Usar alarmes do Amazon CloudWatch
É possível criar alarmes que observem métricas e enviem notificações ou façam alterações automaticamente nos recursos que você está monitorando quando um limite é violado. Por exemplo, você pode monitorar o uso de CPU e de leituras e gravações de disco de suas instâncias do Amazon EC2 e usar esses dados para determinar se deve iniciar instâncias adicionais para lidar com o aumento de carga. Você também pode usar esses dados para interromper instâncias subutilizados para economizar dinheiro.
No Amazon CloudWatch, você pode configurar alarmes de métricas e compostos.
-
Um alarme de métrica observa uma única métrica do CloudWatch ou o resultado de uma expressão matemática baseada em métricas do CloudWatch. O alarme executa uma ou mais ações com base no valor da métrica ou na expressão em relação a um limite em alguns períodos. A ação pode ser enviar uma notificação para um tópico do Amazon SNS, executar uma ação do Amazon EC2 ou uma ação do Amazon EC2 Auto Scaling, iniciar uma investigação nas investigações operacionais do CloudWatch ou criar um OpsItem ou incidente no Systems Manager.
Um alarme composto inclui uma expressão de regra que leva em conta os estados de outros alarmes que você criou. O alarme composto entrará no estado ALARM somente se todas as condições da regra forem atendidas. Os alarmes especificados na expressão de regra de um alarme composto podem incluir alarmes de métrica e outros alarmes compostos.
O uso de alarmes compostos pode reduzir o ruído do alarme. Você pode criar vários alarmes de métrica e também criar um alarme composto e configurar alertas apenas para o alarme composto. Por exemplo, um alarme composto poderá entrar no estado ALARM somente quando todos os alarmes de métrica subjacentes estiverem no estado ALARM.
Os alarmes compostos podem enviar notificações do Amazon SNS quando mudam de estado e podem criar investigações, OpsItems ou incidentes do Systems Manager quando entram no estado ALARM, mas não podem executar ações do EC2 ou ações do Auto Scaling.
nota
Você pode criar quantos alarmes quiser em sua conta da AWS.
É possível adicionar alarmes aos painéis, para monitorar e receber alertas sobre seus recursos da AWS e aplicações em várias regiões. Após ser adicionado a um painel, o alarme ficará cinza quando estiver no estado INSUFFICIENT_DATA e vermelho quando estiver no estado ALARM. O alarme é mostrado sem cor quando está no estado OK.
Também é possível adicionar como favoritos alarmes recém-visitados via opção Favorites and recents (Favoritos e recentes) no painel de navegação do console do CloudWatch. A opção Favorites and recents (Favoritos e recentes) contém colunas para seus alarmes favoritos e alarmes visitados recentemente.
Um alarme invoca ações somente quando muda de estado. A exceção se aplica a alarmes com ações do Auto Scaling. Para ações do Auto Scaling, o alarme continuará invocando a ação para cada período que ele permanecer no novo estado.
Um alarme pode observar uma métrica da mesma conta. Se você habilitou a funcionalidade entre contas no console do CloudWatch, também poderá criar alarmes que observem métricas em outras contas da AWS. Não há suporte para a criação de alarmes compostos entre contas. A criação de alarmes entre contas que usam expressões matemáticas é compatível, exceto as funções ANOMALY_DETECTION_BAND, INSIGHT_RULE e SERVICE_QUOTA que não são compatíveis com alarmes entre contas.
nota
O CloudWatch não testa nem valida as ações especificadas nem detecta erros do Amazon EC2 Auto Scaling ou do Amazon SNS resultantes de uma tentativa de invocar ações não existentes. Verifique se as ações de alarme existem.
Estados de alarme de métrica
Um alarme de métrica tem estes estados possíveis:
-
OK: a métrica ou a expressão está dentro do limite definido. -
ALARM: a métrica ou a expressão está fora do limite definido. -
INSUFFICIENT_DATA: o alarme acabou de ser acionado, a métrica não está disponível ou não há dados suficientes para a métrica determinar o estado do alarme.
Avaliar um alarme
Ao criar um alarme, você especifica três configurações para habilitar o CloudWatch e avaliar quando alterar o estado do alarme:
-
Período é o intervalo de tempo para avaliar a métrica ou a expressão e criar cada ponto de dados de um alarme. Ele é expresso em segundos.
-
Evaluation Periods (Períodos de avaliação) é o número de períodos mais recentes, ou pontos de dados, para avaliar quando determinar o estado do alarme.
-
Datapoints to Alarm (Pontos de dados para alarme) é o número de pontos de dados dentro dos períodos de avaliação que devem estar violando para fazer com que o alarme passe para o estado
ALARM. Os pontos de dados de violação não precisam ser consecutivos, mas eles devem estar dentro do último número de pontos de dados igual ao Evaluation Period (Período de avaliação).
Para qualquer período de um minuto ou mais, um alarme é avaliado a cada minuto, e a avaliação é baseada na janela de tempo definida pelo Período epelos Períodos de Avaliação. Por exemplo, se o Período for de 5 minutos (300 segundos) e os Períodos de Avaliação forem de 1, no final do minuto 5 o alarme será avaliado com base nos dados dos minutos 1 a 5. Então, no final do minuto 6, o alarme será avaliado com base nos dados dos minutos 2 a 6.
Se o período do alarme for de 10, 20 ou 30 segundos, o alarme será avaliado a cada 10 segundos.
Se o número de períodos de avaliação multiplicado pela duração de cada período de avaliação exceder um dia, o alarme será avaliado uma vez por hora. Para obter mais detalhes sobre como esses alarmes de vários dias são avaliados, consulte o exemplo no final desta seção.
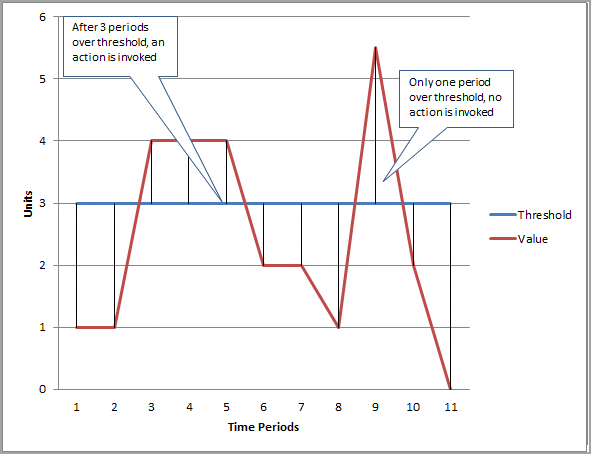
Na figura a seguir, o limite para um alarme de métrica é definido como três unidades. Tanto o Evaluation Period (Período de avaliação) como os Datapoints to Alarm (Pontos de Dados para Alarme) são 3. Ou seja, quando todos os pontos de dados nos três períodos consecutivos mais recentes estiverem acima do limite, o alarme passará para o estado ALARM. Na figura, isso acontece do terceiro ao quinto períodos de tempo. No período seis, o valor fica abaixo do limite. Portanto, um dos períodos que estão sendo avaliados não é violado, e o estado do alarme volta para OK. Durante o nono período, o limite é violado novamente, mas somente em um período. Consequentemente, o estado do alarme permanece OK.
Ao configurar Evaluation Periods (Períodos de avaliação) e Datapoints to Alarm (Pontos de dados para alarme) como valores diferentes, você está configurando um alarme “M de N”. Datapoints to Alarm (Pontos de dados para alarme) é (“M”) e Evaluation Periods (Períodos de avaliação) é (“N”). O intervalo de avaliação é o número de períodos de avaliação multiplicado pela duração do período. Por exemplo, se você configurar 4 de 5 pontos de dados com um período de 1 minuto, o intervalo de avaliação será de 5 minutos. Se você configurar 3 de 3 pontos de dados com um período de 10 minutos, o intervalo de avaliação será de 30 minutos.
nota
Se os pontos de dados estiverem ausentes logo depois que você criar um alarme, e se a métrica estava sendo relatada para o CloudWatch antes da criação do alarme, ao avaliá-lo, o CloudWatch recuperará os pontos de dados mais recentes, de antes de o alarme ter sido criado.
Exemplo de avaliação de um alarme de vários dias
Um alarme será um alarme de vários dias se o número de períodos de avaliação multiplicado pela duração de cada período de avaliação exceder um dia. Os alarmes de vários dias são avaliados uma vez por hora. Quando os alarmes de vários dias são avaliados, o CloudWatch leva em consideração somente as métricas até a hora atual, no minuto :00, durante a avaliação.
Por exemplo, considere um alarme que monitora um trabalho executado a cada 3 dias às 10h.
Às 10h02, o trabalho falha
Às 10h03, o alarme é avaliado e permanece no estado
OK, porque a avaliação considera dados somente até 10h.Às 11h03, o alarme considera dados até 11h e entra no estado
ALARM.Às 11h43, você corrige o erro e o trabalho agora é executado com êxito.
Às 12h03, o alarme é avaliado novamente, identifica o trabalho bem-sucedido e retorna ao estado
OK.
Ações de alarme
É possível especificar quais ações um alarme realizará ao mudar de estado entre os estados OK, ALARM e INSUFFICIENT_DATA.
A maioria das ações pode ser definida para a transição para cada um dos três estados. Com exceção das ações do Auto Scaling, as ações acontecem somente em transições de estado e não serão executadas novamente se a condição persistir por horas ou dias. É possível usar o fato de que várias ações são permitidas para que um alarme envie um email quando um limite for violado e, em seguida, outro quando a condição de violação terminar. Isso o ajudará a verificar se suas ações de escalonamento ou recuperação são acionadas quando esperado e estão funcionando conforme desejado.
As ações apresentadas a seguir são compatíveis como ações de alarme.
Notificar um ou mais assinantes ao usar um tópico do Amazon Simple Notification Service. Os assinantes podem ser aplicações e também pessoas. Para obter mais informações sobre o Amazon SNS, consulte O que é o Amazon SNS?.
Invocar uma função do Lambda. Essa é a maneira mais fácil de automatizar ações personalizadas em alterações de estado de alarme.
-
Os alarmes baseados em métricas do EC2 também podem executar ações do EC2, como interromper, encerrar, reinicializar ou recuperar uma instância do EC2. Para obter mais informações, consulte Criar alarmes para interromper, terminar, reinicializar ou recuperar uma instância do EC2.
Os alarmes podem executar ações para escalar um grupo do Auto Scaling. Para obter mais informações, consultePolíticas de escalabilidade simples e em etapas do Amazon EC2 Auto Scaling.
-
Os alarmes podem criar OpsItems no OpsCenter do Systems Manager ou criar incidentes no AWS Systems Manager Incident Manager. Essas ações são executadas apenas quando o alarme entra no estado ALARM (ALARME). Para obter mais informações, consulte Configurar o CloudWatch para criar OpsItems de alarmes e Criação de incidentes.
Um alarme pode iniciar uma investigação quando entra no estado ALARM. Para obter mais informações sobre as investigações do CloudWatch, consulte Investigações do CloudWatch.
Os alarmes também emitem eventos para Amazon EventBridge quando mudam de estado, e você pode configurar o Amazon EventBridge para acionar outras ações para essas mudanças de estado. Para obter mais informações, consulte O que é o Amazon EventBridge?.
Ações de alarme para o Lambda
Os alarmes do CloudWatch garantem uma invocação assíncrona da função do Lambda para uma determinada alteração de estado, exceto nos seguintes casos:
Quando a função não existe.
Quando o CloudWatch não está autorizado a invocar a função do Lambda.
Se o CloudWatch não conseguir acessar o serviço do Lambda ou se a mensagem for rejeitada por outro motivo, o CloudWatch tentará novamente até que a invocação seja bem-sucedida. O Lambda enfileira a mensagem e processa novas tentativas de execução. Para obter mais informações sobre esse modelo de execução, incluindo informações sobre como o Lambda lida com erros, consulte Invocação assíncrona no Guia do desenvolvedor do AWS Lambda.
Você pode invocar uma função do Lambda na mesma conta ou em outras contas da AWS.
Ao especificar um alarme para invocar uma função do Lambda como uma ação de alarme, é possível optar por especificar o nome da função, o alias da função ou uma versão específica de uma função.
Ao especificar uma função do Lambda como uma ação de alarme, você deve criar uma política de recursos para a função com a finalidade de permitir que a entidade principal de serviço do CloudWatch invoque a função.
Uma maneira de fazer isso é ao usar a AWS CLI, como no seguinte exemplo:
aws lambda add-permission \ --function-namemy-function-name\ --statement-id AlarmAction \ --action 'lambda:InvokeFunction' \ --principal lambda.alarms.cloudwatch.amazonaws.com \ --source-account111122223333\ --source-arn arn:aws:cloudwatch:us-east-1:111122223333:alarm:alarm-name
Como alternativa, é possível criar uma política semelhante a um dos exemplos apresentados a seguir e, em seguida, atribuí-la à função.
O exemplo apresentado a seguir especifica a conta na qual o alarme está localizado, portanto, somente os alarmes dessa conta (111122223333) podem invocar a função.
O exemplo apresentado a seguir tem um escopo mais restrito, permitindo que somente o alarme especificado na conta indicada invoque a função.
Não recomendamos a criação de uma política que não especifique uma conta de origem, porque essas políticas são vulneráveis a problemas de “confused deputy”.
Objeto de evento enviado do CloudWatch para o Lambda
Ao configurar uma função do Lambda como uma ação de alarme, o CloudWatch entrega uma carga JSON à função do Lambda quando invoca a função. Essa carga JSON serve como o objeto de evento para a função. É possível extrair dados desse objeto em JSON e usá-los em sua função. Veja a seguir um exemplo de um objeto de evento de um alarme de métrica.
{ 'source': 'aws.cloudwatch', 'alarmArn': 'arn:aws:cloudwatch:us-east-1:444455556666:alarm:lambda-demo-metric-alarm', 'accountId': '444455556666', 'time': '2023-08-04T12:36:15.490+0000', 'region': 'us-east-1', 'alarmData': { 'alarmName': 'lambda-demo-metric-alarm', 'state': { 'value': 'ALARM', 'reason': 'test', 'timestamp': '2023-08-04T12:36:15.490+0000' }, 'previousState': { 'value': 'INSUFFICIENT_DATA', 'reason': 'Insufficient Data: 5 datapoints were unknown.', 'reasonData': '{"version":"1.0","queryDate":"2023-08-04T12:31:29.591+0000","statistic":"Average","period":60,"recentDatapoints":[],"threshold":5.0,"evaluatedDatapoints":[{"timestamp":"2023-08-04T12:30:00.000+0000"},{"timestamp":"2023-08-04T12:29:00.000+0000"},{"timestamp":"2023-08-04T12:28:00.000+0000"},{"timestamp":"2023-08-04T12:27:00.000+0000"},{"timestamp":"2023-08-04T12:26:00.000+0000"}]}', 'timestamp': '2023-08-04T12:31:29.595+0000' }, 'configuration': { 'description': 'Metric Alarm to test Lambda actions', 'metrics': [ { 'id': '1234e046-06f0-a3da-9534-EXAMPLEe4c', 'metricStat': { 'metric': { 'namespace': 'AWS/Logs', 'name': 'CallCount', 'dimensions': { 'InstanceId': 'i-12345678' } }, 'period': 60, 'stat': 'Average', 'unit': 'Percent' }, 'returnData': True } ] } } }
Veja a seguir um exemplo de um objeto de evento de um alarme composto.
{ 'source': 'aws.cloudwatch', 'alarmArn': 'arn:aws:cloudwatch:us-east-1:111122223333:alarm:SuppressionDemo.Main', 'accountId': '111122223333', 'time': '2023-08-04T12:56:46.138+0000', 'region': 'us-east-1', 'alarmData': { 'alarmName': 'CompositeDemo.Main', 'state': { 'value': 'ALARM', 'reason': 'arn:aws:cloudwatch:us-east-1:111122223333:alarm:CompositeDemo.FirstChild transitioned to ALARM at Friday 04 August, 2023 12:54:46 UTC', 'reasonData': '{"triggeringAlarms":[{"arn":"arn:aws:cloudwatch:us-east-1:111122223333:alarm:CompositeDemo.FirstChild","state":{"value":"ALARM","timestamp":"2023-08-04T12:54:46.138+0000"}}]}', 'timestamp': '2023-08-04T12:56:46.138+0000' }, 'previousState': { 'value': 'ALARM', 'reason': 'arn:aws:cloudwatch:us-east-1:111122223333:alarm:CompositeDemo.FirstChild transitioned to ALARM at Friday 04 August, 2023 12:54:46 UTC', 'reasonData': '{"triggeringAlarms":[{"arn":"arn:aws:cloudwatch:us-east-1:111122223333:alarm:CompositeDemo.FirstChild","state":{"value":"ALARM","timestamp":"2023-08-04T12:54:46.138+0000"}}]}', 'timestamp': '2023-08-04T12:54:46.138+0000', 'actionsSuppressedBy': 'WaitPeriod', 'actionsSuppressedReason': 'Actions suppressed by WaitPeriod' }, 'configuration': { 'alarmRule': 'ALARM(CompositeDemo.FirstChild) OR ALARM(CompositeDemo.SecondChild)', 'actionsSuppressor': 'CompositeDemo.ActionsSuppressor', 'actionsSuppressorWaitPeriod': 120, 'actionsSuppressorExtensionPeriod': 180 } } }
Configurar como os alarmes do CloudWatch tratam dados ausentes
Às vezes, nem todos os pontos de dados esperados para uma métrica são relatados ao CloudWatch. Por exemplo, isso pode ocorrer quando uma conexão é perdida, um servidor é desativado, ou quando uma métrica informa apenas dados de forma intermitente por padrão.
O CloudWatch permite que você especifique como tratar pontos de dados ausentes ao avaliar um alarme. Isso pode ajudar a configurar seu alarme para passar ao estado ALARM quando for apropriado para o tipo de dados que está sendo monitorado. Você pode evitar falsos positivos quando dados ausentes não indicam um problema.
Assim como cada alarme está sempre em um dos três estados, cada ponto de dados específico relatado do CloudWatch se insere em uma destas três categorias:
-
Não violar (dentro do limite)
-
Violar (violando o limite)
-
Missing (Ausente)
Para cada alarme, é possível especificar o CloudWatch para tratar pontos de dados ausentes como qualquer uma destas opções:
-
notBreaching: os pontos de dados ausentes são tratados como "bons" e dentro do limite -
breaching: os pontos de dados ausentes são tratados como “ruins” e violando o limite -
ignore: o estado do alarme atual é mantido -
missing: se todos os pontos de dados no intervalo de avaliação do alarme estiverem ausentes, o alarme passará para INSUFFICIENT_DATA.
A melhor opção depende do tipo de métrica e da finalidade do alarme. Por exemplo, se você estiver criando um alarme de reversão de aplicações usando uma métrica que relata dados continuamente, pode desejar tratar os pontos de dados ausentes como uma violação, pois isso pode indicar que há algo de errado. No entanto, para uma métrica que gera pontos de dados somente quando ocorre um erro, como ThrottledRequests no Amazon DynamoDB, é possível tratar dados ausentes como notBreaching. O comportamento padrão é missing.
Importante
Os alarmes configurados nas métricas do Amazon EC2 podem entrar temporariamente no estado INSUFFICIENT_DATA se houver pontos de dados de métricas ausentes. Isso é raro, mas pode acontecer quando o relatório de métricas é interrompido, mesmo quando a instância do Amazon EC2 está íntegra. Para os alarmes nas métricas do Amazon EC2 que estão configurados para executar ações de interrupção, encerramento, reinicialização ou recuperação, recomendamos configurar esses alarmes para tratar os dados ausentes como missing e para que esses alarmes sejam acionados somente quando estiverem no estado ALARM.
Escolher a melhor opção para seu alarme evita alterações desnecessárias e enganosas e também indica com mais precisão a integridade do seu sistema.
Importante
Alarmes que avaliam métricas no namespace AWS/DynamoDB sempre ignoram dados ausentes, mesmo que você escolha uma opção diferente para como o alarme deve tratar dados ausentes. Quando uma métrica AWS/DynamoDB tem dados ausentes, os alarmes que avaliam essa métrica permanecem no estado em que estiverem na ocasião.
Como o estado do alarme é avaliado quando há dados ausentes
Sempre que um alarme avalia se é necessário alterar o estado, o CloudWatch tenta recuperar um maior número de pontos de dados do que o número especificado em Evaluation Periods (Períodos de avaliação). O número exato de pontos de dados que ele tenta recuperar depende do tamanho do período de alarme e se ele é baseado em uma métrica com resolução padrão ou alta. O período de pontos de dados que ele tenta recuperar é o intervalo de avaliação.
Assim que o CloudWatch recupera esses pontos de dados, ocorre o seguinte:
Se não houver pontos de dados ausentes no intervalo de avaliação, o CloudWatch avaliará o alarme com base nos pontos de dados mais recentes coletados. O número de pontos de dados avaliados é igual ao valor de Evaluation Periods (Períodos de avaliação) do alarme. Os pontos de dados excedentes mais antigos no intervalo de avaliação não são necessários e são ignorados.
Se alguns pontos de dados no intervalo de avaliação estiverem ausentes, mas o total de pontos de dados recuperados corretamente for igual ou maior que os Evaluation Periods (Períodos de avaliação) do alarme, o CloudWatch avaliará o estado do alarme com base nos pontos de dados reais mais recentes que foram recuperados corretamente, inclusive os pontos de dados excedentes necessários mais antigos no período de avaliação. Nesse caso, o valor que você define para como tratar dados ausentes não é necessário e é ignorado.
Se alguns pontos de dados no intervalo de avaliação estiverem ausentes e o número de pontos de dados reais que foram recuperados for menor do que o número de Evaluation Periods (Períodos de avaliação) do alarme, o CloudWatch preencherá os pontos de dados ausentes com o resultado especificado sobre como tratar dados ausentes e avaliará o alarme. Contudo, todos os pontos de dados reais no intervalo de avaliação serão incluídos na avaliação. O CloudWatch usa pontos de dados ausentes o mínimo possível.
nota
Um caso específico desse comportamento é que os alarmes do CloudWatch podem reavaliar repetidamente o último conjunto de pontos de dados por um período depois que o fluxo da métrica é interrompido. Essa reavaliação pode fazer com que o estado do alarme mude e as ações sejam executadas novamente, se ele tiver sido alterado imediatamente antes do fluxo de métrica ser interrompido. Para atenuar esse comportamento, use períodos mais curtos.
As tabelas a seguir ilustram exemplos do comportamento de avaliação de alarme. Na primeira tabela, Datapoints to Alarm (Pontos de dados para alarme) e Evaluation Periods (Períodos de avaliação) são 3. O CloudWatch recupera os cinco pontos de dados mais recentes ao avaliar o alarme, caso algum dos três pontos de dados mais recentes esteja ausente. O intervalo de avaliação do alarme é 5.
A coluna 1 exibe os cinco pontos de dados mais recentes, pois o intervalo de avaliação é 5. Esses pontos de dados são exibidos com o ponto de dados mais recente à direita, em que 0 é um ponto de dados de não violação, X é um ponto de dados violação e - é um ponto de dados ausente.
A coluna 2 mostra quantos dos 3 pontos de dados necessários estão ausentes. Embora os 5 pontos de dados mais recentes sejam avaliados, apenas 3 (a configuração para Evaluation Periods (Períodos de avaliação)) são necessárias para avaliar o estado do alarme. O número de pontos de dados na coluna 2 é o número de pontos de dados que devem ser "preenchidos", usando a configuração de como dados ausentes estão sendo tratados.
Nas colunas de 3 a 6, os cabeçalhos de coluna são os valores possíveis para tratar dados ausentes. As linhas dessas colunas mostram o estado do alarme definido para cada uma dessas possíveis formas de tratar dados ausentes.
| Pontos de dados | Número de pontos de dados que deverão ser preenchidos | MISSING (AUSENTE) | IGNORE | VIOLAÇÃO | NÃO VIOLAÇÃO |
|---|---|---|---|---|---|
|
0 - X - X |
0 |
|
|
|
|
|
- - - - 0 |
2 |
|
|
|
|
|
- - - - - |
3 |
|
Reter estado atual |
|
|
|
0 X X - X |
0 |
|
|
|
|
|
- - X - - |
2 |
|
Reter estado atual |
|
|
Na segunda linha da tabela anterior, o alarme permanece em OK mesmo que os dados ausentes sejam tratados como violação, porque um ponto de dados existente não está violando o limite, e isso é avaliado junto com dois pontos de dados ausentes que são tratados como violação. Na próxima vez em que esse alarme for avaliado, se os dados ainda estiverem ausentes, ele passará para ALARM, pois esse ponto de dados de não violação não estará mais no intervalo de avaliação.
A terceira linha, onde todos os cinco pontos de dados mais recentes estão ausentes, ilustra como as várias configurações para tratar dados ausentes afetam o estado do alarme. Se os pontos de dados ausentes forem considerados de violação, o alarme entrará no estado ALARM; caso forem considerados de não violação, o alarme entrará no estado OK. Se os pontos de dados ausentes forem ignorados, o alarme reterá o estado atual que tinha antes dos pontos de dados ausentes. E se os pontos de dados ausentes são apenas considerados ausentes, então o alarme não tem dados reais recentes suficientes para fazer uma avaliação e passa para INSUFFICIENT_DATA.
Na quarta linha, o alarme passa para o estado ALARM em todos os casos porque os três pontos de dados mais recentes estão em violação, e tanto os Evaluation Periods (Períodos de avaliação) como os Datapoints to Alarm (Pontos de Dados para Alarme) do alarme são ambos definidos como 3. Nesse caso, o ponto de dados que falta é ignorado, e a configuração para como avaliar dados que estão faltando não é necessária, pois há 3 pontos de dados reais para avaliar.
A linha 5 representa um caso especial de avaliação de alarme chamado estado de alarme prematuro. Para obter mais informações, consulte Evitar transições prematuras para o estado do alarme.
Na próxima tabela, o Period (Período) é novamente definido como 5 minutos, e Datapoints to Alarm (Pontos de dados para alarme) é somente 2, enquanto Evaluation Periods (Períodos de avaliação) é 3. Esse é um alarme 2 de 3, M de N.
O intervalo de avaliação é 5. Esse é o número máximo de pontos de dados recentes que são recuperados e podem ser usados caso alguns pontos de dados estejam ausentes.
| Pontos de dados | Número de pontos de dados ausentes | AUSENTE | IGNORE | VIOLAÇÃO | NÃO VIOLAÇÃO |
|---|---|---|---|---|---|
|
0 - X - X |
0 |
|
|
|
|
|
0 0 X 0 X |
0 |
|
|
|
|
|
0 - X - - |
1 |
|
|
|
|
|
- - - - 0 |
2 |
|
|
|
|
|
- - - - X |
2 |
|
Reter estado atual |
|
|
Nas linhas 1 e 2, o alarme sempre passa para o estado ALARM porque dois dos três pontos de dados mais recentes estão em violação. Na linha 2, os dois pontos de dados mais antigos no intervalo de avaliação não são necessários porque nenhum dos três pontos de dados mais recentes está ausente. Portanto, esses dois pontos de dados mais antigos são ignorados.
Nas linhas 3 e 4, o alarme só passará para o estado ALARM se os dados ausentes forem tratados como violação, e nesse caso os dois pontos de dados ausentes mais recentes serão tratados como violação. Na linha 4, esses dois pontos de dados ausentes que são tratados como violação fornecem os dois pontos de dados de violação necessários para acionar o estado ALARM.
A linha 5 representa um caso especial de avaliação de alarme chamado estado de alarme prematuro. Para obter mais informações, consulte a seção a seguir.
Evitar transições prematuras para o estado do alarme
A avaliação de alarmes do CloudWatch inclui lógica para tentar evitar alarmes falsos, nos quais o alarme entra no estado ALARM prematuramente quando os dados são intermitentes. O exemplo da linha 5 nas tabelas da seção anterior ilustra essa lógica. Nessas linhas e nos exemplos a seguir, os Evaluation Periods (Períodos de avaliação) são 3, e o intervalo de avaliação é de 5 pontos de dados. Os Datapoints to Alarm (Pontos de dados para alarme) são 3, exceto para o exemplo M de N, em que os Datapoints to Alarm são 2.
Suponha que os dados mais recentes de um alarme sejam - - - - X, com quatro pontos de dados ausentes e um ponto de dados de violação como ponto de dados mais recente. Como o próximo ponto de dados pode não ser violado, o alarme não entra imediatamente no estado ALARM quando os dados são - - - - X ou - - - X - e Datapoints to Alarm (Pontos de dados para alarme) são 3. Desta forma, evitam-se os falsos positivos quando o próximo ponto de dados for de não violação e faz com que os dados sejam - - - X O ou - - X - O.
Porém, se os últimos pontos de dados forem - - X - -, o alarme entra no estado ALARM mesmo se os pontos de dados ausentes forem tratados como ausentes. Isso ocorre porque os alarmes são projetados para sempre entrar no estado ALARM quando o ponto de dados de violação mais antigo disponível durante o número de pontos de dados dos Evaluation Periods (Períodos de avaliação) é pelo menos tão antigo quanto o valor dos Datapoints to Alarm (Pontos de dados para alarme) e todos os outros pontos de dados mais recentes estão em violação ou ausentes. Neste caso, o alarme entra no estado ALARM mesmo que o número total de pontos de dados disponíveis seja inferior a M Datapoints to Alarm (Pontos de dados para alarme).
Essa lógica de alarme também se aplica a alarmes M de N. Se o ponto de dados em violação mais antigo durante o intervalo de avaliação for pelo menos tão antigo quanto o valor de Datapoints to Alarm (Pontos de dados para alarme), e todos os pontos de dados mais recentes estiverem em violação ou ausentes, o alarme entrará no estado ALARM para qualquer valor de M Datapoints to Alarm (Pontos de dados para alarme).
Alarmes de alta resolução
Se você definir um alarme em uma métrica de alta resolução, poderá especificar um alarme de alta resolução com um período de 10, 20 ou 30 segundos ou poderá definir um alarme regular com um período de qualquer múltiplo de 60 segundos. Há um custo maior para alarmes de alta resolução. Para obter mais informações sobre as métricas de alta resolução, consulte Publicar métricas personalizadas.
Alarmes em expressões matemáticas
Defina um alarme com base no resultado de uma expressão matemática baseada em uma ou mais métricas do CloudWatch. Uma expressão matemática usada para um alarme pode incluir até 10 métricas. Toda métrica deve estar usando o mesmo período.
Para um alarme baseado em uma expressão matemática, é possível especificar como você deseja que o CloudWatch trate pontos de dados ausentes. Nesse caso, o ponto de dados é considerado ausente se a expressão matemática não retornar um valor para esse ponto de dados.
Os alarmes baseados em expressões matemáticas não poderão realizar ações do Amazon EC2.
Para obter mais informações sobre expressões matemáticas e sintaxe de métrica, consulte Uso de expressões matemáticas com as métricas do CloudWatch.
Alarmes do CloudWatch baseados em percentual e exemplos de poucos dados
Quando você define um percentil como a estatística para um alarme, você pode especificar o que fazer quando não há dados suficientes para uma boa avaliação estatística. Você pode escolher que o alarme avalie a estatística de qualquer forma e possivelmente altere o estado do alarme. Ou você pode determinar que o alarme ignore a métrica enquanto o tamanho da amostra for baixo e esperar para avaliá-la até que haja dados suficientes para serem estatisticamente significativos.
Para percentis entre 0,5 (inclusive) e 1,00 (exclusive), essa configuração é usada quando há menos de 10/(1 percentil) pontos de dados durante o período de avaliação. Por exemplo, essa configuração seria usada se houvesse menos do que 1.000 amostras para um alarme em um p99 percentil. Para percentis entre 0 e 0,5 (exclusive), a configuração é usada quando há menos de 10/percentil pontos de dados.
Recursos comuns dos alarmes do CloudWatch
Estes recursos se aplicam a todos os alarmes do CloudWatch:
-
Não há limite para o número de alarmes que você pode criar. Para criar ou atualizar um alarme, use o console do CloudWatch, a ação PutMetricAlarm da API ou o comando put-metric-alarm na AWS CLI.
-
Os nomes dos alarmes devem conter somente caracteres UTF-8 da e não podem conter caracteres de controle ASCII
-
É possível listar um ou todos os alarmes configurados no momento e listar todos os alarmes em um determinado estado usando o console do CloudWatch, a ação DescribeAlarms da API ou o comando describe-alarms na AWS CLI.
-
É possível desabilitar e habilitar ações de alarmes usando as ações DisableAlarmActions e EnableAlarmActions da API ou os comandos disable-alarm-actions e enable-alarm-actions na AWS CLI.
-
É possível testar um alarme configurando-o para qualquer estado usando a ação SetAlarmState da API ou o comando set-alarm-state na AWS CLI. Essa alteração de estado temporária dura somente até ocorrer a próxima comparação de alarmes.
-
É possível criar um alarme para uma métrica personalizada antes de criar essa métrica personalizada. Para o alarme ser válido, é necessário incluir todas as dimensões para a métrica personalizada, além do namespace e do nome da métrica na definição do alarme. Para fazer isso, você pode usar a ação PutMetricAlarm da API ou o comando put-metric-alarm na AWS CLI.
-
É possível exibir o histórico de um alarme usando o console do CloudWatch, a ação DescribeAlarmHistory da API ou o comando describe-alarm-history na AWS CLI. O CloudWatch preserva o histórico de alarmes por 30 dias. Cada transição de estado é marcada com um time stamp exclusivo. Em casos raros, o histórico pode mostrar mais de uma notificação para uma alteração de estado. O time stamp permite confirmar alterações de estado exclusivas.
-
Você pode adicionar alarmes como favoritos na opção Favorites and recents (Favoritos e recentes) no painel de navegação do console do CloudWatch movendo o ponteiro do mouse sobre o alarme que deseja adicionar e escolhendo o símbolo de estrela próximo a ele.
-
Os alarmes têm uma cota de período de avaliação. O período de avaliação é calculado multiplicando-se o período do alarme pelo número de períodos de avaliação utilizados.
O período máximo de avaliação é de sete dias para alarmes com um período de pelo menos uma hora (3.600 segundos).
O período máximo de avaliação é de um dia para alarmes com um período mais curto.
O período máximo de avaliação é de um dia para alarmes que usam a fonte de dados do Lambda personalizada.
nota
Alguns recursos da AWS não enviam dados de métrica para o CloudWatch em determinadas condições.
Por exemplo, o Amazon EBS não pode enviar dados de métrica para um volume disponível que não esteja anexado a uma instância do Amazon EC2, porque não há atividade de métrica a ser monitorada para esse volume. Se você tiver um alarme definido para essa métrica, poderá visualizar a alteração do estado para INSUFFICIENT_DATA. Isso pode indicar que o recurso está inativo e não necessariamente indicar que há um problema. É possível especificar como cada alarme lida com os dados ausentes. Para obter mais informações, consulte Configurar como os alarmes do CloudWatch tratam dados ausentes.
