Performance e escalabilidade no Aurora Serverless v2
Os procedimentos e exemplos a seguir mostram como definir o intervalo de capacidade para clusters do Aurora Serverless v2 e suas instâncias de banco de dados associadas. Você também pode usar os procedimentos a seguir para monitorar o nível de ocupação de suas instâncias de banco de dados. Depois, é possível usar suas constatações para determinar se é necessário ajustar o intervalo de capacidade para cima ou para baixo.
Antes de usar estes procedimentos, verifique se sabe com funciona a escalabilidade do Aurora Serverless v2. O mecanismo de escalabilidade difere do Aurora Serverless v1. Para obter detalhes, consulte Escalabilidade do Aurora Serverless v2.
Sumário
escolher o intervalo de capacidade do Aurora Serverless v2 para um cluster do Aurora
Trabalhar com grupos de parâmetros para o Aurora Serverless v2
Métricas importantes do Amazon CloudWatch para o Aurora Serverless v2
Monitorar a performance do Aurora Serverless v2 com o Performance Insights
escolher o intervalo de capacidade do Aurora Serverless v2 para um cluster do Aurora
Com instâncias de banco de dados do Aurora Serverless v2, você define o intervalo de capacidade que se aplica a todas as instâncias de banco de dados em seu cluster ao mesmo tempo em que adiciona a primeira instância de banco de dados do Aurora Serverless v2. Para saber o procedimento, consulte Configurar o intervalo de capacidade de Aurora Serverless v2 para um cluster.
Você também pode alterar o intervalo de capacidade de um cluster existente. As seções a seguir abordam com mais detalhes como escolher valores mínimos e máximos apropriados e o que acontece quando você faz uma alteração no intervalo de capacidade. Por exemplo, alterar o intervalo de capacidade pode modificar os valores padrão de alguns parâmetros de configuração. Aplicar todas as alterações de parâmetros pode exigir a reinicialização de cada instância de banco de dados do Aurora Serverless v2.
Tópicos
Escolher a configuração de capacidade mínima do Aurora Serverless v2 para um cluster
É tentador escolher sempre 0,5 para a configuração de capacidade mínima do Aurora Serverless v2. Esse valor permite que a instância de banco de dados reduza sua escala na vertical para a menor capacidade quando estiver completamente ociosa, permanecendo ativa. Você também pode ativar o comportamento de pausa automática especificando uma capacidade mínima de 0 ACUs, conforme explicado em Escalar para zero ACUs com pausa e retomada automáticas no Aurora Serverless v2. No entanto, dependendo de como você usa esse cluster e das outras configurações definidas, uma capacidade mínima diferente pode ser o mais eficaz. Considere os seguintes fatores ao escolher a configuração de capacidade mínima:
-
A taxa de escalabilidade para uma instância de banco de dados do Aurora Serverless v2 depende de sua capacidade atual. Quanto maior a capacidade atual, com maior rapidez será possível aumentar a escala dela na vertical. Se você precisar aumentar a escala da instância de banco de dados na vertical com rapidez até uma capacidade muito alta, considere definir a capacidade mínima como um valor em que o intervalo de escalabilidade atenda às suas necessidades.
-
Se você normalmente modifica a classe de suas instâncias de banco de dados prevendo uma workload especialmente alta ou baixa, é possível usar essa experiência para realizar uma estimativa aproximada do intervalo de capacidade do Aurora Serverless v2 equivalente. Para determinar o tamanho da memória a ser usado em momentos de baixo tráfego, consulte Especificações de hardware para classes de instância de banco de dados para o Aurora.
Por exemplo, suponha que você use a classe de instância de banco de dados db.r6g.xlarge quando o cluster tem uma workload baixa. Essa classe de instância de banco de dados tem 32 GiB de memória. Assim, é possível especificar uma configuração mínima de unidade de capacidade do Aurora (ACU) de 16 para configurar uma instância de banco de dados do Aurora Serverless v2 que possa ser reduzida para aproximadamente a mesma capacidade. O motivo é que cada ACU corresponde a aproximadamente 2 GiB de memória. Você pode especificar um valor um pouco menor para permitir que a instância de banco de dados seja reduzida ainda mais no caso de sua instância db.r6g.xlarge às vezes ser subutilizada.
-
Se a aplicação funcionar de forma mais eficiente quando as instâncias de banco de dados tiverem uma certa quantidade de dados no cache de buffer, considere especificar uma configuração mínima de ACU em que a memória seja grande o suficiente para manter os dados acessados com frequência. Caso contrário, alguns dados serão removidos do cache de buffer quando a escala das instâncias de banco de dados do Aurora Serverless v2 é reduzida na vertical para um tamanho de memória menor. Então, quando a escala das instâncias de banco de dados for novamente aumentada na vertical, as informações serão lidas de volta no cache do buffer ao longo do tempo. Se a quantidade de E/S para trazer os dados de volta para o cache de buffer for substancial, talvez seja mais eficaz escolher um valor mínimo de ACU mais alto.
-
Se suas instâncias de banco de dados do Aurora Serverless v2 são executadas na maior parte do tempo em uma determinada capacidade, considere especificar uma configuração de capacidade mínima inferior à linha de base, mas não muito mais baixa. Aurora Serverless v2 As instâncias de banco de dados podem estimar com mais eficiência quanto e com que rapidez a escala será aumentada na vertical quando a capacidade atual não é drasticamente menor do que a capacidade necessária.
-
Se a workload provisionada tiver requisitos de memória muito altos para classes de instâncias de banco de dados pequenas, como T3 ou T4g, escolha uma configuração mínima de ACU que forneça memória comparável a uma instância de banco de dados R5 ou R6g.
Especificamente, recomendamos a seguinte capacidade mínima para uso com os recursos especificados (essas recomendações estão sujeitas a alterações):
-
Performance Insights: duas ACUs
-
Bancos de dados globais do Aurora: oito ACUs (aplica-se somente à Região da AWS primária)
-
-
No Aurora, a replicação ocorre na camada de armazenamento, portanto, a capacidade do leitor não afeta diretamente a replicação. No entanto, para instâncias de banco de dados de leitor do Aurora Serverless v2 que escalam de forma independente, certifique-se de que a capacidade mínima seja suficiente para lidar com workloads durante períodos intensivos de gravação, a fim de evitar a latência da consulta. Se instâncias de banco de dados de leitor nos níveis de promoção de 2 a 15 apresentarem problemas de desempenho, considere aumentar a capacidade mínima do cluster. Para obter detalhes sobre como determinar se as instâncias de banco de dados do leitor são escaladas junto com o gravador ou de forma independente, consulte Escolher o nível de promoção para um leitor do Aurora Serverless v2.
-
Se você tem um cluster de banco de dados com instâncias de banco de dados de leitor do Aurora Serverless v2, os leitores não escalam junto com a instância de banco de dados de gravador quando o nível de promoção dos leitores não é 0 ou 1. Nesse caso, definir uma capacidade mínima baixa pode ocasionar atraso excessivo de replicação. Isso ocorre porque os leitores podem não ter capacidade suficiente para aplicar alterações do gravador quando o banco de dados está ocupado. Recomendamos definir a capacidade mínima como um valor que represente uma quantidade comparável de memória e CPU à instância de banco de dados de gravador.
-
O valor do parâmetro
max_connectionspara instâncias de banco de dados do Aurora Serverless v2 é baseado no tamanho da memória derivado do máximo de ACUs. No entanto, quando você especifica uma capacidade mínima de 0 ou 0,5 ACU em instâncias de banco de dados compatíveis com o PostgreSQL, o valor máximo demax_connectionsé limitado a 2.000.Se você pretende usar o cluster do Aurora PostgreSQL para uma workload de alta conexão, considere usar uma configuração mínima de ACU de 1 ou superior. Para obter detalhes sobre como o Aurora Serverless v2 lida com o parâmetro de configuração
max_connections, consulte Conexões máximas do Aurora Serverless v2. -
O tempo necessário para uma instância de banco de dados do Aurora Serverless v2 escalar de sua capacidade mínima para sua capacidade máxima depende da diferença entre seus valores mínimo e máximo de ACU. Quando a capacidade atual da instância de banco de dados é grande, a escala do Aurora Serverless v2 é aumentada na vertical em incrementos maiores do que quando a instância de banco de dados parte de uma pequena capacidade. Assim, se você especificar uma capacidade máxima relativamente grande e a instância de banco de dados passar a maior parte do tempo próxima dessa capacidade, considere aumentar a configuração mínima de ACU. Dessa forma, a escala de uma instância de banco de dados ociosa pode ser aumentada na vertical novamente até a capacidade máxima com maior rapidez.
Escolher a configuração de capacidade máxima do Aurora Serverless v2 para um cluster
É tentador sempre escolher algum valor alto para configuração de capacidade do Aurora Serverless v2. Uma capacidade máxima grande permite que a escala da instância de banco de dados seja aumentada na vertical ao máximo quando está executando uma workload intensa. Um valor baixo evita a possibilidade de cobranças inesperadas. Dependendo de como você usa esse cluster e das outras configurações definidas, o valor mais efetivo pode ser maior ou menor do que o imaginado originalmente. Considere os seguintes fatores ao escolher a configuração de capacidade máxima:
-
A capacidade máxima deve ser pelo menos tão alta quanto a capacidade mínima. É possível definir a capacidade mínima e máxima como valores idênticos. No entanto, nesse caso, a escala da capacidade nunca é aumentada nem reduzida na vertical. Assim, usar valores idênticos para a capacidade mínima e máxima não é apropriado além das situações de teste.
-
A capacidade máxima deve ser superior a 0,5 ACU. É possível definir a capacidade mínima e máxima como o mesmo valor na maioria dos casos. No entanto, não é possível especificar 0,5 para o mínimo e o máximo. Use um valor de 1 ou superior para a capacidade máxima.
-
Se você normalmente modifica a classe de suas instâncias de banco de dados prevendo uma workload especialmente alta ou baixa, é possível usar essa experiência para calcular o intervalo de capacidade do Aurora Serverless v2 equivalente. Para determinar o tamanho da memória a ser usado em momentos de alto tráfego, consulte Especificações de hardware para classes de instância de banco de dados para o Aurora.
Por exemplo, suponha que você use a classe de instância de banco de dados db.r6g.4xlarge quando o cluster tem uma workload alta. Essa classe de instância de banco de dados tem 128 GiB de memória. Assim, é possível especificar uma configuração máxima de ACU de 64 para configurar uma instância de banco de dados do Aurora Serverless v2 cuja escala possa ser aumentada na vertical para aproximadamente a mesma capacidade. O motivo é que cada ACU corresponde a aproximadamente 2 GiB de memória. Você pode especificar um valor um pouco maior para aumentar ainda mais a escala da instância de banco de dados na vertical, caso sua instância de banco de dados db.r6g.4xlarge às vezes não tenha capacidade suficiente para lidar com a workload de forma eficaz.
-
Se você tiver um limite orçamentário para o uso do banco de dados, escolha um valor que permaneça dentro desse limite, mesmo que todas as suas instâncias de banco de dados do Aurora Serverless v2 sejam executadas na capacidade máxima o tempo todo. Lembre-se de que, quando há n instâncias de banco de dados do Aurora Serverless v2 em seu cluster, em tese, a capacidade do Aurora Serverless v2 que o cluster pode consumir a qualquer momento é n vezes a configuração máxima de ACU para o cluster. (A quantidade real consumida pode ser menor, por exemplo, se alguns leitores forem escalados independentemente do gravador.)
-
Se você fizer uso de instâncias de banco de dados do leitor do Aurora Serverless v2 para descarregar parte da workload somente leitura da instância de banco de dados do gravador, talvez você possa escolher uma configuração de capacidade máxima mais baixa. Esse procedimento é realizado para indicar que nem todas as instâncias de banco de dados do leitor precisam ser escaladas para um valor tão alto como seria necessário se o cluster contivesse apenas uma única instância de banco de dados.
-
Suponha que você queira evitar uso excessivo devido a parâmetros de banco de dados mal configurados ou consultas ineficientes em sua aplicação. Nesse caso, você pode evitar o uso excessivo acidental escolhendo uma configuração de capacidade máxima menor que a mais alta absoluta que seja possível definir.
-
Se os picos decorrentes da atividade real do usuário forem raros, mas acontecerem, você pode levar essas ocasiões em consideração ao escolher a configuração de capacidade máxima. Se a prioridade for a aplicação continuar a funcionar com performance e escalabilidade totais, especifique uma configuração de capacidade máxima maior do que a observada no uso normal. Se for aceitável a aplicação ser executada com taxa de transferência reduzida durante picos extremos de atividade, escolha uma configuração de capacidade máxima um pouco menor. Escolha uma configuração que ainda tenha memória e recursos de CPU suficientes para manter a aplicação em execução.
-
Se você ativar configurações em seu cluster que aumentem o uso de memória para cada instância de banco de dados, leve essa memória em consideração ao decidir sobre o valor máximo de ACU. Estão entre essas configurações aquelas para Performance Insights, consultas paralelas do Aurora MySQL, esquema de performance do Aurora MySQL e replicação de log binário do Aurora MySQL. Verifique se o valor máximo de ACU permite que a escala das instâncias de banco de dados do Aurora Serverless v2 seja aumentada na vertical o suficiente para lidar com a workload quando esses recursos estiverem sendo usados. Para obter informações sobre a solução de problemas causados pela combinação de uma configuração de ACU máxima baixa e recursos do Aurora que ocasionam sobrecarga de memória, consulte Evitar erros de falta de memória.
Exemplo: Alterar o intervalo de capacidade do Aurora Serverless v2 de um cluster do Aurora MySQL
Os exemplos da AWS CLI a seguir mostram como atualizar o intervalo da ACU para instâncias de banco de dados do Aurora Serverless v2 em um cluster existente do Aurora MySQL. Inicialmente, o intervalo de capacidade do cluster é de 8 a 32 ACUs.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
A instância de banco de dados está ociosa e sua escala é reduzida verticalmente para 8 ACUs. As configurações relacionadas à capacidade a seguir se aplicam à instância de banco de dados neste momento. Para representar o tamanho do grupo de buffer em unidades facilmente legíveis, o dividimos por dois para a potência de 30, produzindo uma medida em gibibytes (GiB). O motivo é que as medições relacionadas à memória para o Aurora usam unidades baseadas em potências de dois, não em potências de dez.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 9294577664 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 8.65625 | +-----------+ 1 row in set (0.00 sec)
Depois, alteramos o intervalo de capacidade do cluster. Após o término do comando modify-db-cluster, o intervalo de ACU do cluster é de 12,5 a 80.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
A alteração do intervalo de capacidade causou alterações nos valores padrão de alguns parâmetros de configuração. O Aurora pode aplicar alguns desses novos padrões imediatamente. No entanto, algumas das alterações de parâmetros são aplicadas somente após a reinicialização. O status do pending-reboot indica que é necessária uma reinicialização para aplicar algumas alterações de parâmetro.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
Neste ponto, o cluster está ocioso e a instância de banco de dados serverless-v2-instance-1 está consumindo 12,5 ACUs. O parâmetro innodb_buffer_pool_size já está ajustado com base na capacidade atual da instância de banco de dados. O parâmetro max_connections ainda reflete o valor da capacidade máxima anterior. A redefinição desse valor exige a reinicialização da instância de banco de dados.
nota
Se você definir o parâmetro max_connections diretamente em um grupo de parâmetros de banco de dados personalizado, nenhuma reinicialização será necessária.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 15572402176 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +---------------+ | gibibytes | +---------------+ | 14.5029296875 | +---------------+ 1 row in set (0.00 sec)
Agora reinicializamos a instância de banco de dados e aguardamos até que ela fique disponível novamente.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
O status pending-reboot está limpo. O valor in-sync confirma que o Aurora aplicou todas as alterações de parâmetros pendentes.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
O parâmetro innodb_buffer_pool_size aumentou para seu tamanho final para uma instância de banco de dados ociosa. O parâmetro max_connections aumentou para refletir um valor derivado do valor máximo de ACU. A fórmula que o Aurora usa para max_connections causa um aumento de 1.000 quando o tamanho da memória dobra.
mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 16139681792 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 15.03125 | +-----------+ 1 row in set (0.00 sec) mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 4000 | +-------------------+ 1 row in set (0.00 sec)
Definimos o intervalo de capacidade de 0,5 a 128 ACUs e reinicializamos a instância de banco de dados. Agora, a instância de banco de dados ociosa tem um tamanho de cache de buffer menor que 1 GiB, então nós a medimos em mebibytes (MiB). O valor max_connections de 5.000 é derivado do tamanho da memória da configuração de capacidade máxima.
mysql> select @@innodb_buffer_pool_size / pow(2,20) as mebibytes, @@max_connections; +-----------+-------------------+ | mebibytes | @@max_connections | +-----------+-------------------+ | 672 | 5000 | +-----------+-------------------+ 1 row in set (0.00 sec)
Exemplo: Alterar o intervalo de capacidade do Aurora Serverless v2 de um cluster do Aurora PostgreSQL
Os exemplos de CLI a seguir mostram como atualizar o intervalo de ACU para instâncias de banco de dados do Aurora Serverless v2 em um cluster existente do Aurora PostgreSQL.
-
O intervalo de capacidade do cluster começa em 0,5 a 1 ACU.
-
Altere o intervalo de capacidade para 8 a 32 ACUs.
-
Altere o intervalo de capacidade para 12,5 a 80 ACUs.
-
Altere o intervalo de capacidade para 0,5 a 128 ACUs.
-
Retorne a capacidade para seu intervalo inicial de 0,5 a 1 ACU.
A figura a seguir mostra as alterações de capacidade no Amazon CloudWatch.
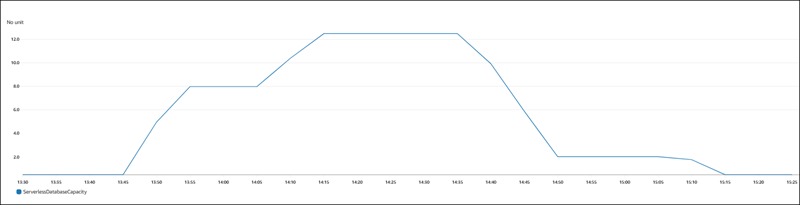
A instância de banco de dados está ociosa e sua escala é reduzida verticalmente para 0,5 ACUs. As configurações relacionadas à capacidade a seguir se aplicam à instância de banco de dados neste momento.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Depois, alteramos o intervalo de capacidade do cluster. Após o término do comando modify-db-cluster, o intervalo de ACU do cluster é de 8,0 a 32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
A alteração do intervalo de capacidade causa alterações nos valores padrão de alguns parâmetros de configuração. O Aurora pode aplicar alguns desses novos padrões imediatamente. No entanto, algumas das alterações de parâmetros são aplicadas somente após a reinicialização. O status do pending-reboot indica que é necessária uma reinicialização para aplicar algumas alterações de parâmetro.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
Neste ponto, o cluster está ocioso e a instância de banco de dados serverless-v2-instance-1 está consumindo 8,0 ACUs. O parâmetro shared_buffers já está ajustado com base na capacidade atual da instância de banco de dados. O parâmetro max_connections ainda reflete o valor da capacidade máxima anterior. A redefinição desse valor exige a reinicialização da instância de banco de dados.
nota
Se você definir o parâmetro max_connections diretamente em um grupo de parâmetros de banco de dados personalizado, nenhuma reinicialização será necessária.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Reinicializamos a instância de banco de dados e aguardamos até que ela fique disponível novamente.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
Agora que a instância de banco de dados foi reinicializada, o status pending-reboot é apagado. O valor in-sync confirma que o Aurora aplicou todas as alterações de parâmetros pendentes.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Após a reinicialização, max_connections mostra o valor da nova capacidade máxima.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Depois, alteramos o intervalo de capacidade do cluster para 12,5 a 80 ACUs.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
Neste ponto, o cluster está ocioso e a instância de banco de dados serverless-v2-instance-1 está consumindo 12,5 ACUs. O parâmetro shared_buffers já está ajustado com base na capacidade atual da instância de banco de dados. O valor max_connections ainda é 5.000.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Nós reinicializamos novamente, mas os valores dos parâmetros permanecem os mesmos. Isso ocorre porque max_connections tem um valor máximo de 5.000 para um cluster de banco de dados Aurora Serverless v2 executando o Aurora PostgreSQL.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Agora definimos o intervalo de capacidade de 0,5 a 128 ACUs. A escala do cluster de banco de dados é reduzida verticalmente para 10 ACUs e depois para 2. Reinicializamos a instância de banco de dados.
postgres=> show max_connections; max_connections ----------------- 2000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
O valor de max_connections para instâncias de banco de dados do Aurora Serverless v2 é baseado no tamanho da memória derivado do máximo de ACUs. No entanto, quando você especifica uma capacidade mínima de 0 ou 0,5 ACU em instâncias de banco de dados compatíveis com o PostgreSQL, o valor máximo de max_connections é limitado a 2.000.
Agora, retornamos a capacidade ao intervalo inicial de 0,5 a 1 ACU e reinicializamos a instância de banco de dados. O parâmetro max_connections retornou ao seu valor original.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Trabalhar com grupos de parâmetros para o Aurora Serverless v2
Quando você cria o seu cluster de banco de dados do Aurora Serverless v2, você escolhe um mecanismo de banco de dados do Aurora específico e um grupo de parâmetros de cluster de banco de dados associado. Se você não estiver familiarizado com a forma como o Aurora usa grupos de parâmetros para aplicar configurações de forma consistente em clusters, consulte Grupos de parâmetros para Amazon Aurora. Todos esses procedimentos para criar, modificar, aplicar e realizar outras ações para grupos de parâmetros se aplicam ao Aurora Serverless v2.
O recurso de grupo de parâmetros geralmente funciona da mesma forma entre clusters provisionados e clusters que contenham instâncias de banco de dados do Aurora Serverless v2:
-
Os valores de parâmetros de cluster padrão para todas as instâncias de banco de dados no cluster são definidos pelo grupo de parâmetros.
-
É possível substituir alguns parâmetros para instâncias de banco de dados específicas determinando um grupo de parâmetros de banco de dados personalizado para elas. Você pode fazer isso durante a depuração ou o ajuste de performance para instâncias de banco de dados específicas. Por exemplo, digamos que você tenha um cluster que contenha algumas instâncias de banco de dados do Aurora Serverless v2 e algumas instâncias de banco de dados provisionadas. Nesse caso, você pode especificar alguns parâmetros diferentes para as instâncias de banco de dados provisionadas usando um grupo de parâmetros de banco de dados personalizado.
-
No caso do Aurora Serverless v2, é possível usar todos os parâmetros que tenham o valor
provisionedno atributoSupportedEngineModesno grupo de parâmetros. No Aurora Serverless v1, você só pode usar o subconjunto de parâmetros que temserverlessno atributoSupportedEngineModes.
Tópicos
Valores de parâmetro padrão
A diferença crucial entre instâncias de banco de dados provisionadas e as instâncias de banco de dados do Aurora Serverless v2 é que o Aurora substitui todos os valores de parâmetro personalizados por determinados parâmetros relacionados à capacidade da instância de banco de dados. Os valores de parâmetros personalizados ainda se aplicam a qualquer instância de banco de dados provisionada em seu cluster. Para obter mais detalhes sobre como as instâncias de banco de dados do Aurora Serverless v2 interpretam os parâmetros dos grupos de parâmetros do Aurora, consulte Parâmetros de configuração para clusters do Aurora. Para saber quais parâmetros específicos são substituídos pelo Aurora Serverless v2, consulte Parâmetros ajustados pelo Aurora à medida que a escala do Aurora Serverless v2 é aumentada ou reduzida na vertical e Parâmetros calculados pelo Aurora com base na capacidade máxima do Aurora Serverless v2.
Você pode obter uma lista de valores padrão para os grupos de parâmetros padrão dos vários mecanismos de banco de dados do Aurora usando o comando da CLI describe-db-cluster-parameters e consultando da Região da AWS. Veja a seguir os valores que você pode usar para as opções --db-parameter-group-family e -db-parameter-group-name para versões de mecanismo compatíveis com o Aurora Serverless v2.
| Mecanismo de banco de dados e versão | Família de grupos de parâmetros | Nome do grupo de parâmetros padrão |
|---|---|---|
|
Aurora MySQL versão 3 |
|
|
|
Aurora PostgreSQL versão 13.x |
|
|
|
Aurora PostgreSQL versão 14.x |
|
|
|
Aurora PostgreSQL versão 15.x |
|
|
|
Aurora PostgreSQL versão 16.x |
|
|
|
Aurora PostgreSQL versão 17.x |
|
|
O exemplo a seguir obtém uma lista de parâmetros do grupo de clusters de banco de dados padrão para o Aurora MySQL versão 3 o Aurora PostgreSQL 13. Estas são as versões do Aurora MySQL e do Aurora PostgreSQL utilizadas com o Aurora Serverless v2.
Para Linux, macOS ou Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-postgresql13 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text
Para Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-mysql8.0 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-postgresql13 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text
Conexões máximas do Aurora Serverless v2
No caso do Aurora MySQL e do Aurora PostgreSQL, as instâncias de banco de dados do Aurora Serverless v2 têm o parâmetro max_connections constante para que as conexões não sejam desativadas quando a escala da instância de banco de dados é reduzida na vertical. O valor padrão para esse parâmetro é derivado de uma fórmula com base no tamanho da memória da instância de banco de dados. Para obter detalhes sobre a fórmula e os valores padrão para classes de instâncias de banco de dados provisionadas, consulte Número máximo de conexões com uma instância de bancos de dados Aurora MySQL e Número máximo de conexões com uma instância de bancos de dados Aurora PostgreSQL.
Quando o Aurora Serverless v2 avalia a fórmula, ele usa o tamanho da memória com base nas unidades de capacidade máxima do Aurora (ACUs) para a instância de banco de dados, não no valor atual de ACU. Se você alterar o valor padrão, recomendamos usar uma variação da fórmula em vez de especificar um valor constante. Dessa forma, o Aurora Serverless v2 pode usar uma configuração apropriada com base na capacidade máxima.
Ao alterar a capacidade máxima de um cluster de banco de dados Aurora Serverless v2, você precisa reinicializar as instâncias de banco de dados Aurora Serverless v2 para atualizar o valor max_connections. Isso ocorre porque max_connections é um parâmetro estático do Aurora Serverless v2.
A tabela a seguir mostra os valores padrão de max_connections para o Aurora Serverless v2 com base no valor máximo da ACU.
| ACUs máximas | Conexões máximas padrão no Aurora MySQL | Conexões máximas padrão no Aurora PostgreSQL |
|---|---|---|
| 1 | 90 | 189 |
| 4 | 135 | 823 |
| 8 | 1.000 | 1.669 |
| 16 | 2.000 | 3.360 |
| 32 | 3.000 | 5.000 |
| 64 | 4.000 | 5.000 |
| 128 | 5.000 | 5.000 |
| 192 | 6.000 | 5.000 |
| 256 | 6.000 | 5.000 |
nota
O valor de max_connections para instâncias de banco de dados do Aurora Serverless v2 é baseado no tamanho da memória derivado do máximo de ACUs. No entanto, quando você especifica uma capacidade mínima de 0 ou 0,5 ACU em instâncias de banco de dados compatíveis com o PostgreSQL, o valor máximo de max_connections é limitado a 2.000.
Para exemplos específicos que mostram como o max_connections muda com o valor máximo da ACU, consulte Exemplo: Alterar o intervalo de capacidade do Aurora Serverless v2 de um cluster do Aurora MySQL e Exemplo: Alterar o intervalo de capacidade do Aurora Serverless v2 de um cluster do Aurora PostgreSQL.
Parâmetros ajustados pelo Aurora à medida que a escala do Aurora Serverless v2 é aumentada ou reduzida na vertical
Durante a escalabilidade automática, o Aurora Serverless v2 precisa ser capaz de alterar os parâmetros para que cada instância de banco de dados funcione melhor com a capacidade aumentada ou reduzida. Dessa forma, não é possível substituir alguns parâmetros relacionados à capacidade. Para alguns parâmetros que possam ser substituídos, evite a codificação de forma rígida. As considerações a seguir se aplicam a essas configurações relacionadas à capacidade.
No caso do Aurora MySQL, o Aurora Serverless v2 redimensiona alguns parâmetros dinamicamente durante a escalabilidade. No caso dos parâmetros a seguir, o Aurora Serverless v2 não usa nenhum valor de parâmetro personalizado que seja especificado:
-
innodb_buffer_pool_size -
innodb_purge_threads -
table_definition_cache -
table_open_cache
No caso do Aurora PostgreSQL, o Aurora Serverless v2 redimensiona os parâmetros a seguir dinamicamente durante a escalabilidade. No caso dos parâmetros a seguir, o Aurora Serverless v2 não usa nenhum valor de parâmetro personalizado que seja especificado:
-
shared_buffers
No caso de todos os parâmetros diferentes dos listados aqui, as instâncias de banco de dados do Aurora Serverless v2 funcionam da mesma forma que as instâncias de banco de dados provisionadas. O valor padrão para o parâmetro é herdado do grupo de parâmetros de cluster. É possível modificar o valor padrão para todo o cluster usando um grupo de parâmetros de cluster personalizado. Você também pode modificar o valor padrão para determinadas instâncias de banco de dados usando um grupo de parâmetros de banco de dados personalizado. Os parâmetros dinâmicos são atualizados imediatamente. As alterações nos parâmetros estáticos só são aplicadas após a reinicialização da instância do banco de dados.
Parâmetros calculados pelo Aurora com base na capacidade máxima do Aurora Serverless v2
No caso dos parâmetros a seguir, o Aurora PostgreSQL usa valores padrão que são derivados do tamanho da memória com base na configuração máxima de ACU, da mesma forma que ocorre com o max_connections:
-
autovacuum_max_workers -
autovacuum_vacuum_cost_limit -
autovacuum_work_mem -
effective_cache_size -
maintenance_work_mem
Evitar erros de falta de memória
Se uma de suas instâncias de banco de dados do Aurora Serverless v2 atinge de forma consistente o limite de sua capacidade máxima, o Aurora indica essa condição definindo o status da instância de banco de dados como incompatible-parameters. Enquanto a instância de banco de dados apresentar o status incompatible-parameters, algumas operações ficarão bloqueadas. Por exemplo, não é possível atualizar a versão do mecanismo.
Normalmente, sua instância de banco de dados entra nesse status quando ela é reiniciada com frequência devido a erros de falta de memória. O Aurora registra um evento quando esse tipo de reinicialização acontece. Você pode visualizar o evento seguindo o procedimento em Visualizar eventos do Amazon RDS. O uso de memória excepcionalmente alto pode ocorrer devido à sobrecarga causada pela ativação de configurações como Performance Insights e autenticação do IAM. A causa também pode ser uma workload pesada em sua instância de banco de dados ou o gerenciamento dos metadados associados a um grande número de objetos de esquema.
Se a pressão da memória se tornar menor para que a instância de banco de dados não atinja sua capacidade máxima com muita frequência, o Aurora alterará automaticamente o status da instância de banco de dados de volta para available.
Para se recuperar dessa condição, você pode realizar algumas ou todas as seguintes ações:
-
Aumente o limite inferior de capacidade para as instâncias de banco de dados do Aurora Serverless v2 alterando o valor mínimo da unidade de capacidade (ACU) do Aurora para o cluster. Isso evita problemas em que um banco de dados ocioso tem a escala reduzida na vertical para uma capacidade com menos memória do que o necessário para os recursos que estão ativados no cluster. Depois de alterar as configurações de ACU do cluster, reinicie a instância de banco de dados do Aurora Serverless v2. Com esse procedimento, você avalia se o Aurora consegue redefinir o status de volta como
available. -
Aumente o limite superior de capacidade das instâncias de banco de dados do Aurora Serverless v2 alterando o valor máximo da unidade de capacidade (ACU) do Aurora para o cluster. Isso evita problemas em que não é possível aumentar a escala de um banco de dados ocupado na vertical até uma capacidade com memória suficiente para os recursos ativados no cluster e na workload do banco de dados. Depois de alterar as configurações de ACU do cluster, reinicie a instância de banco de dados do Aurora Serverless v2. Com esse procedimento, você avalia se o Aurora consegue redefinir o status de volta como
available. -
Desative as configurações que exigem sobrecarga de memória. Por exemplo, digamos que você tenha recursos, como o AWS Identity and Access Management (IAM), o Performance Insights ou a replicação de logs binários do Aurora MySQL ativados, mas não os use. Se esse for o caso, você pode desativá-los. Também é possível ajustar os valores de capacidade mínima e máxima do cluster para valores mais altos com o objetivo de levar em conta a memória utilizada por esses recursos. Para obter as diretrizes sobre como escolher configurações de capacidade mínima e máxima, consulte escolher o intervalo de capacidade do Aurora Serverless v2 para um cluster do Aurora.
-
Reduza a workload na instância de banco de dados. Por exemplo, você pode adicionar instâncias de banco de dados de leitor ao cluster para distribuir a carga de consultas somente leitura por mais instâncias de banco de dados.
-
Ajuste o código SQL usado pela aplicação para usar menos recursos. Por exemplo, você pode examinar seus planos de consulta, conferir o log de consultas lento ou ajustar os índices em suas tabelas. Também é possível realizar outros tipos tradicionais de ajuste SQL.
Métricas importantes do Amazon CloudWatch para o Aurora Serverless v2
Para começar a usar o Amazon CloudWatch para sua instância de banco de dados do Aurora Serverless v2, consulte Visualizar logs do Aurora Serverless v2 no Amazon CloudWatch. Para saber mais sobre como monitorar clusters de Aurora banco de dados por meio de CloudWatch, consulte Monitorar eventos de log no Amazon CloudWatch.
É possível visualizar suas instâncias de banco de dados do Aurora Serverless v2 no CloudWatch para monitorar a capacidade consumida por cada instância de banco de dados com a métrica ServerlessDatabaseCapacity. Você também pode monitorar todas as métricas padrão do CloudWatch para o Aurora, como DatabaseConnections e Queries. Para ver a lista completa de métricas do CloudWatch que é possível monitorar para o Aurora, consulte Métricas do Amazon CloudWatch para o Amazon Aurora. As métricas são divididas em métricas em nível de cluster e em nível de instância, em Métricas no nível do cluster do Amazon Aurora e Métricas no nível da instância do Amazon Aurora.
É importante monitorar as métricas de nível de instância do CloudWatch a seguir para que você compreenda como suas instâncias de banco de dados do Aurora Serverless v2 estão sendo expandidas ou reduzidas. Todas essas métricas são calculadas a cada segundo. Dessa forma, você pode monitorar o status atual das instâncias de banco de dados do Aurora Serverless v2. É possível definir alarmes para notificá-lo se alguma instância de banco de dados do Aurora Serverless v2 se aproximar de um limite das métricas relacionadas à capacidade. Você pode determinar se as configurações de capacidade mínima e máxima são apropriadas ou se você precisa ajustá-las. É possível determinar onde concentrar seus esforços para otimizar a eficiência de seu banco de dados.
-
ServerlessDatabaseCapacity. como métrica específica da instância, ela relata o número de ACUs representadas pela capacidade atual da instância de banco de dados. Como métrica específica do cluster, ela representa a média dos valores deServerlessDatabaseCapacityde todas as instâncias de banco de dados do Aurora Serverless v2 no cluster. Essa métrica é apenas uma métrica específica do cluster no Aurora Serverless v1. No Aurora Serverless v2, está disponível no nível da instância de banco de dados e no nível do cluster. -
ACUUtilization. Essa métrica é nova no Aurora Serverless v2. Esse valor é representado como uma porcentagem. É calculado como o valor da métricaServerlessDatabaseCapacitydividida pelo valor máximo de ACU do cluster de banco de dados. Considere as seguintes diretrizes para interpretar essa métrica e agir:-
Se essa métrica se aproximar de um valor de
100.0, a escala da instância de banco de dados foi aumentada na vertical ao nível mais elevado possível. Considere aumentar a configuração máxima de ACU para o cluster. Dessa forma, as instâncias de banco de dados do gravador e do leitor podem ser escaladas para uma capacidade maior. -
Suponha que uma workload somente leitura faça com que uma instância de banco de dados do leitor se aproxime de um
ACUUtilizationde100.0, enquanto a instância de banco de dados do gravador não está próxima de sua capacidade máxima. Nesse caso, considere adicionar mais instâncias de banco de dados de leitor ao cluster. Dessa forma, você pode distribuir a parte somente leitura da workload por mais instâncias de banco de dados, reduzindo a carga em cada instância de banco de dados do leitor. -
Suponha que você esteja executando uma aplicação de produção, em que a performance e a escalabilidade sejam as principais considerações. Nesse caso, é possível definir o valor máximo de ACU para o cluster como um número elevado. Seu objetivo é que a métrica
ACUUtilizationpermaneça sempre abaixo de100.0. Com um alto valor máximo de ACU, você pode ter certeza de que há espaço suficiente caso haja picos inesperados na atividade do banco de dados. Você só será cobrado pela capacidade do banco de dados que for realmente consumida.
-
-
CPUUtilization. Essa métrica no Aurora Serverless v2 é interpretada de modo diferente do que é em instâncias de banco de dados provisionadas. No caso do Aurora Serverless v2, esse valor é uma porcentagem calculada como a quantidade de CPU que está sendo usada atualmente dividida pela capacidade da CPU disponível abaixo do valor máximo de ACU do cluster de banco de dados. O Aurora monitora esse valor automaticamente e aumenta a escala de sua instância de banco de dados do Aurora Serverless v2 na vertical quando ela usa consistentemente uma alta proporção de sua capacidade de CPU.Se essa métrica se aproximar de um valor de
100.0, a instância de banco de dados atingiu sua capacidade máxima de CPU. Considere aumentar a configuração máxima de ACU para o cluster. Se essa métrica se aproximar de um valor de100.0em uma instância de banco de dados do leitor, considere adicionar mais instâncias de banco de dados do leitor ao cluster. Dessa forma, você pode distribuir a parte somente leitura da workload por mais instâncias de banco de dados, reduzindo a carga em cada instância de banco de dados do leitor. -
FreeableMemory. Esse valor representa a quantidade de memória não utilizada que está disponível quando a instância de banco de dados do Aurora Serverless v2 é escalada para sua capacidade máxima. Para cada ACU em que a capacidade atual está abaixo da capacidade máxima, esse valor aumenta em aproximadamente 2 GiB. Assim, essa métrica não se aproxima de zero até que a escala da instância de banco de dados seja aumentada na vertical ao nível mais alto possível.Se essa métrica se aproximar de um valor de
0, a escala da instância de banco de dados foi aumentada na vertical ao nível mais alto possível e está se aproximando do limite de sua memória disponível. Considere aumentar a configuração máxima de ACU para o cluster. Se essa métrica se aproximar de um valor de0em uma instância de banco de dados do leitor, considere adicionar mais instâncias de banco de dados do leitor ao cluster. Dessa forma, é possível distribuir a parte somente leitura da workload por mais instâncias de banco de dados, reduzindo o uso de memória em cada instância de banco de dados do leitor. -
TempStorageIOPS. O número de IOPS realizadas no armazenamento local anexado à instância de banco de dados. Ele inclui as IOPS para leituras e gravações. Essa métrica representa uma contagem e é medida uma vez por segundo. É uma nova métrica do Aurora Serverless v2. Para obter detalhes, consulte Métricas no nível da instância do Amazon Aurora. -
TempStorageThroughput. A quantidade de dados transferidos entre o armazenamento local associado e a instância de banco de dados. Essa métrica é apresentada em bytes e é medida uma vez por segundo. É uma nova métrica do Aurora Serverless v2. Para obter detalhes, consulte Métricas no nível da instância do Amazon Aurora.
Normalmente, a maioria das expansões de instâncias de banco de dados do Aurora Serverless v2 é ocasionada pelo uso de memória e atividade da CPU. As métricas TempStorageIOPS e TempStorageThroughput podem ajudar você a diagnosticar os casos raros em que a atividade de rede para transferências entre sua instância de banco de dados e dispositivos de armazenamento local é responsável por aumentos inesperados de capacidade. Para monitorar outras atividades de rede, você pode usar estas métricas existentes:
-
NetworkReceiveThroughput -
NetworkThroughput -
NetworkTransmitThroughput -
StorageNetworkReceiveThroughput -
StorageNetworkThroughput -
StorageNetworkTransmitThroughput
É possível fazer com que o Aurora publique alguns ou todos os logs de banco de dados no Amazon CloudWatch Logs. Consulte as seguintes instruções, dependendo do mecanismo de banco de dados:
Como as métricas Aurora Serverless v2 se aplicam à sua fatura da AWS
As cobranças do Aurora Serverless v2 em sua fatura da AWS são calculadas com base na mesma métrica do ServerlessDatabaseCapacity que você pode monitorar. O mecanismo de faturamento pode diferir da média computada do CloudWatch para essa métrica nos casos em que você usa a capacidade do Aurora Serverless v2 por somente parte de uma hora. Também pode ser diferente se os problemas do sistema deixarem a métrica do CloudWatch indisponível por breves períodos. Dessa forma, talvez você veja em sua fatura um valor um pouco diferente de horas de ACU do que o exibido se você mesmo calcular o número a partir do valor médio de ServerlessDatabaseCapacity.
Exemplos de comandos do CloudWatch para métricas do Aurora Serverless v2
Os exemplos da AWS CLI a seguir demonstram como monitorar as métricas mais importantes do CloudWatch relacionadas ao Aurora Serverless v2. Em cada caso, substitua a string Value= do parâmetro --dimensions pelo identificador de sua própria instância de banco de dados do Aurora Serverless v2.
O exemplo do Linux a seguir exibe os valores de capacidade mínima, máxima e média de uma instância de banco de dados, medidos a cada dez minutos em uma hora. O comando date do Linux especifica as horas de início e término em relação à data e hora atuais. A função sort_by no parâmetro --query classifica os resultados cronologicamente com base no campo Timestamp.
aws cloudwatch get-metric-statistics --metric-name "ServerlessDatabaseCapacity" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Os exemplos do Linux a seguir demonstram o monitoramento da capacidade de cada instância de banco de dados em um cluster. Eles medem a utilização mínima, máxima e média da capacidade de cada instância de banco de dados. As medições são realizadas uma vez por hora durante um período de três horas. Esses exemplos usam a métrica ACUUtilization que representa uma porcentagem do limite superior em ACUs, em vez de ServerlessDatabaseCapacity representando um número fixo de ACUs. Dessa forma, não é necessário conhecer os números reais para os valores mínimo e máximo de ACU no intervalo de capacidade. É possível ver porcentagens que variam de 0 a 100.
aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_writer_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_reader_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
O exemplo do Linux a seguir realiza medições semelhantes às anteriores. Nesse caso, as medidas são para a métrica CPUUtilization. As medições são realizadas a cada dez minutos durante um período de uma hora. Os números representam a porcentagem de CPU disponível usada, com base nos recursos da CPU disponíveis para a configuração de capacidade máxima para a instância de banco de dados.
aws cloudwatch get-metric-statistics --metric-name "CPUUtilization" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
O exemplo do Linux a seguir realiza medições semelhantes às anteriores. Nesse caso, as medidas são para a métrica FreeableMemory. As medições são realizadas a cada dez minutos durante um período de uma hora.
aws cloudwatch get-metric-statistics --metric-name "FreeableMemory" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Monitorar a performance do Aurora Serverless v2 com o Performance Insights
É possível usar o Performance Insights para monitorar a performance das instâncias de banco de dados do Aurora Serverless v2. Para saber os procedimentos do Performance Insights, consulte Monitorar a carga de banco de dados com o Performance Insights no Amazon Aurora.
Os novos contadores do Performance Insights a seguir se aplicam a instâncias de banco de dados do Aurora Serverless v2:
-
os.general.serverlessDatabaseCapacity: a capacidade atual da instância de banco de dados em ACUs. O valor corresponde à métricaServerlessDatabaseCapacitydo CloudWatch para a instância de banco de dados. -
os.general.acuUtilization: a porcentagem de capacidade atual da capacidade máxima configurada. O valor corresponde à métricaACUUtilizationdo CloudWatch para a instância de banco de dados. -
os.general.maxConfiguredAcu: a capacidade máxima que você configurou para essa instância de banco de dados do Aurora Serverless v2. É medida em ACUs. -
os.general.minConfiguredAcu: a capacidade mínima que você configurou para essa instância de banco de dados do Aurora Serverless v2. É medida em ACUs.
Para ver a lista completa de contadores do Performance Insights, consulte Métricas de contadores do Performance Insights.
Quando valores vCPU são mostrados para uma instância de banco de dados do Aurora Serverless v2 no Performance Insights, esses valores representam estimativas com base no valor de ACU para a instância de banco de dados. No intervalo padrão de um minuto, todos os valores de vCPU fracionários são arredondados para o número inteiro mais próximo. Para intervalos mais longos, o valor de vCPU mostrado é a média dos valores inteiros de vCPU para cada minuto.
Solução de problemas de capacidade do Aurora Serverless v2
Em alguns casos, a escala do Aurora Serverless v2 não é reduzida verticalmente para a capacidade mínima, mesmo sem carga no banco de dados. Isso pode acontecer por um dos seguintes motivos.
-
Determinados recursos podem aumentar o uso de recursos e impedir que a escala do banco de dados seja reduzida verticalmente para a capacidade mínima. Esses recursos incluem o seguinte:
-
Bancos de dados globais do Aurora
-
Exportar logs do CloudWatch
-
Habilitar
pg_auditem clusters de banco de dados compatíveis com o Aurora PostgreSQL -
Monitoramento avançado
-
Insights de Performance
Para obter mais informações, consulte Escolher a configuração de capacidade mínima do Aurora Serverless v2 para um cluster.
-
-
Se a escala de uma instância de leitor não estiver sendo reduzida verticalmente ao mínimo e permanecer com a mesma capacidade ou maior que a instância do gravador, confira o nível de prioridade da instância do leitor. As instâncias de banco de dados do leitor do Aurora Serverless v2 no nível 0 ou 1 são mantidas em uma capacidade mínima pelo menos tão alta quanto a instância de banco de dados do gravador. Altere o nível de prioridade do leitor para 2 ou superior para que ele aumente e reduza a escala verticalmente independentemente do gravador. Para ter mais informações, consulte Escolher o nível de promoção para um leitor do Aurora Serverless v2.
-
Defina os parâmetros do banco de dados que afetam o tamanho da memória compartilhada como seus valores padrão. Definir um valor maior do que o padrão aumenta a necessidade de memória compartilhada e evita que a escala do banco de dados seja reduzida verticalmente para a capacidade mínima. Os exemplos são
max_connectionsemax_locks_per_transaction.nota
Atualizar parâmetros de memória compartilhada exige que o banco de dados seja reiniciado para que as alterações entrem em vigor.
-
Workloads de banco de dados pesadas podem aumentar o uso de recursos.
-
Grandes volumes de banco de dados podem aumentar o uso de recursos.
O Amazon Aurora usa recursos de memória e CPU para o gerenciamento de clusters de banco de dados. O Aurora exige mais CPU e memória para gerenciar clusters de banco de dados com volumes maiores de banco de dados. Se a capacidade mínima do cluster for menor do que a mínima exigida para o gerenciamento do cluster, a escala do cluster não será reduzida verticalmente para a capacidade mínima.
-
Processos em segundo plano, como a limpeza, também podem aumentar o uso de recursos.
Se a escala do banco de dados ainda não for reduzida verticalmente até a capacidade mínima configurada, pare e reinicie o banco de dados para recuperar quaisquer fragmentos de memória que possam ter se acumulado ao longo do tempo. Interromper e iniciar um banco de dados ocasiona tempo de inatividade, por isso recomendamos fazer isso com moderação.
