Implantações de instâncias de banco de dados multi-AZ para o Amazon RDS
O Amazon RDS oferece alta disponibilidade e suporte para failover em instâncias de banco de dados utilizando implantações multi-AZ com uma única instâncias de banco de dados em espera. Esse tipo de implantação é chamado de implantação de instância de banco de dados multi-AZ. O Amazon RDS usa várias tecnologias diferentes para fornecer esse suporte para failover. Implantações multi-AZ para instâncias de banco de dados MariaDB, MySQL, Oracle, PostgreSQL e RDS Custom para SQL Server usam a tecnologia de failover da Amazon. Instâncias de banco de dados do Microsoft SQL Server utilizam o SQL Server Database Mirroring (DBM) ou grupos de disponibilidade (AGs) Always On. Para obter informações sobre o suporte à versão do SQL Server para multi-AZ, consulte Implantações multi-AZ para o Amazon RDS for Microsoft SQL Server. Para ter informações sobre como trabalhar com o RDS Custom para multi-AZ, consulte Gerenciar uma implantação multi-AZ para o RDS Custom para SQL Server.
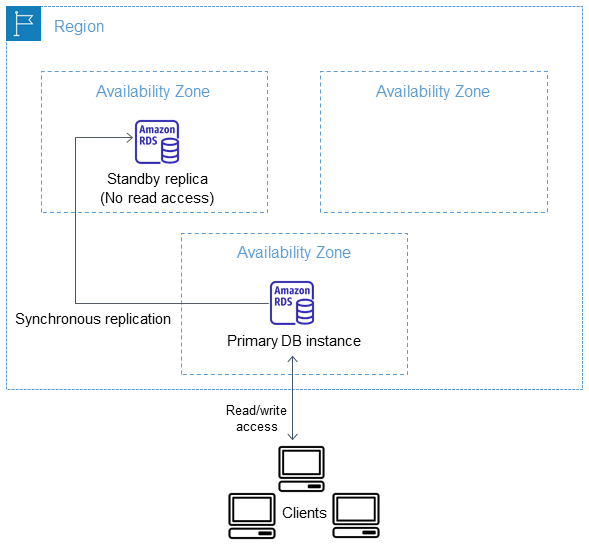
Em uma implantação de instância de banco de dados multi-AZ, o Amazon RDS provisiona e mantém automaticamente uma réplica em espera síncrona em outra zona de disponibilidade. A instância de banco de dados primária é replicada simultaneamente através de zonas de disponibilidade para uma réplica em espera, a fim de proporcionar a redundância de dados e minimizar os picos de latência durante os backups do sistema. Executar uma instância de banco de dados com alta disponibilidade pode aumentar a disponibilidade durante a manutenção planejada do sistema. Também pode ajudar a proteger bancos de dados contra falhas na instância de banco de dados e interrupção da zona de disponibilidade. Para ter mais informações sobre zonas de disponibilidade, consulte Regiões, zonas de disponibilidade e Local Zones.
nota
A opção de alta disponibilidade não é uma solução de escalabilidade para cenários somente leitura. Não é possível utilizar uma réplica em espera para servir tráfego de leitura. Para servir tráfego somente leitura, utilize um cluster de banco de dados multi-AZ ou uma réplica de leitura. Para ter mais informações sobre clusters de banco de dados multi-AZ, consulte Implantações de cluster de banco de dados multi-AZ para o Amazon RDS. Para ter mais informações sobre réplicas de leitura, consulte Trabalhar com réplicas de leitura de instância de banco de dados.
Com o console do RDS, é possível criar uma implantação de instância de banco de dados multi-AZ. Basta especificar multi-AZ ao criar essa instância. Você pode utilizar o console para converter instâncias de banco de dados existentes em implantações de instâncias de banco de dados multi-AZ, modificando a instância de banco de dados e especificando a opção multi-AZ. Também pode especificar uma implantação multi-AZ com a AWS CLI ou a API do Amazon RDS. Use o comando da CLI create-db-instance ou modify-db-instance ou a operação da API CreateDBInstance ou ModifyDBInstance.
O console do RDS mostra a zona de disponibilidade da réplica em espera (chamada AZ secundária). Você também pode usar o comando describe-db-instances da CLI ou a operação DescribeDBInstances da API para localizar a AZ secundária.
Instâncias de banco de dados que usam implantações de instância de banco de dados multi-AZ podem ter maior latência de gravação e confirmação em comparação com uma implantação single-AZ. Isso pode acontecer devido à replicação de dados síncrona que ocorre. É possível ter uma alteração na latência se sua implantação falhar na réplica em espera, ainda que o AWS seja desenvolvido com conectividade de rede de baixa latência entre zonas de disponibilidade. Para uma aplicação de produção que exija performance de E/S rápida e consistente, recomendamos o armazenamento de IOPS provisionadas (operações de entrada/saída por segundo). Para ter mais informações sobre classes de instância de banco de dados, consulte Classes de instâncias de banco de dados do .
