Usar a transição ou o failover no Amazon Aurora Global Database
O recurso Aurora Global Database oferece maior proteção à continuidade dos negócios e recuperação de desastres (BCDR) do que a alta disponibilidade padrão oferecida por um cluster de banco de dados do Aurora em uma única Região da AWS. Quando o Aurora Global Database é utilizado, é possível planejar a recuperação mais rápida de desastres regionais raros ou concluir depressa as interrupções de serviço.
Consulte as diretrizes e os procedimentos a seguir para planejar, testar e implementar sua estratégia de BCDR utilizando o recurso Aurora Global Database.
Tópicos
Planejar a continuidade dos negócios e a recuperação de desastres
Para planejar sua estratégia de continuidade de negócios e recuperação de desastres, é útil entender a terminologia do setor a seguir e como esses termos se relacionam aos recursos do Aurora Global Database.
A recuperação de desastres geralmente é motivada pelos dois objetivos de negócios a seguir:
-
Objetivo de tempo de recuperação (RTO): o tempo que um sistema leva para retornar a um estado funcional após um desastre. Em outras palavras, o RTO mede o tempo de inatividade. Com relação ao Aurora Global Database, o RTO pode estar na ordem dos minutos.
-
Objetivo de ponto de recuperação (RPO): a quantidade de dados que podem ser perdidos (medidos no tempo) após um desastre ou interrupção de serviço. Essa perda de dados costuma decorrer de um atraso na replicação assíncrona. Para um banco de dados globalAurora, o RPO é normalmente medido em segundos. Com um banco de dados global Aurora PostgreSQL–baseado, você pode usar o parâmetro
rds.global_db_rpopara definir e rastrear o limite superior no RPO, mas isso pode afetar o processamento de transações no nó do gravador do cluster primário. Para obter mais informações, consulte Gerenciamento de RPOs para bancos de dados globais baseados em Aurora PostgreSQL–.
A realização de uma transição ou um failover com o Aurora Global Database envolve promover um cluster de banco de dados secundário a cluster de banco de dados primário. O termo “interrupção regional” é frequentemente usado para descrever uma variedade de cenários de falha. O pior cenário pode ser uma interrupção generalizada causada por um evento catastrófico que afeta centenas de quilômetros quadrados. No entanto, a maioria das interrupções é muito mais localizada, afetando apenas um pequeno subconjunto de serviços de nuvem ou sistemas de clientes. Considere o escopo completo da interrupção para garantir que o failover entre regiões seja a solução adequada e para escolher o método de failover apropriado para a situação. A opção pela abordagem de failover ou de transição depende do cenário específico de interrupção:
-
Failover: use essa abordagem para se recuperar de uma interrupção não planejada. Com ela, você executa um failover entre regiões para um dos clusters de banco de dados secundários no banco de dados global do Aurora. O RPO para essa abordagem geralmente é um valor diferente de zero medido em segundos. A quantidade de perda de dados depende do atraso de replicação do banco de dados global do Aurora em todas as Regiões da AWS no momento da falha. Para saber mais, consulte Recuperar um banco de dados global Amazon Aurora de uma interrupção não planejada.
-
Transição: anteriormente, essa operação era chamada de “failover planejado gerenciado”. Use essa abordagem para ambientes controlados, como manutenção operacional e outros procedimentos operacionais planejados em que todos os clusters do Aurora e outros serviços com os quais eles interagem estão íntegros. Como esse recurso sincroniza clusters de banco de dados secundários com o primário antes de fazer outras alterações, o RPO é 0 (sem perda de dados). Para saber mais, consulte Realizar transições para o Amazon Aurora Global Database.
nota
Para que seja possível realizar a transição ou o failover para um cluster de banco de dados secundário do Aurora sem periféricos/sem interface gráfica, será necessário adicionar uma instância de banco de dados a ele. Para obter mais informações sobre clusters de banco de dados sem cabeçalho, consulte Criando um cluster de banco de dados Aurora dedicado em uma região secundária.
Realizar transições para o Amazon Aurora Global Database
nota
Anteriormente, as transições eram chamadas de failovers planejados gerenciados.
Ao usar transições, é possível alterar a região do cluster primário rotineiramente. Essa abordagem destina-se a ambientes controlados, como manutenção operacional e outros procedimentos operacionais planejados.
Há três casos de uso comuns para o uso de transições.
-
Para requisitos de “alternância regional” impostos a setores específicos. Por exemplo, os regulamentos de serviços financeiros podem querer que os sistemas de nível 0 mudem para uma região diferente por vários meses a fim de garantir que os procedimentos de recuperação de desastres sejam executados regularmente.
-
Para aplicações multirregionais ininterruptas (dia e noite). Por exemplo, uma empresa pode querer fornecer gravações de menor latência em diferentes regiões com base no horário comercial em diferentes fusos horários.
-
Como um método sem perda de dados para fazer failback para a região primária original após um failover.
nota
As transições foram projetadas para serem usadas em um Aurora Global Database, no qual todos os clusters do Aurora e outros serviços com os quais eles interagem estão íntegros. Para se recuperar de uma interrupção não planejada, siga o procedimento apropriado em Recuperar um banco de dados global Amazon Aurora de uma interrupção não planejada.
Só é possível realizar transições gerenciadas entre regiões com o Aurora Global Database caso os clusters de banco de dados primário e secundário tenham as mesmas versões principal e secundária do mecanismo. Dependendo do mecanismo e de suas respectivas versões, os níveis de patch podem precisar ser idênticos ou podem ser diferentes. Para conferir uma lista de mecanismos e suas respectivas versões que permitem essas operações entre clusters primários e secundários com diferentes níveis de patch, consulte Compatibilidade em nível de patch para transições e failovers gerenciados entre regiões. Antes de iniciar a transição, verifique as versões do mecanismo no cluster global para garantir que elas sejam compatíveis com a transição gerenciada entre regiões e atualize-as se necessário.
Durante uma transição, o Aurora promove o cluster na região secundária escolhida a cluster primário. O mecanismo de transição mantém a topologia de replicação existente do banco de dados global: ele ainda tem o mesmo número de clusters do Aurora nas mesmas regiões. Antes de iniciar o processo de transição, o Aurora espera que os clusters de destino da região secundária estejam totalmente sincronizados com o cluster da região principal. Depois, o cluster de banco de dados na região primária se torna somente leitura. O cluster secundário escolhido promove um de seus nós somente leitura ao status de gravador completo, permitindo assim que o cluster secundário assuma o papel do cluster primário. Como o cluster de destino secundário foi sincronizado com o primário no início do processo, o novo primário continua as operações para o banco de dados global do Aurora sem perder dados. Seu banco de dados fica indisponível por um curto período enquanto os clusters primários e secundários selecionados estão assumindo suas novas funções.
nota
Para gerenciar slots de replicação para o Aurora PostgreSQL depois de realizar uma transição, consulte Gerenciar slots lógicos para o Aurora PostgreSQL .
Para otimizar a disponibilidade do aplicativo, recomendamos que você faça o seguinte antes de usar esse recurso:
-
Execute essa operação em períodos de pouca demanda ou em outro momento quando as gravações no cluster de banco de dados primário forem mínimas.
-
Verifique os tempos de atraso para ver se há todos os clusters de banco de dados Aurora secundários no banco de dados global Aurora. Para todos os bancos de dados globais baseados no Aurora PostgreSQL e para bancos de dados globais baseados no Aurora MySQL a partir das versões 3.04.0 e posteriores do mecanismo, ou 2.12.0 e posteriores, use o Amazon CloudWatch para visualizar a métrica
AuroraGlobalDBRPOLagpara todos os clusters de banco de dados secundários. Para versões secundárias anteriores dos bancos de dados globais baseados no Aurora MySQL, veja a métricaAuroraGlobalDBReplicationLag. Essa métrica informa a distância (em milissegundos) de um secundário em relação ao cluster de banco de dados primário. Esse valor é diretamente proporcional ao tempo que o Aurora levará para concluir a transição. Portanto, quanto maior o valor do atraso, mais tempo a transição levará. Examine essas métricas por meio do cluster primário atual.Para ter mais informações sobre métricas CloudWatch de Aurora, consulte Métricas no nível do cluster do Amazon Aurora.
-
O cluster de banco de dados secundário que é promovido durante uma transição pode ter configurações diferentes do antigo cluster de banco de dados primário. Recomendamos manter os tipos de configuração a seguir consistentes em todos os clusters do Aurora Global Database. Isso ajuda a minimizar os problemas de desempenho, as incompatibilidades de workload e outros comportamentos anômalos após uma transição.
-
Configure o grupo de parâmetros do cluster de banco de dados do Aurora como o novo primário, se necessário: quando um cluster de banco de dados secundário é promovido a primário, o grupo de parâmetros do secundário pode ser configurado diferentemente do primário. Em caso afirmativo, modifique o parameter group do cluster de banco de dados secundário promovido para estar em conformidade com as configurações do cluster principal. Para saber como, consulte Modificando parâmetros para um banco de dados do Aurora global.
-
Configurar ferramentas e opções de monitoramento, como Amazon CloudWatch Events e alarmes – Configurar o cluster de banco de dados promovido com a mesma capacidade de registro, alarmes e assim por diante, conforme necessário para o banco de dados global. Tal como ocorre com os grupos de parâmetros, a configuração desses recursos não é herdada do primário no processo de transição. Algumas métricas do CloudWatch, como atraso na replicação, só estão disponíveis para regiões secundárias. Assim, uma transição altera a forma de visualizar essas métricas e definir alarmes para elas, e pode exigir alterações em qualquer painel predefinido. Para ter mais informações sobre o monitoramento e os clusters de banco de dados do Aurora, consulte Monitorar métricas do Amazon Aurora com o Amazon CloudWatch.
-
Configurar integrações com outros serviços da AWS: se o banco de dados global do Aurora se integrar a serviços da AWS, como o AWS Secrets Manager, o AWS Identity and Access Management, o Amazon S3 e o AWS Lambda, configure as integrações com esses serviços conforme necessário. Para ter mais informações sobre como integrar Aurora Global Databases com IAM, Amazon S3 e Lambda, consulte Usar bancos de dados globais do Amazon Aurora com outros produtos da AWS. Para saber mais sobre o Secrets Manager, consulte Como automizar a replicação de segredos no AWS Secrets Manager entre Regiões da AWS
.
-
Se você estiver usando o endpoint do gravador do Aurora Global Database, não precisará alterar as configurações de conexão na aplicação. Verifique se as alterações de DNS foram propagadas e se você pode se conectar e realizar operações de gravação no novo cluster primário. Depois, é possível retomar a operação completa da aplicação.
Suponha que as conexões da aplicação usem o endpoint do cluster primário antigo em vez do endpoint do gravador global. Nesse caso, altere as configurações de conexão da aplicação para usar o endpoint do novo cluster primário. Se você aceitou os nomes fornecidos ao criar o banco de dados global Aurora, poderá alterar o endpoint removendo -ro da string de endpoint do cluster promovido em seu aplicativo. Por exemplo, o endpoint do cluster secundário my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com torna-se my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com quando esse cluster é promovido para primário.
Se você estiver usando o RDS Proxy, redirecione as operações de gravação da aplicação para o endpoint de leitura/gravação apropriado do proxy associado ao novo cluster primário. Esse endpoint do proxy pode ser o endpoint padrão ou um endpoint de leitura/gravação personalizado. Para obter mais informações, consulte Como os endpoints do RDS Proxy funcionam com bancos de dados globais.
É possível realizar a transição do Aurora Global Database usando o AWS Management Console, a AWS CLI ou a API do RDS.
Como realizar a transição no banco de dados global do Aurora
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Bancos de dados e localize o Aurora Global Database no qual você deseja realizar a transição.
-
Selecione Fazer troca ou failover do banco de dados global no menu Ações.
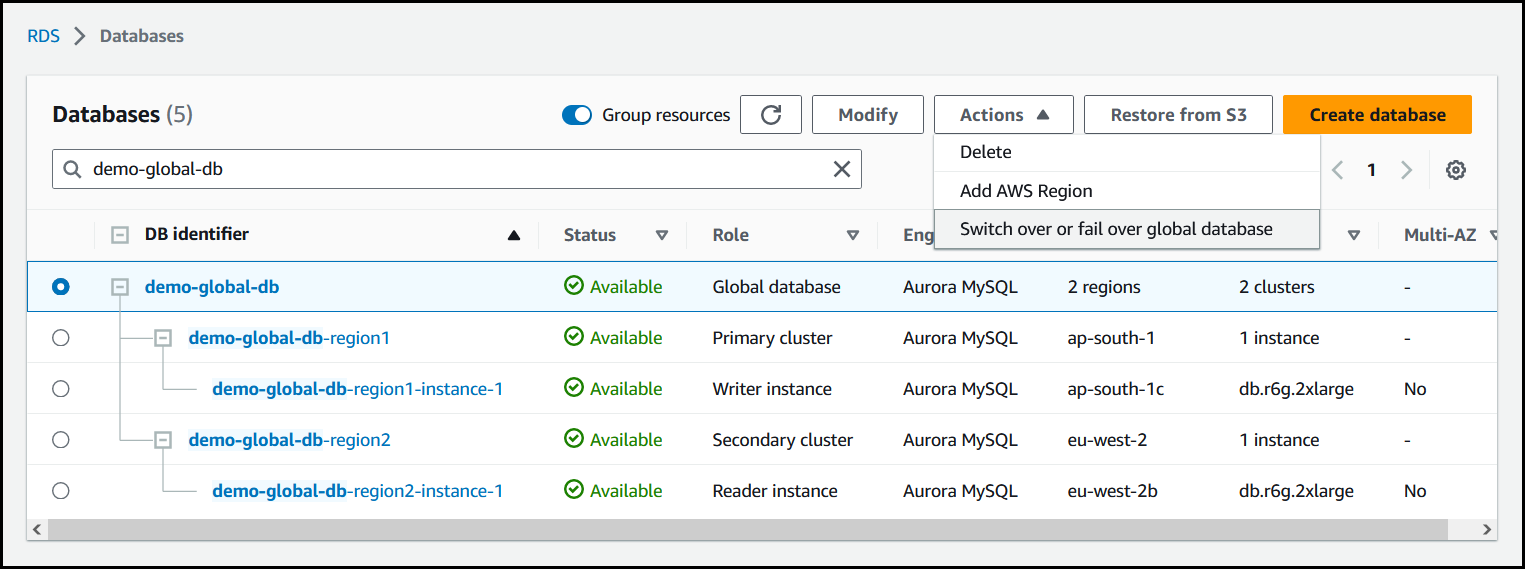
-
Escolha Troca.
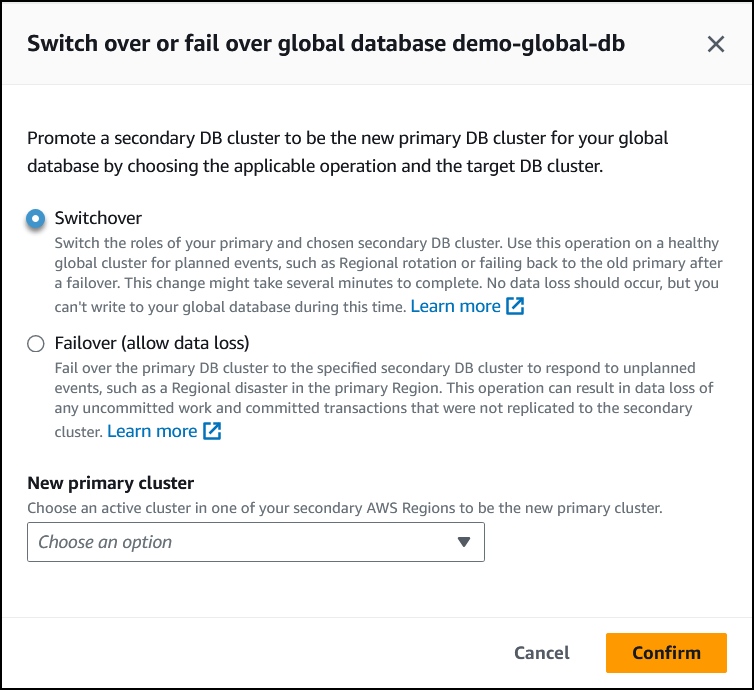
-
Em Novo cluster primário, escolha um cluster ativo em uma das Regiões da AWS secundárias para ser o novo cluster primário.
-
Escolha Confirmar.
Quando a transição for concluída, você verá os clusters de banco de dados do Aurora e as funções atuais deles na lista Bancos de dados, como mostrado na imagem a seguir.
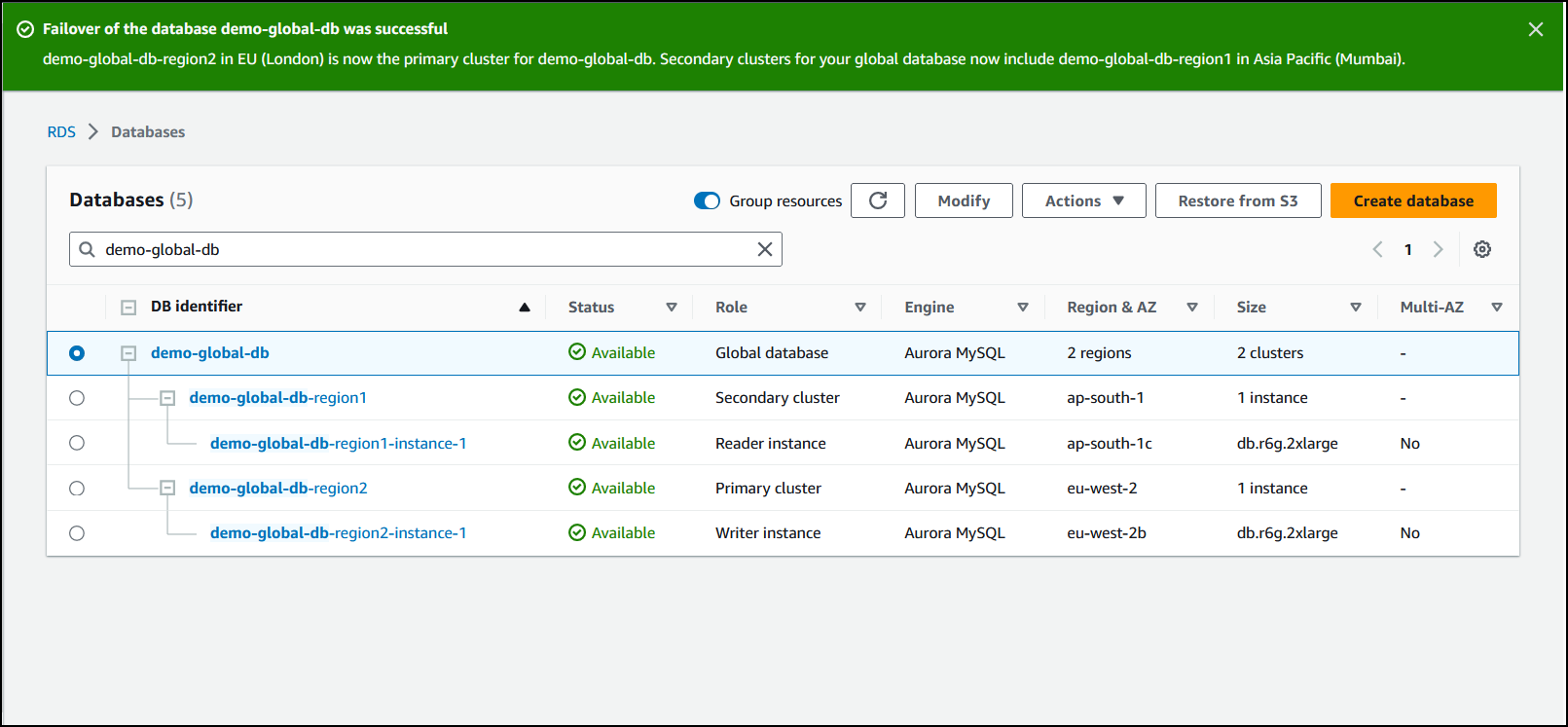
Como realizar a transição em um banco de dados global do Aurora
Use o comando switchover-global-cluster da CLI para realizar a transição do Aurora Global Database. Com o comando, passe valores para os seguintes parâmetros.
-
--region: especifique a Região da AWS em que o cluster de banco de dados primário do Aurora Global Database está sendo executado. -
--global-cluster-identifier– Especifique o nome do banco de dados globalAurora. -
--target-db-cluster-identifier– Especifique o Nome do recursos da Amazon (ARN) do cluster de banco de dados Aurora que você deseja promover para ser o principal para o banco de dados global Aurora.
Para Linux, macOS ou Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Para Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Para realizar a transição do Aurora Global Database, realize a operação de API SwitchoverGlobalCluster.
Recuperar um banco de dados global Amazon Aurora de uma interrupção não planejada
Em ocasiões raras, o Aurora Global Database pode sofrer uma interrupção inesperada na Região da AWS primária. Se isso acontecer, o cluster de banco de dados primário do Aurora e o respectivo nó de gravador não estarão disponíveis, e a replicação entre o cluster primário e os secundários cessará. Para minimizar o tempo de inatividade (RTO) e a perda de dados (RPO), você pode trabalhar rapidamente para executar um failover entre regiões.
O Aurora Global Database tem dois métodos de failover que você pode usar em uma situação de recuperação de desastres:
-
Failover gerenciado: esse método é recomendado para recuperação de desastres. Ao usá-lo, o Aurora adiciona automaticamente a antiga região primária ao banco de dados global como uma região secundária quando ela se torna disponível novamente. Assim, a topologia original do cluster global é mantida. Para saber como usar esse método, consulte Failovers planejados gerenciados para o Aurora Global Database.
-
Failover manual: esse método alternativo pode ser usado quando o failover gerenciado não for uma opção; por exemplo, quando as regiões primária e secundária estiverem executando versões de mecanismo incompatíveis. Para saber como usar esse método, consulte Realizar failovers manuais para bancos de dados globais do Aurora.
Importante
Ambos os métodos de failover podem resultar na perda dos dados da transação de gravação que não foram replicados para o secundário escolhido antes da ocorrência do evento de failover. No entanto, o processo de recuperação que promove uma instância de banco de dados no cluster de banco de dados secundário escolhido para ser a instância de banco de dados principal do gravador garante que os dados estejam em um estado transacionalmente consistente. Os failovers também são suscetíveis a problemas de cérebro dividido.
Failovers planejados gerenciados para o Aurora Global Database
Essa abordagem destina-se à continuidade dos negócios no caso de um desastre regional real ou de uma interrupção completa do nível de serviço.
Durante um failover gerenciado, o cluster secundário na região secundária escolhida se torna o novo cluster primário. O cluster secundário escolhido promove um dos nós somente leitura ao status de gravador completo. Essa etapa permite que o cluster assuma a função de cluster primário. O banco de dados ficará indisponível por um curto período enquanto o cluster estiver assumindo a nova função. Assim que essa região primária antiga estiver íntegra e disponível novamente, o Aurora a adicionará automaticamente ao cluster global como uma região secundária. Assim, a topologia de replicação existente do Aurora Global Database é mantida.
nota
Para gerenciar slots de replicação para o Aurora PostgreSQL após realizar um failover, consulte Gerenciar slots lógicos para o Aurora PostgreSQL .
nota
Só é possível realizar failovers gerenciados entre regiões com o Aurora Global Database caso os clusters de banco de dados primário e secundário tenham as mesmas versões principal e secundária do mecanismo. Dependendo do mecanismo e de suas respectivas versões, os níveis de patch podem precisar ser idênticos ou podem ser diferentes. Para conferir uma lista de mecanismos e suas respectivas versões que permitem essas operações entre clusters primários e secundários com diferentes níveis de patch, consulte Compatibilidade em nível de patch para transições e failovers gerenciados entre regiões. Antes de iniciar o failover, confira as versões do mecanismo no cluster global para garantir que elas sejam compatíveis com a transição gerenciada entre regiões e atualize-as, se necessário. Se as versões do mecanismo exigirem níveis de patch idênticos, mas estiverem executando níveis de patch diferentes, será possível realizar o failover manualmente seguindo as etapas em Realizar failovers manuais para bancos de dados globais do Aurora.
O failover gerenciado não aguarda até os dados serem sincronizados entre a região secundária escolhida e a região primária atual. Como o Aurora Global Database replica dados de forma assíncrona, é possível que nem todas as transações sejam replicadas para a região secundária da AWS escolhida antes de ser promovida para aceitar recursos completos de leitura/gravação.
Para garantir que os dados estejam em um estado consistente, o Aurora cria um volume de armazenamento para a antiga região primária após a recuperação. Antes de criar o volume de armazenamento na região da AWS, o Aurora tenta gerar um snapshot do volume de armazenamento antigo no ponto da falha. Dessa forma, é possível restaurar o snapshot e recuperar todos os dados perdidos por meio dele. Se essa operação for bem-sucedida, o Aurora colocará esse snapshot denominado rds:unplanned-global-failover- na seção de snapshots do AWS Management Console. Também é possível usar o comando name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots da AWS CLI ou a operação de API DescribeDBClusterSnapshots para ver os detalhes do snapshot.
Quando um failover gerenciado é iniciado, o Aurora também tenta interromper o tráfego de gravação por meio da camada de armazenamento altamente disponível do Aurora. Chamamos esse mecanismo de “delimitação de gravação”. Se o processo for bem-sucedido, o Aurora emitirá um evento do RDS informando que as gravações foram interrompidas. No caso improvável de várias falhas de AZ em uma região, é possível que o processo de delimitação de gravação não seja bem-sucedido em tempo hábil. Nesse caso, o Aurora emite um evento do RDS informando que o processo para interromper as gravações atingiu o tempo limite. Se o antigo cluster primário estiver acessível na rede, o Aurora registrará esses eventos nele. Caso contrário, o Aurora registrará os eventos no novo cluster primário. Para saber mais sobre esses eventos, consulte Eventos de cluster de banco de dados. Como limitar a gravação é a melhor tentativa, é possível que as gravações sejam aceitas momentaneamente na antiga região primária, causando problemas de cérebro dividido.
Recomendamos que você conclua as tarefas a seguir antes de realizar um failover com o Aurora Global Database. Isso minimiza a possibilidade de problemas de cérebro dividido ou de recuperação de dados não replicados do snapshot do antigo cluster primário.
-
Para evitar que as gravações sejam enviadas ao cluster primário do Aurora Global Database, desative as aplicações.
-
Todas as aplicações que se conectam ao cluster de banco de dados primário devem usar o endpoint do gravador global. Esse endpoint tem um valor que permanece o mesmo quando uma nova região se torna o cluster primário devido a uma transição ou a um failover. O Aurora implementa proteções adicionais para minimizar a possibilidade de perda de dados nas operações de gravação enviadas por meio do endpoint global. Para ter mais informações sobre os endpoints do gravador global, consulte Conectar-se ao Amazon Aurora Global Database.
-
Se você estiver usando o endpoint do gravador global e os valores de DNS do cache de camadas de rede ou da aplicação, reduza o tempo de vida (TTL) do cache de DNS para um valor baixo, como 5 segundos. Dessa forma, a aplicação registra rapidamente as alterações de DNS no endpoint do gravador global. Embora o Aurora tente bloquear gravações na antiga região primária, não há garantia de êxito da ação. Reduzir a duração do cache de DNS reduz ainda mais a probabilidade de problemas de cérebro dividido. Como alternativa, é possível conferir o evento do RDS que informa quando o Aurora observou as alterações de DNS no endpoint do gravador global. Dessa forma, é possível confirmar se a aplicação também registrou a alteração de DNS antes de reiniciar o tráfego de gravação da aplicação.
-
Confira os tempos de atraso de todos os clusters de banco de dados do Aurora secundários no Aurora Global Database. Escolher a região secundária com o menor atraso de replicação pode minimizar a perda de dados na atual região primária com falha.
Para todas as versões de bancos de dados globais baseados no Aurora PostgreSQL e para bancos de dados globais baseados no Aurora MySQL com versão de mecanismo 3.04.0 e posterior ou 2.12.0 e posterior, use o Amazon CloudWatch para visualizar a métrica
AuroraGlobalDBRPOLagpara todos os clusters de banco de dados secundários. Para versões secundárias anteriores dos bancos de dados globais baseados no Aurora MySQL, veja a métricaAuroraGlobalDBReplicationLag. Essa métrica informa a distância (em milissegundos) de um secundário em relação ao cluster de banco de dados primário.Para ter mais informações sobre métricas CloudWatch de Aurora, consulte Métricas no nível do cluster do Amazon Aurora.
Durante um failover gerenciado, o cluster de banco de dados secundário escolhido é promovido à sua nova função como primário. No entanto, ele não herda as várias opções de configuração do cluster de banco de dados primário. Uma incompatibilidade na configuração pode levar a problemas de performance, incompatibilidades de workload e outros comportamentos anômalos. Para evitar esses problemas, recomendamos que você resolva as diferenças entre os clusters de banco de dados globais Aurora para o seguinte:
-
Configure o grupo de parâmetros do cluster de banco de dados do Aurora para o novo primário, se necessário: é possível configurar os grupos de parâmetros do cluster de banco de dados do Aurora de maneira independente para cada cluster do Aurora no Aurora Global Database. Por isso, quando você promove um cluster de banco de dados secundário para assumir a função primária, o grupo de parâmetros do secundário pode ser configurado diferentemente do grupo do primário. Em caso afirmativo, modifique o parameter group do cluster de banco de dados secundário promovido para estar em conformidade com as configurações do cluster principal. Para saber como, consulte Modificando parâmetros para um banco de dados do Aurora global.
-
Configurar ferramentas e opções de monitoramento, como Amazon CloudWatch Events e alarmes – Configurar o cluster de banco de dados promovido com a mesma capacidade de registro, alarmes e assim por diante, conforme necessário para o banco de dados global. Tal como acontece com os parameter groups, a configuração desses recursos não é herdada do primário no processo de failover. Algumas métricas do CloudWatch, como atraso na replicação, só estão disponíveis para regiões secundárias. Assim, um failover altera a forma de visualizar essas métricas e definir alarmes para elas, e pode exigir alterações em qualquer painel predefinido. Para ter mais informações sobre o monitoramento dos clusters de banco de dados do Aurora, consulte Monitorar métricas do Amazon Aurora com o Amazon CloudWatch.
-
Configure integrações com outros serviços da AWS: se o Aurora Global Database se integrar a outros serviços da AWS, como o AWS Secrets Manager, o AWS Identity and Access Management, o Amazon S3 e o AWS Lambda, será necessário garantir que eles estejam configurados, conforme necessário, para acessar de quaisquer regiões secundárias. Para ter mais informações sobre como integrar Aurora Global Databases com IAM, Amazon S3 e Lambda, consulte Usar bancos de dados globais do Amazon Aurora com outros produtos da AWS. Para saber mais sobre o Secrets Manager, consulte Como automizar a replicação de segredos no AWS Secrets Manager entre Regiões da AWS
.
Normalmente, o cluster secundário escolhido assume a função principal em alguns minutos. Assim que a instância de banco de dados do gravador da nova região primária estiver disponível, será possível conectar as aplicações a ela e retomar as workloads. Depois que o Aurora promove o novo cluster primário, ele reconstrói automaticamente todos os clusters adicionais da região secundária.
Como os bancos de dados globais do Aurora usam replicação assíncrona, o atraso na replicação em cada região secundária pode variar. O Aurora reconstrói essas regiões secundárias para ter exatamente os mesmos dados de um ponto no tempo que o novo cluster da região primária. A duração da tarefa de reconstrução completa pode levar de alguns minutos a várias horas, dependendo do tamanho do volume de armazenamento e da distância entre as regiões. Quando os clusters da região secundária terminam de ser reconstruídos com base na nova região primária, eles ficam disponíveis para acesso de leitura.
Assim que o novo gravador principal for promovido e disponibilizado, o cluster da nova região primária poderá lidar com operações de leitura e gravação no banco de dados global do Aurora.
Se você estiver usando o endpoint global, não precisará alterar as configurações de conexão na aplicação. Verifique se as alterações de DNS foram propagadas e se você pode se conectar e realizar operações de gravação no novo cluster primário. Depois, é possível retomar a operação completa da aplicação.
Se você não estiver usando o endpoint global, altere o endpoint da aplicação para usar o endpoint do cluster de banco de dados recém-promovido a primário. Se você aceitou os nomes fornecidos ao criar o banco de dados global Aurora, poderá alterar o endpoint removendo -ro da string de endpoint do cluster promovido em seu aplicativo.
Por exemplo, o endpoint do cluster secundário my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com torna-se my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com quando esse cluster é promovido para primário.
Se você estiver usando o RDS Proxy, redirecione as operações de gravação de sua aplicação para o endpoint de leitura/gravação apropriado do proxy associado ao novo cluster primário. Esse endpoint do proxy pode ser o endpoint padrão ou um endpoint de leitura/gravação personalizado. Para obter mais informações, consulte Como os endpoints do RDS Proxy funcionam com bancos de dados globais.
Para restaurar a topologia original do cluster de banco de dados global, o Aurora monitora a disponibilidade da antiga região primária. Assim que essa região estiver íntegra e disponível novamente, o Aurora a adicionará automaticamente ao cluster global como uma região secundária. Antes de criar o novo volume de armazenamento na antiga região primária, o Aurora tenta capturar um snapshot do volume de armazenamento antigo no ponto da falha. Ele faz isso para que você possa usá-lo para recuperar os dados perdidos. Se essa operação for bem-sucedida, o Aurora criará um snapshot denominado rds:unplanned-global-failover-. É possível encontrar esse snapshot na seção Snapshots do AWS Management Console. Você também pode ver esse snapshot listado nas informações retornadas pela operação de API DescribeDBClusterSnapshots. name-of-old-primary-DB-cluster-timestamp
nota
O snapshot do volume de armazenamento antigo é um snapshot do sistema sujeito ao período de retenção de backup configurado no antigo cluster primário. Para preservar esse instantâneo fora do período de retenção, você pode copiá-lo para salvá-lo como um snapshot manual. Para saber mais sobre como copiar snapshots, incluindo os preços, consulte Cópia de snapshot de cluster de banco de dados.
Depois que a topologia original for restaurada, você poderá fazer failback do banco de dados global para a região primária original executando uma operação de transição quando fizer mais sentido para seus negócios e sua workload. Para isso, siga as etapas em Realizar transições para o Amazon Aurora Global Database.
É possível realizar um failover com o Aurora Global Database usando o AWS Management Console, a AWS CLI ou a API do RDS.
Como iniciar o processo de failover no banco de dados global do Aurora
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha Bancos de dados e localize o Aurora Global Database no qual você deseja fazer o failover.
-
Selecione Fazer troca ou failover do banco de dados global no menu Ações.
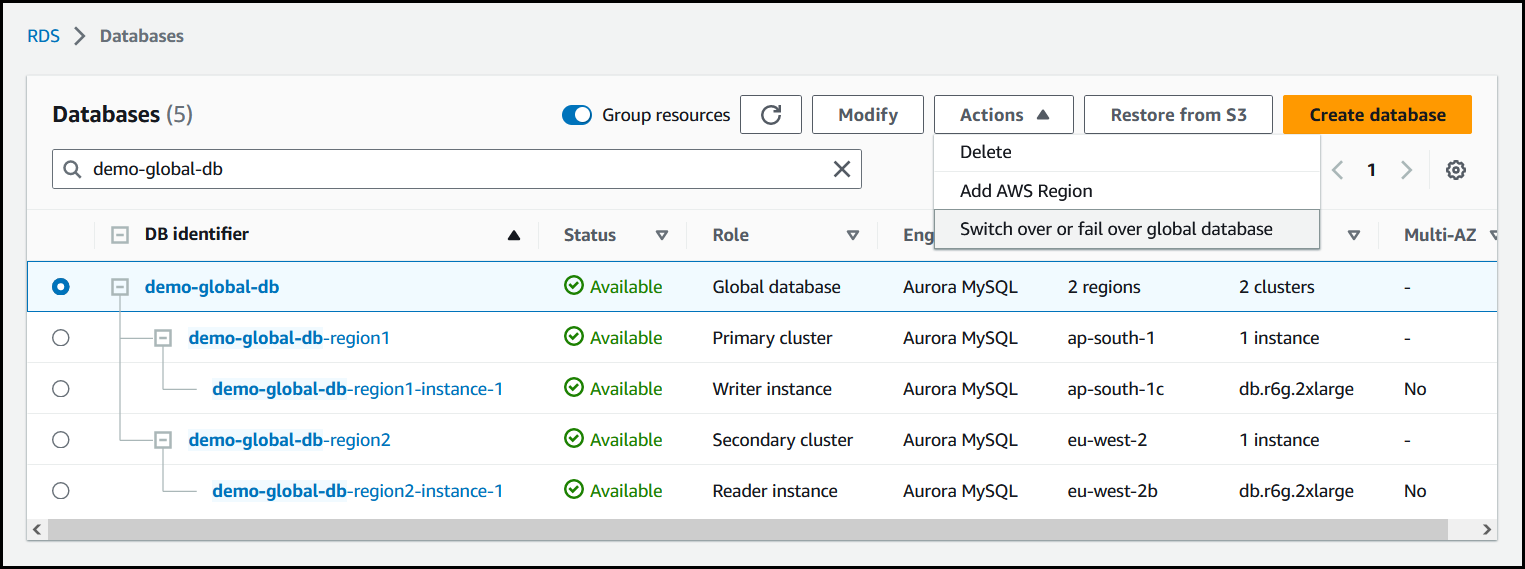
-
Escolha Fazer failover (permitir perda de dados).
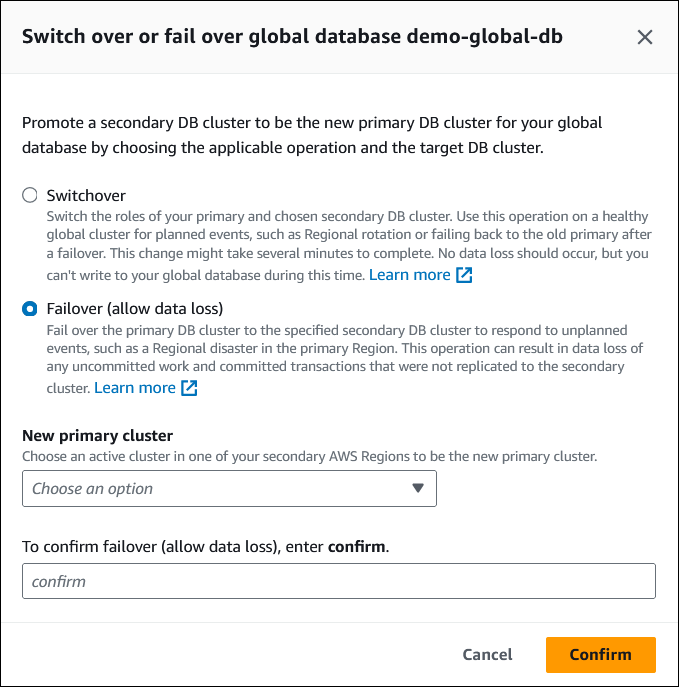
-
Em Novo cluster primário, escolha um cluster ativo em uma das Regiões da AWS secundárias para ser o novo cluster primário.
-
Se solicitado, insira
confirme escolha Confirmar.
Quando o failover for concluído, você verá os clusters de banco de dados do Aurora e o estado atual deles na lista Bancos de dados, como mostrado na imagem a seguir.
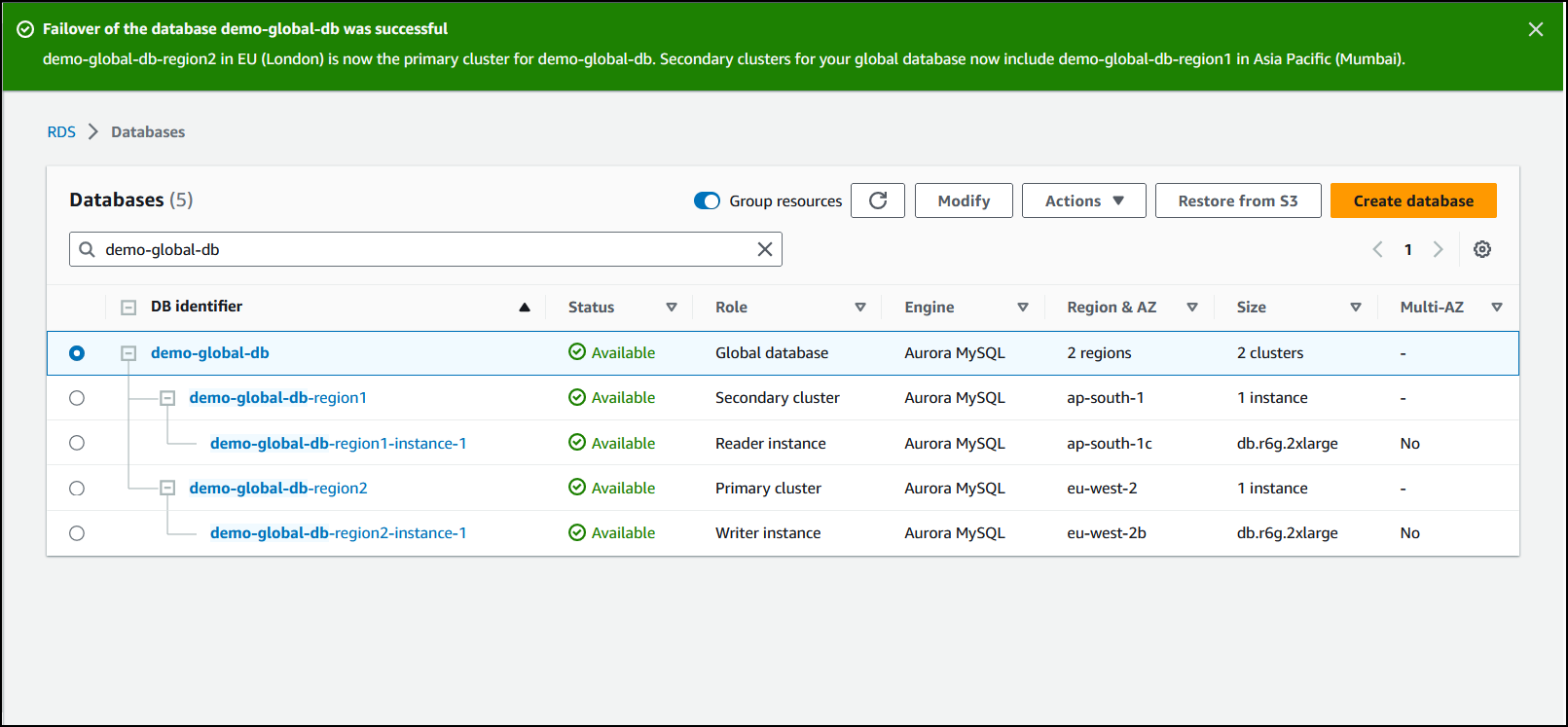
Como iniciar o processo de failover no banco de dados global do Aurora
Use o comando failover-global-cluster da CLI para realizar um failover com o Aurora Global Database. Com o comando, passe valores para os seguintes parâmetros.
-
--region: especifique a Região da AWS onde está sendo executado o cluster de banco de dados secundário que você quer que seja o novo primário para o banco de dados global do Aurora. -
--global-cluster-identifier– Especifique o nome do banco de dados globalAurora. -
--target-db-cluster-identifier: especifique o nome do recurso da Amazon (ARN) do cluster de banco de dados do Aurora que você deseja promover para que seja o novo principal para o banco de dados global do Aurora. -
--allow-data-loss: torne isso explicitamente uma operação de failover em vez de uma operação de transição. Uma operação de failover pode resultar em alguma perda de dados se os componentes de replicação assíncrona não tiverem concluído o envio de todos os dados replicados para a região secundária.
Para Linux, macOS ou Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Para Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Para realizar um failover com o Aurora Global Database, execute a operação de API FailoverGlobalCluster.
Realizar failovers manuais para bancos de dados globais do Aurora
Em alguns ambientes, você pode não conseguir usar o processo de failover gerenciado. Um exemplo é se os clusters de banco de dados primários e secundários não estiverem executando versões de mecanismo compatíveis. Nesse caso, é possível seguir esse processo manual para realizar um failover para a região secundária de destino.
dica
Recomendamos que você entenda esse processo antes de usá-lo. Tenha um plano pronto para prosseguir rapidamente ao primeiro sinal de uma questão em toda a região. Você pode se preparar para identificar a região secundária com o menor atraso de replicação usando o Amazon CloudWatch regularmente para rastrear os tempos de atraso dos clusters secundários. Procure testar seu plano para verificar se os procedimentos estão completos e precisos, bem como se a equipe está treinada para executar um failover de recuperação de desastres antes que isso realmente aconteça.
Como realizar um failover manual para um cluster secundário após uma interrupção não planejada na região primária
-
Interrompa a emissão de instruções de DML e outras operações de gravação para o cluster do banco de dados Aurora principal na Região da AWS com a interrupção.
-
Identifique um cluster de banco de dados Aurora de uma Região da AWS secundária para usar como um novo cluster de banco de dados primário. Se você tiver duas (ou mais) Regiões da AWS secundárias no banco de dados global do Aurora, escolha o cluster secundário que tem o menor atraso de replicação.
-
Desanexe o cluster de banco de dados secundário escolhido do banco de dados global Aurora.
A remoção de um cluster de banco de dados secundário de um banco de dados global Aurora interrompe imediatamente a replicação do primário para este secundário e promove-o ao cluster de banco de dados Aurora provisionado autônomo com recursos completos de leitura/gravação. Quaisquer outros clusters de banco de dados Aurora secundários associados ao cluster primário na região com a interrupção ainda estão disponíveis e podem aceitar chamadas de seu aplicativo. Eles também consomem recursos. Como você está recriando o Aurora Global Database, remova os outros clusters de banco de dados secundários antes de criar o Aurora Global Database nas etapas a seguir. Isso evita inconsistências de dados entre os clusters de banco de dados no Aurora Global Database (problemas de cérebro dividido).
Para obter as etapas detalhadas para desanexar, consulte Remover um cluster de um banco de dados global do Amazon Aurora.
-
Reconfigure seu aplicativo para enviar todas as operações de gravação para esse cluster de banco de dados Aurora autônomo agora usando seu novo endpoint. Se você aceitou os nomes fornecidos ao criar o banco de dados global Aurora, poderá alterar o endpoint removendo a
-rostring do endpoint do cluster em seu aplicativo.Por exemplo, o endpoint do cluster secundário
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.comse tornamy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.comquando esse cluster é separado do banco de dados global Aurora.Esse cluster de banco de dados Aurora se torna o cluster principal de um novo Aurora Global Database quando você começa a adicionar regiões a ele, na próxima etapa.
Se você estiver usando o RDS Proxy, redirecione as operações de gravação de sua aplicação para o endpoint de leitura/gravação apropriado do proxy associado ao novo cluster primário. Esse endpoint do proxy pode ser o endpoint padrão ou um endpoint de leitura/gravação personalizado. Para ter mais informações, consulte Como os endpoints do RDS Proxy funcionam com bancos de dados globais.
-
Adicione uma Região da AWS ao cluster de banco de dados. Quando você faz isso, o processo de replicação de primário para secundário começa. Para obter as etapas detalhadas para adicionar uma região, consulte Adicionar uma Região da AWS a um Amazon Aurora Global Database.
-
Adicione mais Regiões da AWS conforme necessário para recriar a topologia necessária para oferecer suporte à aplicação.
Certifique-se de que as gravações de aplicações sejam enviadas para o cluster de banco de dados Aurora correto antes, durante e depois de fazer essas alterações. Isso evita inconsistências de dados entre os clusters de banco de dados no Aurora Global Database (problemas de cérebro dividido).
Se você executou essa reconfiguração em resposta a uma interrupção em uma Região da AWS, você pode tornar a Região da AWS a principal novamente após a interrupção ser resolvida. Para isso, adicione a antiga Região da AWS ao novo banco de dados global e, depois, use o processo de transição para trocar a respectiva função. O banco de dados global do Aurora deve usar uma versão do Aurora PostgreSQL ou Aurora MySQL que comporte transições. Para obter mais informações, consulte Realizar transições para o Amazon Aurora Global Database.
Gerenciamento de RPOs para bancos de dados globais baseados em Aurora PostgreSQL–
Com um banco de dados global baseado em Aurora PostgreSQL, você pode gerenciar o objetivo de ponto de recuperação (RPO) para o banco de dados global do Aurora usando o parâmetro rds.global_db_rpo. O RPO representa a quantidade máxima de dados que podem ser perdidos em caso de interrupção.
Quando você define um RPO para seu banco de dados global baseado emAurora PostgreSQL–, Aurora monitora o tempo de atraso de RPO de todos os clusters secundários para garantir que pelo menos um cluster secundário permaneça dentro da janela RPO de destino. O tempo de atraso do RPO é outra métrica baseada no tempo.
O RPO é usado quando o banco de dados retoma as operações em uma nova Região da AWS após um failover. O Aurora avalia os tempos de atraso de RPO e RPO para confirmar (ou bloquear) transações no primário da seguinte forma:
-
Compromete a transação se pelo menos um cluster de banco de dados secundário tiver um tempo de atraso de RPO menor que o RPO.
-
Bloqueia a transação se todos os clusters de banco de dados secundários tiverem tempos de atraso de RPO maiores que o RPO. Ele também registra o evento no arquivo de log PostgreSQL e emite eventos de “espera” que mostram as sessões bloqueadas.
Em outras palavras, se todos os clusters secundários estiverem atrás do RPO de destino, Aurora pausará as transações no cluster primário até que pelo menos um dos clusters secundários seja atingidos. As transações pausadas são retomadas e confirmadas assim que o tempo de atraso de pelo menos um cluster de banco de dados secundário se torna menor que o RPO. O resultado é que nenhuma transação pode confirmar até que o RPO seja atendido.
O parâmetro rds.global_db_rpo é dinâmico. Se você decidir que não quer que todas as transações de gravação sejam proteladas até que o atraso diminua o suficiente, você pode redefini-lo rapidamente. Nesse caso, a Aurora reconhece e implementa a alteração após um pequeno atraso.
Importante
Em um banco de dados global com apenas duas regiões da AWS, recomendamos manter o valor padrão do parâmetro rds.global_db_rpo no grupo de parâmetros da região secundária. Caso contrário, realizar um failover devido à perda da região primária da AWS pode fazer com que o Aurora pause as transações. Em vez disso, antes de alterar esse parâmetro para impor um RPO máximo, espere até que o Aurora conclua a reconstrução do cluster na antiga região da AWS com falha.
Se você definir esse parâmetro como descrito a seguir, também poderá monitorar as métricas geradas. Você pode fazer isso usando psql ou outra ferramenta para consultar o cluster do banco de dados primário do banco de dados global Aurora e obter informações detalhadas sobre as operações do banco de dados global baseado em Aurora PostgreSQL–. Para saber como, consulte Monitorar banco de dados globais baseados no Aurora PostgreSQL.
Tópicos
Configurar o objetivo de ponto de recuperação
O parâmetro rds.global_db_rpo controla a configuração de RPO para um banco de dados PostgreSQL. Este parâmetro é tem suporte de Aurora PostgreSQL. Valores válidos de intervalo rds.global_db_rpo de 20 segundos a 2.147.483.647 segundos (68 anos). Escolha um valor realista para atender às suas necessidades de negócios e caso de uso. Por exemplo, você pode querer permitir até 10 minutos para o seu RPO, caso em que você define o valor para 600.
Você pode definir esse valor para seu banco de dados global baseado no Aurora PostgreSQL usando o AWS Management Console, a AWS CLI ou a API do RDS.
Como definir o RPO
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Escolha o cluster principal do seu banco de dados global Aurora e abra a guia Configuration (Configuração) para localizar seu parameter group de cluster de banco de dados. Por exemplo, o parameter group padrão para um cluster de banco de dados primário executando Aurora PostgreSQL 11.7 é
default.aurora-postgresql11.Os grupos de parâmetros não podem ser editados diretamente. Em vez disso, você pode fazer o seguinte:
-
Crie um parameter group de cluster de banco de dados personalizado usando o parameter group padrão apropriado como o ponto de partida. Por exemplo, crie um parameter group de cluster de banco de dados personalizado com base no
default.aurora-postgresql11. -
Em seu parameter group de banco de dados personalizado, defina o valor do parâmetro rds.global_db_rpo para atender ao seu caso de uso. Os valores válidos são de 20 segundos até o valor inteiro máximo de 2.147.483.647 (68 anos).
-
Aplique o parameter group de cluster de banco de dados modificado ao cluster de Aurora banco de dados.
-
Para ter mais informações, consulte Modificar parâmetros em um grupo de parâmetros do cluster de banco de dados no Amazon Aurora.
Para definir o parâmetro rds.global_db_rpo, use o comando CLI modify-db-cluster-parameter-group. No comando, especifique o nome do grupo de parâmetros do cluster primário e os valores para o parâmetro RPO.
O exemplo a seguir define o RPO como 600 segundos (10 minutos) para o grupo de parâmetros de cluster de banco de dados primário chamado my_custom_global_parameter_group.
Para Linux, macOS ou Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Para Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Para modificar o parâmetro rds.global_db_rpo, use a operação de API ModifyDBClusterParameterGroup do Amazon RDS.
Visualizar o objetivo de ponto de recuperação
O objetivo de ponto de recuperação (RPO) de um banco de dados global é armazenado no parâmetro rds.global_db_rpo de cada cluster de banco de dados. Você pode se conectar ao endpoint do cluster secundário que deseja visualizar e usar psql para consultar a instância para esse valor.
show rds.global_db_rpo;db-name=>
Se este parâmetro não estiver definido, a consulta retornará o seguinte:
rds.global_db_rpo
-------------------
-1
(1 row)Esta próxima resposta é de um cluster de banco de dados secundário que tenha uma configuração de RPO de 1 minuto.
rds.global_db_rpo
-------------------
60
(1 row) Você pode igualmente usar a CLI para obter valores para descobrir se rds.global_db_rpo é ativo em alguns dos conjuntos de Aurora banco de dados usando a CLI para obter valores de todos os user parâmetros para o cluster.
Para Linux, macOS ou Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Para Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
O comando retorna uma saída semelhante à seguinte para todos os parâmetros user que não são default-engine ou parâmetros de cluster de banco de dados system.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Para saber mais sobre a visualização de parâmetros do grupo de parâmetros do cluster, consulte Visualizar valores de parâmetros de um grupo de parâmetros do cluster de banco de dados no Amazon Aurora.
Desabilitar o objetivo de ponto de recuperação
Para desabilitar o RPO, redefina o parâmetro rds.global_db_rpo. É possível redefinir parâmetros usando o AWS Management Console, a AWS CLI ou a API do RDS.
Como desabilitar o RPO
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, selecione Parameter groups.
-
Na lista, escolha o grupo de parâmetros de cluster do banco de dados primário.
-
Escolha Edit parameters.
-
Escolha a caixa ao lado do parâmetro rds.global_db_rpo.
-
Escolha Redefinir.
-
Quando a tela mostrar Redefinir parâmetros no grupo de parâmetros do banco de dados, escolha Redefinir parâmetros.
Para ter mais informações sobre como redefinir um parâmetro com o console, consulte Modificar parâmetros em um grupo de parâmetros do cluster de banco de dados no Amazon Aurora.
Para redefinir o parâmetro rds.global_db_rpo, use o comando reset-db-cluster-parameter-group .
Para Linux, macOS ou Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Para Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Para redefinir o parâmetro rds.global_db_rpo, use a operação ResetDBClusterParameterGroup da API do Amazon RDS.
