Usar o Amazon Aurora Global Database
Com o recurso Amazon Aurora Global Database, você configura vários clusters de banco de dados do Aurora que abrangem várias Regiões da AWS. O Aurora sincroniza automaticamente todas as alterações feitas no cluster de banco de dados primário com um ou mais clusters secundários. Um Aurora Global Database tem um cluster de banco de dados primário em uma região e até dez clusters de banco de dados secundários em diferentes regiões. Essa configuração de várias regiões oferece recuperação rápida de qualquer interrupção incomum que possa afetar uma Região da AWS inteira. Ter uma cópia completa de todos os dados em várias localizações geográficas também viabiliza operações de leitura de baixa latência em aplicações que se conectam de locais extremamente separados em todo o mundo.
Tópicos
Visão geral do Amazon Aurora Global Database
Ao usar o recurso Amazon Aurora Global Database, é possível executar as aplicações distribuídas globalmente usando um único banco de dados do Aurora que abrange várias Regiões da AWS.
Um Aurora Global Database consiste em uma Região da AWS principal, onde seus dados são utilizados, e até dez Regiões da AWS secundárias apenas para leitura. Envie operações de gravação ao cluster de banco de dados primário na Região da AWS primária. A maneira mais conveniente de fazer isso é conectar-se ao endpoint do gravador do Aurora Global Database, que sempre aponta para o cluster de banco de dados primário, mesmo após uma transição ou um failover para outra Região da AWS. Após qualquer operação, o Aurora replica dados para as Regiões da AWS secundárias que usam infraestrutura exclusiva, com latência normalmente inferior a um segundo.
O diagrama a seguir mostra um exemplo de Aurora Global Database que abrange duas Regiões da AWS.
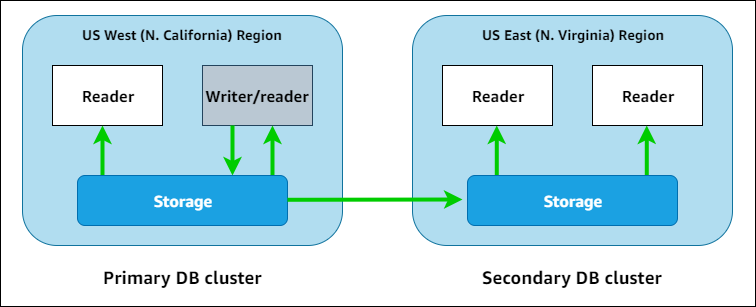
É possível aumentar a escala verticalmente de cada cluster secundário de maneira independente, adicionando uma ou mais instâncias do leitor do Aurora para atender a workloads somente leitura. É possível usar o Aurora Serverless v2 para as instâncias do leitor a fim de ter uma escalabilidade ainda mais granular e flexível.
Somente o cluster primário realiza operações de gravação. Os clientes que realizam operações de gravação se conectam ao endpoint do gravador do Aurora Global Database, que sempre aponta para a instância de banco de dados do gravador do cluster primário. Como mostrado no diagrama, o Aurora usa o volume de armazenamento de cluster e não o mecanismo de banco de dados para replicação rápida e de baixo custo. Para saber mais, consulte Visão geral do armazenamento do Amazon Aurora.
O Aurora Global Database é projetado para aplicações com uma presença mundial. Os clusters de banco de dados secundários somente leitura em várias Regiões da AWS ajudam a otimizar operações de leitura mais próximas dos usuários da aplicação. Ao usar o recurso de encaminhamento de gravação, você também pode configurar um banco de dados global para que os clusters secundários enviem solicitações de gravação ao primário. Para obter mais informações, consulte Como usar o encaminhamento de gravação em um banco de dados global Amazon Aurora.
O Aurora Global Database oferece suporte a duas operações diferentes para alterar a região do cluster de banco de dados primário, dependendo do cenário: transição do Aurora Global Database e failover do Aurora Global Database.
-
Para procedimentos operacionais planejados, como troca regional, use o mecanismo de transição (anteriormente chamado de “failover planejado gerenciado”). Com esse recurso, é possível realocar o cluster primário de um Aurora Global Database íntegro para uma de suas regiões secundárias sem perda de dados. Para saber mais, consulte Realizar transições para o Amazon Aurora Global Database.
-
Para recuperar o Aurora Global Database após uma interrupção na região primária, use o mecanismo de failover. Com esse recurso, você realiza um failover do cluster de banco de dados primário para outra região (failover entre regiões). Para saber mais, consulte Failovers planejados gerenciados para o Aurora Global Database.
Vantagens do Amazon Aurora Global Database
Ao usar o Aurora Global Database, você pode ter as seguintes vantagens:
Leituras globais com latência local: se você tem escritórios em todo o mundo, pode usar o Aurora Global Database para manter suas principais fontes de informações atualizadas na Região da AWS primária. Escritórios em outras regiões podem acessar as informações em sua própria região com latência local.
Clusters de banco de dados secundários do Aurora escaláveis: é possível escalar os clusters secundários adicionando mais instâncias somente leitura a uma Região da AWS secundária. O cluster secundário é somente leitura, portanto, é compatível com até 16 instâncias de banco de dados somente leitura em vez do limite normal de 15 para um único cluster do Aurora.
Replicação rápida de clusters de banco de dados do Aurora primários para secundários: a replicação realizada pelo Aurora Global Database tem pouco impacto no desempenho do cluster de banco de dados primário. Os recursos das instâncias de banco de dados são totalmente dedicados para atender as workloads de leitura e gravação.
Recuperação de interrupções em toda a região: os clusters secundários permitem que você disponibilize um Aurora Global Database em uma nova Região da AWS primária mais depressa (menor RTO) e com menor perda de dados (menor RPO) do que as soluções tradicionais de replicação.
Disponibilidade de regiões e versões
A disponibilidade e a compatibilidade de recursos variam entre versões específicas de cada mecanismo de banco de dados do Aurora e entre Regiões da AWS. Para ter mais informações sobre a disponibilidade de versões e de regiões com o Aurora Global Database, consulte Regiões e mecanismos de banco de dados compatíveis com bancos de dados globais do Aurora.
Limitações do Amazon Aurora Global Database
No momento, as seguintes limitações se aplicam ao Aurora Global Database:
O Aurora Global Database está disponível em determinadas Regiões da AWS e para versões específicas do Aurora MySQL e do Aurora PostgreSQL. Para obter mais informações, consulte Regiões e mecanismos de banco de dados compatíveis com bancos de dados globais do Aurora.
O Aurora Global Database tem requisitos específicos de configuração para classes de instância de banco de dados do Aurora aceitas, número máximo de Regiões da AWS etc. Para obter mais informações, consulte Requisitos de configuração do banco de dados do Amazon Aurora global.
Para compatibilidade do Aurora MySQL com MySQL 5.7, as transições do Aurora Global Database exigem a versão 2.09.1 ou uma versão secundária posterior.
-
Só é possível realizar transições ou failovers gerenciados entre regiões com o Aurora Global Database caso os clusters de banco de dados primário e secundário tenham as mesmas versões principal e secundária. Dependendo do mecanismo e de suas respectivas versões, os níveis de patch podem precisar ser idênticos ou podem ser diferentes. Para conferir uma lista de mecanismos e suas respectivas versões que permitem essas operações entre clusters primários e secundários com diferentes níveis de patch, consulte Compatibilidade em nível de patch para transições e failovers gerenciados entre regiões. Se as versões do mecanismo exigirem níveis de patch idênticos, será possível realizar o failover manualmente seguindo as etapas em Realizar failovers manuais para bancos de dados globais do Aurora.
O Aurora Global Database ainda não oferece suporte aos seguintes recursos do Aurora:
-
Aurora Serverless v1
-
Retroceder no Aurora
-
Para saber as limitações ao uso do recurso RDS Proxy com o Aurora Global Database, consulte Limitações do RDS Proxy com bancos de dados globais.
A atualização automática da versão secundária não se aplica a clusters do Aurora MySQL e do Aurora PostgreSQL que fazem parte de um banco de dados global. Observe que você pode especificar essa configuração para uma instância de banco de dados que faz parte de um cluster de banco de dados global, mas a configuração não tem qualquer efeito.
O Aurora Global Database ainda não oferece suporte ao Aurora Auto Scaling para clusters de banco de dados secundários.
Para usar o Database Activity Streams (DAS) no Aurora Global Database executando o Aurora MySQL 5.7, a versão do mecanismo deve ser 2.08 ou posterior. Para ter mais informações sobre DAS, consulte Monitorar o Amazon Aurora com o recurso Database Activity Streams.
-
No momento, as seguintes limitações se aplicam à atualização do Aurora Global Database:
Você não pode aplicar um grupo de parâmetros personalizado ao cluster de banco de dados global enquanto estiver executando uma atualização de versão principal desse banco de dados global do Aurora. Crie seus grupos de parâmetros personalizados em cada região do cluster global e, depois, aplique-os manualmente aos clusters regionais após a atualização.
-
Com um banco de dados Aurora global baseado no Aurora MySQL, você não poderá executar uma atualização no local do Aurora MySQL versão 2 para a versão 3 se o parâmetro
lower_case_table_namesestiver ativado. Para ter mais informações sobre os métodos que você pode usar, consulte Atualizações de versão principal. Com o Aurora Global Database, não será possível realizar uma atualização de versão principal do mecanismo de banco de dados do Aurora PostgreSQL se o recurso de objetivo de ponto de recuperação (RPO) estiver ativado. Para ter mais informações sobre o recurso RPO, consulte Gerenciamento de RPOs para bancos de dados globais baseados em Aurora PostgreSQL–.
Com um Aurora Global Database, não é possível realizar uma atualização de versão secundária do Aurora MySQL 3.01 ou 3.02 para 3.03 ou posterior utilizando o processo padrão. Para obter detalhes sobre processo que deve ser utilizado, consulte Atualizar o Aurora MySQL modificando a versão do mecanismo.
Para ter informações sobre como atualizar o Aurora Global Database, consulte Atualizar um Amazon Aurora Global Database.
Não é possível interromper nem iniciar os clusters de banco de dados do Aurora em seu banco de dados global individualmente. Para saber mais, consulte Interromper e iniciar um cluster de banco de dados do Amazon Aurora.
Instâncias de banco de dados do leitor do Aurora anexadas ao cluster de banco de dados do Aurora secundário podem ser reiniciadas em determinadas circunstâncias. Se a instância de banco de dados do gravador da Região da AWS primária for reiniciada ou sofrer failover, as instâncias de banco de dados do leitor em regiões secundárias também serão reiniciadas. O cluster secundário fica indisponível até que todas as instâncias de banco de dados do leitor estejam novamente sincronizadas com a instância do gravador do cluster de banco de dados primário. O comportamento do cluster primário durante a reinicialização ou o failover é igual ao de um cluster de banco de dados único e não global. Para obter mais informações, consulte Replicação com o Amazon Aurora.
Certifique-se de entender os impactos no seu banco de dados global antes de fazer alterações no cluster de banco de dados primário. Para saber mais, consulte Recuperar um banco de dados global Amazon Aurora de uma interrupção não planejada.
O Aurora Global Database ainda não oferece suporte ao status
inaccessible-encryption-credentials-recoverablequando o Amazon Aurora perde o acesso à chave do AWS KMS do cluster de banco de dados. Nesses casos, o cluster de banco de dados criptografado entra diretamente no estado terminalinaccessible-encryption-credentials. Para mais informações sobre esses estados, consulte Visualizar o status do cluster do banco de dados.-
O Secrets Manager não é compatível com o Aurora Global Database. Ao adicionar uma região a um banco de dados global, você deve primeiro desativar a integração do Secrets Manager para a instância de banco de dados.
-
Os clusters de banco de dados baseados em Aurora PostgreSQL que usam o Aurora Global Database têm as seguintes limitações:
Não há suporte ao gerenciamento de cache de cluster para clusters de banco de dados secundários do Aurora PostgreSQL que fazem parte de bancos de dados globais do Aurora.
-
Se o cluster primário do banco de dados global for baseado em uma réplica de uma instância do Amazon RDS PostgreSQL, não será possível criar um cluster secundário. Não tente criar um secundário a partir desse cluster usando a operação AWS Management Console, AWS CLI ou API da
CreateDBCluster. As tentativas de fazer isso expiram e o cluster secundário não é criado.
Recomendamos criar clusters de banco de dados secundários para os bancos de dados globais usando a mesma versão do mecanismo de banco de dados do Aurora como primário. Para obter mais informações, consulte Criar um banco de dados global do Amazon Aurora.
