Gerenciar clusters de banco de dados do Aurora Serverless v2
Com o Aurora Serverless v2, seus clusters são intercambiáveis com clusters provisionados. As propriedades do Aurora Serverless v2 aplicam-se a uma ou mais instâncias de banco de dados dentro de um cluster. Dessa forma, os procedimentos para criar e modificar clusters, criar e restaurar snapshots etc. são basicamente os mesmos que para outros tipos de cluster do Aurora. Com relação a procedimentos gerais para gerenciar clusters e instâncias de banco de dados do Aurora, consulte Como gerenciar um cluster de banco de dados do Amazon Aurora.
Nos tópicos a seguir, saiba mais sobre considerações de gerenciamento para clusters que contêm instâncias de banco de dados do Aurora Serverless v2.
Tópicos
Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster
Para modificar parâmetros de configuração ou outras configurações para clusters que contenham instâncias de banco de dados do Aurora Serverless v2 ou as próprias instâncias de banco de dados, siga os mesmos procedimentos gerais para os clusters provisionados. Para obter detalhes, consulte Modificar um cluster de bancos de dados Amazon Aurora.
A configuração mais importante exclusiva do Aurora Serverless v2 é o intervalo de capacidade. Depois de definir os valores mínimo e máximo da unidade de capacidade do Aurora (ACU) para um cluster do Aurora, você não precisa ajustar ativamente a capacidade das instâncias de banco de dados do Aurora Serverless v2 no cluster. O Aurora faz isso por você. Essa configuração é gerenciada no nível do cluster. Os mesmos valores mínimo e máximo da ACU se aplicam a cada instância de banco de dados do Aurora Serverless v2 no cluster.
Você pode definir os seguintes valores específicos:
-
Minimum ACUs (Mínimo de ACUs): a instância de banco de dados do Aurora Serverless v2 pode reduzir a capacidade até esse número de ACUs.
-
Maximum ACUs (Máximo de ACUs): a instância de banco de dados do Aurora Serverless v2 pode aumentar a capacidade até esse número de ACUs.
nota
Quando você modifica o intervalo de capacidade de um cluster de banco de dados do Aurora Serverless v2, a alteração ocorre imediatamente, independentemente de você optar por aplicá-la imediatamente ou durante a próxima janela de manutenção programada.
Para obter detalhes sobre os efeitos do intervalo de capacidade e como monitorá-lo e ajustá-lo, consulte Métricas importantes do Amazon CloudWatch para o Aurora Serverless v2 e Performance e escalabilidade no Aurora Serverless v2. Seu objetivo é garantir que a capacidade máxima do cluster seja alta o suficiente para lidar com picos da workload, e o mínimo seja baixo o suficiente para minimizar os custos quando o cluster não estiver ocupado.
Suponha que você determine com base no monitoramento que o intervalo de ACU para o cluster deva ser maior, menor, mais amplo ou mais estreito. É possível definir a capacidade de um cluster do Aurora como um intervalo específico de ACUs com o AWS Management Console, o AWS CLI ou a API do Amazon RDS. Esse intervalo de capacidade se aplica a todas as instâncias de banco de dados do Aurora Serverless v2 no cluster.
Por exemplo, suponha que seu cluster tenha um intervalo de capacidade de 1 a 16 ACUs e contenha duas instâncias de banco de dados do Aurora Serverless v2. Depois, o cluster como um todo consome entre duas ACUs (quando ocioso) e 32 ACUs (quando totalmente utilizado). Se você alterar o intervalo de capacidade de oito para 20,5 ACUs, o cluster consumirá 16 ACUs quando ocioso e até 41 ACUs quando totalmente utilizado.
O Aurora define automaticamente determinados parâmetros para instâncias de banco de dados do Aurora Serverless v2 para valores que dependem do valor máximo de ACU no intervalo de capacidade. Para obter uma lista desses parâmetros, consulte Conexões máximas do Aurora Serverless v2. No caso de parâmetros estáticos que dependem desse tipo de cálculo, o valor é avaliado novamente quando você reinicializa a instância de banco de dados. Assim, é possível atualizar o valor desses parâmetros reinicializando a instância de banco de dados depois de alterar o intervalo de capacidade. Para conferir se você precisa reinicializar sua instância de banco de dados para obter essas alterações de parâmetros, confira o atributo ParameterApplyStatus da instância de banco de dados. Um valor de pending-rebootindica que a reinicialização aplicará alterações a alguns valores de parâmetros.
Você pode definir o intervalo de capacidade de um cluster que contém instâncias de banco de dados do Aurora Serverless v2 com o AWS Management Console.
Ao usar o console, defina o intervalo de capacidade para o cluster ao adicionar a primeira instância de banco de dados do Aurora Serverless v2 a esse cluster. Você pode fazer isso ao escolher a classe de instância de banco de dados Serverless v2 (Sem servidor v2) para a instância de banco de dados do gravador ao criar o cluster. Ou você pode fazer isso ao escolher a classe de instância de banco de dados Serverless (Sem servidor) ao adicionar uma instância de banco de dados do leitor do Aurora Serverless v2 ao cluster. Ou ao converter uma instância de banco de dados provisionada existente no cluster à classe Serverless (Sem servidor). Para ver as versões completas desses procedimentos, consulte Criar uma instância de banco de dados de gravador do Aurora Serverless v2, Adicionar um leitor do Aurora Serverless v2 e Converter um gravador ou leitor provisionado em Aurora Serverless v2.
Qualquer intervalo de capacidade que você definir no nível do cluster se aplicará a todas as instâncias de banco de dados do Aurora Serverless v2 em seu cluster. A imagem a seguir mostra um cluster com várias instâncias de banco de dados do leitor do Aurora Serverless v2. Cada uma tem um intervalo de capacidade idêntico de duas a 64 ACUs.
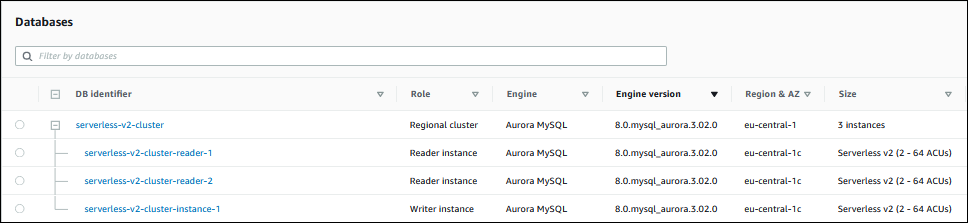
Como modificar o intervalo de capacidade de um cluster do Aurora Serverless v2
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Databases (Bancos de dados).
-
Escolha o cluster que contém suas instâncias de banco de dados do Aurora Serverless v2 na lista. O cluster já deve conter pelo menos uma instância de banco de dados do Aurora Serverless v2. Caso contrário, o Aurora não mostrará a seção Capacity range (Intervalo de capacidade).
-
Para Actions (Ações), escolha Modify (Modificar).
-
Na seção Capacity range (Intervalo de capacidade), escolha o seguinte:
-
Insira um valor para Minimum ACUs (Mínimo de ACUs). O console mostra o intervalo de valores permitido. É possível escolher uma capacidade mínima de 0,5 a 128 ACUs. É possível escolher uma capacidade máxima de 1 a 128 ACUs. É possível ajustar os valores de capacidade em incrementos de 0,5 ACU.
-
Insira um valor para Maximum ACUs (Máximo de ACUs). Esse valor deve ser maior que ou igual a Minimum ACUs (Mínimo de ACUs). O console mostra o intervalo de valores permitido. A figura a seguir mostra essa opção.
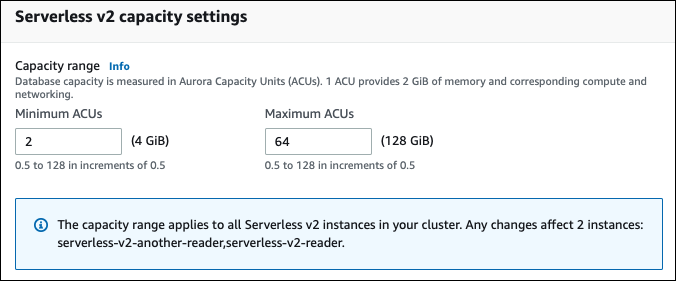
-
-
Escolha Continue. A página Resumo das modificações é exibida.
-
Escolha Apply immediately (Aplicar imediatamente).
A modificação de capacidade ocorre imediatamente, independentemente de você optar por aplicá-la imediatamente ou durante a próxima janela de manutenção programada.
-
Escolha Modify cluster (Modificar cluster) para aceitar o resumo das modificações. Você também pode escolher BAck (Voltar) para modificar suas alterações ou Cancel (Cancelar) para descartar suas alterações.
Para definir a capacidade de um cluster no qual você pretenda usar instâncias de banco de dados do Aurora Serverless v2 usando o AWS CLI, execute o comando modify-db-cluster do AWS CLI. Especifique a opção --serverless-v2-scaling-configuration. Talvez o cluster já contenha uma ou mais instâncias de banco de dados do Aurora Serverless v2 ou você pode adicioná-las posteriormente. Valores válidos para os campos MinCapacity e MaxCapacity incluem os seguintes:
-
0.5,1,1.5,2, etc., em etapas de 0,5, até no máximo 128.
Neste exemplo, você define o intervalo de ACU de um cluster de banco de dados do Aurora chamado sample-cluster como no mínimo 48.5 e no máximo 64.
aws rds modify-db-cluster --db-cluster-identifier sample-cluster \ --serverless-v2-scaling-configuration MinCapacity=48.5,MaxCapacity=64
A modificação de capacidade ocorre imediatamente, independentemente de você optar por aplicá-la imediatamente ou durante a próxima janela de manutenção programada.
Depois disso, você pode adicionar instâncias de banco de dados do Aurora Serverless v2 ao cluster, e cada nova instância de banco de dados pode ser escalada entre 48,5 e 64 ACUs. O novo intervalo de capacidade também se aplica a todas as instâncias de banco de dados do Aurora Serverless v2 já presentes no cluster. A escala das instâncias de banco de dados é aumentada ou reduzida na vertical para se inserir no novo intervalo de capacidade.
Para obter exemplos adicionais de configuração do intervalo de capacidade usando a CLI, consulte escolher o intervalo de capacidade do Aurora Serverless v2 para um cluster do Aurora.
Para modificar a configuração de escalabilidade do cluster de banco de dados do Aurora Serverless usando a AWS CLI, execute o comando modify-db-cluster da AWS CLI. Especifique a opção --serverless-v2-scaling-configuration para configurar a capacidade mínima e máxima. Entre os valores de capacidade válidos estão os seguintes:
-
Aurora MySQL:
0.5,1,1.5,2, etc., em incrementos de 0,5 ACUs até no máximo128. -
Aurora PostgreSQL:
0.5,1,1.5,2, etc., em incrementos de 0,5 ACUs até no máximo128.
No exemplo a seguir, você modificará a configuração de escalabilidade de uma instância de banco de dados do Aurora Serverless v2 denominada sample-instance que faz parte de um cluster chamado sample-cluster.
Para Linux, macOS ou Unix:
aws rds modify-db-cluster --db-cluster-identifier sample-cluster \ --serverless-v2-scaling-configuration MinCapacity=8,MaxCapacity=64
Para Windows:
aws rds modify-db-cluster --db-cluster-identifier sample-cluster ^ --serverless-v2-scaling-configuration MinCapacity=8,MaxCapacity=64
É possível definir a capacidade de uma instância de bancos de dados do Aurora com a operação da API ModifyDBCluster. Especifique o parâmetro ServerlessV2ScalingConfiguration. Valores válidos para os campos MinCapacity e MaxCapacity incluem os seguintes:
-
0.5,1,1.5,2, etc., em etapas de 0,5, até no máximo 128.
É possível modificar a configuração de escalabilidade de um cluster que contém instâncias de banco de dados do Aurora Serverless v2 com a operação da API ModifyDBCluster. Especifique o parâmetro ServerlessV2ScalingConfiguration para configurar a capacidade mínima e máxima. Entre os valores de capacidade válidos estão os seguintes:
-
Aurora MySQL:
0.5,1,1.5,2, etc., em incrementos de 0,5 ACUs até no máximo128. -
Aurora PostgreSQL:
0.5,1,1.5,2, etc., em incrementos de 0,5 ACUs até no máximo128.
A modificação de capacidade ocorre imediatamente, independentemente de você optar por aplicá-la imediatamente ou durante a próxima janela de manutenção programada.
Conferir o intervalo de capacidade do Aurora Serverless v2
O procedimento para conferir o intervalo de capacidade do seu cluster do Aurora Serverless v2 exige primeiro definir um intervalo de capacidade. Caso ainda não tenha feito isso, siga o procedimento em Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
Qualquer intervalo de capacidade definido no nível do cluster se aplicará a todas as instâncias de banco de dados do Aurora Serverless v2 em seu cluster. A imagem a seguir mostra um cluster com várias instâncias de banco de dados do Aurora Serverless v2. Cada uma tem um intervalo de capacidade idêntico.
Você também pode visualizar a página de detalhes de qualquer instância de banco de dados do Aurora Serverless v2 no cluster. O intervalo de capacidade das instâncias de banco de dados é exibido na guia Configuration (Configuração).

Você também pode ver o intervalo de capacidade atual do cluster na página Modify (Modificar) do cluster. A imagem a seguir mostra o procedimento. Nesse ponto, você pode alterar o intervalo de capacidade. Para saber todas as maneiras de definir ou alterar o intervalo de capacidade, consulte Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
Conferir o intervalo de capacidade atual de um cluster do Aurora
É possível conferir o intervalo de capacidade configurado para instâncias de banco de dados do Aurora Serverless v2 em um cluster examinando o atributo ServerlessV2ScalingConfiguration para o cluster. O exemplo de AWS CLI a seguir mostra um cluster com uma capacidade mínima de 0,5 unidades de capacidade do Aurora (ACUs) e uma capacidade máxima de 16 ACUs.
$ aws rds describe-db-clusters --db-cluster-identifier serverless-v2-64-acu-cluster \ --query 'DBClusters[*].[ServerlessV2ScalingConfiguration]' [ [ { "MinCapacity": 0.5, "MaxCapacity": 16.0 } ] ]
Adicionar um leitor do Aurora Serverless v2
Para adicionar uma instância de banco de dados do leitor do Aurora Serverless v2 ao cluster, siga o mesmo procedimento geral que em Adicionar réplicas do Aurora a um cluster de banco de dados. Escolha a classe de instância Serverless v2 para a nova instância de banco de dados.
Se a instância de banco de dados do leitor for a primeira instância de banco de dados do Aurora Serverless v2 no cluster, escolha também o intervalo de capacidade. A imagem a seguir mostra os controles utilizados para especificar as unidades de capacidade mínima e máxima do Aurora (ACUs). Essa configuração se aplica a essa instância de banco de dados do leitor e a todas as outras instâncias de banco de dados do Aurora Serverless v2 adicionadas ao cluster. Cada instância de banco de dados do Aurora Serverless v2 pode ser escalada entre os valores mínimo e máximo de ACUs.
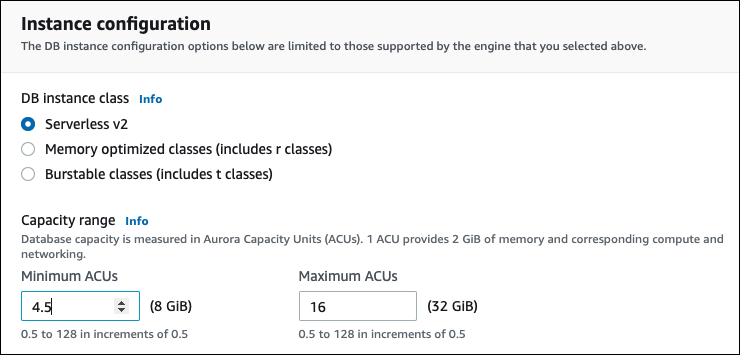
Se você já adicionou qualquer instância de banco de dados do Aurora Serverless v2 ao cluster, a inclusão de outra instância de banco de dados do leitor do Aurora Serverless v2 mostrará o intervalo de capacidade atual. A imagem a seguir mostra esses controles somente leitura.
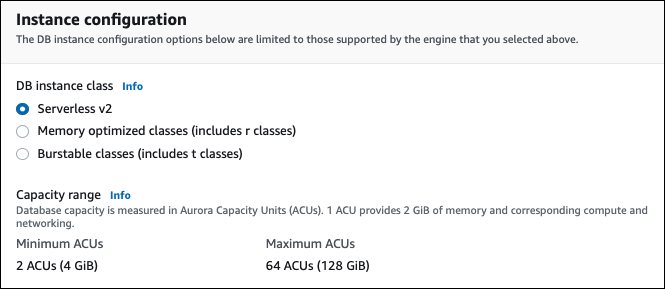
Caso queira alterar o intervalo de capacidade do cluster, siga o procedimento em Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
No caso de clusters que contenham mais de uma instância de banco de dados do leitor, a prioridade de failover de cada instância de banco de dados do leitor do Aurora Serverless v2 desempenha um papel importante na forma como a escala dessa instância é aumentada ou reduzida na vertical. Não é possível especificar a prioridade ao criar inicialmente o cluster. Tenha em mente essa propriedade ao adicionar uma segunda instância de banco de dados do leitor ao cluster ou ao fazê-lo posteriormente. Para obter mais informações, consulte Escolher o nível de promoção para um leitor do Aurora Serverless v2.
Para saber outras maneiras de ver o intervalo de capacidade atual de um cluster, consulte Conferir o intervalo de capacidade do Aurora Serverless v2.
Converter um gravador ou leitor provisionado em Aurora Serverless v2
É possível converter uma instância de banco de dados provisionada para usar o Aurora Serverless v2. Para fazer isso, siga o procedimento em Modificar uma instância de banco de dados em um cluster de banco de dados. O cluster deve atender aos requisitos em Requisitos e limitações do Aurora Serverless v2. Por exemplo, as instâncias de banco de dados do Aurora Serverless v2 exigem que o cluster esteja executando determinadas versões mínimas do mecanismo.
Suponha que você esteja convertendo um cluster provisionado em execução para aproveitar o Aurora Serverless v2. Nesse caso, é possível minimizar o tempo de inatividade convertendo uma instância de banco de dados em Aurora Serverless v2 como a primeira etapa no processo de alternância. Para saber o procedimento completo, consulte Alternar de um cluster provisionado para o Aurora Serverless v2.
Se a instância de banco de dados convertida for a primeira instância de banco de dados do Aurora Serverless v2 no cluster, escolha o intervalo de capacidade para o cluster como parte da operação Modify(Modificar). Esse intervalo de capacidade se aplica a todas as instâncias de banco de dados do Aurora Serverless v2 adicionadas ao cluster. A imagem a seguir mostra a página na qual especificar as unidades de capacidade mínima e máxima do Aurora (ACUs).
Para obter detalhes sobre a importância do intervalo de capacidade, consulte Capacidade do Aurora Serverless v2.
Se o cluster já contiver uma ou mais instâncias de banco de dados do Aurora Serverless v2, você verá o intervalo de capacidade existente durante a operação Modify (Modificar). A imagem a seguir mostra um exemplo desse painel de informações.
Caso queira alterar o intervalo de capacidade do cluster depois de adicionar mais instâncias de banco de dados do Aurora Serverless v2, siga o procedimento em Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
Converter um gravador ou leitor do Aurora Serverless v2 em provisionado
É possível converter uma instância de banco de dados do Aurora Serverless v2 em uma instância de banco de dados provisionada. Para fazer isso, siga o procedimento em Modificar uma instância de banco de dados em um cluster de banco de dados. Escolha uma classe de instância de banco de dados diferente de Serverless (Sem servidor).
Você pode converter um instância de banco de dados do Aurora Serverless v2 em provisionada se precisar de uma capacidade maior do que a disponível com as unidades de capacidade máxima do Aurora (ACUs) de uma instância de banco de dados do Aurora Serverless v2. Por exemplo, as maiores classes de instância de banco de dados db.r5 e db.r6g têm uma capacidade de memória maior do que a capacidade para a qual uma instância de banco de dados do Aurora Serverless v2 pode ser escalada.
dica
Algumas classes de instância de banco de dados mais antigas, como db.r3 e db.t2, não estão disponíveis para as versões do Aurora que você usa com o Aurora Serverless v2. Para ver quais classes de instância de banco de dados você pode usar ao converter uma instância de banco de dados do Aurora Serverless v2 para uma provisionada, consulte Mecanismos de banco de dados compatíveis para classes de instância de banco de dados.
Se você estiver convertendo a instância de banco de dados do gravador do seu cluster do Aurora Serverless v2 em provisionada, poderá seguir o procedimento em Alternar de um cluster provisionado para o Aurora Serverless v2, mas de forma inversa. Alterne uma das instâncias de banco de dados do leitor no cluster de Aurora Serverless v2 em provisionada. Depois, execute um failover para transformar essa instância de banco de dados provisionada no gravador.
O intervalo de capacidade especificado anteriormente para o cluster permanecerá em vigor, mesmo que todas as instâncias de banco de dados do Aurora Serverless v2 sejam removidas do cluster. Se quiser alterar o intervalo de capacidade, modifique o cluster, conforme explicado em Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
Escolher o nível de promoção para um leitor do Aurora Serverless v2
No caso de clusters que contenham várias instâncias de banco de dados do Aurora Serverless v2 ou uma mistura de instâncias de banco de dados, do Aurora Serverless v2 e provisionadas, preste atenção à configuração do nível de promoção para cada instância de banco de dados do Aurora Serverless v2. Essa configuração controla mais aspectos do comportamento das instâncias de banco de dados do Aurora Serverless v2 do que das instâncias de banco de dados provisionadas.
No AWS Management Console, especifique essa configuração usando a opção Failover priority (Prioridade de failover) em Additional configuration(Configuração adicional) para as páginas Create database (Criar banco de dados), Modify instance (Modificar instância) e Add reader (Adicionar leitor). Veja essa propriedade para instâncias de banco de dados existentes na coluna Priority tier (Nível prioritário) da página Databases (Bancos de dados). Você também pode ver essa propriedade na página de detalhes de um cluster de banco de dados ou instância de banco de dados.
No caso de instâncias de banco de dados provisionadas, a escolha do nível de 0 a 15 determina apenas a ordem na qual o Aurora escolhe qual instância de banco de dados do leitor promover ao gravador durante uma operação de failover. No caso de instâncias de banco de dados do leitor do Aurora Serverless v2, o número de níveis também determina se a instância de banco de dados tem a escala aumentada na vertical para corresponder à capacidade da instância de banco de dados do gravador ou se é escalada independentemente com base em sua própria workload. As instâncias de banco de dados do leitor do Aurora Serverless v2 nos níveis 0 ou 1 são mantidas com uma capacidade mínima pelo menos tão alta quanto a da instância de banco de dados do gravador. Dessa forma, elas estão prontas para assumir o controle da instância de banco de dados do gravador em caso de failover. Se a instância de banco de dados do gravador for uma instância de banco de dados provisionada, o Aurora estimará a capacidade do Aurora Serverless v2 equivalente. Ele usa essa estimativa como a capacidade mínima para a instância de banco de dados do leitor do Aurora Serverless v2.
As instâncias de banco de dados de leitor do Aurora Serverless v2 nos níveis 2 a 15 não têm a mesma restrição em sua capacidade mínima. Quando estiverem ociosas, elas poderão ter a escala reduzida na vertical para o valor mínimo da unidade de capacidade do Aurora (ACU) especificado no intervalo de capacidade do cluster.
O exemplo do AWS CLI do Linux a seguir mostra como examinar os níveis de promoção de todas as instâncias de banco de dados em seu cluster. O campo final inclui um valor de True para a instância de banco de dados do gravador e False para todas as instâncias de banco de dados do leitor.
$ aws rds describe-db-clusters --db-cluster-identifier promotion-tier-demo \ --query 'DBClusters[*].DBClusterMembers[*].[PromotionTier,DBInstanceIdentifier,IsClusterWriter]' \ --output text 1 instance-192 True 1 tier-01-4840 False 10 tier-10-7425 False 15 tier-15-6694 False
O exemplo da AWS CLI do Linux a seguir mostra como alterar o nível de promoção de uma instância de banco de dados específica em seu cluster. Os comandos primeiro modificam a instância de banco de dados com um novo nível de promoção. Depois, eles esperam que a instância de banco de dados fique disponível novamente e confirmam o novo nível de promoção para a instância de banco de dados.
$ aws rds modify-db-instance --db-instance-identifier instance-192 --promotion-tier 0 $ aws rds wait db-instance-available --db-instance-identifier instance-192 $ aws rds describe-db-instances --db-instance-identifier instance-192 \ --query '*[].[PromotionTier]' --output text 0
Para obter mais orientações sobre como especificar níveis de promoção para diferentes casos de uso, consulte Escalabilidade do Aurora Serverless v2.
Usar TLS/SSL com o Aurora Serverless v2
O Aurora Serverless v2 pode usar o protocolo Transport Layer Security/Secure Sockets Layer (TLS/SSL) para criptografar as comunicações entre clientes e suas instâncias de banco de dados do Aurora Serverless v2. Ele é compatível com TLS/SSL versões 1.0, 1.1 e 1.2. Para obter informações gerais sobre como usar o TLS/SSL com o Aurora, consulte Conexões do TLS com clusters de banco de dados do Aurora MySQL.
Para saber mais sobre como se conectar ao banco de dados do Aurora MySQL com o cliente MySQL, consulte Conectar-se a uma instância de banco de dados que esteja executando o mecanismo de banco de dados MySQL.
O Aurora Serverless v2 é compatível com todos os modos TLS/SSL disponíveis para o cliente do MySQL (mysql) e o cliente do PostgreSQL (psql), incluindo aqueles listados na tabela a seguir.
| Descrição do modo TLS/SSL | mysql | psql |
|---|---|---|
|
Conectar sem usar TLS/SSL. |
DISABLED |
desabilitar |
|
Tente a conexão usando TLS/SSL primeiro, mas volte para não SSL, se necessário. |
PREFERRED |
preferir (padrão) |
|
Imponha o uso de TLS/SSL. |
REQUIRED |
require |
|
Imponha o TLS/SSL e verifique a autoridade de certificação (CA). |
VERIFY_CA |
verify-ca |
|
Imponha o TLS/SSL, verifique a CA e verifique o hostname da CA. |
VERIFY_IDENTITY |
verify-full |
Aurora Serverless v2O usa certificados curinga. Se você especificar a opção “verificar CA” ou “verificar CA e nome do host da CA” ao usar TLS/SSL, primeiro baixe o armazenamento de confiança CA 1 raiz da Amazon
Para Linux, macOS ou Unix:
psql 'host=endpointuser=usersslmode=require sslrootcert=amazon-root-CA-1.pem dbname=db-name'
Para saber mais sobre como trabalhar com o banco de dados do Aurora PostgreSQL usando o cliente do Postgres, consulte Conectar-se a uma instância de banco de dados que esteja executando o mecanismo de banco de dados do PostgreSQL.
Para obter mais informações sobre como se conectar a clusters de bancos de dados Aurora em geral, consulte Como conectar-se a um cluster de bancos de dados Amazon Aurora.
Pacotes de cifras compatíveis com clusters de banco de dados do Aurora Serverless v2
Usando conjuntos de cifras configuráveis, você pode ter mais controle sobre a segurança de suas conexões de banco de dados. É possível especificar uma lista de conjuntos de cifras que você deseja permitir para proteger conexões TLS/SSL do cliente com o banco de dados. Com conjuntos de cifras configuráveis, você pode controlar a criptografia de conexão aceita pelo servidor de banco de dados. Isso impede o uso de cifras que não são seguras ou que não são mais usadas.
Os clusters de banco de dados do Aurora Serverless v2 que são baseados no Aurora MySQL são compatíveis com os mesmos conjuntos de cifras que os clusters de banco de dados provisionados pelo Aurora MySQL. Para obter informações sobre esses conjuntos de cifras, consulte Configurar conjuntos de criptografia para conexões com clusters de banco de dados do Aurora MySQL.
Os clusters de banco de dados do Aurora Serverless v2 que são baseados no Aurora PostgreSQL são compatíveis com os mesmos conjuntos de cifras que os clusters de banco de dados provisionados pelo Aurora PostgreSQL. Para obter informações sobre esses conjuntos de cifras, consulte Configurar conjuntos de cifras para conexões a clusters de banco de dados PostgreSQL do Aurora.
Visualizar gravadores e leitores do Aurora Serverless v2
É possível visualizar os detalhes das instâncias de banco de dados do Aurora Serverless v2 da mesma forma que você faz para instâncias de banco de dados provisionadas. Para isso, siga o procedimento geral de Visualizar um cluster de bancos de dados Amazon Aurora. Um cluster pode conter todas as instâncias de banco de dados do Aurora Serverless v2, todas as instâncias de banco de dados provisionadas ou algumas de cada.
Depois de criar uma ou mais instâncias de banco de dados do Aurora Serverless v2, será possível visualizar quais delas são do tipo Serverless (Sem servidor) e quais são do tipo Instance (Instância). Também é possível visualizar as unidades de capacidade mínima e máxima do Aurora (ACUs) que a instância de banco de dados do Aurora Serverless v2 pode usar. Cada ACU é uma combinação da capacidade de processamento (CPU) e de memória (RAM). Esse intervalo de capacidade se aplica a todas as instâncias de banco de dados do Aurora Serverless v2 no cluster. Para que o procedimento confira o intervalo de capacidade de um cluster ou de qualquer instância de banco de dados do Aurora Serverless v2 no cluster, consulte Conferir o intervalo de capacidade do Aurora Serverless v2.
No AWS Management Console, as instâncias de banco de dados do Aurora Serverless v2 são marcadas sob a coluna Size (Tamanho) na página Databases (Bancos de dados). As instâncias de banco de dados provisionadas mostram o nome de uma classe de instância de banco de dados, como r6g.xlarge. As instâncias de banco de dados do Aurora Serverless mostram Serverless (Sem servidor) para a classe de instância de banco de dados, juntamente com a capacidade mínima e máxima da instância de banco de dados. Por exemplo, você pode ver Serverless v2 (4—64 ACUs) ou Serverless v2 (1-40 ACUs).
Você pode encontrar as mesmas informações na guia Configuration (Configuração) para cada instância de banco de dados do Aurora Serverless v2 no console. Por exemplo, talvez você veja uma seção Instance type (Tipo de instância) como a seguinte. Aqui, o valor Instance type (Tipo de instância) é Serverless v2, o valor Minimum capacity (Capacidade mínima) é 2 ACUs (4 GiB) e o valor Maximum capacity (Capacidade máxima) é 64 ACUs (128 GiB).
Você pode monitorar a capacidade de cada instância de banco de dados do Aurora Serverless v2 com o tempo. Dessa forma, é possível conferir as ACUs mínima, máxima e média consumidas por cada instância de banco de dados. Você também pode conferir a proximidade da instância de banco de dados de sua capacidade mínima ou máxima. Para ver esses detalhes no AWS Management Console, examine os grafos das métricas do Amazon CloudWatch na guia Monitoring (Monitoramento) para a instância de banco de dados. Para obter mais informações sobre as métricas a serem observadas e interpretá-las, consulte Métricas importantes do Amazon CloudWatch para o Aurora Serverless v2.
Registro em log para o Aurora Serverless v2
Para ativar o registro em log do banco de dados, especifique os logs a serem habilitados usando parâmetros de configuração em seu grupo de parâmetros personalizado.
No caso do Aurora MySQL, você pode habilitar os logs a seguir.
| Aurora MySQL | Descrição |
|---|---|
|
|
Cria o log geral. Defina como 1 para ativar. O padrão é desativado (0). |
|
|
Registra todas as consultas no log de consultas lentas que não usam um índice. O padrão é desativado (0). Defina como 1 para ativar esse log. |
|
|
Impede que consultas em execução rápida sejam registradas no log de consultas lentas. Pode ser definido como um float entre 0 e 31536000. O padrão é 0 (não ativo). |
|
|
A lista de eventos a serem capturados nos logs. Os valores compatíveis são |
|
|
Defina como 1 para ativar o log de auditoria do servidor. Se você ativar isso, você poderá especificar os eventos de auditoria a serem enviados, CloudWatch listando-os no |
|
|
Cria um log de consulta lento. Defina como 1 para ativar o log de consulta lenta. O padrão é desativado (0). |
Para obter mais informações, consulte Como utilizar a auditoria avançada em um cluster de banco de dados do Amazon Aurora MySQL.
Para o Aurora PostgreSQL, você pode habilitar os logs a seguir em suas instâncias de banco de dados do Aurora Serverless v2.
| Aurora PostgreSQL | Descrição |
|---|---|
|
|
Registra cada conexão bem-sucedida. |
|
|
Registra o fim de uma sessão, incluindo a duração. |
|
|
O padrão é 0 (desativado). Defina como 1 para registrar esperas por bloqueio. |
|
|
A duração mínima (em milissegundos) para que uma instrução seja executada antes de ser registrada. |
|
|
Define os níveis de mensagem registrados. Os valores compatíveis são debug5, debug4, debug3, debug2, debug1, info, notice, warning, error, log, fatal, panic. Para registrar dados de performance no log do postgres, defina o valor como debug1. |
|
|
Registra o uso de arquivos temporários que estão acima dos kilobytes (kB) especificados. |
|
|
Controla as instruções SQL específicas que são registradas. Os valores compatíveis são |
Tópicos
Registro em log com o Amazon CloudWatch
Depois de seguir o procedimento em Registro em log para o Aurora Serverless v2 para escolher quais logs de banco de dados ativar, você pode escolher quais logs carregar (“publicar”) para o Amazon CloudWatch.
É possível usar o Amazon CloudWatch para analisar os dados de log, criar alarmes e visualizar métricas. Por padrão, logs de erros para o Aurora Serverless v2 são habilitados e carregados automaticamente no CloudWatch. Você também pode carregar outros logs de instâncias de banco de dados do Aurora Serverless v2 no CloudWatch.
Depois, selecione de qual desses logs fazer upload para o CloudWatch usando as configurações Log exports (Exportações de log) no AWS Management Console ou a opção --enable-cloudwatch-logs-exports na AWS CLI.
É possível escolher qual dos seus logs do Aurora Serverless v2 carregar para o CloudWatch. Para obter mais informações, consulte Como utilizar a auditoria avançada em um cluster de banco de dados do Amazon Aurora MySQL.
Como em qualquer tipo de cluster de Aurora banco de dados, você não pode modificar o grupo de parâmetros de cluster de banco de dados padrão. Em vez disso, crie seu próprio grupo de parâmetros de cluster de banco de dados com base em um parâmetro padrão para o cluster de banco de dados e o tipo de mecanismo. Recomendamos que você crie seu grupo de parâmetros de cluster de banco de dados personalizado antes de criar seu cluster de Aurora Serverless v2 banco de dados, para que ele esteja disponível para escolher quando você cria um banco de dados no console.
nota
Para o Aurora Serverless v2, você pode criar um cluster de banco de dados e grupos de parâmetros de banco de dados. Isso é diferente com o Aurora Serverless v1, no qual você só pode criar grupos de parâmetros de cluster de banco de dados.
Visualizar logs do Aurora Serverless v2 no Amazon CloudWatch
Depois de usar o procedimento em Registro em log com o Amazon CloudWatch para escolher quais logs de banco de dados serão ativados, você pode visualizar o conteúdo dos logs.
Para obter mais informações sobre como usar o CloudWatch com os logs do CloudWatch ou do Aurora MySQL, consulte Monitorar eventos de log no Amazon CloudWatch e Publicar logs do Aurora PostgreSQL no Amazon CloudWatch Logs.
Para visualizar logs do cluster de banco de dados do Aurora Serverless v2
Abra o console do CloudWatch em https://console.aws.amazon.com/cloudwatch/
. -
Escolha a Região da AWS.
-
Escolha Grupos de logs.
-
Escolha o log do cluster de banco de dados do Aurora Serverless v2 na lista. O padrão de nomenclatura de log é o seguinte.
/aws/rds/cluster/cluster-name/log_type
nota
Para clusters de banco de dados Aurora Serverless v2 compatíveis com o Aurora MySQL, o log de erros inclui eventos de escalabilidade do grupo de buffer mesmo quando não há erros.
Monitoramento da capacidade com Amazon CloudWatch
Com Aurora Serverless v2, é possível usar o CloudWatch para monitorar a capacidade e a utilização de todas as instâncias de banco de dados do Aurora Serverless v2 em seu cluster. Você pode visualizar métricas específicas da instância para conferir a capacidade de cada instância de banco de dados do Aurora Serverless v2 à medida que a escala dela é reduzida ou aumentada na vertical. Você também pode comparar as métricas relacionadas à capacidade com outras métricas para ver como as alterações nas workloads afetam o consumo de recursos. Por exemplo, você pode comparar ServerlessDatabaseCapacity com DatabaseUsedMemory, DatabaseConnections e DMLThroughput para avaliar como seu cluster de banco de dados está respondendo durante as operações. Para obter detalhes sobre as métricas relacionadas à capacidade que se aplicam ao Aurora Serverless v2, consulte Métricas importantes do Amazon CloudWatch para o Aurora Serverless v2.
Para monitorar a capacidade do Aurora Serverless v2 cluster de banco de dados
Abra o console do CloudWatch em https://console.aws.amazon.com/cloudwatch/
. -
Escolha Metrics (Métricas). Todas as métricas disponíveis aparecem como cartões no console, agrupadas por nome do serviço.
-
Escolha RDS.
-
(Opcional) Use a caixa Search (Pesquisar) para encontrar as métricas que são especialmente importantes para Aurora Serverless v2:
ServerlessDatabaseCapacity,ACUUtilization,CPUUtilizationeFreeableMemory.
Recomendamos que você configure um painel do CloudWatch para monitorar a capacidade do cluster de banco de dados do Aurora Serverless v2 usando as métricas relacionadas à capacidade. Para saber como, consulte Criação de painéis com o CloudWatch.
Para saber mais sobre o uso do Amazon CloudWatch com o Amazon Aurora, consulte Publicar logs do Amazon Aurora MySQL no Amazon CloudWatch Logs.
