is a substantial difference in size between the data you are reading in and the data you are using, try the following solutions.
Amazon S3
To reduce the amount of data loaded into your job when reading from Amazon S3, consider file size, compression, file format, and file layout (partitions) for your dataset. AWS Glue for Spark jobs are often used for ETL of raw data, but for efficient distributed processing, you need to inspect the features of your data source format.
-
File size – We recommend keeping the file size of inputs and outputs within a moderate range (for example, 128 MB). Files that are too small and files that are too large can cause issues.
A large number of small files cause following issues:
-
Heavy network I/O load on Amazon S3 because of the overhead required to make requests (such as
List,Get, orHead) for many objects (compared with a few objects that store the same quantity of data). -
Heavy I/O and processing load on the Spark driver, which will generate many partitions and tasks and lead to excessive parallelism.
On the other hand, if your file type is not splittable (such as gzip) and the files are too large, the Spark application must wait until a single task has completed reading the entire file.
To reduce excessive parallelism incurred when an Apache Spark task is created for each small file, use file grouping for DynamicFrames. This approach reduces the chances of an OOM exception from the Spark driver. To configure file grouping, set the
groupFilesandgroupSizeparameters. The following code example uses the AWS Glue DynamicFrame API in an ETL script with these parameters.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Compression – If your S3 objects are in the hundreds of megabytes, consider compressing them. There are various compression formats, which can be broadly classified into two types:
-
Unsplittable compression formats such as gzip require the entire file to be decompressed by one worker.
-
Splittable compression formats, such as bzip2 or LZO (indexed), allow partial decompression of a file, which can be parallelized.
For Spark (and other common distributed-processing engines), you will split up your source data file into chunks your engine can process in parallel. These units are often referred to as splits. After your data is in a splittable format, the optimized AWS Glue readers can retrieve splits from an S3 object by providing the
Rangeoption to theGetObjectAPI to retrieve only specific blocks. Consider the following diagram to see how this would work in practice.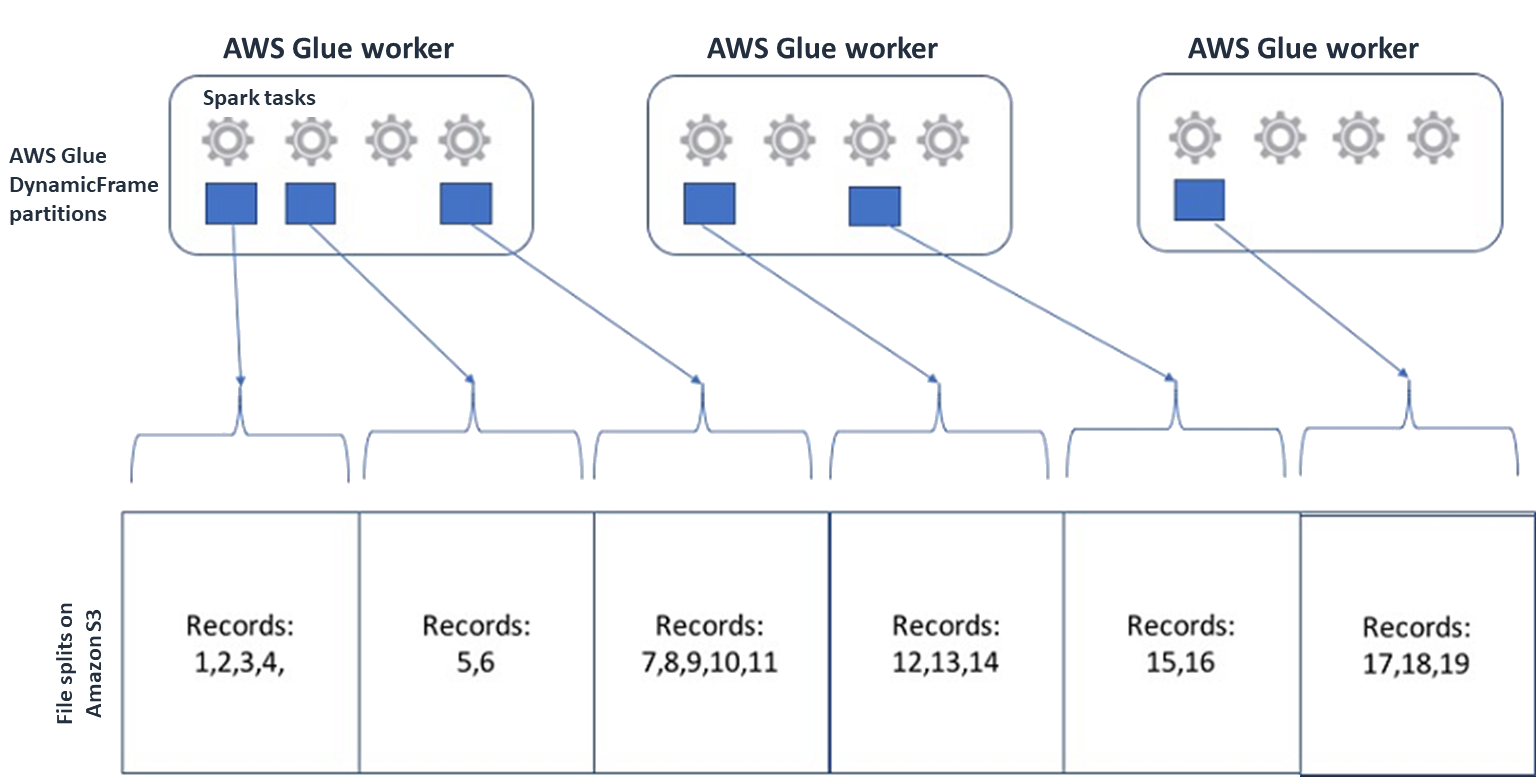
Compressed data can speed up your application significantly, as long as the files are either of an optimal size or the files are splittable. The smaller data sizes reduce the data scanned from Amazon S3 and the network traffic from Amazon S3 to your Spark cluster. On the other hand, more CPU is required to compress and decompress data. The amount of compute required scales with the compression ratio of your compression algorithm. Consider this trade-off when choosing your splittable compression format.
Note
While gzip files are not generally splittable, you can compress individual parquet blocks with gzip, and those blocks can be parallelized.
-
-
File format – Use a columnar format. Apache Parquet
and Apache ORC are popular columnar data formats. Parquet and ORC store data efficiently by employing column-based compression, encoding and compressing each column based on its data type. For more information about Parquet encodings, see Parquet encoding definitions . Parquet files are also splittable. Columnar formats group values by column and store them together in blocks. When using columnar formats, you can skip blocks of data that correspond to columns you don't plan to use. Spark applications can retrieve only the columns you need. Generally, better compression ratios or skipping blocks of data means reading fewer bytes from Amazon S3, leading to better performance. Both formats also support the following pushdown approaches to reduce I/O:
-
Projection pushdown – Projection pushdown is a technique for retrieving only the columns specified in your application. You specify columns in your Spark application, as shown in the following examples:
-
DataFrame example:
df.select("star_rating") -
Spark SQL example:
spark.sql("select start_rating from <table>")
-
-
Predicate pushdown – Predicate pushdown is a technique for efficiently processing
WHEREandGROUP BYclauses. Both formats have blocks of data that represent column values. Each block holds statistics for the block, such as maximum and minimum values. Spark can use these statistics to determine whether the block should be read or skipped depending on the filter value used in the application. To use this feature, add more filters in the conditions, as shown in the following examples as follows:-
DataFrame example:
df.select("star_rating").filter("star_rating < 2") -
Spark SQL example:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
File layout – By storing your S3 data to objects in different paths based on how the data will be used, you can efficiently retrieve relevant data. For more information, see Organizing objects using prefixes in the Amazon S3 documentation. AWS Glue supports storing keys and values to Amazon S3 prefixes in the format
key=value, partitioning your data by the Amazon S3 path. By partitioning your data, you can restrict the amount of data scanned by each downstream analytics application, improving performance and reducing cost. For more information, see Managing partitions for ETL output in AWS Glue.Partitioning divides your table into different parts and it keeps the related data in grouped files based on column values such as year, month, and day, as shown in the following example.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...You can define partitions for your dataset by modeling it with a table in the AWS Glue Data Catalog. You can then restrict the amount of data scan by using partition pruning as follows:
-
For AWS Glue DynamicFrame, set
push_down_predicate(orcatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
For Spark DataFrame, set a fixed path to prune partitions.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
For Spark SQL, you can set the where clause to prune partitions from the Data Catalog.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
To partition by date when writing your data with AWS Glue, you set partitionKeys in DynamicFrame or partitionBy()
in DataFrame with the date information in your columns as follows. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
This can improve the performance of the consumers of your output data.
If you don't have access to alter the pipeline that creates your input dataset, partitioning is not an option. Instead, you can exclude unneeded S3 paths by using glob patterns. Set exclusions when reading in DynamicFrame. For example, the following code excludes days in months 01 to 09, in year 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )You can also set exclusions in the table properties in the Data Catalog:
-
Key:
exclusions -
Value:
["**year=2023/month=0[1-9]/**"]
-
-
-
Too many Amazon S3 partitions – Avoid partitioning your Amazon S3 data on columns that contain a wide range of values, such as an ID column with thousands of values. This can substantially increase the number of partitions in your bucket, because the number of possible partitions is the product of all of the fields you have partitioned by. Too many partitions might cause the following:
-
Increased latency for retrieving partition metadata from the Data Catalog
-
Increased number of small files, which requires more Amazon S3 API requests (
List,Get, andHead)
For example, when you set a date type in
partitionByorpartitionKeys, date-level partitioning such asyyyy/mm/ddis good for many use cases. However,yyyy/mm/dd/<ID>might generate so many partitions that it would negatively impact performance as a whole.On the other hand, some use cases, such as real-time processing applications, require many partitions such as
yyyy/mm/dd/hh. If your use case requires substantial partitions, consider using AWS Glue partition indexes to reduce latency for retrieving partition metadata from the Data Catalog. -
Databases and JDBC
To reduce data scan when retrieving information from a database, you can
specify a where predicate (or clause) in a SQL query. Databases
that do not provide a SQL interface will provide their own mechanism for
querying or filtering.
When using Java Database Connectivity (JDBC) connections, provide a select
query with the where clause for the following parameters:
-
For DynamicFrame, use the sampleQuery option. When using
create_dynamic_frame.from_catalog, configure theadditional_optionsargument as follows.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )When
using create_dynamic_frame.from_options, configure theconnection_optionsargument as follows.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
For DataFrame, use the query
option. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
For Amazon Redshift, use AWS Glue 4.0 or later to take advantage of pushdown support in the Amazon Redshift Spark connector.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
For other databases, consult the documentation for that database.
AWS Glue options
-
To avoid a full scan for all continuous job runs, and process only data that wasn't present during the last job run, enable job bookmarks.
-
To limit the quantity of input data to be processed, enable bounded execution with job bookmarks. This helps to reduce the amount of scanned data for each job run.
