Conector do Amazon Athena para o HBase
O conector do HBase no Amazon Athena permite que o Amazon Athena se comunique com as instâncias do Apache HBase para que você possa consultar os dados do HBase com SQL.
Diferentemente dos armazenamentos de dados relacionais tradicionais, as coleções do HBase não têm um esquema definido. O HBase não tem um armazenamento de metadados. Cada entrada em uma coleção do HBase pode ter diferentes campos e tipos de dados.
O conector HBase oferece suporte a dois mecanismos para gerar informações do esquema da tabela: inferência básica de esquema e metadados do AWS Glue Data Catalog.
A inferência de esquema é o padrão. Essa opção examina um pequeno número de documentos em sua coleção, forma uma união de todos os campos e força campos que têm tipos de dados não sobrepostos. Essa opção funciona bem para coleções que têm, em sua maioria, entradas uniformes.
Para coleções com uma maior variedade de tipos de dados, o conector oferece suporte à recuperação de metadados do AWS Glue Data Catalog. Se o conector vê um banco de dados do AWS Glue e uma tabela que correspondam aos nomes de seu namespace do HBase e nomes de coleção, ele obtém suas informações de esquema da tabela AWS Glue correspondente. Quando você cria sua tabela AWS Glue, recomendamos que você a torne um superconjunto de todos os campos que você talvez queira acessar da sua coleção do HBase.
Se você tiver o Lake Formation habilitado em sua conta, o perfil do IAM para seu conector Lambda federado para Athena que você implantou no AWS Serverless Application Repository deve ter acesso de leitura ao AWS Glue Data Catalog no Lake Formation.
Esse conector pode ser registrado como um catálogo federado no Glue Data Catalog. Ele é compatível com controles de acesso a dados definidos no Lake Formation nos níveis de catálogo, banco de dados, tabela, coluna, linha e tag. Esse conector usa o Glue Connections para centralizar as propriedades de configuração no Glue.
Pré-requisitos
Implante o conector na sua Conta da AWS usando o console do Athena ou o AWS Serverless Application Repository. Para ter mais informações, consulte Criar uma conexão de fonte de dados ou Usar o AWS Serverless Application Repository para implantar um conector de fonte de dados.
Parâmetros
Use os parâmetros nesta seção para configurar o conector do HBase.
nota
Os conectores de fonte de dados do Athena criados a partir de 3 de dezembro de 2024 usam conexões do AWS Glue.
Os nomes e definições dos parâmetros listados abaixo são para conectores de fonte de dados do Athena criados antes de 3 de dezembro de 2024. Eles podem diferir de suas propriedades de conexão do AWS Glue correspondentes. A partir de 3 de dezembro de 2024, use os parâmetros abaixo somente ao implantar manualmente uma versão anterior de um conector de fonte de dados do Athena.
-
spill_bucket: especifica o bucket do Amazon S3 para dados que excedem os limites da função do Lambda.
-
spill_prefix: (opcional) assume como padrão uma subpasta no
spill_bucketespecificado chamadoathena-federation-spill. Recomendamos que você configure um ciclo de vida de armazenamento do Amazon S3 neste local para excluir derramamentos anteriores a um número predeterminado de dias ou horas. -
spill_put_request_headers: (opcional) um mapa codificado em JSON de cabeçalhos e valores de solicitações para a solicitação
putObjectdo Amazon S3 usada para o derramamento (por exemplo,{"x-amz-server-side-encryption" : "AES256"}). Para outros cabeçalhos possíveis, consulte PutObject na Referência da API do Amazon Simple Storage Service. -
kms_key_id: (opcional) por padrão, todos os dados transmitidos para o Amazon S3 são criptografados usando o modo de criptografia autenticado AES-GCM e uma chave gerada aleatoriamente. Para que sua função do Lambda use chaves de criptografia mais fortes geradas pelo KMS, como
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, é possível especificar um ID de chave do KMS. -
disable_spill_encryption: (opcional) quando definido como
True, desativa a criptografia do derramamento. É padronizado comoFalse, para que os dados transmitidos para o S3 sejam criptografados usando o AES-GCM — usando uma chave gerada aleatoriamente ou o KMS para gerar chaves. Desativar a criptografia do derramamento pode melhorar a performance, especialmente se o local do derramamento usar criptografia no lado do servidor. -
disable_glue: (opcional) se estiver presente e definido como verdadeiro, o conector não tentará recuperar metadados complementares do AWS Glue.
-
glue_catalog: (opcional) use essa opção para especificar um catálogo do AWS Glue entre contas. Por padrão, o conector tenta obter metadados de sua própria conta do AWS Glue.
-
default_hbase: se estiver presente, especifica uma string de conexão do HBase a ser usada quando não existir uma variável de ambiente específica do catálogo.
-
enable_case_insensitive_match: (opcional) caso seja
true, realiza pesquisas sem distinção entre maiúsculas e minúsculas em nomes de tabelas no HBase. O padrão éfalse. Use se sua consulta contiver nomes de tabelas com letras maiúsculas.
Especificação de strings de conexão
É possível fornecer uma ou mais propriedades que definem os detalhes da conexão do HBase para as instâncias do HBase que você usar com o conector. Para fazer isso, defina uma variável de ambiente Lambda que corresponda ao nome do catálogo que você deseja usar no Athena. Por exemplo, suponha que você queira usar as seguintes consultas para consultar duas instâncias diferentes do HBase no Athena:
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
Antes de usar essas duas instruções de SQL, você deverá adicionar duas variáveis de ambiente à sua função do Lambda: hbase_instance_1 e hbase_instance_2. O valor para cada uma deverá ser uma string de conexão do HBase no seguinte formato:
master_hostname:hbase_port:zookeeper_port
Uso de segredos
Opcionalmente, é possível usar o AWS Secrets Manager para obter parte ou todo o valor dos detalhes da string de conexão. Para usar o recurso Athena Federated Query com o Secrets Manager, a VPC conectada à sua função do Lambda deve ter acesso à Internet
Se você usar a sintaxe ${my_secret} para colocar o nome de um segredo do Secrets Manager em sua string de conexão, o conector substituirá o nome do segredo pelos valores de seu nome de usuário e senha do Secrets Manager.
Por exemplo, suponha que você defina a variável de ambiente Lambda para hbase_instance_1 com o seguinte valor:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
O SDK do Athena Query Federation tenta automaticamente recuperar um segredo chamado hbase_instance_1_creds do Secrets Manager e injetar esse valor no lugar de ${hbase_instance_1_creds}. Qualquer parte da string de conexão que esteja delimitada pela combinação de caracteres ${
} será é interpretada como um segredo do Secrets Manager. Se você especificar um nome secreto que o conector não consiga encontrar no Secrets Manager, o conector não substituirá o texto.
Configuração de bancos de dados e tabelas no AWS Glue
A inferência de esquema incorporada do conector oferece suporte somente a valores serializados no HBase, como strings (por exemplo, String.valueOf(int)). Como a capacidade incorporada de inferência de esquema do conector é limitada, talvez você queira usar o AWS Glue para metadados, em vez disso. Para habilitar uma tabela do AWS Glue para uso com o HBase, é preciso ter um banco de dados do AWS Glue e uma tabela com nomes que correspondam ao namespace do HBase e à tabela para a qual você deseja fornecer metadados complementares. O uso das convenções de nomenclatura da família de colunas do HBase é opcional, mas não obrigatório.
Para usar uma tabela AWS Glue para metadados complementares
-
Quando você editar a tabela e o banco de dados no console do AWS Glue, adicione as seguintes propriedades de tabela:
hbase-metadata-flag: essa propriedade indica ao conector HBase que o conector pode usar a tabela para metadados complementares. É possível fornecer qualquer valor para
hbase-metadata-flag, desde que a propriedadehbase-metadata-flagesteja presente na lista de propriedades da tabela.-
hbase-native-storage-flag: use esse sinalizador para alternar os dois modos de serialização de valores com suporte pelo conector. Por padrão, quando esse campo não estiver presente, o conector assumirá que todos os valores estão armazenados no HBase como strings. Como tal, ele tentará analisar tipos de dados como
INT,BIGINTeDOUBLEdo HBase como strings. Se esse campo for definido com qualquer valor na tabela em AWS Glue, o conector muda para o modo de armazenamento “nativo” e tenta lerINT,BIGINT,BIT, eDOUBLEcomo bytes usando as seguintes funções:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Use os tipos de dados apropriados para o AWS Glue, conforme listado neste documento.
Modelagem de famílias de colunas
O conector Athena HBase oferece suporte a duas formas de modelagem de famílias de colunas do HBase: nomenclatura totalmente qualificada (plana), como family:column ou usando objetos STRUCT.
No modelo STRUCT, o nome do campo STRUCT deve corresponder à família da coluna, e filhos do STRUCT devem corresponder aos nomes das colunas da família. No entanto, como ainda não há suporte total para a redução de predicados e as leituras colunares com tipos complexos como STRUCT, o uso de STRUCT, atualmente, não é recomendado.
A imagem a seguir mostra uma tabela configurada no AWS Glue que usa uma combinação das duas abordagens.
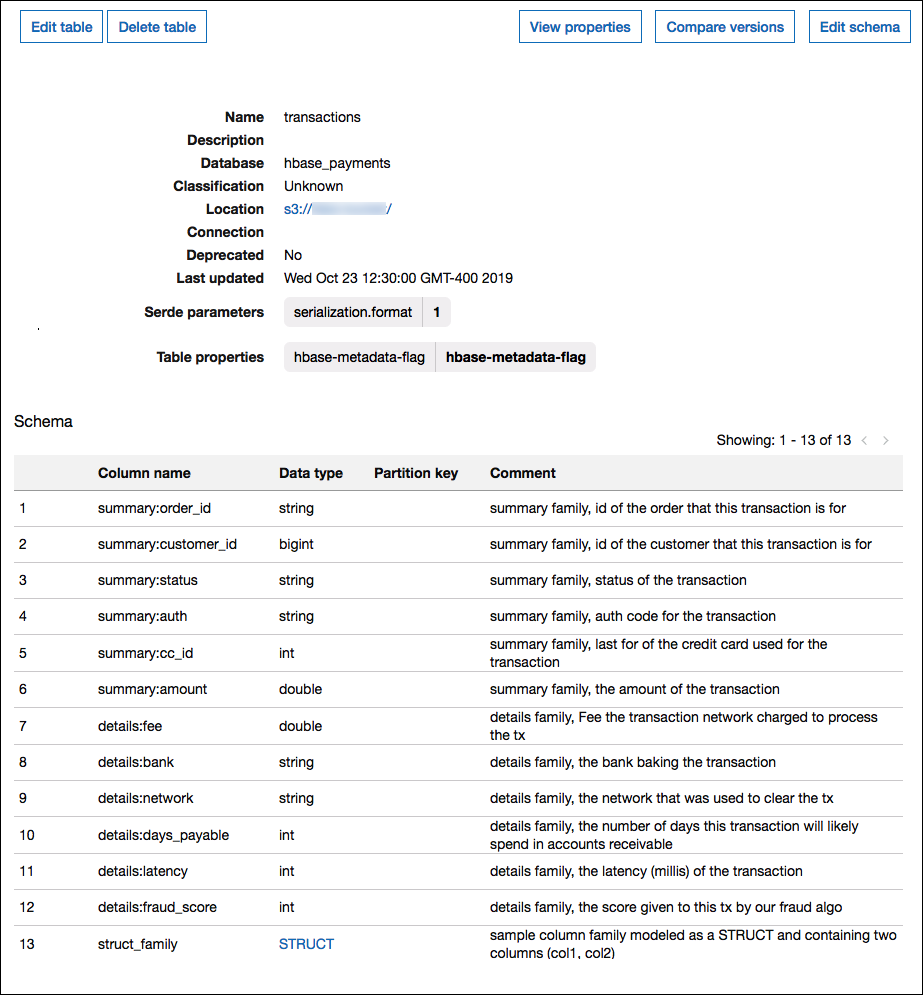
Suporte ao tipo de dados
O conector recupera todos os valores do HBase como o tipo básico byte. Em seguida, com base em como você definiu suas tabelas no Catálogo de dados do AWS Glue, ele mapeia os valores em um dos tipos de dados do Apache Arrow na tabela a seguir.
| Tipo de dados do AWS Glue | Tipo de dados Apache Arrow |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| flutuação | FLOAT4 |
| boolean | BIT |
| binary | VARBINARY |
| string | VARCHAR |
nota
Se você não usar AWS Glue para complementar seus metadados, a inferência do esquema do conector usará somente os tipos de dados BIGINT, FLOAT8 e VARCHAR.
Permissões obrigatórias
Os detalhes completos sobre as políticas do IAM exigidas por esse conector podem ser encontrados na seção Policies do arquivo athena-hbase.yaml
-
Acesso de gravação do Amazon S3: o conector requer acesso de gravação a um local no Amazon S3 para mostrar resultados de grandes consultas.
-
Athena GetQueryExecution: o conector usa esta permissão para falhar rapidamente quando a consulta upstream do Athena é encerrada.
-
AWS Glue Data Catalog: o conector HBase requer acesso somente de leitura ao AWS Glue Data Catalog para obter informações do esquema.
-
CloudWatch Logs: o conector requer acesso ao CloudWatch Logs para armazenar registros.
-
Acesso de leitura do AWS Secrets Manager: se você optar por armazenar os detalhes do endpoint do HBase no Secrets Manager, deverá conceder ao conector acesso a esses segredos.
-
Acesso à VPC: o conector exige a capacidade de conectar e desconectar interfaces à sua VPC para que ela possa se conectar a ela e se comunicar com suas instâncias do HBase.
Performance
O conector Athena HBase tenta paralelizar as consultas em sua instância do HBase lendo cada servidor da região em paralelo. O conetor do Athena para o HBase realiza a passagem direta de predicados para diminuir os dados examinados pela consulta.
A função do Lambda também executa o empilhamento de projeções para diminuir os dados verificados pela consulta. No entanto, selecionar um subconjunto de colunas, às vezes, resulta em um runtime de consulta mais longo. As cláusulas LIMIT reduzem a quantidade de dados verificados, mas se você não fornecer um predicado, deverá aguardar que as consultas SELECT com uma cláusula LIMIT verifiquem, no mínimo, 16 MB de dados.
O HBase está propenso a falhas na consulta e tempos de execução variáveis para as consultas. Pode ser necessário repetir as consultas diversas vezes para que elas sejam bem-sucedidas. O conector HBase é resiliente ao controle de utilização devido à simultaneidade.
Consultas de passagem
O conector do HBase é compatível com consultas de passagem e é baseado em NoSQL. Para obter informações sobre como consultar o Apache HBase usando filtros, consulte Filter language
Para usar consultas de passagem com o HBase, use a seguinte sintaxe:
SELECT * FROM TABLE( system.query( database => 'database_name', collection => 'collection_name', filter => '{query_syntax}' ))
O exemplo a seguir de consulta de passagem do HBase filtra funcionários com 24 ou 30 anos na coleção employee do banco de dados default.
SELECT * FROM TABLE( system.query( DATABASE => 'default', COLLECTION => 'employee', FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' || ' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')' ))
Informações de licença
O projeto do conector HBase do Amazon Athena é licenciado sob a Licença Apache-2.0
Recursos adicionais
Para obter mais informações sobre esse conector, visite o site correspondente
